
Enterprise AI Evaluation Is Not a Scorecard. It Is a Feedback Flywheel.
Enterprise AI evaluation should not be treated as a scorecard. It should be treated as the operating system for product improvement.
Most teams start evaluating enterprise AI systems the same way: collect a few examples, ask people to rate the answers, add a dashboard, and call it an eval.
That works for a demo. It does not work for a production enterprise assistant.
Demo evals ask: “Was the answer good?”
Production evals have to ask: “What failed, why did it fail, who owns the fix, and how do we know the fix worked without breaking something else?”
After working on enterprise AI assistants, I have found that the hardest part of evaluation is not producing a score. It is turning messy production failures into targeted, owned, validated fixes.
Enterprise AI systems fail in ways that are more complicated than “the answer was bad.” A user may be unhappy because the assistant did not search when it should have, searched the wrong corpus, retrieved the right document but used the wrong passage, answered correctly but ignored the requested format, clarified when it should have acted, or lacked the product capability needed to complete the task.
If all of those failures collapse into one metric called “bad answer,” the team cannot improve the system systematically. A useful evaluation system does more than say whether the model failed. It explains where the system failed, what kind of fix is needed, and how to validate that fix.
That is why enterprise AI evaluation should be designed as a feedback flywheel, not a static scorecard.
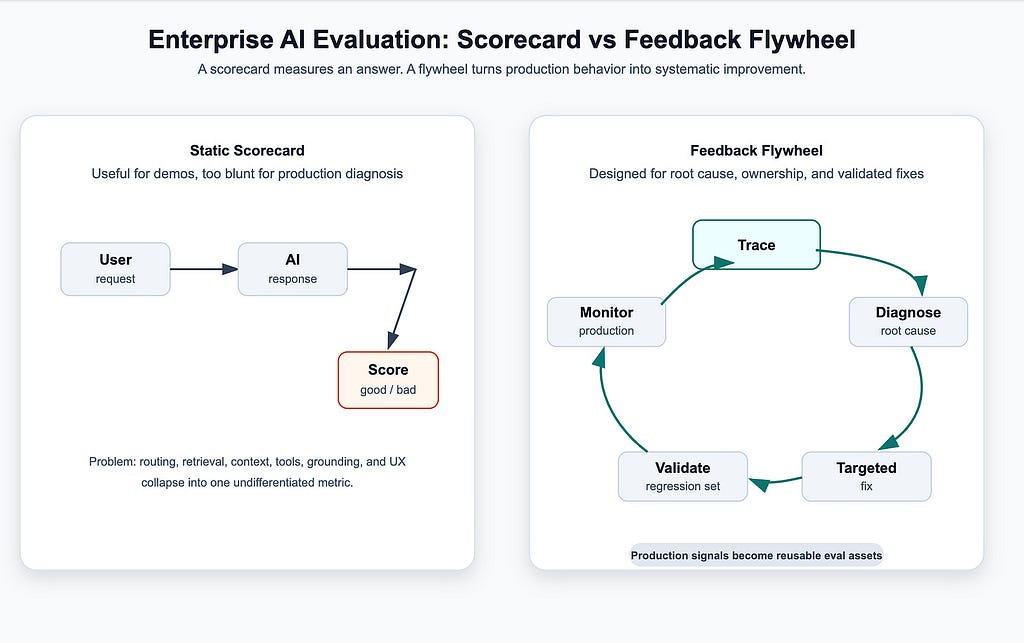
Static scorecard versus feedback flywheel
The Core Problem
An enterprise assistant is not just a model. It is a system:
- intent detection
- routing
- retrieval or search
- context selection
- planning
- tool use
- response generation
- citation and grounding
- formatting
- memory or multi-turn context
- safety and policy checks
- product UX
Imagine a sales leader asks:
Can you summarize the customer escalation from last week and draft a follow-up email?
There are many ways the assistant can fail:
- It may answer from memory instead of searching.
- It may search but retrieve irrelevant account notes.
- It may retrieve the right account thread but miss the escalation email.
- It may summarize correctly but omit the follow-up draft.
- It may draft the email but hallucinate the recipient.
- It may cite sources incorrectly.
- It may ask a clarification question even though the request was clear.
- It may use the wrong tone for a customer-facing message.
A scorecard may mark the output as bad. That is directionally useful, but it is not actionable enough.
The engineering team needs to know whether the fix belongs in routing, retrieval, prompt instructions, tool design, context construction, model selection, product UX, or the evaluation itself.
The unit of improvement is not the answer. It is the diagnosed failure pattern.
There is another reason enterprise AI evaluation is hard: many tasks do not have a fully verifiable environment.
In code generation, math, or some tool-execution tasks, the system may be able to check whether the answer worked. Did the code compile? Did the test pass? Did the API call return the expected state?
Many enterprise assistant tasks are not like that. For question answering over company knowledge, summarization, customer communication, planning, or decision support, the system often does not have a clean ground-truth label. It may not even know whether it retrieved the document the user had in mind.
For example, suppose a user asks about “the customer escalation from last week.” The assistant may retrieve a relevant account note that contains part of the answer. But there may be another email thread, support ticket, Slack message, or meeting note that better matches the user’s intent. Without access to the user’s full mental context, the system cannot always verify that it found the exact source the user expected.
This creates an evaluation problem. The team still needs quality signals, but many of those signals are proxies:
- user feedback
- human review
- source relevance judgments
- answer usefulness ratings
- citation and grounding checks
- LLM-as-judge rubrics
- downstream task completion
- repeated rephrasing or correction behavior
That is why LLM-as-judge is useful in enterprise AI, even though it is not ground truth. It gives the team a scalable way to estimate relevance, groundedness, completeness, and constraint following when no deterministic verifier exists.
But it also means the eval system has to be careful about credit assignment. If the final answer is weak, was the problem that the model reasoned poorly, or that retrieval missed the user’s intended source, or that the judge did not see enough context to evaluate fairly? In enterprise AI, evaluation is partly about scoring outputs, but it is also about reconstructing enough of the environment to understand what the system could have known.
From Scores To Root Cause
A practical enterprise AI evaluation system should measure the workflow in stages.
Instead of scoring only the final answer, I like to break evaluation into component-level questions:
- Did the assistant understand the user’s intent?
- Did it decide correctly whether to search, answer directly, clarify, abstain, or use a tool?
- If it searched, were the queries appropriate?
- Were the retrieved sources relevant?
- Did the context contain enough evidence to answer?
- Did the model use the context correctly?
- Were citations grounded in retrieved sources?
- Did the final answer satisfy the requested format and constraints?
- Did the assistant preserve multi-turn context?
- Did it call the right tools with the right arguments?
This does not mean every request needs every score. It means the evaluation framework should be able to decompose failures when needed.
The most useful evals are not just labels. They are diagnostic signals with reasons.

For the sales escalation example, a trace might look like this:
User request:
"Summarize the customer escalation from last week and draft a follow-up email."
Trace summary:
- user intent: summarize escalation and draft customer follow-up
- selected path: answer directly
- enterprise context: not retrieved
- final response: generic account summary, no customer email draft
Diagnostic signal:
The assistant chose a direct-answer path for a request that required fresh enterprise context.
Likely intervention:
Update prompting to prioritize searching from enterprise knowledge over using general knowledge for certain cases;
Or optimize routing criteria (maybe optimizing classifier if current agent system is composed of dedicated agents with a workflow, router) handled
The important part is not that the answer was bad. The important part is that the failure is now owned. This is not primarily a generation problem. It could be a reasoning problem (if the agent architecture is react) that agent skip calling the internal search tools and only answer with general knowledge. The fix should be from updating the prompt (or adding few show examples), and the validation set should include a certain portion/amount of failure cases where fresh enterprise context is required but agent didn’t call the internal tools (along with other non-targeted cases), and a regression dataset that represents overall distribution of current production traces.
The important part is not simply that the answer was bad. The important part is that the failure is now diagnosable and owned.
In this example, the issue is not final-response generation. It may be a reasoning or routing failure: the agent answered from general knowledge when the task required internal enterprise context. A good fix would target that decision point, perhaps through clearer prompting (e.g. for a ReAct agent) to discuss when to use search tool or not, or a clearer routing instructions (e.g. if decision point is from a classification layer routing to orchestrate agent).
The validation set should then include a focused slice of similar failures, where the assistant needed fresh enterprise context but did not retrieve it. It should also include non-targeted regression cases that represent the broader production distribution, so the fix does not improve one behavior while degrading overall quality.
That is the difference between measuring quality and improving it.
The Evaluation Stack
For an enterprise assistant, I think about evaluation in five layers.
Evaluation stack
+-----------------------------------+
| Launch gates and regression tests |
+-----------------------------------+
| Human calibration |
+-----------------------------------+
| Metrics (verifiable, llm-as-judge)|
+-----------------------------------+
| Production traces |
+-----------------------------------+
| Curated offline datasets |
+-----------------------------------+
1. Curated Offline Datasets
Offline datasets are the foundation. They should include representative examples of the tasks the assistant is expected to handle, but “offline” should not mean frozen forever. As the product, user behavior, data sources, and failure patterns change, the eval set should be refreshed on a cadence that fits the business. For some teams, that may mean weekly updates from production traces. For others, it may mean monthly or quarterly refreshes tied to major product or policy changes. The goal is to keep the dataset stable enough for regression testing, but current enough to reflect how the assistant is actually being used.
For enterprise AI, public benchmarks are rarely enough. Real enterprise data is messy:
- noisy documents
- duplicated or stale content
- partial relevance
- multiple documents that each contain part of the answer
- hard negatives that look relevant but are not
- permission boundarie
- ambiguous user references
- messy multi-turn context
If the offline data is too clean, the eval will overestimate product quality. A useful dataset should include normal cases and adversarial-but-realistic cases: answerable questions, unanswerable questions, search-required tasks, multi-document questions, hard-negative context, clarification cases, and abstention cases.
The goal is not to create a perfect benchmark. The goal is to create a stable measurement surface that reflects product reality.
2. Production Traces
Offline datasets tell you whether a change improves known cases. Production traces tell you what is actually happening.
For agentic systems, traces are critical because the final answer is only the last step. You need visibility into the user request, plan, tool calls, queries, retrieved documents, selected context, final answer, and attached scores or user feedback.
Without traces, the team is debugging a black box.
With traces, you can turn “the assistant gave a bad answer” into “the assistant failed to call search even though the answer required fresh enterprise context.”
That difference matters.
3. Metrics & Reward Signals
Metrics and reward signals are what make the feedback flywheel work.
In some domains, feedback is easy to verify. A math problem has a correct answer. A coding task can be checked with tests. A recommender system may have clicks, purchases, or dwell time. Those signals are imperfect, but they give the system something concrete to optimize.
Enterprise AI assistants often do not have that luxury.
For many knowledge-work tasks, we do not know whether the user found the answer useful. Even when the product includes thumbs up/down buttons, explicit feedback is usually sparse. Most users do not stop their workflow to label the assistant’s response.
Implicit feedback can help. A follow-up question, correction, rephrasing, abandonment, or repeated request may suggest that the assistant failed. But those signals are noisy and incomplete. Many successful interactions have no follow-up. Many failed interactions also have no explicit complaint.
That is why metrics and reward design become central to enterprise AI evaluation. The system needs a way to turn sparse, noisy, partial signals into usable quality estimates.
LLM-as-judge can help close this gap, but only if it is designed carefully.
There are trade-offs in judge design across cost, quality, coverage, and interpretability. A generic final-answer judge is cheaper to build and easier to run, but it may be too blunt for root-cause analysis. Component-level judges require more design work, but they can tell you where the workflow broke.
For example:
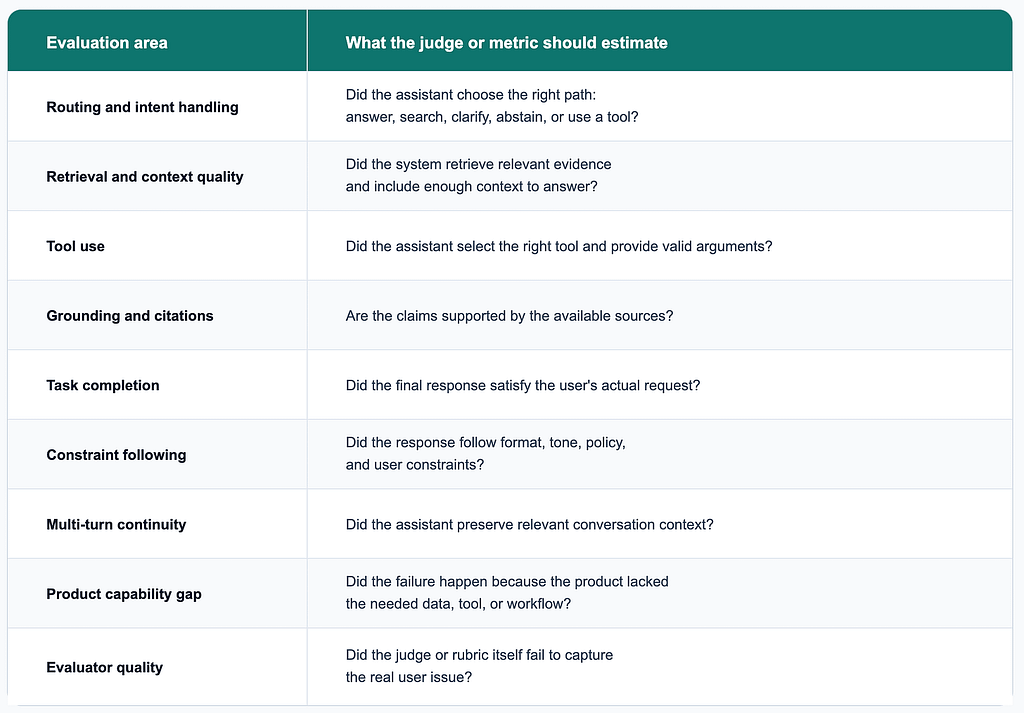
There is no universally correct judge design. The right approach depends on the product, traffic volume, risk level, cost constraints, and the kinds of failures the team needs to catch. The important thing is to experiment, calibrate against human review, and treat judge outputs as proxy signals rather than ground truth.
Each judge should return structured outputs: a score, a rationale, and a diagnostic category. The score says how bad something is. The category says what kind of bad it is.
Those structured signals can later power error analysis, routing improvements, prompt optimization, regression tests, and eventually reward modeling or preference-data construction. But the foundation is the same: make the quality signal rich enough that the team can act on it.
4. Human Calibration
LLM judges are not ground truth. They are scalable approximations.
To make them trustworthy, they need to be calibrated against human signals. Those signals can come from expert annotations, human review, thumbs up/down feedback, written user comments, or high-confidence product outcomes.
Calibration should answer a few questions:
– Where do judge scores agree or disagree with human labels?
– What kinds of false positives and false negatives does the judge produce?
– Which failure types are most often missed?
– Does the judge reward behavior that users or reviewers actually dislike?
– Which high-risk tasks need small gold sets for ongoing validation?
This is especially important when the judge does not see the same evidence the assistant saw. If a judge evaluates an answer without retrieved context, it may penalize a well-grounded response or reward a plausible hallucination. If it sees too much irrelevant context, it may miss that the assistant relied on the wrong evidence.
Evaluation quality is itself a product surface. If the eval is wrong, the optimization loop will optimize the wrong thing.
The judge should therefore improve over time, just like the assistant. Human feedback can be fed back into the evaluation loop to refine judge prompts, adjust rubrics, update thresholds, and identify blind spots. Prompt-optimization techniques, meta-prompting, or agentic judge workflows can help propose better rubrics or judge prompts, but they should still be validated against human-calibrated examples.
In a mature system, human calibration is not a one-time setup step. It is a continuous loop.
The goal is not to make the judge perfect. The goal is to make it reliable enough that teams can trust the direction of the signal and know when human review is still required.
5. Launch Gates And Regression Tests
An eval system becomes operationally useful when it affects shipping decisions.
For every proposed change, the team should be able to ask:
- Did the target failure improve?
- Did general quality regress?
- Did latency regress?
- Did tool usage explode?
- Did costs change?
- Did user-facing behavior become less predictable?
- Did any safety or policy score regress?
Launch gates and regression datasets are especially important if the team wants to automate parts of the improvement loop. They provide the safety net. A system can propose prompt edits, retrieval changes, or code changes, but those changes should not ship unless they improve the target behavior without damaging broader product quality.
In other words, regression tests are what make automation safe. They let the team move faster without turning every fix into a new source of risk.
The Feedback Flywheel
Once the evaluation stack exists, the next step is closing the loop.
7-steps flywheel frameworks:
- Detect: develop Triage skills to detect failures from production signals.
- Diagnose root causes using traces and component-level scores and generated Prioritize fixed dimensions: Planning, Prompt quality, Ranking/retrieval, Tool harness gaps, Context hallucination, Memory
- Improve: Targeted fixes against root cause automatically (e.g. new prompt variants, ranking algorithm, context, code fix, model parameters update with Reinforcement Learning, each auto optimization candidate may require a set up or its own loop (e.g. auto research))
- Validate fixes on failure slices and general regression sets;
- Ship behind a gate or experiment.
- Monitor production impact.
- Add newly discovered failures back into the eval set.
The loop matters more than any individual metric.
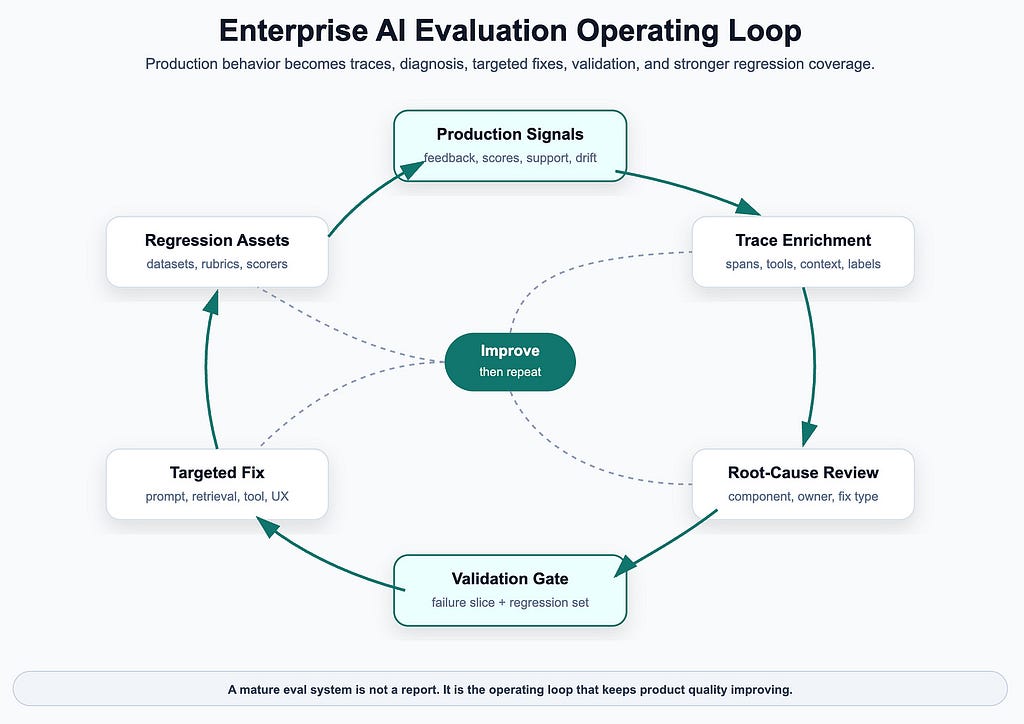
Evaluation feedback operating loop
A Practical Roadmap
The feedback flywheel does not need to start as a fully automated self-improving system. In practice, it should be built in phases.
A reliable agent-improvement loop is not built in a day. It requires the surrounding infrastructure: evaluation harnesses, trace schemas, dataset strategy, scoring rubrics, human-in-the-loop review, auto-optimization workflows, launch gates, and monitoring. It also needs operational guardrails around cost, token usage, latency, and runtime.
The goal is not to automate everything immediately. The goal is to keep improving the framework until the system can propose, test, and ship improvements with enough evidence that the team can trust the loop.
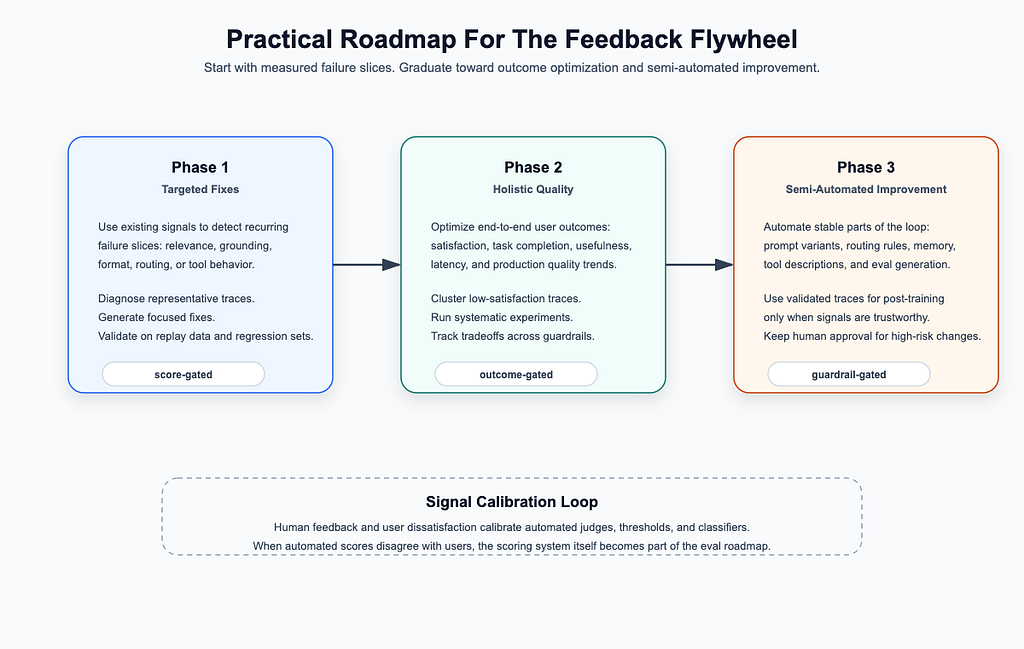
Practical roadmap for the feedback flywheel
Phase 1: Targeted Fixes
Start with failure areas where you already have measurement coverage.
For example, if you can already score answer relevance, groundedness, tool correctness, or formatting, use those signals to find low-performing traces. Then sample representative failures, diagnose the likely component, create a small replay dataset, and test targeted fixes against that slice.
This phase is score-gated. The goal is not to solve every quality problem. The goal is to make one recurring failure pattern measurable, fixable, and regression-tested.
For areas where measurement is missing, the first task is not fixing the model. It is building the missing measurement surface: a new rubric, scorer, classifier, human review queue, or labeled dataset for that behavior.
Phase 2: Holistic Quality Improvement
Once targeted fixes are working, shift from isolated failures to end-to-end user outcomes.
This phase is outcome-gated. The key signals are user satisfaction, task completion, final answer usefulness, and production quality trends. Instead of only asking whether one failure category improved, the team asks whether the overall assistant experience is getting better.
Low-satisfaction traces can be clustered by task and diagnosis pattern. Those clusters then guide systematic experiments: better context selection, retrieval reranking, context compaction, prompt variants, tool additions, or UX changes for cases where the assistant cannot complete the task alone.
Phase 3: Semi-Automated Improvement
Only after the first two phases are reliable should the team automate more of the improvement loop.
For closed-source models, the system around the model can evolve: prompts, few-shot examples, routing rules, memory, retrieval policies, tool descriptions, and orchestration logic. The eval system can propose candidate changes, replay traces, and accept only changes that improve the target slice without breaking guardrails.
For open-source or controllable models, validated trajectories can become post-training data. Successful traces become demonstrations. Failed traces become contrastive examples. User feedback and judge scores become preference or reward signals. But this only works if the evaluation loop is already trustworthy.
The roadmap matters because it keeps the team from jumping too quickly to automation. The order should be: measure the behavior, diagnose it, validate fixes, then automate the parts of the loop that are stable.
Detect
Signals can come from thumbs up/down, written comments, repeated rephrasing, abandonment, human review, online judge scores, latency anomalies, tool-call anomalies, and support tickets.
Some signals are sparse but high-quality, like written user feedback. Others are broad but noisy, like automated judge scores. A good system uses both.
There is also a calibration loop inside the flywheel. Explicit feedback, such as written user complaints or human review, should be used to calibrate broader automated signals. If online scores say an answer is good but users consistently disagree, the scoring system has a blind spot. That blind spot should become an eval improvement task.
Diagnose
This is where many teams get stuck.
It is tempting to sample bad responses and ask, “How do we improve the prompt?” But many failures are not prompt failures.
I like to sort failures into buckets:
- prompt or instruction issue
- retrieval or ranking issue
- missing tool or product capability
- tool argument issue
- context construction issue
- model limitation
- memory or multi-turn issue
- data freshness issue
- latency or infrastructure issue
- evaluation or scorer issue
This prevents prompt engineering from becoming the universal hammer.
Root cause -> likely fix

Fix, Validate, Ship
The fix should match the failure mode.
A prompt issue may need clearer instructions or examples. A retrieval issue may need query rewriting, ranking algorithm changes, or better context selection. A tool issue may need a better schema or argument validation. A model limitation may need a model switch, fine-tuning, or post-training. An evaluation issue may need a rubric update and human calibration.
Every fix should be tested on at least two slices:
- the targeted failure set
- a broad regression set
If a prompt improves the target failures but hurts general traffic, it may not be worth shipping. For example, a more aggressive search instruction may reduce search-routing failures but increase latency and unnecessary tool calls. Whether that tradeoff is acceptable depends on the product.
Validation should also include guardrails: final answer quality, context relevance, ambiguity handling, latency, cost, tool-call count, and user-facing format.
Even when offline validation looks good, production may surprise you. I prefer shipping behind a feature flag or experiment, then monitoring target metrics, general quality, latency, cost, user feedback, and new failure patterns.
Add Failures Back To The Dataset
The best evaluation sets are living assets.
Whenever the system fails in a new way, the team should ask:
- Is this failure already represented in our offline evals?
- Do our judges detect it?
- Is the failure important enough to become a regression test?
- Which component owns the fix?
This is how the eval set becomes a memory of the product. It captures what the system has learned, where it has failed, and what it should never regress on again.
Toward Self-Improving Agents
The feedback flywheel is the prerequisite for self-improving agents.
Once the loop is working, you can start automating parts of it. I think about this in three levels.
Level 1: Human-Led, Eval-Assisted
The system surfaces failures, clusters them, and provides traces. Humans inspect, decide fixes, and ship.
This is where most teams should start.
Level 2: Semi-Automated Fix Generation
The system proposes targeted changes:
- prompt variants
- tool description edits
- routing logic update
- ranking algorithm update
- memory retrieval update
Humans still approve changes, but the loop becomes faster.
A practical version of this is not just “ask a model to improve the prompt.” It is an autonomous improvement pipeline around the agent:
1. Build data and eval frameworks. The system needs to identify failing traces, preserve the relevant context, and attach enough diagnostic signal to explain why the trace failed.
2. Build triage skills. A triage agent or classifier should assign likely root cause, estimate severity, and rank fix priority. Not every failure deserves the same amount of engineering attention.
3. Improve and fix automatically. For each prioritized failure cluster, the system can create candidate fixes in parallel worktrees or isolated experiment branches. One cluster may need a prompt change. Another may need a retrieval change, a tool-schema update, a routing rule, or a code fix.
4. Use different auto-improvement techniques for different layers. Prompt failures may benefit from prompt optimization methods such as GEPA-style reflection and rewriting. Retrieval or ranking failures may need auto-research over chunking, reranking, or feature changes. Model-behavior failures may eventually require fine-tuning, preference optimization, or reinforcement learning.
5. Gate every candidate. No automatically generated fix should ship just because it looks plausible. It should pass evals, targeted failure slices, regression datasets, guardrail metrics, and cost/latency checks.
This is the difference between vague self-improvement and an engineering system for improvement. The agent does not simply “learn from feedback” in the abstract. The surrounding system gives it data, triage skills, experiment isolation, specialized optimization tools, and launch gates.
Level 3: Training From Feedback
If you control the model or a smaller specialist model, the collected trajectories can become training data:
- successful traces become demonstrations
- failed traces become negative examples
- user feedback becomes preference data
- judge scores become reward signals
- edited outputs become supervised targets
This can support supervised fine-tuning, preference optimization, reinforcement learning, or other post-training methods.
But I would not jump here too early. If the evaluation loop is weak, training will amplify unclear signals.
The order should be: measure reliably, diagnose accurately, validate fixes, and only then automate optimization.
Automation maturity
Level 1: Human-led, eval-assisted
Signals + traces + clusters -> human diagnosis -> human-approved fixes
Level 2: Semi-automated fix generation
Diagnostic categories -> candidate prompt/tool/eval changes -> human approval
Level 3: Training from feedback
Validated traces + preferences + judge signals -> post-training data
In a future post, I will go deeper into how failure traces can be used for semi-automated prompt optimization, eval generation, and post-training with Reinforcement Learning.
Common Failure Modes
Here are mistakes I have seen teams make when building AI evaluation systems.
Mistake 1: Only Evaluating Final Answers
Final-answer quality matters, but it is not enough for agents. If retrieval returned the wrong context, rewriting the final-response prompt may not help.
Mistake 2: Treating LLM-As-Judge As Ground Truth
LLM judges are useful, but they need calibration. They can be biased by wording, missing context, position, and rubric ambiguity.
Mistake 3: Optimizing One Metric Without Guardrails
If you optimize search recall too aggressively, the agent may search constantly. If you optimize concision too aggressively, it may omit important details. If you optimize confidence, it may hallucinate.
Every target metric needs guardrails.
Mistake 4: Building Clean Evals For Messy Products
Enterprise data is messy. Your evals should be messy too.
Include hard negatives, stale docs, partial relevance, duplicated content, and multi-document ambiguity.
Mistake 5: Not Assigning Ownership
Root-cause analysis is only useful if it maps to ownership.
Prompt issue. Retrieval issue. Tooling issue. Product gap. Model limitation. Evaluation bug.
Each category needs a path to action.
What Good Looks Like
A mature enterprise AI evaluation system should let the team answer:
- What are users unhappy about this week?
- Which failures are increasing?
- Which failures are prompt-tunable?
- Which failures require retrieval, tool, or product changes?
- Which evals are missing important user complaints?
- Which launch candidates improve target behavior without regressions?
- Which failures should become permanent regression tests?
- Which signals are strong enough to train or fine-tune on?
When you can answer those questions, evaluation becomes more than measurement. It becomes the operating system for product improvement.
Conclusion
Enterprise AI quality does not improve because a team has one better prompt, one better model, or one better dashboard.
It improves because the team builds a loop.
Production signals become traces. Traces become root-cause analysis. Root causes become targeted fixes. Fixes are validated against failure slices and regression sets. Shipped changes are monitored. New failures are added back into the evaluation set.
Over time, that loop becomes the memory of the product. It captures what the system has learned, where it has failed, and what it should never regress on again.
That is why enterprise AI evaluation should not be treated as a scorecard.
It should be treated as the operating system for product improvement.
Enterprise AI Evaluation Is Not a Scorecard. It Is a Feedback Flywheel. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.