
PyAgent: A Design Pattern Orchestrator for Multi-Agent LLM Systems
Kubernetes for your Multi-Agent LLM System
Someone builds a “router” that classifies incoming requests and sends them to the right specialist agent. Two weeks later, a different team builds a “dispatcher” that does almost the same thing. A month after that, someone else ships a “coordinator”. It’s mostly the similar idea, different name, different bugs. Meanwhile, nobody can version these systems, test them without hitting the real API, or debug what actually happened when a run goes wrong under one eco-system.
Engineers working with frameworks like LangGraph, CrewAI, AutoGen which are industry standards that give you raw primitives but leave everything else to you. You get graph nodes and message passing. You don’t get a shared vocabulary of named patterns, a way to declare your system as code, cost visibility, memory management, or an observability layer that knows what a “Debate” pattern is versus a generic span.
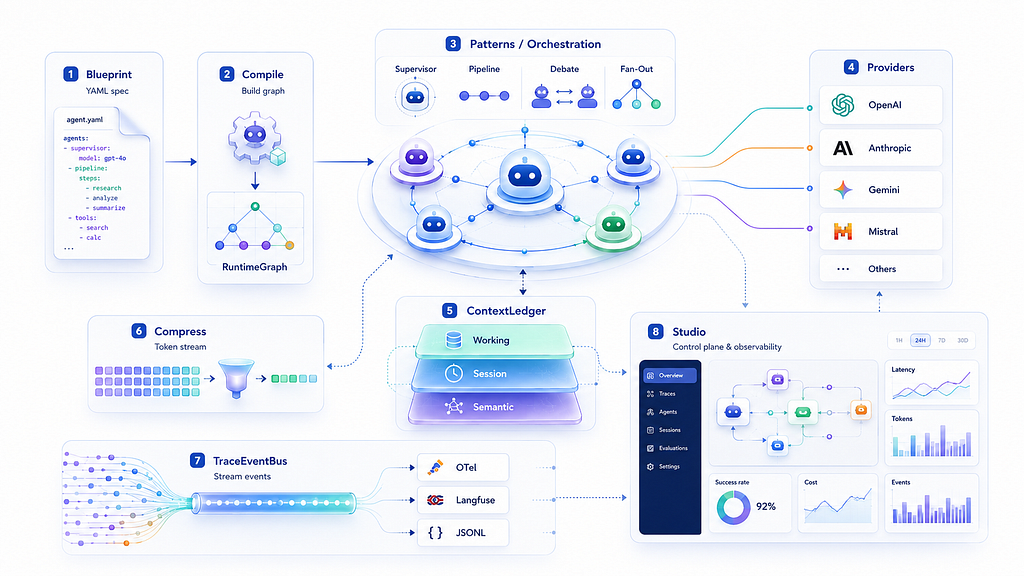
PyAgent fills all of it. It’s eight packages that form a coherent stack, from YAML specification through to a visual control plane. You can use one package or all eight. This is what the full stack looks like and how each piece fits.
The Architecture
The intended flow is:
- Specify — declare agents, workflows, providers, and contracts in a YAML blueprint
- Compile — BlueprintCompiler transforms the spec into a runnable RuntimeGraph
- Orchestrate — Patterns coordinate agent collaboration (Pipeline, Supervisor, Debate…)
- Provide — Provider registry handles fallback chains, cost routing, and capability negotiation
- Remember — ContextLedger maintains three-tier memory across agents and turns
- Compress — CompressMiddleware trims inter-agent token transfer and enforces budgets
- Trace — TraceEventBus collects structured events from agents, patterns, and providers
- Observe — Studio visualises traces, costs, compliance, and provider health in real time
Let’s walk through each layer.
Blueprint — your agent system as code
The standard way to write multi-agent systems in Python is to wire agents together in code. That works until you need to version them, review them in a PR, run them in CI without hitting real APIs, or hand the system to a team member who has to grep through call sites to understand how things connect.
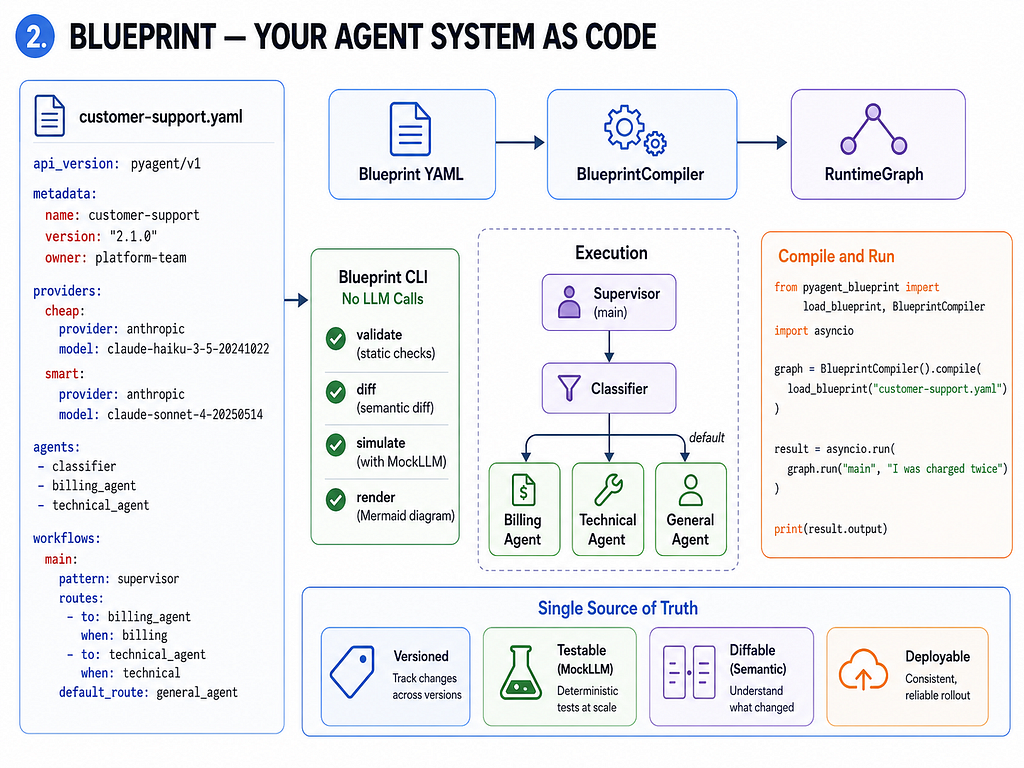
Blueprint separates what your system does — the YAML spec — from how it runs — the compiler and runtime. The same file that deploys to production can be statically validated in CI, simulated with MockLLM in tests, and diffed against the previous version to see exactly what changed.
Think of it as Kubernetes for agent systems: infrastructure as code, but for LLM workflows.
https://medium.com/media/77d76feb7d35abe0935f780841dfd880/href
Sample blueprint kick-starter to load specified blueprint and compile it.
https://medium.com/media/ebed9ed0ebbf703eb657ec4f1ae53eba/href
The Blueprint YAML supports seven top-level sections: metadata, providers, agents, workflows, context, contracts, and observability. Beyond runtime execution, the same spec is used by the Blueprint CLI for static validation, Mermaid diagram rendering, semantic diffing between versions, and contract conformance testing — all without making a single LLM call.
https://medium.com/media/be8e8ed9c9bcdf086d08af609fc788c0/href
Agent Orchestration Design Patterns
Patterns are the execution layer. Each is a named, tested, composable class that encodes one recurring coordination problem and its trade-offs. The full set is 18 patterns across four tiers.
Why named patterns matter
In a codebase where one team builds a “router,” another builds a “dispatcher,” and a third builds a “coordinator,” you can’t reason about the system at a glance. When the codebase instead uses Supervisor, FanOutFanIn, and Debate, every engineer on the team immediately knows what each piece does, what it costs, and what its failure modes are. The pattern name is the shared vocabulary.
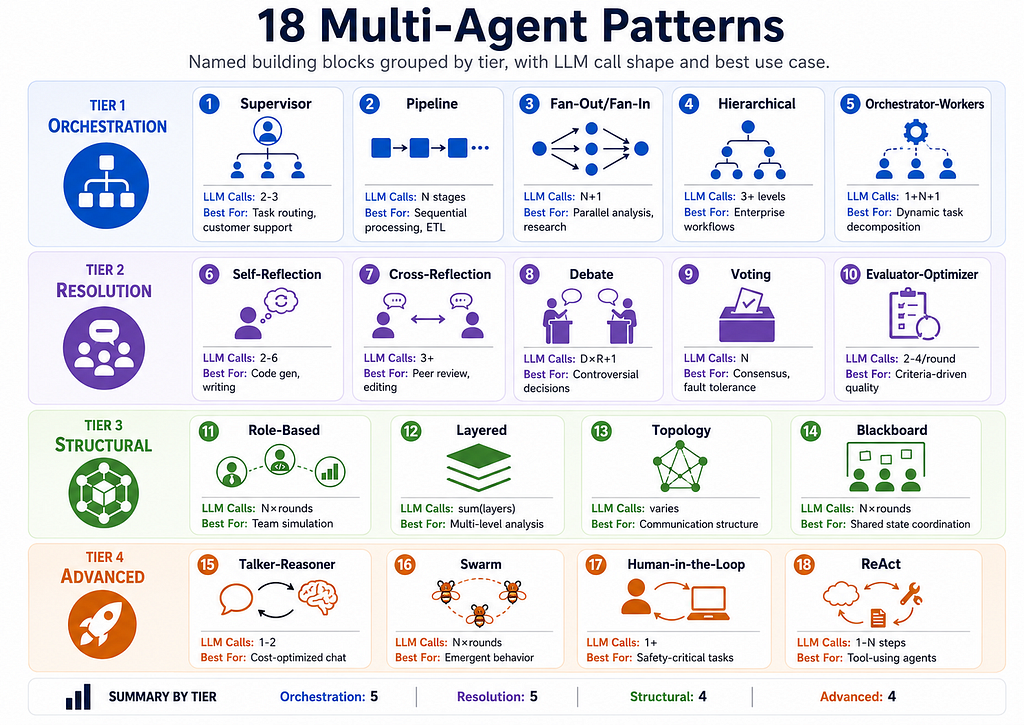
Tier 1 — Orchestration: getting work to the right place
- Supervisor classifies incoming tasks and routes them to the appropriate specialist. Most customer-facing applications start here. A cheap model handles classification; expensive models are reserved for the domains that actually need them.
https://medium.com/media/be83d00989b6f99146be8790040e9ede/href
- Pipeline passes a task sequentially through a chain of agents, each receiving the previous agent’s output as its input. It’s the natural starting point with low cost, easy to reason about, debuggable at each stage.
https://medium.com/media/36474fbbd8652380c7ddd4427e308faf/href
- Fan-Out / Fan-In broadcasts a task to all agents simultaneously (wall-clock time = slowest agent, not the sum), then passes all outputs to an aggregator for synthesis. The right pattern when you need multiple independent perspectives like bull/bear/neutral on an investment, three different technical reviewers, competing hypotheses in research.
- Hierarchical extends Supervisor to multiple levels: a top-level coordinator delegates to domain sub-supervisors, which route to workers. The right structure for enterprise workflows where each domain has its own routing logic.
- Orchestrator-Workers handles open-ended goals where the required subtasks aren’t known upfront. The orchestrator plans the work at runtime in JSON, dispatching only the workers this particular task needs. More flexible than Supervisor; one extra planning call.
Tier 2 — Resolution: when one pass isn’t good enough
- Self-Reflection asks a model to critique its own output and revise based on that critique. The critic doesn’t have to be the same model as the generator, usually a cheaper model generates drafts and a stronger model critiques them. The stop_phrase enables early exit when the output is already good.
https://medium.com/media/c98b313b3d034fffccc31ccaf6534e3e/href
- Cross-Reflection uses genuinely different agents — ideally different providers — for generator and reviewer, eliminating correlated errors. Anthropic and OpenAI models make different mistakes; a reviewer from a different provider won’t share the author’s blindspots.
- Debate assigns agents opposing positions, runs structured argumentation rounds where each debater responds to the others, and has a judge render a verdict. The full transcript is available in result.metadata[“debate_log”] which is useful for understanding how the decision was reached, not just what it was.
- Voting runs the same task across N agents and selects the answer with the most agreement. Most powerful when agents come from different providers — correlated failures are rare across providers. Also the right pattern for fault tolerance: one hallucinated response doesn’t win.
https://medium.com/media/fb24cb31d6aa06c4a0501e8bd5e8796f/href
- Evaluator-Optimizer applies structured scoring criteria rather than free-form critique. The evaluator scores output across explicit dimensions; the optimizer revises specifically to improve low-scoring ones. The improvement loop is targeted and measurable.
Tier 3 — Structural: controlling how information flows
- Role-Based runs agents with distinct professional roles across multiple rounds, each seeing the others’ contributions. Useful for simulating team review — product manager, engineer, and designer each bringing their lens to a proposal.
- Layered structures agents into horizontal tiers where each tier’s collective output feeds the next. A natural fit for multi-level analysis: gather broadly in layer 1, analyse by domain in layer 2, synthesise across domains in layer 3.
- Topology exposes three communication structures directly — Chain (sequential, lowest cost), Star (parallel collection then synthesis), and Mesh (every agent sees every other’s output each round, most thorough, most expensive). The choice is a direct cost/quality trade-off.
- Blackboard decouples agents entirely: they read from and write to a shared key-value store, each declaring which keys it reads and writes. Agents can be added, removed, or reordered without touching each other. The right choice for long pipelines where you need to maintain loose coupling.
Tier 4 — Advanced: patterns that adapt at runtime
- Talker-Reasoner is about your inference bill. The talker — a cheap fast model — handles the easy majority of queries. If it signals uncertainty, it escalates to the reasoner. At scale, routing even 70% of queries to a nano-class model produces significant cost savings.
https://medium.com/media/f8f6fe5649d97ee5e56c3a3ce1a06714/href
- Swarm lets agents autonomously influence each other across rounds without a central coordinator. Behaviour emerges from local interactions — useful for research tasks where agents discover they need a specialist mid-way, or creative tasks where one agent’s direction inspires another to pivot.
- Human-in-the-Loop pauses execution at defined checkpoints and waits for a human decision before continuing. Essential for safety-critical workflows: content moderation pipelines that flag edge cases, code agents that ask before running destructive operations, approval flows that require sign-off before sending communications.
- ReAct implements the Thought → Action → Observation cycle, adding tool use to the reasoning loop. The agent reasons about the task, decides which tool to call, calls it, observes the result, and reasons again. The full trace in result.metadata[“trace”] shows every decision step.
Patterns Composition and Advisor
Because every pattern implements the same Pattern base class, any pattern can be used anywhere an Agent is expected. A FanOut of Pipelines, wrapped in SelfReflection, is three classes:
https://medium.com/media/a8b1f9db68f3cbbe4f41c0b51a1e1feb/href
When you’re not sure which pattern to reach for, the PatternAdvisor can suggest one based on your task description and constraints.
https://medium.com/media/a1467f5e3f8dca2434e7e5de4aedbf32/href
Providers — multi-provider registry with fallback chains
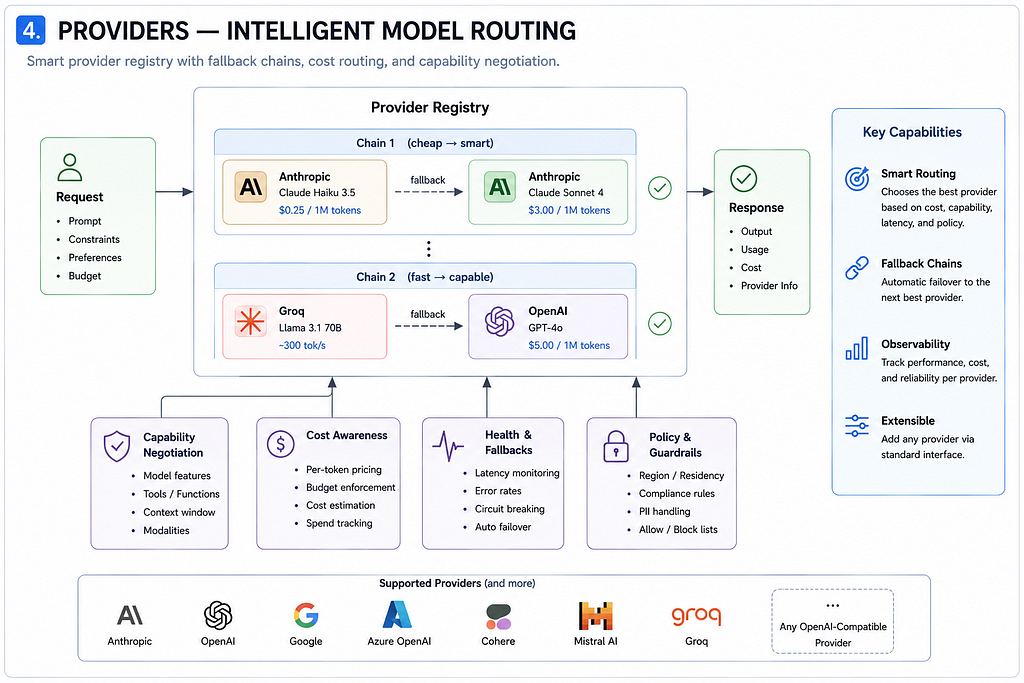
pyagent-providers is a unified registry over Anthropic, OpenAI, Gemini, and any LiteLLM-compatible backend. Rather than wiring LLM clients directly into agents, you define a provider registry in your Blueprint (or in code) and reference providers by name. The registry handles fallback chains, capability negotiation, and cost-aware routing automatically.
https://medium.com/media/2974ccfc6db5f6d110b835a60434bc00/href
If the primary provider is unavailable or over rate limit, the registry falls back to the next in the chain — without the agent needing to know. The provider section in Blueprint also wires into the Router for difficulty-aware model selection (covered below).
Context — three-tier memory across agents and turns
pyagent-context gives agents memory that persists within and across runs. The ContextLedger manages three tiers:
Working memory is the in-flight context for the current task — what’s been said so far in this run.
Session memory persists across turns in a conversation, but not across separate sessions. Useful for stateful chat applications where the agent needs to remember what was discussed earlier in the conversation.
Semantic memory is a long-term store for facts, preferences, and learned context that should persist across sessions. Agents that read from semantic memory can recall things like user preferences, past decisions, or domain knowledge that was accumulated in prior runs.
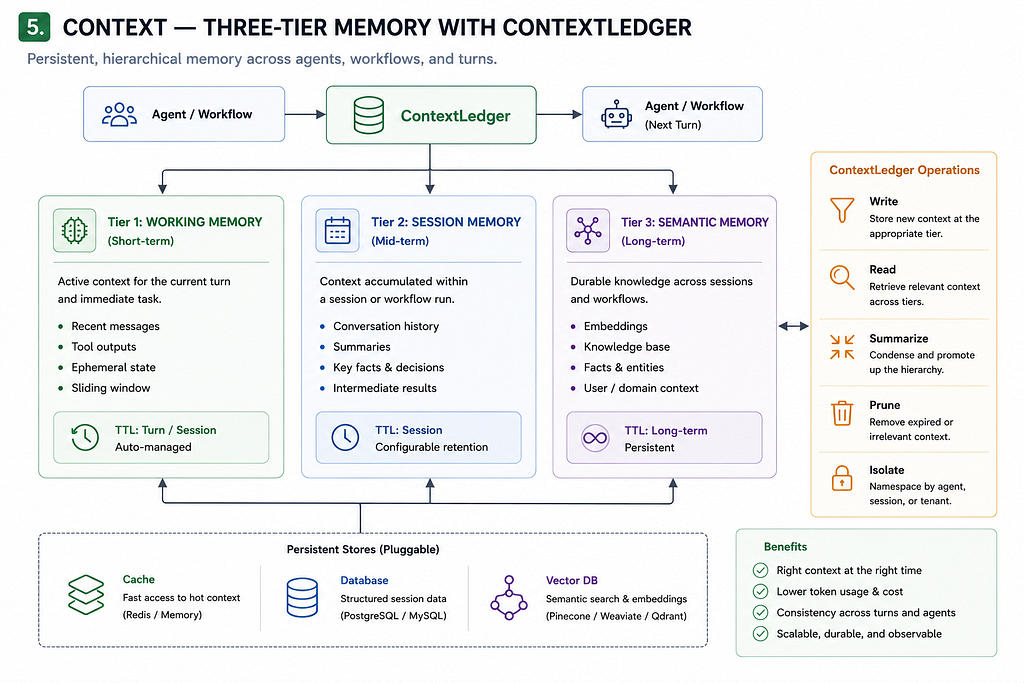
In Blueprint, context configuration lives in its own section:
https://medium.com/media/dc98c9134e2244adc2d6dbebbcb99088/href
The context layer also handles redaction of PII before it reaches external providers — the same PIIGuard available in the Guardrails API but applied at the memory level.
Compress — keeping inter-agent token transfer in check
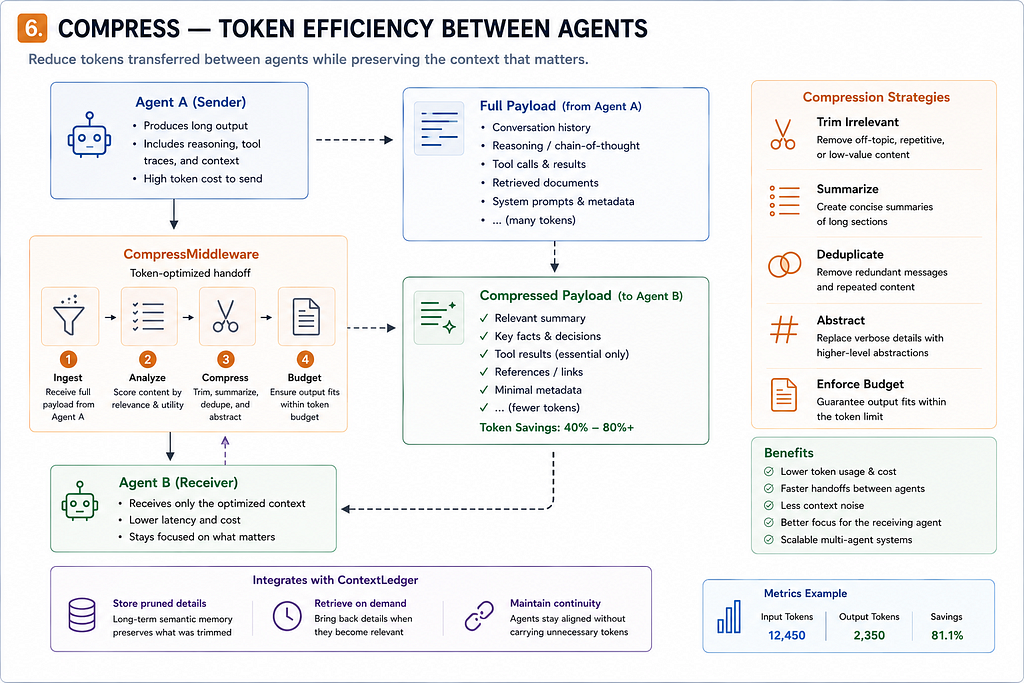
In a five-stage Pipeline, if each agent outputs 2,000 tokens, the fifth agent receives 8,000 tokens of prior context before it even starts its own work. pyagent-compress addresses this by trimming inter-agent message transfer while preserving key information.
https://medium.com/media/bf31ed349ee145aa9fde284682ee706a/href
The package also supports token budget enforcement (hard cutoffs that trigger compression before a call would exceed the model’s context window) and agent pruning (removing older agents’ contributions from the shared context when they’re no longer relevant to the current stage).
In long pipelines where compression is always-on, the OTel trace will include a pyagent.compress.savings_pct attribute on every span, so you can see exactly how much the compressor is saving at each step.
Trace — structured observability from every layer of the stack
pyagent-trace wraps the whole stack with structured observability. Every agent call, pattern execution, and LLM invocation emits events through a TraceEventBus. Consumers hook to the exporters, cost trackers, whereas Studio hook to subscribe the event-bus and receive events in real time.
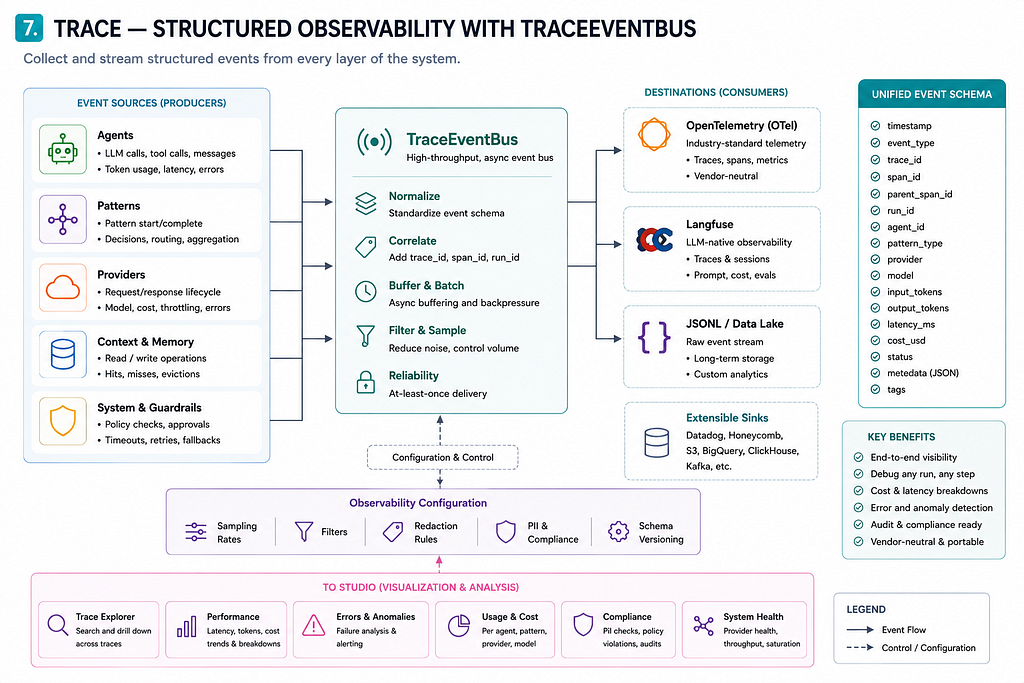
The key design is that the trace is pattern-aware. Spans carry attributes like pyagent.pattern.type, pyagent.agent.name, pyagent.router.difficulty, and pyagent.compress.savings_pct. This means your tracing backend doesn’t just see generic HTTP calls — it knows a Debate ran for 3 rounds, the judge was claude-sonnet, and the whole thing cost $0.01032.
https://medium.com/media/7201381fd8251caff7620ab487da4770/href
The simplest integration is the decorator approach — inherit from a traced variant of any pattern class:
https://medium.com/media/288549df857d100ea030c4b0f14ce406/href
CostTracker aggregates costs by pattern, model, and agent across a session:
https://medium.com/media/5349e27607b1fb877b9eb873888dafb6/href
Recorder captures every LLM call to JSONL for deterministic replay — useful for debugging a specific run without re-incurring API costs:
https://medium.com/media/fa76ac2bced4b80df6ba55619494311e/href
OTel backends are supported out of the box — Jaeger for local development, Langfuse for production LLM observability, Grafana Tempo + Prometheus for infrastructure teams, and any OTLP endpoint. A recorded trace looks like:
Trace: investment-analysis / debate (9.8s total, $0.01032)
├── pyagent.agent.bull 2.4s gemini-2.5-flash 450→380 tok $0.00094
├── pyagent.agent.bear 2.7s gemini-2.5-flash 450→410 tok $0.00098
├── pyagent.agent.bull 2.1s (round 2) 410→360 tok $0.00086
├── pyagent.agent.bear 1.9s (round 2) 410→380 tok $0.00084
└── pyagent.agent.judge 0.7s claude-sonnet-4 1200→480 tok $0.00840
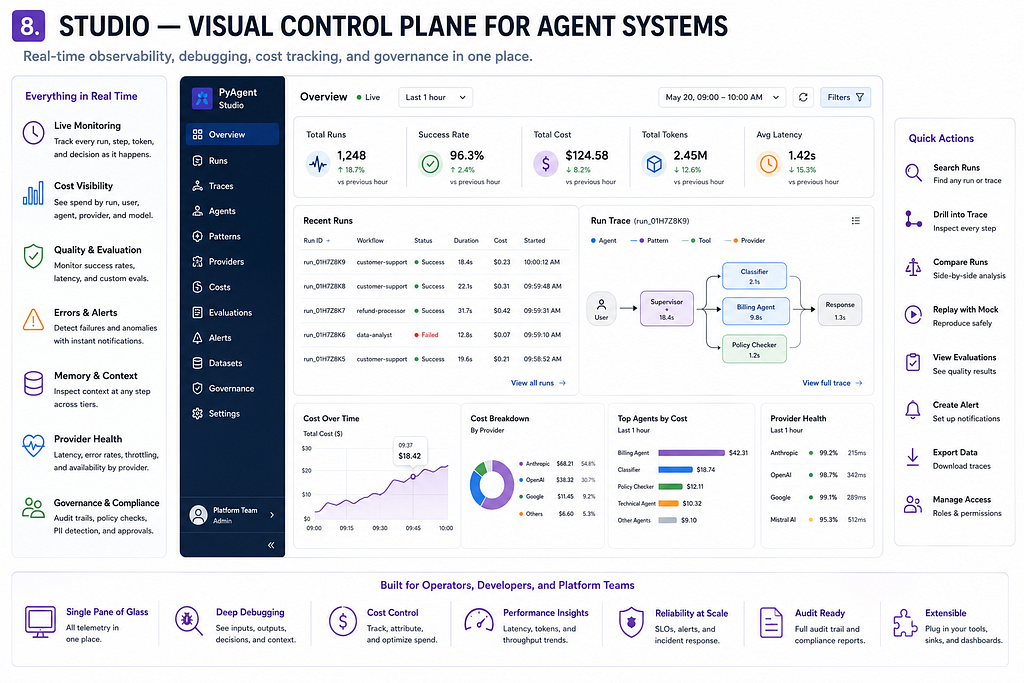
Studio — the Kubernetes Dashboard for your agent stack
pyagent-studio is a kubectl-style CLI and web control plane for designing, simulating, debugging, and governing multi-agent systems. The analogy from the docs is direct: Studio is to PyAgent what kubectl + the Kubernetes Dashboard are to Kubernetes.
https://medium.com/media/86feaedc7697b228b2239167b49d411e/href
The web dashboard has nine sections:
/overview gives a system summary — loaded blueprints, provider health, recent run stats.
/workflows and /agents let you inspect how agents are wired together and what their configurations are.
/simulate runs a workflow against MockLLM (no API cost) and shows the full execution path.
/traces is the trace explorer, powered by the JSONL files from pyagent-trace. You can filter by agent, pattern type, cost range, or duration, and drill into any span for the full input/output.
/governance validates loaded blueprints against their contracts and flags any violations.
/providers shows provider health, latency percentiles, and per-model cost breakdowns.
/diff renders semantic diffs between two Blueprint versions side by side.
The CLI and the web dashboard share the same underlying service layer, so anything you can do in the UI you can also script with pyagent commands in CI.
Router — routing tasks to the cheapest model that can handle them
pyagent-router scores incoming queries for difficulty and selects the most cost-effective model that’s capable of handling them. It knows pricing for the full range of current models — GPT-4.1-nano through o3, Haiku through Sonnet, Gemini Flash through Pro — and applies that knowledge at call time.
https://medium.com/media/21efaedb2678d4d6359cb3610733f31e/href
The router integrates with the Blueprint’s providers section through routing strategies. cost_optimized minimises spend; latency minimises wall-clock time; capability ensures the model can handle the inferred difficulty. In practice, most teams start with cost_optimized and adjust after seeing their trace cost breakdowns in Studio.
This is also how Talker-Reasoner works under the hood — the router is the mechanism that decides whether the talker or the reasoner handles a given query.
Where to start
If you’re new to multi-agent systems, start with pyagent-patterns and the Pipeline and Supervisor patterns. Get something running, then layer in routing and context once you’ve established the basic shape of your system.
If you’re adding PyAgent to an existing codebase, the hooks guide is worth reading first — it shows how to attach trace, context, compression, and cost tracking to agents you’ve already built, without rewiring everything.
If you’re building for production, start with Blueprint. The discipline of declaring your system in YAML pays off quickly in CI validation, versioned diffs, and simulation — especially once the system gets complex enough that you can’t hold it all in your head.
- Docs: https://pyagent.org
- GitHub: https://github.com/pyagent-core/pyagent
PyAgent is MIT licensed, requires Python 3.11+, and has zero mandatory dependencies in the core packages.
PyAgent: A Design Pattern Orchestrator for Multi-Agent LLM Systems was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.