
The 10 Best AI Models in 2026, and Why the Most Powerful One You Can’t Use
There is no single best AI model, and anyone who tells you otherwise is selling something. There is a top tier locked in a three-way fight, a strange tier of models too capable or too restricted to slot neatly anywhere, and a fast-rising open tier that keeps embarrassing the price of the closed ones. Here is the honest map of the ten that matter, what each does best, where each one lacks, and a quick comparison table at the end of every tier.

Every few weeks lately, a new model launches claiming to be the best, and the truth is that “best” has stopped meaning anything useful. The field has split into models that are genuinely great at different things, priced differently, and in some cases available to completely different people. A model that tops the overall charts can lose badly on the specific task you care about, and the most capable model in the world right now is one most people are not even allowed to use.
So the useful way to look at the field is not a single ranking but tiers, groups of models that play similar roles, with honest notes on what each is for and where each falls down. What follows is the state of the top ten as it actually stands, sorted into four tiers, each capped with a comparison table. Treat every vendor’s own benchmark with suspicion, lean on the independent ones, and remember throughout that the right model is the one that fits your job, not the one at the top of someone’s table.
Tier one, the frontier three
At the very top sit three models from three companies, separated by small enough margins that which one leads depends on the week and the test. This is the tier you reach for when the work is hard and you want the best general capability money can buy.
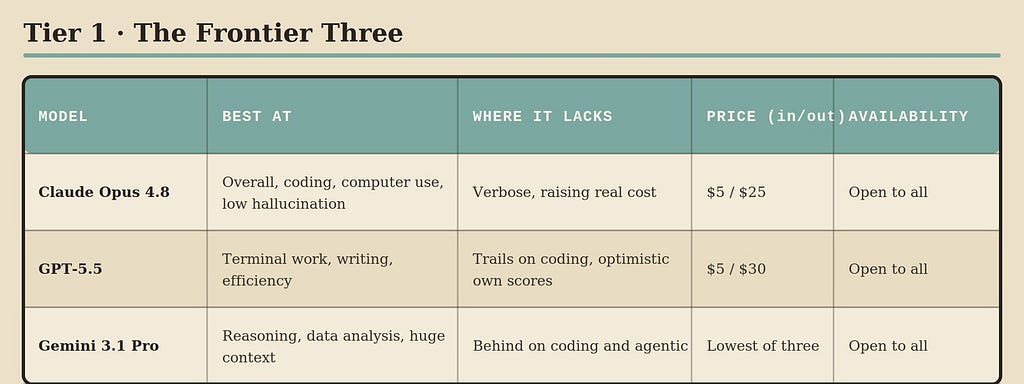
Claude Opus 4.8. As of now, it’s the strongest overall on the most-cited independent composite, where it became the first model to clear a clear margin above the rest of the field. Its real standout is coding, where it leads the standardized agentic benchmark by a wide margin over the other two in this tier, and it’s the best at computer-use tasks, the kind where the model actually operates software on your behalf. It also hallucinates less than its rivals, which matters more than any headline score for anything you ship. Where it lacks is verbosity. It tends to use more tokens than it needs to, so even though its per-token price is moderate, your actual bills can run higher than the sticker suggests. It’s the sensible default for serious work.
GPT-5.5. It sits a hair behind on the overall composite but wins outright in specific places. It’s the leader on terminal-native tasks, the command-line automation work where it beats everyone, and it’s widely considered the best of the group at creative writing. Its quiet superpower is efficiency. It finishes comparable work in fewer tokens and fewer steps than the Claude models, which makes its real cost-per-result among the best at the frontier, and its coding intelligence is delivered at roughly half the cost of competing top coders. Where it lacks is that on raw coding and computer-use benchmarks it trails Opus, and its own reported scores tend to sit above what independent trackers find, so its numbers deserve the same skepticism as everyone’s. It’s the pragmatist’s frontier pick.
Gemini 3.1 Pro. It rounds out the tier and owns a different hill. It’s the leader on pure reasoning and data analysis, topping the hardest abstract-reasoning and graduate-level science benchmarks, and it carries a context window far larger than anything else here, into the millions of tokens, which makes it the natural choice for working across enormous documents or codebases at once. It’s also the cheapest of the three closed leaders and strongly multimodal. Where it lacks is coding and agentic work, where it sits behind both Opus and GPT-5.5 on the standardized tests. It’s the model for reasoning, long-context, and analysis rather than for building software.
The honest summary of tier one is that the gap between the three is small, and the choice should be made on the axis you care about. There’s no wrong pick here, only a wrong pick for your specific task.
Tier two, the gated and the specialized
This is the strange tier, the one that breaks any clean ranking, because it holds models that are arguably more capable than tier one on certain tasks but that you may not be able to use at all.
Claude Fable 5. On the available evidence, it’s the most capable model in the world at hard, long-running agentic coding, posting a score on the standardized coding benchmark well above even the frontier three, and pulling further ahead the longer and more complex the task runs. If raw capability on difficult software engineering were the only thing that mattered, Fable would top this entire article. But it comes with two defining catches. It’s the most expensive major model by a wide margin, priced well above the tier-one models. And more importantly, it’s not freely available the way they are. It ships with significant access restrictions, and its fullest configuration is gated behind vetting that most individuals and many companies cannot get through. So its place in the field is genuinely odd. It may be the best, and for most readers that’s close to irrelevant, because a model you can’t access isn’t actually an option.
Claude Mythos 5. It’s the purest expression of that oddity. Under the hood it’s the same model as Fable, with its safety restrictions lifted, and it’s available only to a small set of vetted government, security, and infrastructure partners through a closed program. It posts the highest scores anywhere on certain hard tests, but it’s not a product you can buy at any price as an ordinary user. Its inclusion here is less a recommendation than a marker of where the ceiling actually is, because the most capable version of a frontier model is now something deliberately kept out of public hands. Where it lacks, for you, is simply existence as an option. You almost certainly can’t use it, and that’s the entire point of how it was released.
The lesson of tier two is that capability and availability are different things, and the field has started to separate them on purpose. The practical best model and the absolute best model are no longer the same model.

Tier three, the open-weight chasers
Below the closed frontier sits the most exciting tier for many builders, the open-weight models you can download, run yourself, and use without sending your data to anyone. They haven’t caught the very top, but they’ve closed the gap enough that for a great deal of real work, paying frontier prices is hard to justify.
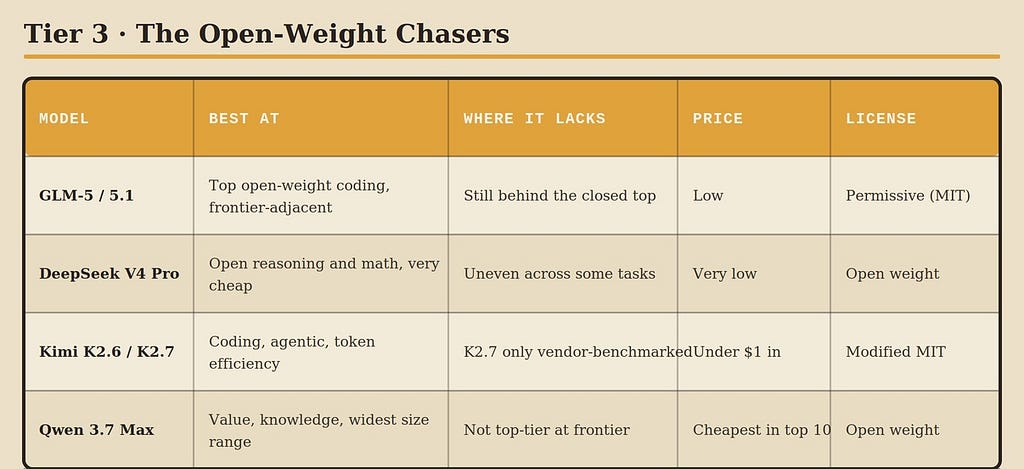
GLM-5 and GLM-5.1, from Zhipu, currently lead the open-weight field on the independent cross-comparisons, with strong coding scores approaching the lower end of the closed frontier, released under a permissive license. They’re the open model to beat right now, and the first thing to test if you want frontier-adjacent capability on your own hardware.
DeepSeek V4 Pro is the other open heavyweight, scoring at or near the top of the open tier on independent benchmarks, particularly strong on reasoning and math, and a genuine threat to the closed models on those axes at a fraction of the cost. Its lineage has repeatedly reset expectations of how good an open model can be.
Kimi K2.6, and the brand-new K2.7-Code from Moonshot are the coding-and-agentic specialists of the open tier, with K2.6 scoring strongly on independent comparisons and the just-released K2.7-Code pitching itself on token efficiency, using markedly fewer reasoning tokens to do the same work. The important caveat on K2.7 specifically is that its benchmarks so far are all the vendor’s own, with no independent results yet, so treat its claims as promising rather than proven.
Qwen 3.7 Max, from Alibaba, is the value champion of the group and the cheapest model in the entire top ten, while still posting frontier-adjacent scores on knowledge and reasoning. Alibaba also ships the widest range of sizes, which makes the Qwen family the most flexible if you need to match a model to specific hardware.
Where this whole tier lacks is at the very top end and in consistency. The open models are genuinely close on average, but the most capable closed models still hold the top of the verified charts, and open models can be more uneven across tasks and more dependent on you having the toolchain to run them well. The gap has narrowed dramatically. It hasn’t closed. But for cost-sensitive work, private deployment, or anyone who wants to own their stack, this tier is where the value lives.
Tier four, the ecosystem incumbent
The last entry stands a little apart, included not for topping benchmarks but for mattering in a way scores do not capture.
Meta’s Llama 4, in its Scout and Maverick versions, has genuinely fallen behind the frontier on raw capability, scoring below where you’d expect given the attention it gets, and below several models in the open tier above it. On a pure benchmark basis, it no longer belongs in a best-of conversation. But it earns its place for two real reasons. It has by far the largest fine-tuning and tooling community of any open model, two years of accumulated integrations, tutorials, and infrastructure that make it the path of least resistance for many teams. And the Scout version carries an enormous context window, useful for long-document work. Where it lacks is straightforward, it’s simply not as capable as the open models that have passed it, and it carries a more restrictive license than the cleanly-permissive alternatives. It’s here as the incumbent default, the safe and familiar choice whose ecosystem advantage sometimes outweighs its benchmark deficit, not as a frontier contender.

How to actually use this
Step back from the ten and the practical picture is simpler than the list suggests.
For most serious work, you want a tier-one model, and you choose among the three by task: Opus for coding and computer use and low hallucination, GPT-5.5 for terminal work and efficiency and writing, Gemini for reasoning and long context. If you need the absolute top end of coding capability and you happen to be able to access it and afford it, tier two’s Fable is the ceiling, with the heavy caveat that most people cannot get it. If you’re cost-sensitive, care about privacy, or want to run models yourself, tier three’s open models now deliver enough capability that frontier prices are hard to justify for a lot of tasks. And if you value a mature ecosystem and easy tooling over raw scores, Llama remains the comfortable default even as others have passed it.
The single most important habit is to stop asking which model is best and start asking which model is best for this. The ten here are not rungs on one ladder, they’re tools with different strengths, different prices, and in tier two’s case, different rules about who is even allowed to hold them. The field rewards people who match the model to the work, and quietly penalizes everyone still chasing a single champion that, on close inspection, does not exist.
One last note that applies to every tier. The numbers in this space move monthly, vendors grade their own homework generously, and the only scores worth real trust are independent and run under identical conditions. Take any single benchmark, including the ones here, as a snapshot rather than a verdict, run your own tests on your own work where it matters, and revisit the field often, because the model that fits best today may be outranked by next month’s release. That churn isn’t a flaw in this guide. It’s the defining feature of the moment.
If you use several of these in different places, the comment worth leaving is your routing logic: which model you reach for on which job, and what made you switch. That real-world breakdown is more useful to the next person than any leaderboard.
Resources
- The Artificial Analysis model index, the independent composite behind much of the tier-one ranking: https://artificialanalysis.ai/models
- BenchLM, for independent cross-comparisons across the open-weight models: https://benchlm.ai
- SWE-Bench, the standardized agentic coding benchmark used throughout: https://www.swebench.com
- The Hugging Face Open LLM Leaderboard, for the open-weight tier specifically: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
- LMArena, for real-world human-preference rankings as a cross-check on benchmarks: https://lmarena.ai
The 10 Best AI Models in 2026, and Why the Most Powerful One You Can’t Use was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.