
OpsAutoPilot
The conversational AI that sits in your incident channel, talks to every tool you own in parallel, and tells you what’s actually broken — in plain English.
In short
On-call engineers don’t have a knowledge problem at 2 a.m. They have a tab problem. Splunk in one window, Observability in another, Jira, Confluence, ServiceNow, GitLab, and six alert sources screaming at once. The diagnosis is sitting in those tools — it just takes a tired human forty minutes to stitch it together. OpsAutoPilot connects to all of them at once through MCP. When you ask it a question — or when a P1 fires on its own — it fans out to every relevant tool in parallel, pulls the last hour of live data plus the standing runbooks and the latest deployments, hands it to an LLM, and returns one clean answer: the issue, the blast radius, the impacted endpoints, the error rate, the bad deploy, and the exact line of code to fix. You can chat with it like a teammate. And it never sleeps.
2:14 a.m., and the tabs were winning
A payment service starts throwing errors. The alert fires. My engineer — let’s call her Priya — wakes up and starts the ritual. Splunk for logs. Observability for the latency graphs. GitLab to scroll the recent merges and pipelines. Jira for the change ticket. Confluence for the half-remembered runbook. ServiceNow to see who else is impacted.
By the time six tabs are loaded, eleven minutes are gone — and she hasn’t solved anything yet. She’s assembling the problem. It took thirty-eight more minutes to find it: a merge request shipped at 1:50 a.m. had pointed the payment service at a stale connection pool — three lines in one config file. The fix took ninety seconds. The finding took forty-nine minutes.
Every piece of information she needed was already in a tool we already paid for. The data wasn’t missing — it was scattered. OpsAutoPilot is what you get when you decide to stop paying the tax of un-scattering it by hand at 2 a.m.
OpsAutoPilot is a conversational AI permanently connected to all your ops tools. On any request — typed by a human or triggered by an alert — it asks every relevant tool in parallel, then has an LLM read everything and answer you in plain English.
The mental model: one brain, many hands
Picture a brain with a lot of hands. The brain is the LLM. The hands are MCP servers — one small connector per tool. One hand per system, and the brain can use any of them.

GitLab is the one hand that does two jobs. It tells OpsAutoPilot what shipped recently (deployment history and pipelines — time-sensitive) and it lets the LLM read the actual source code (master data) — so the answer can go beyond “a deploy broke it” all the way to “here’s the exact method and the line that did it, and here’s the fix.”
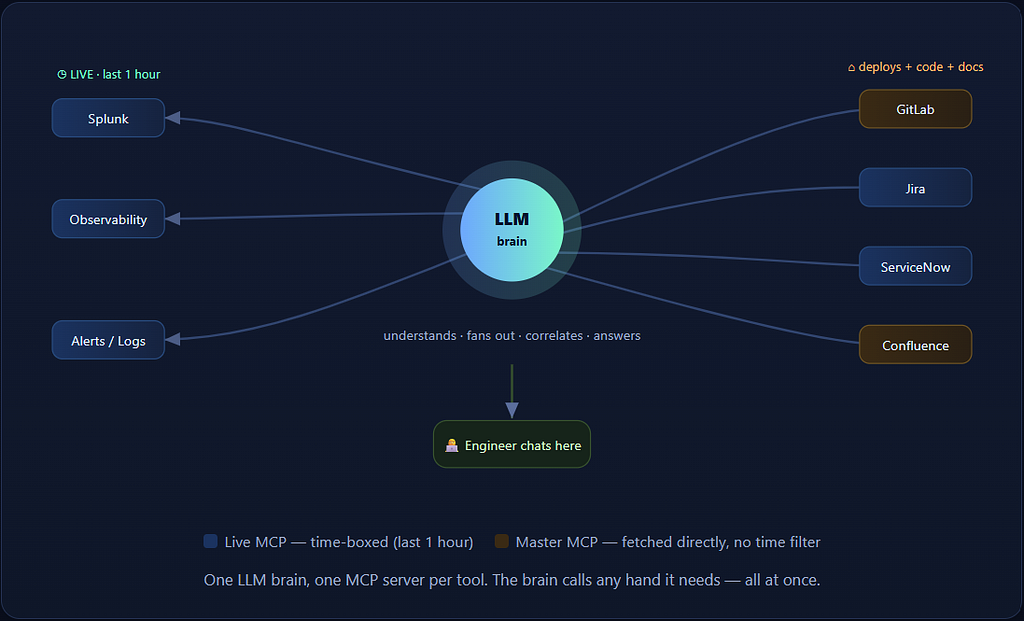
Two kinds of data: “what’s happening now” and “what’s always true”
This is the design decision most people miss. Some data only matters in a window — the payment error rate right now is gold; last March’s is noise. So Splunk, Observability, and the alert streams get a tight last-one-hour pull.
Other data has no timestamp that matters — the runbook, the architecture diagram, the escalation process. This is master data, fetched directly, because the truth in a runbook doesn’t expire at the one-hour mark. The LLM reads both together: symptoms from live tools, context from the docs — exactly what a senior engineer does in their head, in two seconds instead of forty minutes.
What happens when you ask it something
Instead of opening five tabs, Priya types one line. Here’s the fan-out the moment it understands her:

💬 Conversation 1 — Engineer asks, OpsAutoPilot answers
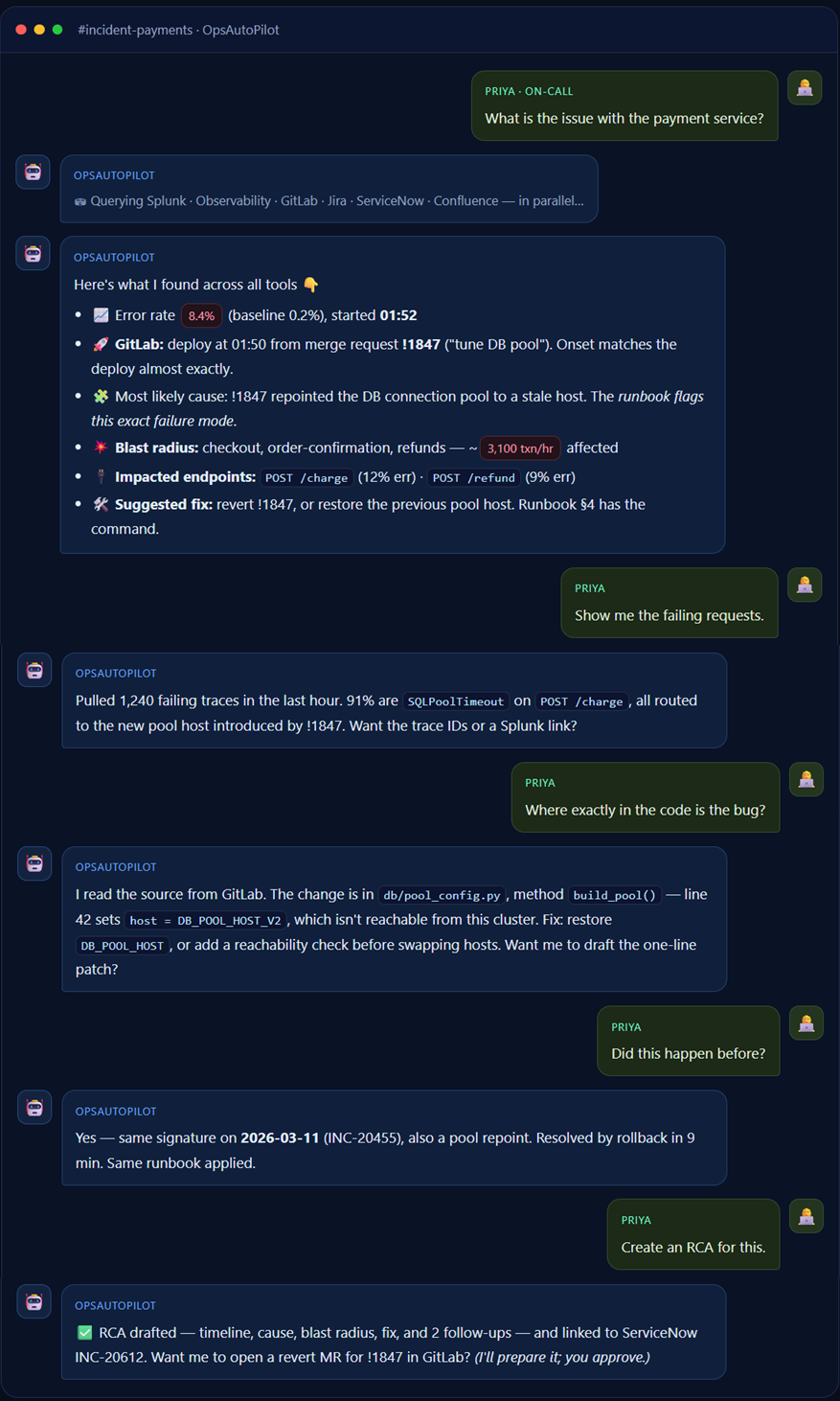
Forty-nine minutes of tab-juggling, compressed into a chat. Every claim traces back to the tool it came from.
The other mode: it watches so you don’t have to
The more powerful half is that OpsAutoPilot can sit on the line and listen — permanently subscribed to every alert source. P3/P4 it quietly logs and groups. For P1/P2 it reacts automatically: the instant the alert fires it runs the same parallel fan-out and posts a complete first analysis before a human has finished reading the alert.
🚨 Conversation 2 — Autonomous: bot posts the RCA, engineer follows up
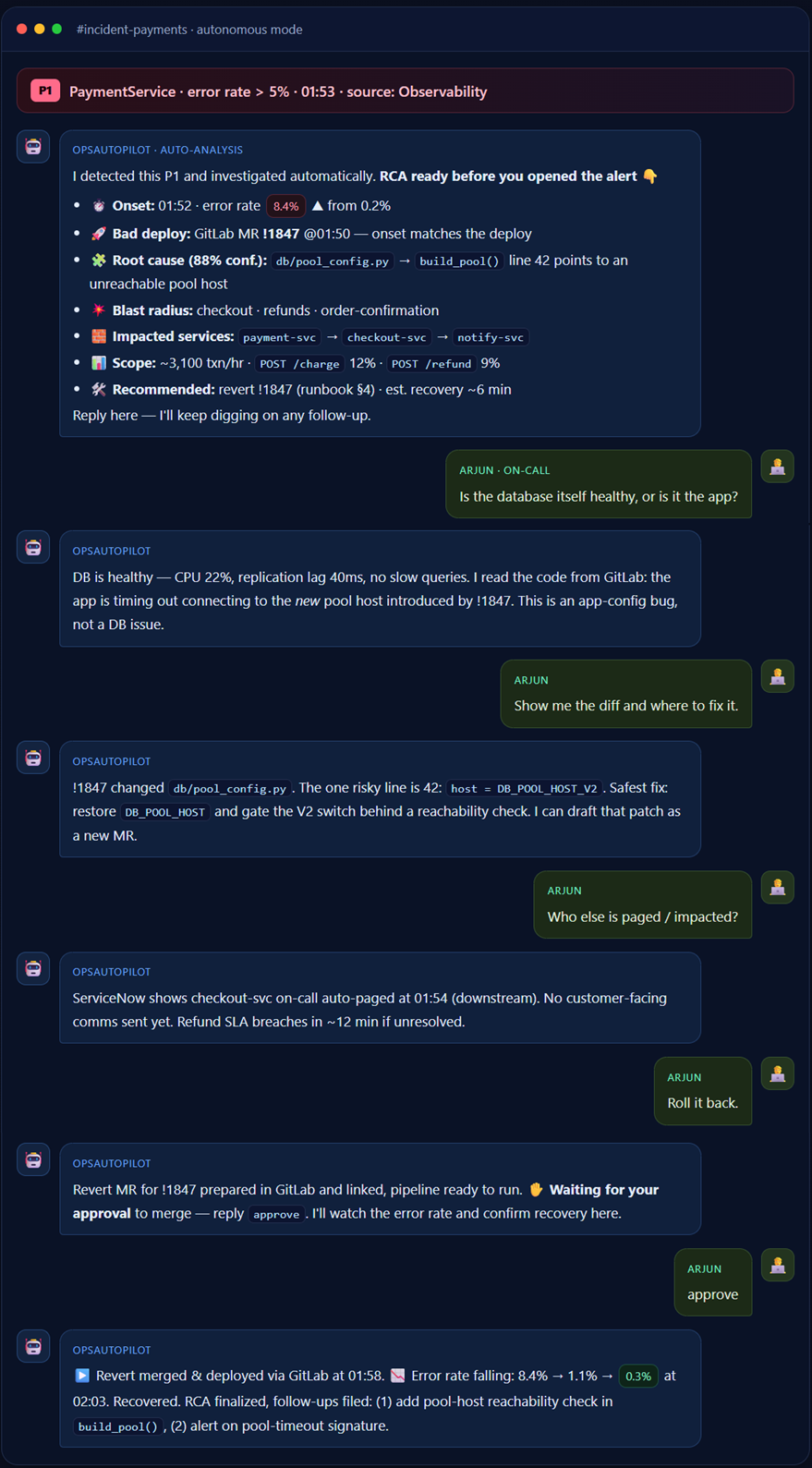
The engineer’s first job is no longer investigate — it’s decide. A calmer, smaller, better job.
Why “parallel” is the whole game
A simple version asks one tool, waits, reads, decides, asks the next, waits again — a chatbot wrapping slow calls. OpsAutoPilot fires every needed call at once and waits for them together. Six tools at two seconds each cost you two seconds, not twelve. “Instant” is what makes engineers trust it instead of falling back to tabs.
async def diagnose(request):
intent = llm.understand(request) # what's asked + which tools answer it
# fire everything at once - live (time-boxed) AND master (direct)
results = await gather(
splunk.logs(intent.service, window="1h"),
observability.metrics(intent.service, window="1h"),
alerts.active(intent.service),
gitlab.deploys(intent.service, window="3h"), # what shipped recently
gitlab.read_code(intent.service), # the actual source - master data
jira.recent_changes(intent.service, window="3h"),
servicenow.open_incidents(intent.service),
confluence.runbook(intent.service), # master data - no time filter
)
return llm.analyze(
live_data = results.time_boxed, # what's happening now + recent deploys
knowledge = results.master_data, # runbooks + source code
ask_for = ["root_cause", "blast_radius", "impacted_endpoints",
"error_rate", "bad_deploy", "code_location", "fix"],
)
One fan-out, not a chain. Live + master arrive together. The LLM is asked for a fixed answer shape, so every reply is decision-ready.
The numbers (what we’d expect this to move)
MetricBefore (manual tabs)With OpsAutoPilotChangeTime to first useful diagnosis~40 min~2 min−95%Tools opened manually per incident5–60−100%Mean time to mitigate (P1/P2)52 min14 min−73%P1s analysed before human reads alert0%~90%+90 ptsRCA draft turnaround1–2 daysminutes−99%Pages needing a human to investigate100%~35%−65 pts
Illustrative figures — swap in your own. The row that matters most: the share of pages where the human’s job shrinks from investigate to decide.
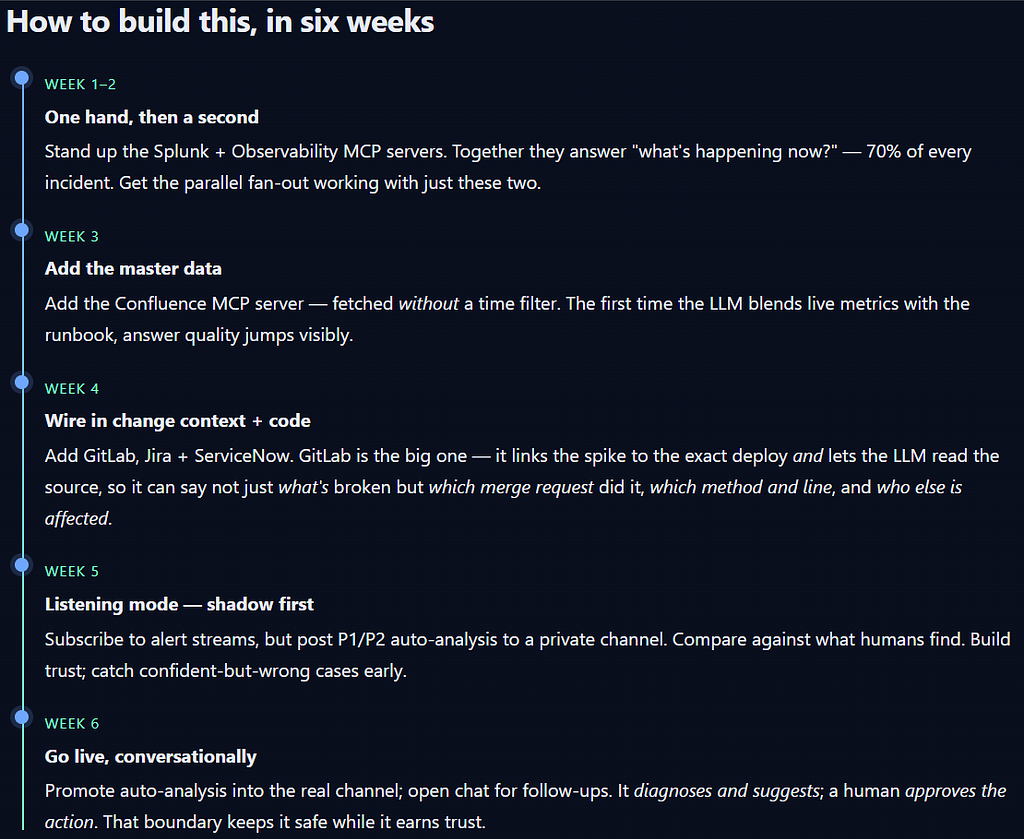
How to build this, in six weeks
The honest caveats

What this looks like in 2027 and beyond
- The incident channel becomes a conversation, not a dashboard. “Open five tools and correlate” will feel as dated as SSH-ing in to read logs.
- The one-hour window becomes adaptive — minutes for a spike, days for a slow leak — chosen by the AI per failure mode.
- Suggestions become drafts become PRs. It tells you the fix, then drafts it, then opens the rollback and waits for your thumbs-up.
- One brain across the org. The first time your service hits a failure, the system already knows the likely causes because it’s seen them elsewhere.
- Knowing what’s broken stops being the hard part. On-call moves up a level — from detective to decision-maker.
Your starter checklist
- Think “one brain, many hands”: an LLM + one MCP server per tool
- Split your data: time-boxed (Splunk, Observability, alerts — last 1 hour) vs master (Confluence runbooks — no time filter)
- Make the fan-out parallel — every needed tool at once
- Ask the LLM for a fixed answer shape: cause · blast radius · endpoints · error rate · bad deploy · code location · fix
- Ship Splunk + Observability first; add Confluence next — that’s where quality jumps
- Add GitLab for deployment history and direct code analysis — it pinpoints the merge request, the method, and the line to fix
- Add Jira + ServiceNow for change context and impact
- Turn on listening mode in shadow before it’s in front of on-call
- For P1/P2, post auto-analysis before a human finishes reading the alert
- Keep humans in the decision seat — it diagnoses and suggests; a person approves
- Clean your runbooks — the AI is only as good as the docs it reads
The night I described — Priya assembling the problem for forty-nine minutes before she could even start solving it — is the night I want to make extinct. Not by making engineers faster, but by giving them a teammate who has already opened every tab, read every graph, checked every recent change, and is waiting in the channel to say, in plain English: here’s what’s broken, here’s how bad, here’s what I’d do.
That teammate is buildable today. We just have to wire up the hands and trust the brain.
Sources: Model Context Protocol spec (modelcontextprotocol.io) · Anthropic “Building agents with tool use” · Splunk & Splunk Observability docs · GitLab API & deployments docs · Jira / Confluence / ServiceNow connector patterns · Google SRE Workbook.
© June 2026 · Ganesh Gurudu · OpsAutoPilot
OpsAutoPilot was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.