
Why Cost Per Token Is the Wrong AI Metric

Cost per token is an infrastructure metric. Cost per successful task is a business metric. Here’s the one equation that connects them — and why it flips the model you should deploy.
Every model you can call — GPT, Gemini, Claude, Qwen, DeepSeek — is sold on cost per token and paid for on cost per successful task. Those are not the same number, and the gap between them is where AI budgets quietly die. Modern systems increasingly route each request to a different model by complexity instead of using one model for everything — so which number you optimize is a live architectural decision.
The reason: a frontier model is priced against labor substitution, not compute. Its anchor isn’t a GPU-hour — it’s an engineer’s hourly rate. So once output can be wrong in a way a human must fix, the token bill becomes a rounding error next to the fix.
Cost per token is an infrastructure metric. Cost per successful task is a business metric.
The real cost of one attempt
TCO = C_token + P(fail) × L
C_token — tokens for one attempt. P(fail) — chance the output needs a human (won’t compile, breaks a schema, hallucinates a column). L — fully-loaded cost of that fix: hourly rate × hours to repair. A cheap model minimizes the first term and quietly inflates the second. The first is on your invoice; the second is on your payroll.
The equation that decides everything
Take any budget model B and any frontier model F. F is cheaper to run when C_F + P_F·L < C_B + P_B·L. Rearranged, the entire decision collapses to one line:
ΔC < Δp · L
ΔC = the token premium for F (positive, fixed, knowable). Δp = the failures F prevents. Pay the premium only when the labor it saves is worth more than it. That saved labor, Δp·L, is a reliability dividend — larger when the cheap model fails more and your engineers cost more. Nothing vendor-specific appears in it. It survives every price change the labs ship.
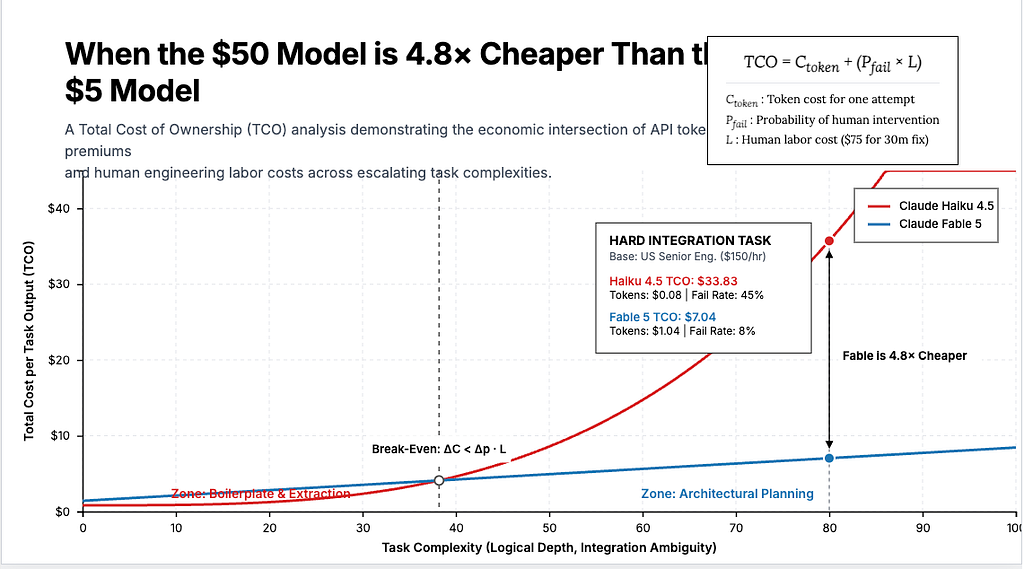
The budget model stays cheaper until complexity drives its failure rate high enough that Δp·L overtakes the token premium. Left of the break-even, route cheap; right of it, route frontier. The crossover isn’t a property of either model — it’s ΔC / L. (Dollar example uses Claude; the shape is universal.)
One instantiation (the only part that expires)
Plug in today’s frontier pair. Per Anthropic’s official pricing, Claude Fable 5 runs $10/$50 per MTok against Claude Haiku 4.5 at $1/$5 — a 10× gap, ~13× once you count that Fable’s newer tokenizer emits ~30% more tokens for the same text. One hard agentic turn (40k in / 8k out): budget ≈ $0.08/attempt, frontier ≈ $1.04 → ΔC ≈ $0.96.
Suppose — illustratively — the budget model fails 45% of the time and the frontier 8% (Δp = 0.37), with a US senior at $150/hr, 30-min fixes (L = $75):
Token cost Expected rework TCO Budget model $0.08 0.45 × $75 $33.83 Frontier model $1.04 0.08 × $75 $7.04
The frontier model is 4.8× cheaper per finished task while costing 13× more per token. Change the pricing next quarter and only this box changes — the equation doesn’t.
The break-even is set by your payroll, not the model
Solve for the gap F must clear: Δp* = ΔC / L. It moves violently with L — a fact about where your engineers sit, not about the models:
Engineer Fix time L Δp* US senior ($150/hr) 60 min $150 0.6 pp US senior ($150/hr) 15 min $37.50 2.6 pp Offshore senior (~$15/hr) 30 min $7.50 12.8 pp Offshore senior (~$15/hr) 15 min $3.75 25.6 pp
A US team on a slow-to-debug task justifies the frontier model at a 0.6-point edge — almost always cleared. A $15/hr team with fast fixes needs 25.6 points — cleared only on genuinely hard work. Same models, same prices, opposite decision. Any “always use the frontier model” take that doesn’t name a labor rate is only true in San Francisco.
Where it breaks (concede it or don’t publish)
- On raw tokens, the budget model wins ~13×. The whole case rests on Δp·L being large.
- On easy tasks, the budget model wins outright — both succeed ~98% and a failed output costs seconds, so L collapses too — which is why the crossover exists.
- The budget model is rarely the real rival. Nobody routes a hard task to the cheapest model; the mid-tier one usually dominates both. The extreme framing isolates the mechanism.
- Δp is yours to measure. Benchmarks point the way but are workload-specific. The equation is the deliverable; the parameters come from your evals.
Deploy on complexity, not on price
The strategy is mechanical and the opposite of what the sticker suggests. Route the 90% boilerplate — routine SQL, CRUD, extraction — to the cheap model, where P(fail) and L are both small. Bring in the frontier model as the architect: to plan the system, resolve the ambiguous integration, and write the tests that make the cheap models safe — then shut its budget off.
Using a premium model to write unit tests burns money. Using a cheap model to architect a migration burns engineering weeks — and that fire doesn’t hit your API bill until the sprint is already gone.
Cost per token is what you’re billed. Cost per successful task is what you pay. Optimize the one that lands on payroll.
Prices from Anthropic’s official docs (Fable 5 $10/$50, Haiku 4.5 $1/$5 per MTok; ~30% tokenizer inflation on Fable). Failure rates and labor costs are labeled assumptions — swap in your numbers and ΔC < Δp·L still decides the call.
Why Cost Per Token Is the Wrong AI Metric was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.