
Reflection Agent Architecture: Eliminating LLM Hallucinations via Tool-Grounded Iterative…
Reflection Agent Architecture: Eliminating LLM Hallucinations via Tool-Grounded Iterative Self-Verification
A Technical Design Paper Covering Prompt Architecture, Multi-Agent Design, and LangGraph Integration
Large language models (LLMs) are increasingly deployed in production systems where response accuracy, factual grounding, and reasoning quality are critical requirements. One-shot generation the conventional approach of producing a final response in a single inference pass provides no mechanism for self-correction and offers no guarantee that the output is factually grounded. This paper presents the design and rationale of a Reflection Agent architecture that separates response generation into three distinct phases: Generate, Validate + Critique, and Refine, orchestrated in an iterative loop with external verification.
A central question addressed in this paper is how a language model can evaluate its own output without domain-specific training on a labeled dataset. We demonstrate that evaluation quality depends not on separate training but on the verification source employed during the critique phase. A model critiquing its own output using prompt instructions alone what we term single- shot internal critique represents weak reflection and is subject to a phenomenon we name consistent hallucination: the model fails to detect its own errors because those errors are internally coherent with its world-model. By contrast, grounding the critique in external evidence
SQL database re-queries, retrieved documents, and rule validators produces strong reflection that can detect and correct factual errors the original generation introduced.This paper makes a three-way distinction that most existing literature collapses into two: (1)single-shot prompting with no critique, (2) single-shot prompting with internal chain-of-thought
critique, and (3) multi-phase multi-agent reflection with external verification between phases. We show precisely where approach (2) fails relative to (3), and we provide concrete prompt structures for each approach to make the mechanical differences visible. The multi-agent design assigns opposing objectives to the generator and critic agents thoroughness versus scepticism and gives the critic access to external data the generator never saw, which is the structural reason the multi-agent approach catches errors that internal critique cannot. The paper concludes with an analysis of LangGraph as the recommended orchestration framework, detailing how its stateful graph model, conditional routing, native loop support, and observability features map directly to the requirements of the reflection pipeline.
Key Contributions
1. Three-way distinction: single-shot / single-shot with internal critique / multi-phase multi-agent reflection
2. Naming and definition of consistent hallucination why internal critique has a reliability ceiling
3. Concrete prompt structures for all three approaches showing mechanical differences
4. Formal characterisation of weak vs strong reflection based on verification source type
5. Design of a three-phase Generate-Critique-Refine pipeline with SQL re-fetch grounding
6. Mapping of LangGraph primitives to multi-agent reflection agent requirements
The Problem with One-Shot Generation
Standard LLM deployments operate in a one-shot manner: a user query is combined with retrieved context, passed to the model, and a response is returned directly to the user. This architecture is simple and low-latency, but it has a fundamental limitation the model has no opportunity to review what it has produced. Errors introduced during generation, whether factual hallucinations, incorrect numerical values, mismatched scenario reasoning, or incomplete logic, are delivered directly to the user without any internal check. For low-stakes applications such as general-purpose chatbots or FAQ systems, this is acceptable. But for enterprise use cases marketing campaign analytics, financial reporting, legal document summarisation, medical question answering, or code generation factual
accuracy is non-negotiable. A one-shot system that confidently states an incorrect metric or draws the wrong conclusion from retrieved data erodes user trust rapidly.
Three Approaches to LLM Response Generation
The literature on LLM response quality typically distinguishes two approaches: one-shot generation and reflection-based generation. This paper argues that this binary is insufficient and that three approaches must be distinguished, because the failure modes of approach two arefrequently misattributed to approach three:
Single-Shot Prompting: A single prompt produces a single response. No critique,no revision. The model operates in pure generative mode. Fast, simple, and appropriate for low-stakes text generation tasks.
Single-Shot with Internal Critique: A single prompt instructs the model to generate a draft, critique that draft, and produce a final revised version all within one continuous token stream. This is sometimes called chain-of-thought self-refinement. It improves output quality compared to approach one for pure text tasks, but it has a structural limitation that approach
three resolves: the critique cannot pause generation to fetch external data, and the critique operates on the same internal world-model that produced the error in the first place.
Multi-Phase Multi-Agent Reflection: Separate LLM calls handle generation,
critique, and refinement. Each call operates on a clean context with a role-specific system prompt. Between the generation call and the critique call, external tool calls database re- queries, API calls, rule validators fetch ground truth evidence that the critique uses to evaluate the draft. This is the architecture described in detail in this paper.
The Reflection Hypothesis:
The reflection hypothesis states that an LLM can improve the quality of its own output by evaluating it against explicit criteria and using that evaluation to produce a revised version. This idea has its roots in self-consistency prompting, chain-of-thought reasoning, and constitutional AI, but takes a more operational form in agentic architectures where evaluation and refinement are separate, observable, and auditable steps.
The key insight is that generation and evaluation activate different reasoning patterns within the same model. When prompted to produce an answer, the model operates in a generative mode completing a plausible continuation of the context. When prompted to critique an existing
answer, the model operates in an analytical mode scanning for contradictions, missing information, factual inconsistencies, and logical gaps. These two modes are complementary, and the second mode often catches errors that the first introduces.
An analogy from human cognition is instructive: a student writing an exam answer and a teacher marking that same answer use the same underlying knowledge, but different objectives and different attention patterns. The teacher mode is more likely to notice that a formula was applied to the wrong scenario, or that a key condition was not stated. Similarly, the LLM in critique mode is more likely to notice that a retrieved statistic was cited out of context provided it has access to the original data to compare against.
The Core Question: Evaluation Without Training:
A natural question arises: if the same model that generated the response is also being asked to evaluate it, how can it determine correctness without having been trained on domain-specific labeled data? This question motivated much of the analysis in this paper. The answer has two parts. First, during pretraining and reinforcement learning from human
feedback (RLHF), the model has been exposed to vast quantities of correct and incorrect answers, logical inconsistencies, factual errors, and evaluative language. This means it has internalized patterns of what good answers look like, even without task-specific training. Second, and more importantly, the reliability of critique depends on the external evidence the critique phase has access to. A model that critiques using only its parametric memory is limited by the accuracy of that memory and is vulnerable to consistent hallucination. A model that
critiques by re-querying a database and comparing the draft against the actual query results is grounded in truth that does not depend on the models internal knowledge.
Self-Consistency and Chain-of-Thought:
Self-consistency prompting (Wang et al., 2022) demonstrated that sampling multiple reasoning chains and selecting the most consistent answer improves LLM performance on reasoning tasks. Chain-of-thought prompting (Wei et al., 2022) showed that asking the model to reason
step-by-step before giving an answer reduces errors on arithmetic and multi-step problems.
Both techniques exploit the same phenomenon: slower, more deliberate generation processes produce better outputs than fast single-step generation.
The reflection agent extends this logic to a multi-call architecture. Rather than including critique and refinement as part of the same generation pass, they are separated into distinct inference calls, each with its own context, objective, and verification mechanisms. This separation enables external tool calls between phases a capability that single-pass chain-of-thought cannot provide.
Constitutional AI and Critic Models :
Anthropics Constitutional AI (Bai et al., 2022) introduced the concept of using a model to critique its own outputs against a set of constitutional principles and then revising the output to comply. This is an early instantiation of the generate-critique-refine loop applied to safety. The
key difference in the architecture described here is that the critique phase is grounded in domain-specific factual verification rather than constitutional principles, and that the loop is embedded in a production inference pipeline rather than a training procedure.
Retrieval-Augmented Generation :
Retrieval-Augmented Generation (RAG) addresses the factual limitation of LLMs by retrieving relevant documents or database records before generation and including them in the model context. RAG reduces hallucination by ensuring the model has access to accurate information
at generation time. The reflection architecture described here builds on RAG by also performing retrieval during the critique phase specifically, re-querying the database to verify that numerical claims in the draft match actual database values. This combines the benefits of RAG with an
additional verification pass that RAG alone cannot provide.
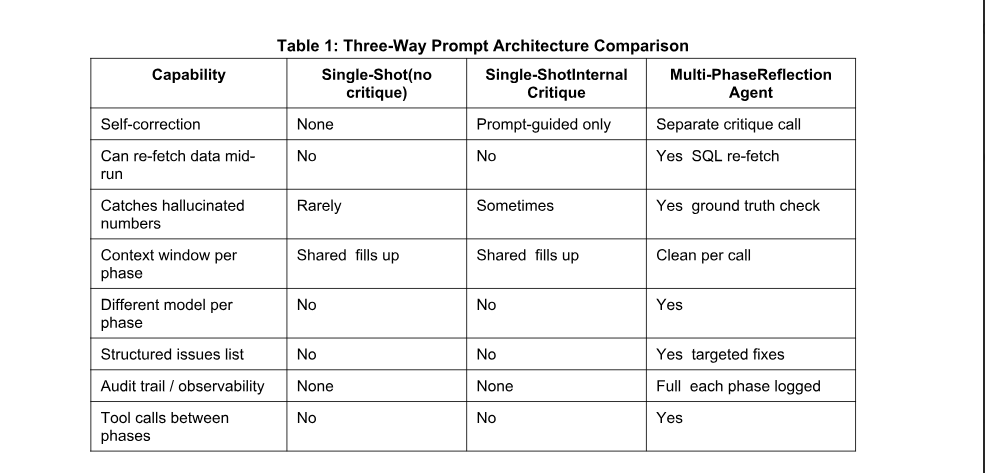
Prompt Architecture: Three Approaches Compared
Approach 1 Single-Shot Prompting
In single-shot prompting, one prompt produces one response. The structure is minimal:
This approach is appropriate for simple, low-stakes queries where a plausible answer is sufficient. Its failure mode is silent: when the model hallucinated a number or misread a retrieved value, nothing catches it. The error is delivered as the final response.
Single-Shot with Internal Critique :
Single-shot internal critique adds a chain-of-thought instruction that asks the model to critique its own draft and produce a revised answer all within one continuous token stream. This is the most commonly proposed alternative to full reflection agents, and its limitations are frequently
underestimated.This approach does improve output quality for pure text generation tasks. However, it has two structural limitations that no amount of prompt refinement can overcome:
The critique cannot pause to fetch new data. If the model stated that CTR was 4.2% in the draft and the actual database value is 2.8%, the critique step has no access to the database. It can only evaluate whether 4.2% sounds plausible given what the model generated which it does, because the model generated it.
The critique operates on the same world-model that produced the error. This is the consistent hallucination problem described in Section 3.4. The model does not know it hallucinated, so the hallucination passes internal review.
Approach 3 Multi-Phase Multi-Agent Reflection :
The multi-agent approach separates generation, critique, and refinement into three distinct LLM calls with different system prompts and different inputs. The critical addition is the SQL re-fetch between calls external data that the critique agent uses to evaluate the draft against ground truth.
Three structural properties of this design are not achievable in approaches 1 or 2:
Opposing objectives: the generator is instructed to be thorough, the critic is instructed to be sceptical. These opposing objectives mean the critic is not trying to validate what the generator produced it is trying to find fault with it. This is the multi-agent equivalent of having a separate editor review a writers work.
External ground truth for critique: the critic receives the SQL re-fetch results that the generator never saw. When these results contradict a claim in the draft, the critic has definitive evidence of an error not an opinion about plausibility.
Targeted refinement: the refine agent receives a structured issues list with specific corrections. It does not regenerate the full response from scratch, which would risk introducing new errors. It fixes exactly what the critic identified and preserves everything else.
Reflection Agent Architecture :
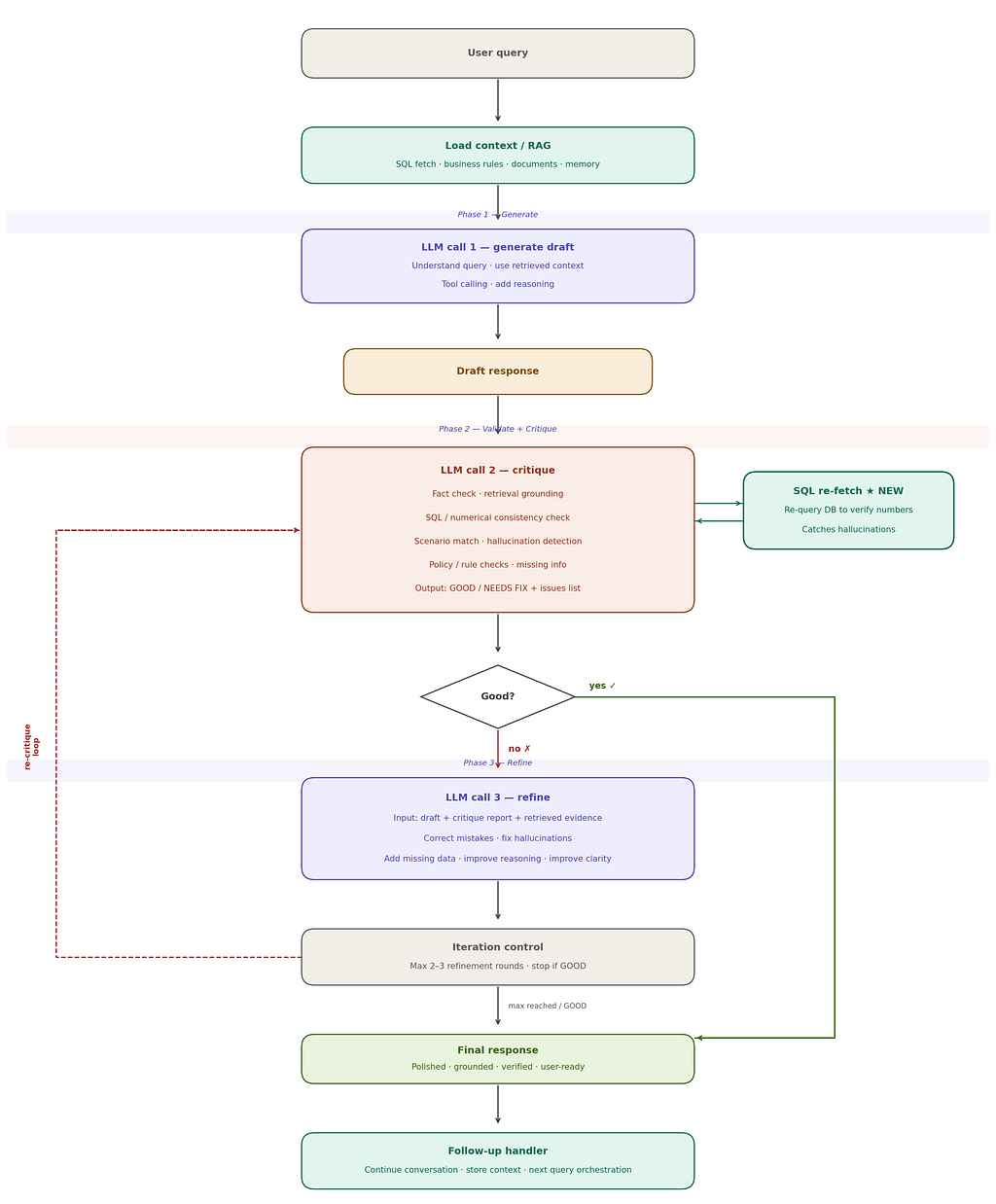
A Three-Phase Architecture:Generate → Critique→Refine
The practical version of this looks like a pipeline with three distinct phases, run in a loop:
Phase 1 — Generate. The model receives the query plus retrieved context (think: RAG, business rules, prior conversation memory) and produces a structured draft — not just an answer, but the answer plus the specific data points it cited and the reasoning it used to get there. That structure matters: you can’t critique a claim you can’t trace back to its source
Phase 2 — Validate + Critique. This is the phase that actually does the work. Two things happen together here: the system re-runs the relevant database queries from scratch (not relying on the model’s memory of the first fetch), and a separate LLM call compares the draft against this freshly verified data. The critique checks for factual accuracy, whether claims are actually grounded in retrieved evidence, whether the model correctly understood the scenario, and whether anything important got left out. The output isn’t a vague “looks fine” — it’s a structured verdict (GOOD or NEEDS FIX) plus a specific list of issues, each one pointing to the exact claim, the contradicting evidence, and a suggested fix.
Phase 3 — Refine. If there’s a fix needed, a third call takes the original draft, the issue list, and the verified data, and makes targeted corrections — not a full rewrite. This constraint matters: regenerating from scratch risks introducing new errors while fixing old ones. Targeted correction preserves what was already right.
This whole loop runs with a cap — typically 2 to 3 rounds — so a stubborn disagreement between the critique and refine steps doesn’t spiral into an infinite loop.
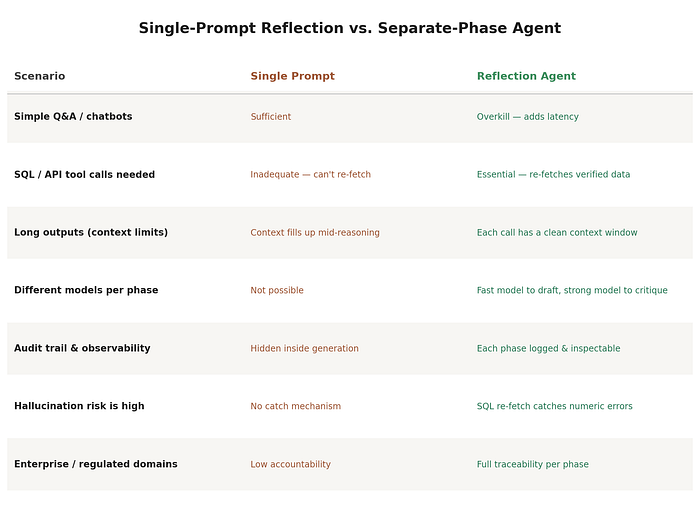
Weak vs Strong Reflection:
Not all reflection agent designs are equally reliable. The quality of the critique phase is determined by the verification source used. Below Figure summarises the trust levels associated with different critique approaches.

The fundamental principle is: reflection is only as trustworthy as its verification source. A reflection pipeline that relies exclusively on LLM self-judgment including single-shot internal critique is weak reflection. It is more reliable than single-pass generation but still vulnerable to consistent hallucination. A reflection pipeline that anchors its critique in real database queries,retrieved documents, and rule validators is strong reflection it can detect specific factual errors and provide the evidence needed to correct them.
When does this complexity actually pay off?
Not every use case needs this. A single prompt that says “answer, then critique yourself, then revise” works fine for low-stakes chatbots and simple Q&A — and it’s a lot cheaper and faster to build.
The dividing line is whether the critique phase needs to do anything external. A single prompt is one continuous stream of tokens — it can’t pause mid-generation, go query a database, and come back with the answer. A multi-phase architecture can. So separate phases become necessary specifically when:
- The critique needs to re-fetch data (SQL, API calls) to verify numbers
- The output is long enough that context window degradation becomes a real risk
- You want a cheaper/faster model handling generation and a stronger model handling critique
- You need an audit trail — each phase logged and inspectable on its own, which matters a lot in regulated or enterprise settings
For a marketing analytics dashboard reporting campaign metrics to executives, every one of those conditions applies. That’s the use case this architecture is actually built for.
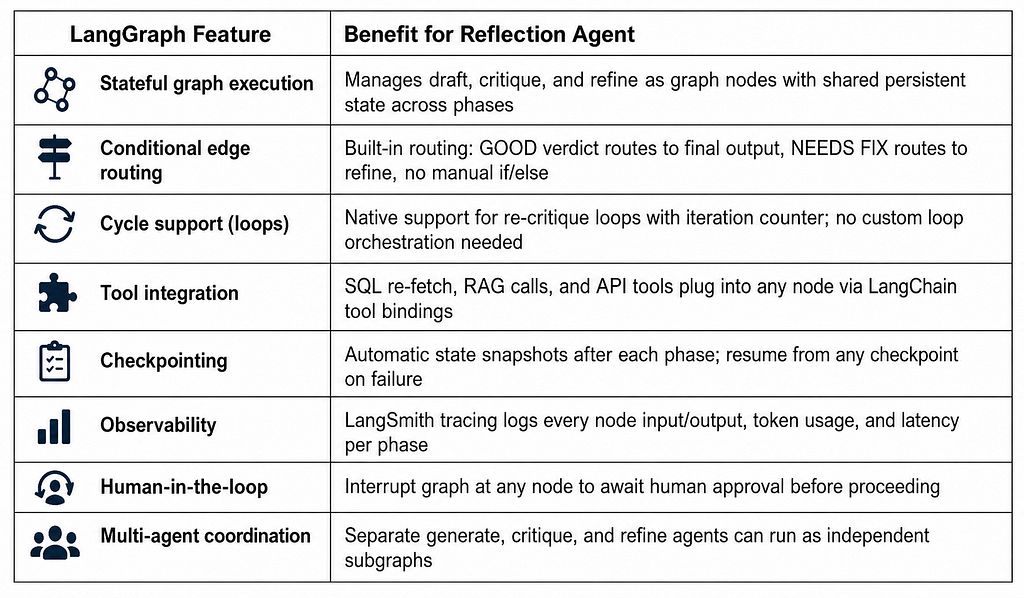
Why LangGraph fits this naturally
LangGraph is an open-source orchestration framework built on LangChain that models agentic workflows as stateful directed graphs. Each node represents a processing step an LLM call, a tool execution, or a control decision. Edges between nodes can be conditional, enabling routing
based on state. The framework natively supports cycles, making it well-suited to iterative refinement loops.
If you’re building this, LangGraph (the orchestration layer built on LangChain) maps onto the architecture almost one-to-one. It models the whole pipeline as a stateful graph: each phase is a node, the verdict decision is a conditional edge (GOOD routes to final output, NEEDS FIX routes back to refine), and the refinement loop is handled by LangGraph’s native cycle support rather than custom orchestration code.
A few features that make this less painful in production: automatic checkpointing after each node (so a failed SQL call doesn’t mean starting over), native tracing through LangSmith (every draft, critique, and refinement gets logged with full input/output and latency), and built-in support for pausing the graph to bring a human into the loop — useful if a critique flags something serious enough to warrant manual review before it goes further.
The reflection agent architecture maps directly onto LangGraph primitives. Table details the correspondence LangGraph Features and Reflection Agent Benefits.
Open Gaps and Future Directions
The architecture described in this paper represents a production-ready design, but several gaps remain that represent directions for future development.
- Critique rubrics are still mostly hand-written. Defining what separates a “4” from a “5” on dimensions like completeness or scenario match is domain work, not just engineering work — it needs input from people who actually know the data.
- The critic is still a prompted LLM, not a trained model. A reward model trained on labeled human critique examples would likely be more consistent than prompt-based judgment, especially on subjective dimensions. That’s future work, not current state.
References
Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., … & Kaplan, J. (2022). Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862.
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., … & Clark, P. (2023). Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing
Systems, 36.
Shinn, N., Cassano, F., Labash, A., Gopinath, A., Narasimhan, K., & Yao, S. (2023). Reflexion:Language agents with verbal reinforcement learning. Advances in Neural Information
Processing Systems, 36.
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., … & Zhou, D. (2022). Self-
consistency improves chain of thought reasoning in language models. arXiv preprint
arXiv:2203.11171.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., … & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information
Processing Systems, 35, 24824–24837.
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., … & Kiela, D. (2020).Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459–9474.
LangChain. (2024). LangGraph: Build stateful, multi-actor applications with LLMs.
https://github.com/langchain-ai/langgraph
Reflection Agent Architecture: Eliminating LLM Hallucinations via Tool-Grounded Iterative… was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.