
Multi-Model Code Review: How Developers Can Catch Better Bugs Without Drowning in AI Noise

One AI reviewer can miss the risky part of a pull request. Three AI reviewers can bury you in comments. The useful pattern is not “ask every model everything.” It is a small review system that routes models by lens, measures agreement, and leaves the final judgment to an engineer.
AI code review is moving from novelty to normal workflow. OpenAI positions Codex as a coding agent for real engineering work and high-signal review. Anthropic documents Claude Code as a tool that can read a codebase, edit files, run commands, automate reviews, and integrate with CI. GitHub has been pushing toward a world where different coding agents can work inside the same developer surface. The direction is clear: developers will not use one assistant forever. They will use several.
That sounds powerful until the first pull request gets five overlapping AI comments, three false alarms, one vague architecture warning, and a security note that might be real. At that point, “multi-model” stops sounding like better review and starts sounding like another inbox.
The trick is to treat multi-model code review as an engineering workflow, not a chat habit. You are not asking Codex, Claude, Gemini, Copilot, or any other model to be the ultimate reviewer. You are asking each one to inspect the same change through a narrow lens, return structured findings, and help you decide what deserves human attention.
Why Multi-Model Review Is Becoming a Real Developer Pattern
The demand is not hard to understand. Developers are already comparing coding agents in public: Which model catches harder bugs? Which one handles large codebases? Which one burns fewer tokens? Which one is better at security, tests, migrations, or framework-specific work?
The pain behind those questions is practical. Single-model review has blind spots. One model may be strong at architecture but weak at edge cases. Another may catch risky input handling but over-comment on style. A third may be good at test design but miss a subtle backward-compatibility issue.
Human code review has the same shape. A backend engineer, security engineer, and product-minded reviewer will notice different things. Multi-model review borrows that idea, but it needs guardrails because models are cheap enough to overuse and confident enough to sound right when they are not.
Mozilla.ai’s Star Chamber project is one useful signal that this pattern is maturing. It runs code or design reviews across multiple LLM providers, then groups feedback by consensus, disagreement, and individual observations. That framing matters: the value is not just “more opinions.” The value is calibrated confidence.
The goal of multi-model review is not to replace code review. It is to give the human reviewer a sharper starting point.
The Wrong Way: Ask Every Model to Review Everything
The simplest version of multi-model review is also the one most likely to fail. You paste the same diff into three models and ask, “Review this code.” Then you get three long answers with overlapping advice.
That workflow has four problems.
- No clear scope: The model comments on style, naming, architecture, security, tests, and product behavior in one pass.
- No severity contract: A small naming suggestion can look as important as a real data leak.
- No deduplication: Three models may describe the same problem in different words.
- No accountability: The reviewer still has to decide what is real, but now with more text to read.
That is how AI review turns into noise. It does not fail because the models are useless. It fails because the system gives them an open-ended job and no shared output format.
The Better Pattern: Lenses, Not Loudness
A better multi-model code review system starts with review lenses. Each lens gives a model a narrow job. You can use different models for different lenses, or run the same model with different prompts. The important part is separation.
For most engineering teams, three lenses are enough to start:
- Security lens: Look for auth bypasses, injection risks, secret handling, unsafe deserialization, insecure dependencies, and permission mistakes.
- Architecture lens: Look for broken boundaries, unclear ownership, hidden coupling, bad abstractions, and changes that violate project conventions.
- Test lens: Look for missing edge cases, weak assertions, flaky tests, untested failure paths, and migration coverage gaps.
You can add more later, such as performance, accessibility, data privacy, or API compatibility. But do not start with seven lenses. The first goal is to make the review useful enough that developers trust it.
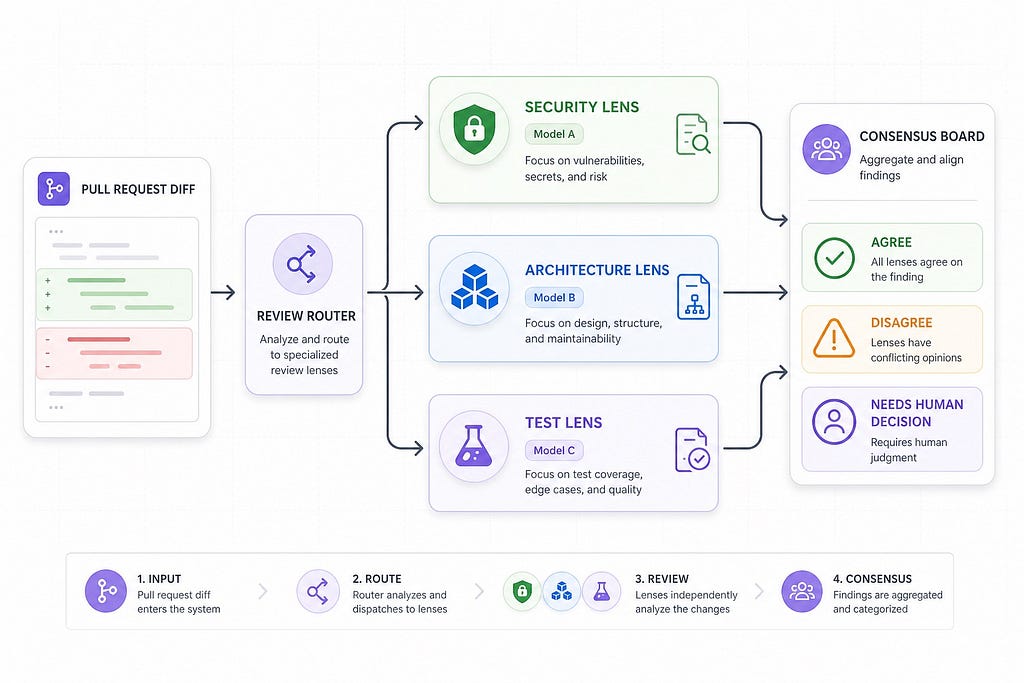
A Practical Architecture for Multi-Model Code Review
You do not need a large platform to test this pattern. A first version can be a script that collects a pull request diff, sends focused prompts to model providers, normalizes the responses, and writes a review summary. Later, you can wire it into GitHub Actions, GitLab CI, Buildkite, or your internal developer portal.
The architecture has six parts.
1. Diff Collector
The collector decides what the models see. This is more important than it sounds. A raw full diff may be too large, too noisy, or missing context. A good collector includes changed files, nearby surrounding code, related tests, package manifests, API contracts, and project instructions.
Keep the input small enough for repeatable review. If the PR is huge, split it by file group or risk area. A model reviewing 600 changed lines in one module will usually do better than a model skimming 8,000 lines across the whole repo.
2. Review Router
The router decides which lens runs. Not every PR needs every lens. A documentation-only change does not need a security review. A database migration probably needs compatibility and rollback checks. A login flow needs security and tests.
A basic router can use file paths and labels:
{
"rules": [
{
"when_changed": ["auth/**", "api/**", "middleware/**"],
"run_lenses": ["security", "tests", "architecture"]
},
{
"when_changed": ["migrations/**", "schema/**"],
"run_lenses": ["compatibility", "rollback", "tests"]
},
{
"when_changed": ["docs/**", "*.md"],
"run_lenses": ["clarity"]
}
]
}
This keeps cost and noise under control. It also makes the review feel less random because developers can predict which checks will run.
3. Model Assignments
Model choice should be boring and adjustable. Assign models by strength, cost, latency, and availability. For example, you might use a stronger reasoning model for architecture, a faster model for test suggestions, and a model with good security behavior for risky code paths.
Do not hard-code your company’s future around one provider. Use a small adapter layer so you can change model names, providers, temperature, timeouts, and token limits without rewriting the workflow.
4. Prompt Contracts
The prompt should tell the model what to ignore as clearly as what to inspect. This is where many teams lose the plot. A good AI reviewer should not comment on formatting if formatting is handled by CI. It should not suggest broad refactors unless the change creates a real risk. It should not leave motivational feedback. It should produce findings.
Here is a simple prompt contract for a security lens:
You are reviewing a pull request through a security lens only.
Focus on:
- authentication and authorization mistakes
- input validation and injection risks
- secret handling
- unsafe dependencies
- data exposure
- privilege boundaries
Ignore:
- naming preferences
- formatting
- broad refactors unrelated to security
- issues already caught by static analysis
Return JSON only:
{
"findings": [
{
"title": "short title",
"severity": "critical|high|medium|low",
"file": "path",
"line_hint": "line or function if known",
"why_it_matters": "plain-language risk",
"suggested_fix": "specific fix",
"confidence": "high|medium|low"
}
]
}
The JSON does not need to be perfect on the first try. Validate it, repair it if needed, and reject responses that do not fit the schema. The schema is what lets you deduplicate and compare findings across models.
5. Consensus Aggregator
The aggregator is the heart of the workflow. It groups findings into three buckets:
- Consensus findings: Multiple models or lenses flag the same issue. These deserve the fastest attention.
- Single-lens findings: One lens finds something specific. These may be valuable, but they need review.
- Conflicts: Models disagree about whether a change is risky. These should go to a human, not a bot fight.
The aggregator should not pretend to know the truth. It should help the reviewer decide where to look first.
6. Human Review Surface
The final output should be short. Developers should not have to read three model transcripts. Give them a concise summary, then link to raw model output only when needed.
A useful PR comment might look like this:
AI review summary
2 findings need human attention:
1. High confidence: possible authorization bypass in api/projects/update
- flagged by security and architecture lenses
- check owner_id validation before write
2. Medium confidence: migration lacks rollback coverage
- flagged by test lens only
- add downgrade test or document irreversible migration
No blocking action was taken automatically.
That last line matters. AI review should be advisory at first. Let CI block on deterministic checks: tests, lint, type checks, secret scanning, dependency policies, and known vulnerability scanners. Let AI point out judgment calls.

How to Keep AI Review From Becoming a Nit Machine
Most AI code review systems fail socially before they fail technically. Developers stop reading the comments because too many are low value. Once that trust is gone, even good findings get ignored.
Use these controls early.
Set a Comment Budget
Limit the number of findings per lens. For example: no more than three findings per lens, and no more than five findings total in the PR summary. This forces ranking.
Ban Style Comments
If a formatter, linter, type checker, or static analyzer can catch it, AI should not comment on it. The model can mention only issues that require reasoning about intent, context, or risk.
Require Reproducible Claims
A finding should include a file, a line hint, a reason, and a concrete fix. If the model says “this may cause issues” without naming the issue, drop it.
Track False Positives
Add a lightweight label system. When a reviewer dismisses a finding, mark it as false positive, not relevant, already covered, or useful but not now. Feed that back into prompt tuning.
Where Multi-Model Review Helps Most
This workflow is not worth running on every change. It shines when the cost of missing something is higher than the cost of extra review.
Use it for security-sensitive pull requests. Login flows, permissions, payment logic, tenant isolation, admin actions, file uploads, and public APIs are good candidates.
Use it for large refactors. Models can compare intent against implementation and ask whether the change preserved behavior across call sites.
Use it for migrations. Schema changes, data backfills, queue changes, and API version changes benefit from compatibility and rollback review.
Use it for unfamiliar code. If an engineer is reviewing a module they do not own, a multi-model summary can help them ask better questions.
Skip it for tiny changes. A typo fix, snapshot update, or low-risk copy change should not summon a review council.
How to Measure Whether It Works
Do not measure multi-model review by how many comments it creates. That rewards noise. Measure whether it changes outcomes.
Start with these metrics:
- Useful finding rate: The percentage of AI findings that reviewers accept, fix, or discuss seriously.
- False positive rate: The percentage of AI findings dismissed as wrong or irrelevant.
- Escaped issue rate: Bugs found after merge that a review lens should have caught.
- Review time impact: Whether AI summaries make human review faster or slower.
- Cost per useful finding: Total model cost divided by findings that changed the PR.
The most important number is useful finding rate. If fewer than one in five AI findings matter, your prompts are too broad, your routing is too aggressive, or your model output is not filtered enough.
A Starter Workflow You Can Implement This Week
If you want to test multi-model code review without building a platform, start with a manual but repeatable workflow.
- Pick one repository and one PR category, such as auth changes or database migrations.
- Create three review prompts: security, architecture, and tests.
- Run each prompt against the same diff using different models or different model settings.
- Normalize responses into the same JSON schema.
- Group similar findings manually for the first few runs.
- Post only the top three findings in the PR.
- Ask reviewers to label each finding as useful, noisy, or wrong.
After 10 to 20 pull requests, you will know more than any vendor comparison can tell you. You will know which lens helps your codebase, which model over-comments, which prompts need tightening, and whether the workflow deserves CI automation.
Common Mistakes to Avoid
Giving Models Authority They Did Not Earn
Do not let AI review block merges until you have measured it. Start advisory. Promote only narrow, high-confidence checks after repeated validation.
Mixing Objective Checks With Subjective Review
Use deterministic tools for objective rules. If a secret scanner, type checker, or unit test can decide the issue, do not ask a model to debate it.
Ignoring Repository Context
A model cannot enforce architecture it cannot see. Include project rules, ownership boundaries, API contracts, and known design decisions in the review context.
Chasing the “Best” Model Forever
The best model will change. Your workflow should survive that. Build adapters, evals, and prompt contracts so switching models is a config change, not a migration project.
The Real Promise: Better Human Judgment
Multi-model code review is not magic. It will not make bad engineering practices good. It will not replace maintainers who understand the product. It will not remove the need for tests, observability, incident review, or architecture ownership.
Its real promise is smaller and more useful: it can surface more of the review space before a human spends attention. One model can be a helpful assistant. Several models, used with structure, can act like a set of specialized reviewers that prepare the room before the actual decision.
The teams that get value from this will not be the teams that run the most AI. They will be the teams that ask narrower questions, measure usefulness, and keep humans in charge of judgment.
FAQ
What is multi-model code review?
Multi-model code review is a workflow where two or more AI models review the same code change, usually through different lenses such as security, architecture, tests, or performance. The findings are then grouped by agreement and reviewed by a human.
Is multi-model code review better than using one AI coding agent?
It can be better for risky or complex changes because different models catch different issues. It is not automatically better for small changes. Without routing, schemas, and noise controls, it can produce too many low-value comments.
Should AI code review block pull requests?
Not at first. AI review should usually be advisory until the team has measured its useful finding rate and false positive rate. Deterministic checks such as tests, type checks, lint, secret scanning, and vulnerability scanning are better merge blockers.
Which models should I use for multi-model code review?
Use the models that perform well on your own repository and risk profile. A practical setup might combine a strong reasoning model for architecture, a security-focused prompt on another model, and a faster model for tests. Keep model choice configurable.
How do I reduce noisy AI review comments?
Use narrow prompts, ban style comments, require structured findings, set a comment budget, deduplicate similar issues, and track reviewer feedback. If a finding does not include a specific risk and fix, it probably should not appear in the PR summary.
Can I use this with Codex, Claude Code, Copilot, Gemini, or open-source models?
Yes. The workflow is provider-agnostic if you use an adapter layer and a shared response schema. The exact model matters less than the review contract, routing logic, and measurement loop around it.
When should I skip multi-model code review?
Skip it for tiny, low-risk changes where normal CI and human review are enough. Use it for security-sensitive code, large refactors, migrations, unfamiliar modules, and changes where missing a subtle issue would be expensive.
Sources and Further Reading
- OpenAI Codex
- Claude Code documentation
- GitHub Copilot
- Mozilla.ai: The Star Chamber, multi-LLM consensus for code quality
- Microsoft Security: securing code, agents, and models across the development lifecycle
Multi-Model Code Review: How Developers Can Catch Better Bugs Without Drowning in AI Noise was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.