
Pydantic AI Is Only 73 Lines of My Codebase: The Other 90% Is Architecture
Why production AI systems spend far more engineering effort on state management, tool governance, model identity, and transport layers than on the agent framework itself.
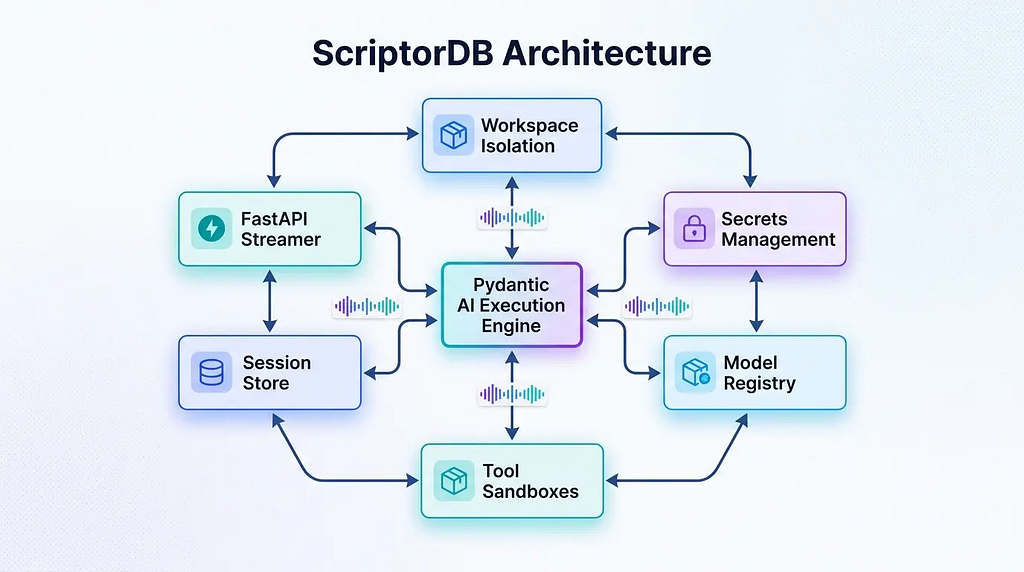
In our recently open-sourced project, ScriptorDB, the code that directly invokes Pydantic AI amounts to exactly 73 lines. Well over 90% of the engineering effort goes into workspace isolation, secrets management, model resolution, tool security policies, session persistence, SSE streaming, error tracking, and execution auditing-all of which occur outside the framework. This ratio isn’t accidental; it reveals a truth obscured by most AI agent framework demos: Pydantic AI solves the execution problem, not the architectural one.
If you’ve only looked at the official examples, it’s easy to get the impression that defining an Agent, attaching a few tools, and calling agent.run() is all it takes to build a production-grade AI application.
But push this code into a real-world environment, and by week two, you’ll hit questions the framework doesn’t answer: How do you isolate chat histories between User A and User B? If some team members use OpenAI and others use Claude, how do you handle model IDs that are completely incompatible across providers? What is the source of truth for checkpoint recovery? When streaming output mixes tool-call events with text deltas, how should your HTTP routing handle it?
These are not edge cases; they are baseline requirements for production systems. Pydantic AI doesn’t solve them-nor does it intend to. It deliberately restricts itself to the role of an execution engine: providing you with a type-safe, testable LLM invocation layer that supports streaming and structured outputs, and honestly leaving the question of how to structure the application to the developer.
The real engineering effort lies in building a comprehensive production-grade AI application architecture around this engine.
![Diagram: AppConfig block with database URL and model configs injected into Agent[AppConfig] via deps.](https://cdn-images-1.medium.com/max/1024/1*_ilrC_fvvFua-UoP8Lm1SA.png)
I. Where Are the Boundaries of the Framework?
The ideal form of a production-grade AI agent framework is to reduce itself to a thin execution kernel. It should only manage round-trip communication with the LLM, serialization and deserialization of tool calls, structured output validation, and streaming event generation. These are its unique capabilities-type safety, asynchronous scheduling, and event-driven execution-and anything beyond this should not be handled by the framework.
Once this boundary is clearly drawn, more than half of your production requirements naturally fall on the outside: state isolation, secrets management, model resolution, session persistence, and transport protocol adaptation. These requirements are largely agnostic to which AI agent framework you use, yet they dictate whether your system can transition from a demo to a robust enterprise application.
ScriptorDB enforces this boundary strictly. The 73 lines of code in agents/db_agent.py do exactly four things: instantiate Agent[AppConfig]based on the current configuration; attach three FunctionToolsets; inject audit hooks; and wrap specific providers in an OpenAIProviderlayer. After that, the framework exits the stage.
A crucial design decision here was that ScriptorDB does not stuff business state into the agent. AppConfig is passed in via deps, but it functions as a lightweight configuration object holding the current workspace’s database connection. The Agent depends on it, but doesn’t own it. This read-only dependency injection pattern completely isolates state management from the engine.
II. Why the Tool Layer Must Be an Independent Subsystem
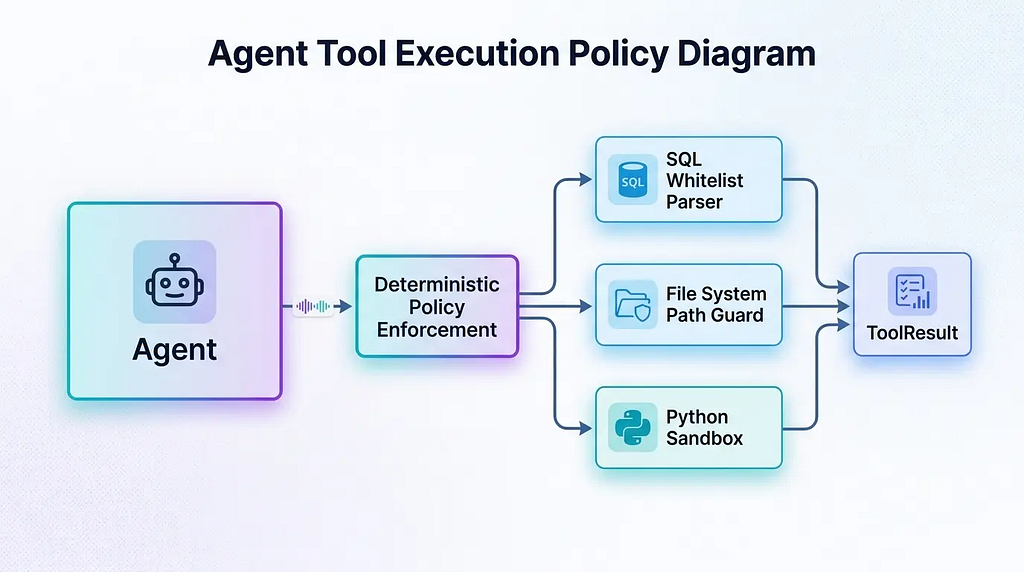
Pydantic AI provides the @agent.tool decorator, which makes demos look exceptionally clean: one function equals one tool. But in production, the complexity of a tool extends far beyond a single function signature. Real-world systems require deterministic policy enforcement before any tool executes.
ScriptorDB’s practice is to decouple the tool layer entirely from the Agent definition, forming independent subsystems. Each tool carries its own parameter validators, execution strategies, and result encapsulation. For example, the database query tool passes through a SQL read-only whitelist validator; write_csv checks if the file path is attempting to traverse out of the workspace directory; run_python_code filters dangerous imports during sandbox validation before execution.
Execution strategies are similarly configured independently: timeouts range from 5 to 60 seconds, retries are set to 1 or 2, and write operations explicitly require human approval. All tools return a unified ToolResult structure containing success, error, and data fields, standardizing the agent’s error handling.
The most immediate engineering benefit of this design is testability. ScriptorDB’s test_tools.py directly tests SQLite queries, CSV parsing, and path validation without ever spinning up the agent. Furthermore, tool security policies belong to application governance and shouldn’t be coupled with the inference engine’s implementation details. When you need to add manual approval to a high-risk tool, you should only modify the tool’s configuration, not refactor the agent’s registration logic.
III. Model Identity Confusion: The Hidden Debt of Production
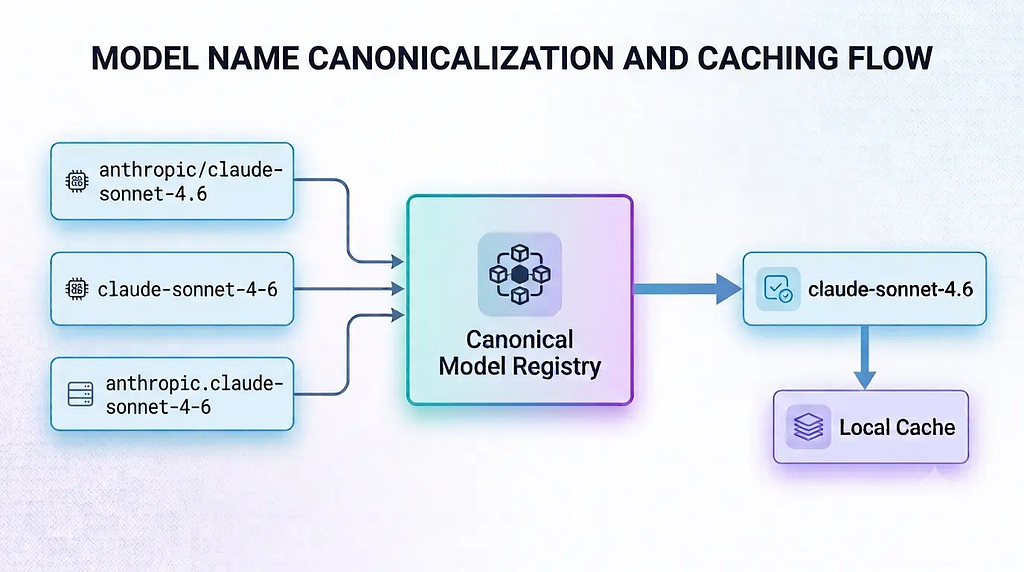
Almost every engineer who has run multiple LLM providers in production has encountered the same headache: the same model is called completely different names across different platforms. Claude Sonnet 4.6 is claude-sonnet-4–6 on Anthropic, anthropic/claude-sonnet-4.6 on OpenRouter, and yet another variant on Google Vertex. If your system uses the raw ID provided by the vendor as the persistent key, searching logs, restoring sessions, tracking metrics, and migrating configurations will slowly devolve into unmaintainable technical debt.
ScriptorDB’s solution is to introduce a Canonical Model Registry, which maintains a standardized, cross-provider list of models where each entry has a stable slug (e.g., claude-3–5-sonnet) and a mapping of aliases for different providers.
At runtime, fuzzy matching maps user input to the provider-specific ID, and the raw response is reverse-normalized into the canonical slug for session logging and trace tracking. The model registry also includes a local cache with a 1-hour TTL to avoid hitting provider APIs on every startup.
The value of this design goes far beyond “making user input easier.” In a production-grade AI application, a unified model identity is foundational infrastructure for configuration migrations, A/B testing, cost attribution, and error tracking. The canonical layer decouples “what the user calls the model” from “how the system identifies the model”-a prerequisite for long-term maintainability.
IV. Don’t Treat Framework Data Structures as Persistence Formats
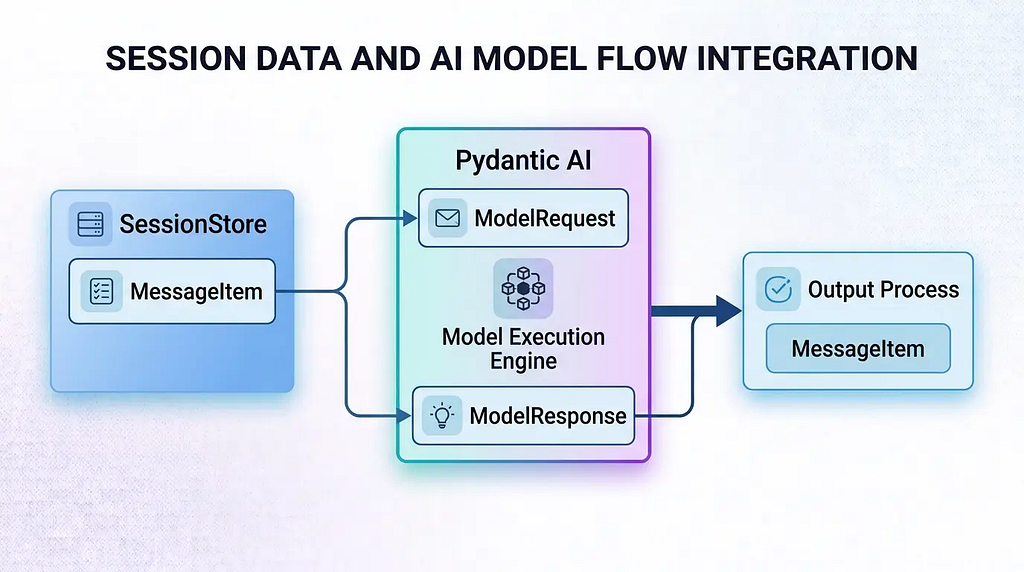
AI agent frameworks typically expose conversation history as a disposable message_history array, which is fine for single-shot inference. But production systems require persistent, isolated, and migratable lifecycle management for conversations. The most dangerous pitfall here is serializing the framework’s internal ModelMessage objects directly to disk as your long-term storage format.
Framework upgrades can arbitrarily change internal message structure definitions. If historical sessions are stored in this format, a single dependency upgrade can render old sessions unparsable, causing user data loss.
ScriptorDB’s approach is to define an independent Session model and a SessionStore abstraction. It maintains its own simplified MessageItem (role + content) for frontend rendering and long-term storage, only assembling ModelRequest / ModelResponse as temporary transport payloads for the Agent at runtime. The SessionStore is an interface; the default implementation relies on JSON files, but it can be swapped out for Redis or PostgreSQL at any time-without changing a single line of Agent code.
The core motivation behind this decision is schema ownership. Your application must own the schema definition of conversational data, rather than ceding this control to a framework’s internal implementation. The framework should be treated as a mutable external dependency; its data structures should exist only as transient runtime objects. Once you write a framework’s message format into your database, you are unknowingly signing a contract that could be unilaterally altered at any moment.
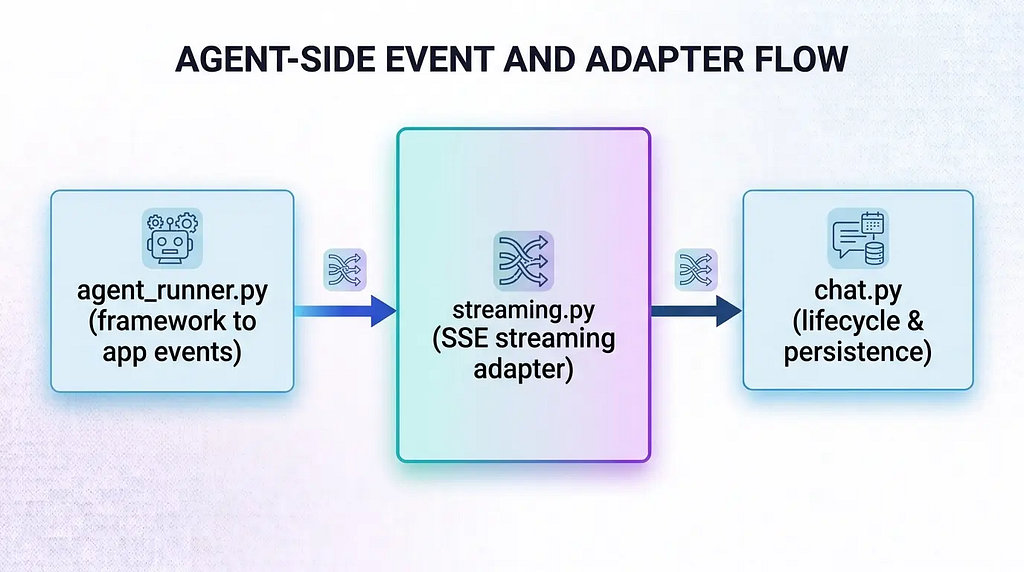
V. HTTP Routes Should Not Call the Agent Directly
Pydantic AI’s agent.run() is an asynchronous call that returns a final result. However, production APIs must deal with Server-Sent Events (SSE) streams, real-time pushes of tool-call events, execution metadata collection, error fallbacks, and timeout controls. If you allow your FastAPI routes to call agent.run() directly, your routing code will rapidly bloat into a messy stew of inference logic, transport protocols, and persistence handling.
ScriptorDB breaks service orchestration down into a three-stage pipeline, strictly following the Single Responsibility Principle:
- agent_runner.py intercepts raw events from Pydantic AI via an event_stream_handler, converting them into standardized internal dictionaries (tool_call, tool_result, text_delta, trace). Simultaneously, a RunTracker logs the latency and state of each tool call. This layer is solely responsible for “translating framework events into application events.”
- streaming.py acts as a thin adapter on top of this, wrapping the dictionaries into SSE strings and appending canonical model metadata. This layer is solely responsible for “translating application events into transport protocols.”
- chat.py routes the SSE stream back to the frontend, while appending the new message and execution record to the SessionStore once the stream concludes. This layer is solely responsible for “HTTP lifecycles and persistence finalization.”
The key insight of this stratification is: the inference engine, transport protocol, and persistence strategy are orthogonal; they should never meet in the same function. When you need to swap SSE for WebSockets, you only touch streaming.py. When you need to add auditing fields, you modify agent_runner.py. When you switch storage backends, you adjust the teardown logic in chat.py. Pydantic AI’s agent.run() is firmly isolated at the very bottom of the stack, completely insulated from transport protocol details.
Every mature AI application will eventually grow its own layers around the AI agent framework: session isolation, runtime context, model identity abstraction, streaming protocols, security, and auditing.
The framework itself changes far less frequently than these surrounding layers, but these layers will continuously evolve-they are where you truly invest your engineering efforts.
This perspective isn’t limited to Pydantic AI. Whether you are using LangGraph, OpenAI Agents SDK, CrewAI, or any emerging AI agent framework, you will eventually face the same boundary: the framework handles execution, but everything beyond execution-state, identity, protocols, security-falls squarely under application architecture.
In the entirety of ScriptorDB’s codebase, the parts related to the AI agent framework make up less than ten percent. The remaining ninety percent solves workspace isolation, secrets management, model resolution, tool security policies, session persistence, streaming, and error tracking. None of these are advertised selling points of the framework, but every single one of them is the code you check first when your production environment goes down.
This is not a flaw in Pydantic AI; it is precisely its design triumph. It draws a crystal-clear boundary, honestly telling you: I can help you run the agent, but keeping the system from collapsing is your own architectural challenge.
So, if you are evaluating whether an AI agent framework is suitable for a production-grade AI application, don’t look at how flashy its demo is. Look at whether, once the framework’s boundaries end, your code can cleanly take over runtime assembly, state isolation, transport protocols, and error fallbacks. What truly determines whether your AI application will survive long-term operation is not the few dozen lines of code inside the framework, but the peripheral architecture you build around it-an architecture that can evolve, be tested, and be replaced entirely on its own.
Frameworks make agents run. Architecture makes products survive.
Originally published at https://aivault.dev.
Pydantic AI Is Only 73 Lines of My Codebase: The Other 90% Is Architecture was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.