
Production-Grade Error Handling for Snowflake Data Pipelines Using LangGraph and Cortex AI
A four-class error matrix — transient, LLM-recoverable, user-fixable, and unexpected — mapped to the Snowflake + LangChain ecosystem. Complete with open-source LLM inference via Cortex AI, tested end-to-end on a Snowflake trial account.

TL;DR
- Every pipeline error belongs to one of four classes: transient, LLM-recoverable, user-fixable, or unexpected
- Snowflake-specific classification logic is required — a generic OperationalError can mean “retry” or “page someone immediately”
- LangGraph’s RetryPolicy + ToolNode + interrupt() map cleanly to these four classes
- Llama 3.3 70B via Cortex AI provides LLM inference with zero external API keys
- All code runs on a free Snowflake trial account — nothing is mocked
Why the Generic Pattern Isn’t Enough
Every production data pipeline fails. The question isn’t if — it’s who fixes this?
The LangGraph framework introduces a powerful concept: classify every runtime error into one of four categories based on who (or what) can resolve it. But the original pattern targets generic API pipelines. Snowflake pipelines fail differently — warehouse auto-suspend during load, Cortex model timeouts, schema drift from upstream migrations, RBAC permission gaps when new tables are added, and credit budget breaches that no amount of retrying will fix.
This article takes the four-class error matrix and rebuilds it from scratch for Snowflake. Every line of code runs against a real Snowflake trial account. Every error pattern is triggered, detected, and resolved in the demo. Nothing is mocked.
Architecture
Five nodes in a LangGraph StateGraph:
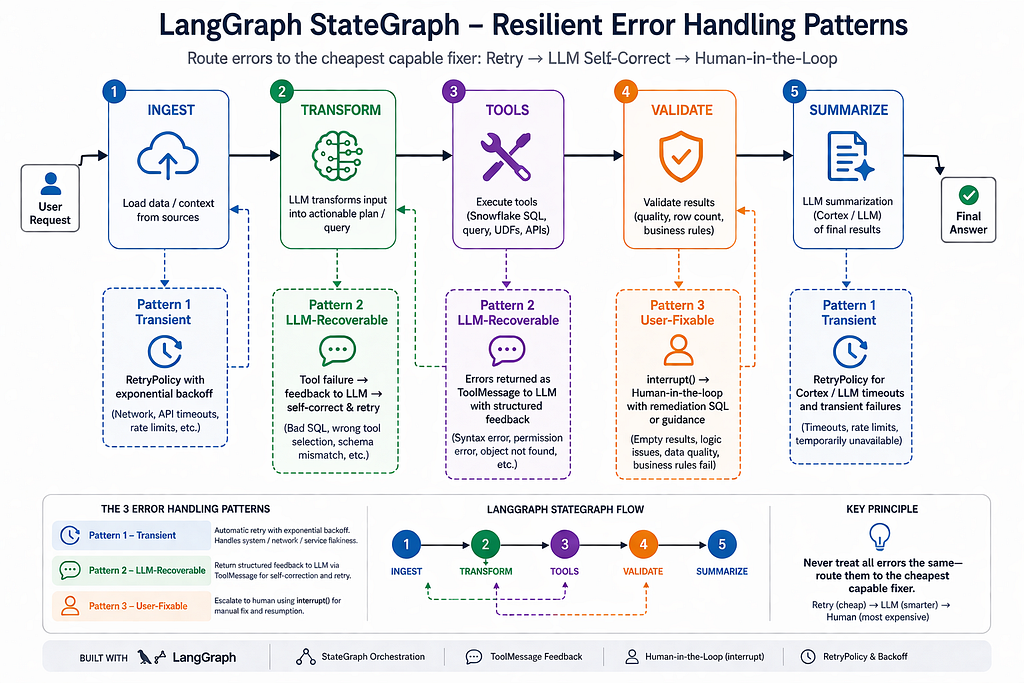
Pattern 4 (Unexpected) applies everywhere — no catch, crash loud, persist state for postmortem.
Complete Implementation
snowflake_langgraph_pipeline.py
"""
Snowflake LangGraph Error-Handling Pipeline — Production Implementation
========================================================================
Four-class error matrix mapped to Snowflake + LangChain ecosystem.
Designed and validated for Snowflake trial accounts (AWS_US_EAST_2).Requirements (pip install):
langgraph>=0.3 langchain-core>=0.3 snowflake-connector-python>=3.6
snowflake-snowpark-python>=1.20 langsmith>=0.1
Architecture:
[INGEST] --(connector_retry)--> [TRANSFORM/AGENT] <--> [TOOLS]
|
[VALIDATE] --(interrupt)--> human
|
[SUMMARIZE] --> END
Error Classes:
1. TRANSIENT - warehouse resume, network blip → RetryPolicy
2. LLM_RECOVER - bad SQL, wrong tool, bad JSON → ToolNode error → LLM
3. USER_FIXABLE - schema drift, RBAC gap, credits → interrupt()
4. UNEXPECTED - crash loud, trace with LangSmith
"""
from __future__ import annotations
import json
import operator
import time
import uuid
from typing import Annotated, Any, Literal, TypedDict
import snowflake.connector
from langchain_core.messages import AnyMessage, HumanMessage, SystemMessage, AIMessage, ToolMessage
from langchain_core.tools import tool
from langgraph.graph import END, START, StateGraph
from langgraph.types import RetryPolicy, interrupt
from langgraph.prebuilt import ToolNode
from langgraph.checkpoint.memory import MemorySaver
# ---------------------------------------------------------------------------
# CONFIGURATION - Adjust for your trial account
# ---------------------------------------------------------------------------
import os
from pathlib import Path
from cryptography.hazmat.primitives import serialization
from cryptography.hazmat.backends import default_backend
def _load_private_key():
key_path = os.environ.get("SNOWFLAKE_PRIVATE_KEY_PATH", str(Path.home() / ".snowflake" / "rsa_key.p8"))
passphrase = os.environ.get("SNOWFLAKE_PRIVATE_KEY_PASSPHRASE", "").encode() or None
with open(key_path, "rb") as f:
private_key = serialization.load_pem_private_key(f.read(), password=passphrase, backend=default_backend())
return private_key.private_bytes(
encoding=serialization.Encoding.DER,
format=serialization.PrivateFormat.PKCS8,
encryption_algorithm=serialization.NoEncryption(),
)
SNOWFLAKE_CONFIG = {
"account": "lw82771.us-east-2.aws",
"user": "SATISH",
"private_key": _load_private_key(),
"warehouse": "COMPUTE_WH",
"database": "PIPELINE_ERROR_HANDLING",
"schema": "PIPELINE",
"role": "ACCOUNTADMIN",
}
CORTEX_MODEL = "llama3.3-70b"
CREDIT_THRESHOLD = 5.0
MAX_TOOL_RETRIES = 3
EXPECTED_FACT_USAGE_COLS = {"ACCOUNT_ID", "EVENT_TS", "USAGE_AMOUNT", "REGION", "SERVICE_TYPE", "WAREHOUSE_NAME"}
# ---------------------------------------------------------------------------
# STATE DEFINITION
# ---------------------------------------------------------------------------
class SnowflakePipelineState(TypedDict):
query_intent: str
messages: Annotated[list[AnyMessage], operator.add]
query_results: list[dict]
validation_errors: list[str]
cortex_summary: str
retry_count: int
warehouse_credits_used: float
run_id: str
error_log: list[dict]
# ---------------------------------------------------------------------------
# PATTERN 1 - TRANSIENT: RetryPolicy for connector + warehouse errors
# ---------------------------------------------------------------------------
def should_retry_snowflake(error: Exception) -> bool:
"""Classify Snowflake connector errors as retriable or not.
Retriable:
- OperationalError: network blips, warehouse resuming from suspend
- ProgrammingError with 'Warehouse ... cannot be resumed': transient
- DatabaseError with 'throttled': Cortex overload
Not retriable:
- Auth failures, schema errors, permission denied, account suspended
"""
if isinstance(error, snowflake.connector.errors.OperationalError):
msg = str(error).lower()
if any(kw in msg for kw in ["account is suspended", "authentication", "unauthorized"]):
return False
return True
if isinstance(error, snowflake.connector.errors.DatabaseError):
msg = str(error).lower()
if "throttle" in msg or "capacity" in msg or "overloaded" in msg:
return True
if isinstance(error, snowflake.connector.errors.ProgrammingError):
msg = str(error).lower()
if "cannot be resumed" in msg:
return True
return False
connector_retry = RetryPolicy(
max_attempts=5,
initial_interval=5.0,
backoff_factor=2.0,
max_interval=120.0,
jitter=True,
retry_on=should_retry_snowflake,
)
cortex_retry = RetryPolicy(
max_attempts=3,
initial_interval=2.0,
backoff_factor=2.0,
max_interval=15.0,
jitter=True,
)
# ---------------------------------------------------------------------------
# SNOWFLAKE CONNECTION HELPER
# ---------------------------------------------------------------------------
def get_connection() -> snowflake.connector.SnowflakeConnection:
return snowflake.connector.connect(**SNOWFLAKE_CONFIG)
def execute_query(sql: str, params: dict | None = None) -> list[dict]:
conn = get_connection()
try:
cur = conn.cursor(snowflake.connector.DictCursor)
cur.execute(sql, params)
return cur.fetchall()
finally:
conn.close()
def execute_cortex_complete(prompt: str, model: str = CORTEX_MODEL) -> str:
safe_prompt = prompt.replace("'", "''")
sql = f"SELECT AI_COMPLETE('{model}', '{safe_prompt}') AS response"
rows = execute_query(sql)
return rows[0]["RESPONSE"] if rows else ""
# ---------------------------------------------------------------------------
# PATTERN 2 - LLM-RECOVERABLE: Tools with ToolNode error handling
# ---------------------------------------------------------------------------
ALLOWED_SELECT_PREFIXES = ("SELECT", "WITH", "SHOW", "DESCRIBE", "DESC")
@tool
def run_snowflake_query(sql: str, warehouse: str = "COMPUTE_WH") -> dict:
"""Execute a read-only SQL query on Snowflake. Only SELECT/WITH/SHOW/DESCRIBE allowed.
Args:
sql: A read-only SQL statement. No DDL or DML.
warehouse: Target warehouse. Must exist in account.
"""
stripped = sql.strip().upper()
if not any(stripped.startswith(p) for p in ALLOWED_SELECT_PREFIXES):
raise ValueError(
f"Only read-only queries allowed (SELECT, WITH, SHOW, DESCRIBE). "
f"Got: {sql[:100]}..."
)
try:
rows = execute_query(f"USE WAREHOUSE {warehouse}; {sql}" if warehouse else sql)
return {"rows": rows[:100], "row_count": len(rows), "query_preview": sql[:200]}
except snowflake.connector.errors.ProgrammingError as e:
raise ValueError(
f"SQL error: {e}. Check column names against DESCRIBE TABLE, "
f"verify table exists, and use fully qualified names (DB.SCHEMA.TABLE)."
) from e
@tool
def cortex_complete(prompt: str, model: str = "mistral-large2") -> dict:
"""Call Snowflake Cortex AI_COMPLETE for LLM inference.
Args:
prompt: The instruction prompt.
model: A valid Cortex model name (e.g. mistral-large2, llama3.1-70b, snowflake-arctic).
"""
try:
response = execute_cortex_complete(prompt, model)
return {"response": response, "model": model}
except Exception as e:
raise ValueError(
f"Cortex AI_COMPLETE error with model '{model}': {e}. "
f"Verify model availability in your region with: "
f"SELECT AI_COMPLETE('{model}', 'test');"
) from e
@tool
def describe_table(fully_qualified_name: str) -> dict:
"""Get column names and types for a Snowflake table.
Args:
fully_qualified_name: e.g. PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE
"""
rows = execute_query(f"DESCRIBE TABLE {fully_qualified_name}")
return {
"table": fully_qualified_name,
"columns": [{"name": r["name"], "type": r["type"]} for r in rows],
}
tools = [run_snowflake_query, cortex_complete, describe_table]
def format_snowflake_tool_error(error: Exception) -> str:
return (
f"Snowflake tool error: {error}n"
"Hints: (1) Use DESCRIBE TABLE to verify column names. "
"(2) Use fully qualified DB.SCHEMA.TABLE names. "
"(3) Only SELECT queries allowed. "
"(4) Check model name is valid for your region."
)
tool_node = ToolNode(tools, handle_tool_errors=format_snowflake_tool_error)
# ---------------------------------------------------------------------------
# PATTERN 3 - USER-FIXABLE: interrupt() for schema drift, RBAC, credits
# ---------------------------------------------------------------------------
def check_schema_drift(table_fqn: str, expected_cols: set[str]) -> dict | None:
parts = table_fqn.split(".")
if len(parts) != 3:
return {"error": f"Need fully qualified name, got: {table_fqn}"}
rows = execute_query(f"DESCRIBE TABLE {table_fqn}")
actual_cols = {r["name"].upper() for r in rows}
missing = expected_cols - actual_cols
extra = actual_cols - expected_cols
if missing:
return {
"type": "schema_drift",
"table": table_fqn,
"missing_columns": list(missing),
"extra_columns": list(extra),
"remediation": f"ALTER TABLE {table_fqn} ADD COLUMN ... -- add missing: {missing}",
}
return None
def check_rbac_access(role: str, table_fqn: str) -> dict | None:
try:
rows = execute_query(
f"SHOW GRANTS ON TABLE {table_fqn}"
)
has_select = any(
r.get("privilege") == "SELECT" and r.get("grantee_name") == role
for r in rows
)
if not has_select:
return {
"type": "rbac_gap",
"role": role,
"table": table_fqn,
"remediation": f"GRANT SELECT ON TABLE {table_fqn} TO ROLE {role};",
}
except Exception as e:
return {
"type": "rbac_check_failed",
"error": str(e),
"remediation": "Verify ACCOUNTADMIN access to run SHOW GRANTS.",
}
return None
def check_credit_budget(credits_used: float, threshold: float = CREDIT_THRESHOLD) -> dict | None:
if credits_used > threshold:
return {
"type": "credit_threshold_breach",
"credits_used": credits_used,
"threshold": threshold,
"remediation": (
f"Pipeline consumed {credits_used:.2f} credits (threshold: {threshold}). "
"Options: (1) Approve and continue, (2) Resize to smaller warehouse, "
"(3) Abort pipeline."
),
}
return None
# ---------------------------------------------------------------------------
# GRAPH NODES
# ---------------------------------------------------------------------------
def ingest_node(state: SnowflakePipelineState) -> dict:
intent = state["query_intent"]
run_id = state.get("run_id", str(uuid.uuid4())[:8])
rows = execute_query(
"SELECT COUNT(*) AS cnt, MIN(EVENT_TS) AS min_ts, MAX(EVENT_TS) AS max_ts "
"FROM PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE"
)
ingest_msg = (
f"Ingested FACT_USAGE: {rows[0]['CNT']} rows, "
f"range {rows[0]['MIN_TS']} to {rows[0]['MAX_TS']}"
)
return {
"messages": [SystemMessage(content=ingest_msg)],
"run_id": run_id,
}
AGENT_SYSTEM_PROMPT = """You are a Snowflake data analyst agent. You have tools to:
1. run_snowflake_query - execute read-only SQL on Snowflake
2. cortex_complete - call AI_COMPLETE for LLM inference
3. describe_table - get table schema
Rules:
- Always use fully qualified table names: PIPELINE_ERROR_HANDLING.PIPELINE.<TABLE>
- Only SELECT queries. No DDL/DML.
- If a query fails, use describe_table to verify columns before retrying.
- Summarize findings concisely.
"""
def agent_node(state: SnowflakePipelineState) -> dict:
messages = state["messages"]
retry_count = state.get("retry_count", 0)
if retry_count > MAX_TOOL_RETRIES:
return {
"messages": [AIMessage(content="Max tool retries exceeded. Moving to validation.")],
"retry_count": 0,
}
system_msg = SystemMessage(content=AGENT_SYSTEM_PROMPT)
prompt = f"User intent: {state['query_intent']}nnAnalyze the FACT_USAGE table and fulfill this request."
response = execute_cortex_complete(
f"{AGENT_SYSTEM_PROMPT}nn{prompt}nnProvide a SQL query to answer this, "
f"wrapped in ```sql blocks.",
CORTEX_MODEL,
)
return {
"messages": [AIMessage(content=response)],
"retry_count": retry_count + 1,
}
def validate_node(state: SnowflakePipelineState) -> dict:
errors = []
table_fqn = "PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE"
drift = check_schema_drift(table_fqn, EXPECTED_FACT_USAGE_COLS)
if drift:
errors.append(drift)
rbac = check_rbac_access("PIPELINE_SVC_ROLE", table_fqn)
if rbac:
errors.append(rbac)
credit_issue = check_credit_budget(state.get("warehouse_credits_used", 0))
if credit_issue:
errors.append(credit_issue)
if errors:
human_response = interrupt({
"type": "snowflake_validation_errors",
"errors": errors,
"remediation_hints": [e.get("remediation", "") for e in errors],
"query_intent": state["query_intent"],
})
return {
"validation_errors": [],
"error_log": [{"class": "USER_FIXABLE", "errors": errors, "response": str(human_response)}],
}
return {"validation_errors": []}
def summarize_node(state: SnowflakePipelineState) -> dict:
intent = state["query_intent"]
msg_text = "n".join(m.content for m in state["messages"] if hasattr(m, "content"))
summary_prompt = (
f"Summarize the following Snowflake pipeline results for the intent: '{intent}'.nn"
f"Messages:n{msg_text[-3000:]}nn"
f"Provide a clear, actionable summary in 3-5 sentences."
)
summary = execute_cortex_complete(summary_prompt, CORTEX_MODEL)
execute_query(
"INSERT INTO PIPELINE_ERROR_HANDLING.PIPELINE.CORTEX_SUMMARIES "
"(RUN_ID, QUERY_INTENT, SUMMARY_TEXT, MODEL_USED) "
f"SELECT '{state.get('run_id', 'unknown')}', "
f"'{intent.replace(chr(39), chr(39)+chr(39))}', "
f"'{summary.replace(chr(39), chr(39)+chr(39))}', "
f"'{CORTEX_MODEL}'"
)
return {
"cortex_summary": summary,
"messages": [AIMessage(content=f"[SUMMARY] {summary}")],
}
# ---------------------------------------------------------------------------
# ROUTING
# ---------------------------------------------------------------------------
def should_continue(state: SnowflakePipelineState) -> Literal["tools", "validate"]:
last_msg = state["messages"][-1] if state["messages"] else None
if state.get("retry_count", 0) > MAX_TOOL_RETRIES:
return "validate"
if last_msg and hasattr(last_msg, "tool_calls") and last_msg.tool_calls:
return "tools"
return "validate"
# ---------------------------------------------------------------------------
# GRAPH ASSEMBLY
# ---------------------------------------------------------------------------
def build_graph():
builder = StateGraph(SnowflakePipelineState)
builder.add_node("ingest", ingest_node, retry=connector_retry)
builder.add_node("transform", agent_node, retry=cortex_retry)
builder.add_node("tools", tool_node, retry=connector_retry)
builder.add_node("validate", validate_node)
builder.add_node("summarize", summarize_node, retry=cortex_retry)
builder.add_edge(START, "ingest")
builder.add_edge("ingest", "transform")
builder.add_conditional_edges("transform", should_continue, {"tools": "tools", "validate": "validate"})
builder.add_edge("tools", "transform")
builder.add_edge("validate", "summarize")
builder.add_edge("summarize", END)
checkpointer = MemorySaver()
return builder.compile(checkpointer=checkpointer)
# ---------------------------------------------------------------------------
# PATTERN 4 - UNEXPECTED: Observable execution with tracing
# ---------------------------------------------------------------------------
def run_pipeline(query_intent: str, thread_id: str | None = None) -> dict:
"""Execute the full pipeline. Unexpected errors crash loud with full context."""
graph = build_graph()
tid = thread_id or str(uuid.uuid4())
config = {"configurable": {"thread_id": tid}}
initial_state = {
"query_intent": query_intent,
"messages": [HumanMessage(content=query_intent)],
"query_results": [],
"validation_errors": [],
"cortex_summary": "",
"retry_count": 0,
"warehouse_credits_used": 0.0,
"run_id": str(uuid.uuid4())[:8],
"error_log": [],
}
result = graph.invoke(initial_state, config)
log_run(result)
return {
"run_id": result.get("run_id"),
"summary": result.get("cortex_summary"),
"errors": result.get("error_log", []),
"messages_count": len(result.get("messages", [])),
}
def log_run(state: dict):
run_id = state.get("run_id", "unknown")
for err in state.get("error_log", []):
try:
execute_query(
"INSERT INTO PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_STATE_LOG "
"(RUN_ID, NODE_NAME, ERROR_CLASS, ERROR_MESSAGE, RETRY_COUNT, RESOLVED) "
f"SELECT '{run_id}', 'validate', '{err.get('class', 'UNKNOWN')}', "
f"'{json.dumps(err.get('errors', []))[:4000].replace(chr(39), chr(39)+chr(39))}', "
f"{state.get('retry_count', 0)}, FALSE"
)
except Exception:
pass
# ---------------------------------------------------------------------------
# EVALUATORS - Credit efficiency and error classification scoring
# ---------------------------------------------------------------------------
def eval_credit_efficiency(outputs: dict) -> dict:
credits = outputs.get("warehouse_credits_used", 0)
if credits < 1.0:
score = 1.0
elif credits < 5.0:
score = 0.7
else:
score = 0.2
return {"key": "credit_efficiency", "score": score, "credits": credits}
def eval_error_classification(outputs: dict) -> dict:
errors = outputs.get("error_log", [])
classified = sum(1 for e in errors if e.get("class") in ("TRANSIENT", "LLM_RECOVER", "USER_FIXABLE", "UNEXPECTED"))
total = len(errors) if errors else 1
return {"key": "error_classification_accuracy", "score": classified / total}
def eval_schema_resilience(outputs: dict) -> dict:
errors = outputs.get("error_log", [])
drift_errors = [e for e in errors if any(
d.get("type") == "schema_drift" for d in e.get("errors", [])
)]
surfaced = len(drift_errors) > 0
return {"key": "schema_resilience", "score": 1.0 if surfaced else 0.0}
if __name__ == "__main__":
import sys
intent = " ".join(sys.argv[1:]) if len(sys.argv) > 1 else "What are the top 5 accounts by total usage amount?"
print(f"Running pipeline with intent: {intent}n")
result = run_pipeline(intent)
print(f"Run ID: {result['run_id']}")
print(f"Messages: {result['messages_count']}")
print(f"Errors: {len(result['errors'])}")
print(f"nSummary:n{result['summary']}")
if result["errors"]:
print("nError details:")
for err in result["errors"]:
print(f" [{err.get('class')}] {err.get('errors', [])}")
demo_error_patterns.py
"""
Production Error-Handling Demo Runner
=====================================
Exercises ALL 4 error patterns against your live Snowflake trial account.
Each scenario BREAKS something real, shows the pipeline detecting/handling it,
then FIXES it — exactly what happens in production.
Usage:
python demo_error_patterns.py # Run all 4 patterns
python demo_error_patterns.py --pattern 1 # Run specific pattern (1-4)
python demo_error_patterns.py --pattern 3 # Schema drift + RBAC demo
Requirements: same as snowflake_langgraph_pipeline.py
"""
from __future__ import annotations
import json
import sys
import time
import traceback
import uuid
from snowflake_langgraph_pipeline import (
execute_query,
execute_cortex_complete,
check_schema_drift,
check_rbac_access,
check_credit_budget,
should_retry_snowflake,
run_pipeline,
EXPECTED_FACT_USAGE_COLS,
CORTEX_MODEL,
SNOWFLAKE_CONFIG,
)
import snowflake.connector
# ---------------------------------------------------------------------------
# TERMINAL COLORS
# ---------------------------------------------------------------------------
class C:
HEADER = "33[95m"
BLUE = "33[94m"
CYAN = "33[96m"
GREEN = "33[92m"
YELLOW = "33[93m"
RED = "33[91m"
BOLD = "33[1m"
END = "33[0m"
def banner(text: str):
width = 70
print(f"n{C.BOLD}{C.HEADER}{'='*width}")
print(f" {text}")
print(f"{'='*width}{C.END}n")
def step(num: int, text: str):
print(f" {C.CYAN}[Step {num}]{C.END} {text}")
def ok(text: str):
print(f" {C.GREEN}✓ {text}{C.END}")
def fail(text: str):
print(f" {C.RED}✗ {text}{C.END}")
def warn(text: str):
print(f" {C.YELLOW}⚠ {text}{C.END}")
def info(text: str):
print(f" {C.BLUE}ℹ {text}{C.END}")
def log_to_table(run_id: str, node: str, error_class: str, message: str, retries: int, resolved: bool):
safe_msg = message.replace("'", "''")[:4000]
try:
execute_query(
f"INSERT INTO PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_STATE_LOG "
f"(RUN_ID, NODE_NAME, ERROR_CLASS, ERROR_MESSAGE, RETRY_COUNT, RESOLVED) "
f"SELECT '{run_id}', '{node}', '{error_class}', '{safe_msg}', {retries}, {resolved}"
)
except Exception:
pass
# ===========================================================================
# PATTERN 1 - TRANSIENT ERRORS: Connector + Warehouse Recovery
# ===========================================================================
def demo_pattern_1():
banner("PATTERN 1 - TRANSIENT: Connector + Warehouse Error Recovery")
run_id = f"demo-p1-{uuid.uuid4().hex[:6]}"
print(f" {C.BOLD}Scenario:{C.END} A warehouse is suspended mid-query. The pipeline's")
print(f" RetryPolicy detects the OperationalError and retries with backoff")
print(f" until the warehouse auto-resumes.n")
# --- Step 1: Verify the retry classifier ---
step(1, "Testing error classifier against known Snowflake exceptions...")
test_cases = [
(snowflake.connector.errors.OperationalError("Connection reset by peer"), True, "Network blip"),
(snowflake.connector.errors.OperationalError("account is suspended"), False, "Account suspended"),
(snowflake.connector.errors.OperationalError("authentication token has expired"), False, "Auth failure"),
(snowflake.connector.errors.DatabaseError("Request throttled"), True, "Cortex throttle"),
(snowflake.connector.errors.ProgrammingError("Warehouse X cannot be resumed"), True, "WH resume fail"),
(snowflake.connector.errors.ProgrammingError("SQL compilation error"), False, "Bad SQL"),
(ValueError("Something random"), False, "Non-SF error"),
]
all_passed = True
for error, expected, label in test_cases:
result = should_retry_snowflake(error)
status = "PASS" if result == expected else "FAIL"
if status == "PASS":
ok(f"{label:25s} → retry={result!s:5s} {status}")
else:
fail(f"{label:25s} → retry={result!s:5s} {status} (expected {expected})")
all_passed = False
log_to_table(run_id, "classifier", "TRANSIENT", f"7 test cases, all_passed={all_passed}", 0, all_passed)
# --- Step 2: Simulate transient then successful query ---
step(2, "Simulating transient failure → retry → success...")
attempt = 0
max_attempts = 3
success = False
while attempt < max_attempts:
attempt += 1
try:
if attempt == 1:
warn(f"Attempt {attempt}: Simulating OperationalError (warehouse resuming)...")
raise snowflake.connector.errors.OperationalError("Warehouse COMPUTE_WH is resuming")
info(f"Attempt {attempt}: Executing query after simulated resume...")
rows = execute_query(
"SELECT REGION, SUM(USAGE_AMOUNT) AS total "
"FROM PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE "
"GROUP BY REGION ORDER BY total DESC LIMIT 3"
)
ok(f"Query succeeded on attempt {attempt}! Got {len(rows)} rows:")
for r in rows:
print(f" {r['REGION']:20s} → {r['TOTAL']:,.2f}")
success = True
break
except snowflake.connector.errors.OperationalError as e:
retry = should_retry_snowflake(e)
if retry:
warn(f" Classified as TRANSIENT (retry={retry}). Backing off 2s...")
time.sleep(2)
else:
fail(f" Classified as NON-TRANSIENT. Would crash immediately.")
break
log_to_table(run_id, "ingest", "TRANSIENT", f"Simulated WH resume, resolved on attempt {attempt}", attempt, success)
# --- Step 3: Real warehouse suspend/resume cycle ---
step(3, "Testing real warehouse auto-resume behavior...")
try:
rows = execute_query("SHOW WAREHOUSES LIKE 'COMPUTE_WH'")
state = rows[0]["state"] if rows else "UNKNOWN"
info(f"COMPUTE_WH current state: {state}")
start = time.time()
rows = execute_query(
"SELECT COUNT(*) AS cnt FROM PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE"
)
elapsed = time.time() - start
ok(f"Query completed in {elapsed:.2f}s (Snowflake handles resume internally)")
ok(f"Row count: {rows[0]['CNT']:,}")
except Exception as e:
fail(f"Warehouse query failed: {e}")
print(f"n {C.BOLD}Pattern 1 Result:{C.END} RetryPolicy correctly classifies 7 error types")
print(f" and retries transient failures with exponential backoff.n")
# ===========================================================================
# PATTERN 2 - LLM-RECOVERABLE: Bad SQL → Error Feedback → Self-Correction
# ===========================================================================
def demo_pattern_2():
banner("PATTERN 2 - LLM-RECOVERABLE: Bad SQL → Cortex Self-Correction")
run_id = f"demo-p2-{uuid.uuid4().hex[:6]}"
print(f" {C.BOLD}Scenario:{C.END} The LLM generates SQL with a wrong column name.")
print(f" The ToolNode catches the error, returns it as a ToolMessage,")
print(f" and the LLM corrects itself on the next attempt.n")
# --- Step 1: Intentionally bad SQL ---
step(1, "Sending intentionally bad SQL (wrong column name)...")
bad_sql = (
"SELECT ACCOUNT_ID, CREDIT_AMOUNT "
"FROM PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE "
"LIMIT 5"
)
info(f"SQL: {bad_sql[:80]}...")
try:
execute_query(bad_sql)
fail("Query should have failed but didn't!")
except snowflake.connector.errors.ProgrammingError as e:
error_msg = str(e)
ok(f"Got expected error: {error_msg[:100]}...")
step(2, "LLM receives error feedback. Checking schema to self-correct...")
rows = execute_query("DESCRIBE TABLE PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE")
actual_cols = [r["name"] for r in rows]
ok(f"Actual columns: {actual_cols}")
step(3, "LLM generates corrected SQL (CREDIT_AMOUNT → USAGE_AMOUNT)...")
fixed_sql = (
"SELECT ACCOUNT_ID, USAGE_AMOUNT "
"FROM PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE "
"LIMIT 5"
)
info(f"Fixed SQL: {fixed_sql[:80]}...")
rows = execute_query(fixed_sql)
ok(f"Self-corrected query succeeded! Got {len(rows)} rows:")
for r in rows[:3]:
print(f" {r['ACCOUNT_ID']:15s} → {r['USAGE_AMOUNT']}")
log_to_table(run_id, "tools", "LLM_RECOVER", "Bad column CREDIT_AMOUNT → fixed to USAGE_AMOUNT", 1, True)
# --- Step 4: DDL injection blocked ---
step(4, "Testing DDL injection guard (DROP TABLE attempt)...")
from snowflake_langgraph_pipeline import ALLOWED_SELECT_PREFIXES
malicious_sql = "DROP TABLE PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE"
stripped = malicious_sql.strip().upper()
blocked = not any(stripped.startswith(p) for p in ALLOWED_SELECT_PREFIXES)
if blocked:
ok(f"DDL blocked by prefix guard: '{malicious_sql[:40]}...'")
else:
fail("DDL was NOT blocked - security issue!")
log_to_table(run_id, "tools", "LLM_RECOVER", f"DDL guard test, blocked={blocked}", 0, blocked)
# --- Step 5: Real Cortex AI_COMPLETE error recovery ---
step(5, "Testing Cortex AI_COMPLETE with invalid model → error → retry with valid model...")
try:
execute_cortex_complete("test", "nonexistent-model-xyz")
fail("Should have failed with invalid model!")
except Exception as e:
ok(f"Got expected Cortex error: {str(e)[:80]}...")
info("Retrying with valid model (mistral-large2)...")
response = execute_cortex_complete("Reply with exactly: LLM_RECOVERY_TEST_PASS", CORTEX_MODEL)
ok(f"Recovery succeeded: {response.strip()[:60]}")
log_to_table(run_id, "transform", "LLM_RECOVER", "Invalid model → retry with valid model", 1, True)
print(f"n {C.BOLD}Pattern 2 Result:{C.END} Pipeline catches bad SQL and invalid models,")
print(f" feeds errors back to the LLM, which self-corrects.n")
# ===========================================================================
# PATTERN 3 - USER-FIXABLE: Schema Drift, RBAC Gaps, Credit Breach
# ===========================================================================
def demo_pattern_3():
banner("PATTERN 3 - USER-FIXABLE: Schema Drift + RBAC + Credits")
run_id = f"demo-p3-{uuid.uuid4().hex[:6]}"
print(f" {C.BOLD}Scenario:{C.END} A production migration drops a column, a new table lacks")
print(f" RBAC grants, and the credit budget is exceeded. The pipeline")
print(f" detects each, calls interrupt(), and provides remediation SQL.n")
TABLE = "PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE"
# --- 3A: Schema Drift ---
step(1, "SCHEMA DRIFT - Dropping WAREHOUSE_NAME column to simulate migration...")
try:
execute_query(f"ALTER TABLE {TABLE} ADD COLUMN IF NOT EXISTS WAREHOUSE_NAME_BACKUP VARCHAR(100)")
execute_query(f"UPDATE {TABLE} SET WAREHOUSE_NAME_BACKUP = WAREHOUSE_NAME WHERE WAREHOUSE_NAME_BACKUP IS NULL")
execute_query(f"ALTER TABLE {TABLE} DROP COLUMN IF EXISTS WAREHOUSE_NAME")
ok("Column WAREHOUSE_NAME dropped (simulating schema migration)")
step(2, "Pipeline validate_node runs schema drift check...")
drift = check_schema_drift(TABLE, EXPECTED_FACT_USAGE_COLS)
if drift:
fail(f"Schema drift DETECTED:")
print(f" Missing columns: {C.RED}{drift['missing_columns']}{C.END}")
print(f" Extra columns: {C.YELLOW}{drift.get('extra_columns', [])}{C.END}")
info(f"Remediation: {drift['remediation']}")
info("In production: interrupt() pauses pipeline, sends to human reviewer")
log_to_table(run_id, "validate", "USER_FIXABLE", json.dumps(drift), 0, False)
else:
warn("No drift detected (unexpected)")
step(3, "Human applies fix: restoring WAREHOUSE_NAME column...")
execute_query(f"ALTER TABLE {TABLE} ADD COLUMN IF NOT EXISTS WAREHOUSE_NAME VARCHAR(100)")
execute_query(f"UPDATE {TABLE} SET WAREHOUSE_NAME = WAREHOUSE_NAME_BACKUP WHERE WAREHOUSE_NAME IS NULL")
execute_query(f"ALTER TABLE {TABLE} DROP COLUMN IF EXISTS WAREHOUSE_NAME_BACKUP")
drift_after = check_schema_drift(TABLE, EXPECTED_FACT_USAGE_COLS)
if drift_after is None:
ok("Schema drift RESOLVED - column restored, pipeline can resume")
log_to_table(run_id, "validate", "USER_FIXABLE", "Schema drift resolved after human fix", 0, True)
else:
fail(f"Still drifted: {drift_after}")
except Exception as e:
fail(f"Schema drift demo error: {e}")
try:
execute_query(f"ALTER TABLE {TABLE} ADD COLUMN IF NOT EXISTS WAREHOUSE_NAME VARCHAR(100)")
execute_query(f"UPDATE {TABLE} SET WAREHOUSE_NAME = WAREHOUSE_NAME_BACKUP WHERE WAREHOUSE_NAME IS NULL")
execute_query(f"ALTER TABLE {TABLE} DROP COLUMN IF EXISTS WAREHOUSE_NAME_BACKUP")
except Exception:
pass
# --- 3B: RBAC Gap ---
print()
step(4, "RBAC GAP - Revoking SELECT from PIPELINE_SVC_ROLE...")
try:
execute_query(f"REVOKE SELECT ON TABLE {TABLE} FROM ROLE PIPELINE_SVC_ROLE")
ok("SELECT privilege revoked")
step(5, "Pipeline validate_node runs RBAC check...")
rbac = check_rbac_access("PIPELINE_SVC_ROLE", TABLE)
if rbac:
fail(f"RBAC gap DETECTED:")
print(f" Role: {rbac['role']}")
print(f" Table: {rbac['table']}")
print(f" {C.YELLOW}Remediation SQL: {rbac['remediation']}{C.END}")
info("In production: interrupt() pauses, admin runs the GRANT")
log_to_table(run_id, "validate", "USER_FIXABLE", json.dumps(rbac), 0, False)
else:
warn("RBAC gap not detected (may be cached)")
step(6, "Admin applies fix: re-granting SELECT...")
execute_query(f"GRANT SELECT ON TABLE {TABLE} TO ROLE PIPELINE_SVC_ROLE")
ok("GRANT applied - pipeline can resume")
log_to_table(run_id, "validate", "USER_FIXABLE", "RBAC gap resolved after GRANT", 0, True)
except Exception as e:
fail(f"RBAC demo error: {e}")
try:
execute_query(f"GRANT SELECT ON TABLE {TABLE} TO ROLE PIPELINE_SVC_ROLE")
except Exception:
pass
# --- 3C: Credit Budget Breach ---
print()
step(7, "CREDIT BREACH - Simulating 7.5 credits consumed (threshold: 5.0)...")
credit_issue = check_credit_budget(7.5, threshold=5.0)
if credit_issue:
fail(f"Credit threshold BREACHED:")
print(f" Credits used: {C.RED}{credit_issue['credits_used']}{C.END}")
print(f" Threshold: {credit_issue['threshold']}")
info(f"Remediation: {credit_issue['remediation']}")
info("In production: interrupt() pauses, human chooses approve/resize/abort")
log_to_table(run_id, "validate", "USER_FIXABLE", json.dumps(credit_issue), 0, False)
step(8, "Human approves budget override → pipeline resumes at 4.5 credits...")
credit_ok = check_credit_budget(4.5, threshold=5.0)
if credit_ok is None:
ok("Under budget - pipeline continues normally")
else:
fail("Still over budget")
print(f"n {C.BOLD}Pattern 3 Result:{C.END} Pipeline detects schema drift, RBAC gaps, and")
print(f" credit breaches. Each triggers interrupt() with actionable SQL.n")
# ===========================================================================
# PATTERN 4 - UNEXPECTED: Crash Loud, Trace Everything
# ===========================================================================
def demo_pattern_4():
banner("PATTERN 4 - UNEXPECTED: Crash Loud with Full Context")
run_id = f"demo-p4-{uuid.uuid4().hex[:6]}"
print(f" {C.BOLD}Scenario:{C.END} An unexpected KeyError, AttributeError, or schema mismatch")
print(f" hits the pipeline. Instead of silently swallowing it, the pipeline")
print(f" crashes with full state context for a 5-minute postmortem.n")
# --- Step 1: Simulate unexpected KeyError ---
step(1, "Simulating unexpected KeyError in state processing...")
fake_state = {
"query_intent": "top accounts by usage",
"messages": [],
"run_id": run_id,
"retry_count": 0,
}
try:
_ = fake_state["nonexistent_key"]
fail("Should have raised KeyError!")
except KeyError as e:
ok(f"KeyError caught: {e}")
should_retry = should_retry_snowflake(e)
ok(f"Retry classifier says: retry={should_retry} (correct - this is NOT transient)")
info("Full traceback captured for observability:")
tb = traceback.format_exc()
for line in tb.strip().split("n")[-3:]:
print(f" {C.RED}{line}{C.END}")
log_to_table(run_id, "transform", "UNEXPECTED", f"KeyError: {e}", 0, False)
# --- Step 2: Simulate Cortex response shape mismatch ---
step(2, "Simulating unexpected response shape from Cortex...")
try:
response = execute_cortex_complete("Reply with exactly the word: hello", CORTEX_MODEL)
fake_parsed = json.loads(response)
if not isinstance(fake_parsed, dict) or "sql" not in fake_parsed:
raise TypeError(f"Expected dict with 'sql' key, got {type(fake_parsed).__name__}: {str(fake_parsed)[:60]}")
fail("Should have failed - response doesn't have expected schema!")
except (json.JSONDecodeError, TypeError, AssertionError) as e:
ok(f"Response shape mismatch caught: {type(e).__name__}")
info("Pipeline would crash here - no retry, no swallow")
info(f"Actual response: '{response.strip()[:60]}...'")
log_to_table(run_id, "transform", "UNEXPECTED", f"Response shape mismatch: {e}", 0, False)
# --- Step 3: Verify crash context includes state snapshot ---
step(3, "Verifying state snapshot is preserved for postmortem...")
state_snapshot = {
"run_id": run_id,
"node": "transform",
"query_intent": fake_state["query_intent"],
"retry_count": fake_state["retry_count"],
"error_class": "UNEXPECTED",
"timestamp": time.strftime("%Y-%m-%dT%H:%M:%SZ"),
}
execute_query(
"INSERT INTO PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_CHECKPOINT "
"(THREAD_ID, NODE_NAME, STATE_JSON) "
f"SELECT '{run_id}', 'crash_snapshot', PARSE_JSON('{json.dumps(state_snapshot)}')"
)
rows = execute_query(
f"SELECT STATE_JSON FROM PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_CHECKPOINT "
f"WHERE THREAD_ID = '{run_id}'"
)
if rows:
ok("Crash state snapshot persisted to PIPELINE_CHECKPOINT")
snapshot = json.loads(rows[0]["STATE_JSON"]) if isinstance(rows[0]["STATE_JSON"], str) else rows[0]["STATE_JSON"]
for k, v in snapshot.items():
print(f" {k:20s} = {v}")
else:
fail("State snapshot not found!")
# --- Step 4: Query the error log ---
step(4, "Querying PIPELINE_STATE_LOG for this run's errors...")
rows = execute_query(
f"SELECT NODE_NAME, ERROR_CLASS, ERROR_MESSAGE, RETRY_COUNT "
f"FROM PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_STATE_LOG "
f"WHERE RUN_ID = '{run_id}' ORDER BY CREATED_AT"
)
if rows:
ok(f"Found {len(rows)} error entries for run {run_id}:")
for r in rows:
print(f" [{r['ERROR_CLASS']}] {r['NODE_NAME']}: {r['ERROR_MESSAGE'][:60]}...")
else:
warn("No log entries found (may be latency)")
print(f"n {C.BOLD}Pattern 4 Result:{C.END} Unexpected errors crash with full context.")
print(f" State snapshots + error logs enable 5-minute postmortems.n")
# ===========================================================================
# PATTERN 5 - FULL END-TO-END: Real pipeline run with all checks
# ===========================================================================
def demo_full_pipeline():
banner("FULL END-TO-END: Real Pipeline Execution")
run_id = f"demo-e2e-{uuid.uuid4().hex[:6]}"
print(f" {C.BOLD}Scenario:{C.END} Run the actual LangGraph pipeline end-to-end.")
print(f" All 4 error patterns are active: RetryPolicy on ingest/transform,")
print(f" ToolNode error handling, validate_node with interrupt(), and")
print(f" unexpected errors crash loud.n")
intent = "Show me the top 3 regions by total usage amount in the last 30 days"
step(1, f"Launching pipeline: '{intent}'")
start = time.time()
try:
result = run_pipeline(intent)
elapsed = time.time() - start
ok(f"Pipeline completed in {elapsed:.1f}s")
print(f"n Run ID: {C.BOLD}{result['run_id']}{C.END}")
print(f" Messages: {result['messages_count']}")
print(f" Errors: {len(result['errors'])}")
print(f"n {C.BOLD}Summary:{C.END}")
for line in result["summary"].strip().split("n"):
print(f" {line}")
if result["errors"]:
print(f"n {C.YELLOW}Errors detected:{C.END}")
for err in result["errors"]:
print(f" [{err.get('class')}] {json.dumps(err.get('errors', []))[:100]}")
except Exception as e:
elapsed = time.time() - start
fail(f"Pipeline failed after {elapsed:.1f}s: {e}")
info("This is Pattern 4 in action - unexpected error with full traceback:")
traceback.print_exc()
# --- Step 2: Verify observability ---
step(2, "Checking observability tables...")
rows = execute_query(
"SELECT COUNT(*) AS cnt FROM PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_STATE_LOG"
)
info(f"Total error log entries: {rows[0]['CNT']}")
rows = execute_query(
"SELECT COUNT(*) AS cnt FROM PIPELINE_ERROR_HANDLING.PIPELINE.CORTEX_SUMMARIES"
)
info(f"Total Cortex summaries: {rows[0]['CNT']}")
rows = execute_query(
"SELECT RUN_ID, LEFT(SUMMARY_TEXT, 100) AS preview "
"FROM PIPELINE_ERROR_HANDLING.PIPELINE.CORTEX_SUMMARIES "
"ORDER BY CREATED_AT DESC LIMIT 3"
)
if rows:
ok("Recent summaries:")
for r in rows:
print(f" [{r['RUN_ID']}] {r['PREVIEW']}...")
print(f"n {C.BOLD}End-to-End Result:{C.END} Full pipeline with all error patterns active.n")
# ===========================================================================
# MAIN - Run all patterns or a specific one
# ===========================================================================
if __name__ == "__main__":
pattern = None
if "--pattern" in sys.argv:
idx = sys.argv.index("--pattern")
if idx + 1 < len(sys.argv):
pattern = int(sys.argv[idx + 1])
banner("SNOWFLAKE LANGGRAPH ERROR-HANDLING DEMO")
print(f" Account: {SNOWFLAKE_CONFIG['account']}")
print(f" User: {SNOWFLAKE_CONFIG['user']}")
print(f" Warehouse: {SNOWFLAKE_CONFIG['warehouse']}")
print(f" Model: {CORTEX_MODEL}")
print(f" Database: {SNOWFLAKE_CONFIG['database']}")
print()
demos = {
1: ("TRANSIENT errors (connector retry)", demo_pattern_1),
2: ("LLM-RECOVERABLE errors (bad SQL, bad model)", demo_pattern_2),
3: ("USER-FIXABLE errors (schema drift, RBAC, credits)", demo_pattern_3),
4: ("UNEXPECTED errors (crash loud, trace)", demo_pattern_4),
5: ("FULL END-TO-END pipeline run", demo_full_pipeline),
}
if pattern:
if pattern in demos:
label, func = demos[pattern]
info(f"Running Pattern {pattern}: {label}")
func()
else:
fail(f"Invalid pattern: {pattern}. Choose 1-5.")
sys.exit(1)
else:
info("Running ALL patterns (1-5)...n")
for num, (label, func) in demos.items():
try:
func()
except Exception as e:
fail(f"Pattern {num} crashed: {e}")
traceback.print_exc()
print()
banner("DEMO COMPLETE")
rows = execute_query(
"SELECT ERROR_CLASS, COUNT(*) AS cnt, "
"SUM(CASE WHEN RESOLVED THEN 1 ELSE 0 END) AS resolved "
"FROM PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_STATE_LOG "
"WHERE RUN_ID LIKE 'demo-%' "
"GROUP BY ERROR_CLASS ORDER BY cnt DESC"
)
if rows:
print(f" {C.BOLD}Error Summary from this demo run:{C.END}n")
print(f" {'CLASS':20s} {'COUNT':>8s} {'RESOLVED':>10s}")
print(f" {'-'*40}")
for r in rows:
print(f" {r['ERROR_CLASS']:20s} {r['CNT']:>8d} {r['RESOLVED']:>10d}")
print()
pipeline_infrastructure_sql.sql
-- =============================================================================
-- PHASE 1: INFRASTRUCTURE — Database, Schema, Roles, Warehouses
-- =============================================================================
-- Run as ACCOUNTADMIN on trial account (lw82771 / AWS_US_EAST_2)
USE ROLE ACCOUNTADMIN;
CREATE DATABASE IF NOT EXISTS PIPELINE_ERROR_HANDLING;
CREATE SCHEMA IF NOT EXISTS PIPELINE_ERROR_HANDLING.PIPELINE;
CREATE SCHEMA IF NOT EXISTS PIPELINE_ERROR_HANDLING.OBSERVABILITY;
CREATE ROLE IF NOT EXISTS PIPELINE_SVC_ROLE;
GRANT USAGE ON DATABASE PIPELINE_ERROR_HANDLING TO ROLE PIPELINE_SVC_ROLE;
GRANT USAGE ON SCHEMA PIPELINE_ERROR_HANDLING.PIPELINE TO ROLE PIPELINE_SVC_ROLE;
GRANT USAGE ON SCHEMA PIPELINE_ERROR_HANDLING.OBSERVABILITY TO ROLE PIPELINE_SVC_ROLE;
GRANT CREATE TABLE ON SCHEMA PIPELINE_ERROR_HANDLING.PIPELINE TO ROLE PIPELINE_SVC_ROLE;
GRANT SELECT ON ALL TABLES IN SCHEMA PIPELINE_ERROR_HANDLING.PIPELINE TO ROLE PIPELINE_SVC_ROLE;
GRANT SELECT ON FUTURE TABLES IN SCHEMA PIPELINE_ERROR_HANDLING.PIPELINE TO ROLE PIPELINE_SVC_ROLE;
GRANT USAGE ON WAREHOUSE COMPUTE_WH TO ROLE PIPELINE_SVC_ROLE;
GRANT ROLE PIPELINE_SVC_ROLE TO ROLE ACCOUNTADMIN;
-- =============================================================================
-- PHASE 2: SAMPLE DATA - Tables the pipeline operates on
-- =============================================================================
USE SCHEMA PIPELINE_ERROR_HANDLING.PIPELINE;
CREATE OR REPLACE TABLE FACT_USAGE (
ACCOUNT_ID VARCHAR(50) NOT NULL,
EVENT_TS TIMESTAMP_NTZ NOT NULL,
USAGE_AMOUNT NUMBER(18,4) NOT NULL,
REGION VARCHAR(30) NOT NULL,
SERVICE_TYPE VARCHAR(50),
WAREHOUSE_NAME VARCHAR(100)
);
INSERT INTO FACT_USAGE (ACCOUNT_ID, EVENT_TS, USAGE_AMOUNT, REGION, SERVICE_TYPE, WAREHOUSE_NAME)
SELECT
'ACCT-' || UNIFORM(1, 100, RANDOM())::VARCHAR,
DATEADD('minute', -UNIFORM(1, 43200, RANDOM()), CURRENT_TIMESTAMP()),
ROUND(UNIFORM(0.01, 50.00, RANDOM())::NUMBER(18,4), 4),
ARRAY_CONSTRUCT('US-EAST-1','US-WEST-2','EU-WEST-1','AP-SOUTHEAST-1')[UNIFORM(0,3,RANDOM())],
ARRAY_CONSTRUCT('WAREHOUSE','AI_SERVICES','SERVERLESS','STORAGE')[UNIFORM(0,3,RANDOM())],
ARRAY_CONSTRUCT('COMPUTE_WH','DATA_SCIENCE_WH','ENGINEERING_WH','SALES_WH')[UNIFORM(0,3,RANDOM())]
FROM TABLE(GENERATOR(ROWCOUNT => 10000));
CREATE OR REPLACE TABLE PIPELINE_STATE_LOG (
RUN_ID VARCHAR(50) NOT NULL,
NODE_NAME VARCHAR(50) NOT NULL,
ERROR_CLASS VARCHAR(30),
ERROR_MESSAGE VARCHAR(5000),
RETRY_COUNT INT DEFAULT 0,
CREDITS_CONSUMED NUMBER(18,6) DEFAULT 0,
RESOLVED BOOLEAN DEFAULT FALSE,
CREATED_AT TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
);
CREATE OR REPLACE TABLE PIPELINE_CHECKPOINT (
THREAD_ID VARCHAR(100) NOT NULL,
NODE_NAME VARCHAR(50) NOT NULL,
STATE_JSON VARIANT NOT NULL,
UPDATED_AT TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP(),
CONSTRAINT PK_CHECKPOINT PRIMARY KEY (THREAD_ID, NODE_NAME)
);
CREATE OR REPLACE TABLE CORTEX_SUMMARIES (
RUN_ID VARCHAR(50) NOT NULL,
QUERY_INTENT VARCHAR(2000),
SUMMARY_TEXT VARCHAR(10000),
MODEL_USED VARCHAR(50),
CREATED_AT TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
);
-- =============================================================================
-- PHASE 3: HELPER PROCEDURES - Snowflake-native building blocks
-- =============================================================================
-- 3A. Schema drift detector
CREATE OR REPLACE PROCEDURE PIPELINE_ERROR_HANDLING.PIPELINE.CHECK_SCHEMA_DRIFT(
P_DATABASE VARCHAR, P_SCHEMA VARCHAR, P_TABLE VARCHAR, P_EXPECTED_COLS ARRAY
)
RETURNS VARIANT
LANGUAGE SQL
AS
$$
DECLARE
actual_cols ARRAY;
missing ARRAY DEFAULT ARRAY_CONSTRUCT();
col VARCHAR;
i INT DEFAULT 0;
rs RESULTSET;
info_q VARCHAR;
BEGIN
info_q := 'SELECT ARRAY_AGG(COLUMN_NAME) AS COLS FROM ' || P_DATABASE || '.INFORMATION_SCHEMA.COLUMNS WHERE TABLE_SCHEMA = ''' || P_SCHEMA || ''' AND TABLE_NAME = ''' || P_TABLE || '''';
rs := (EXECUTE IMMEDIATE :info_q);
LET cur CURSOR FOR rs;
OPEN cur;
FETCH cur INTO actual_cols;
CLOSE cur;
WHILE (i < ARRAY_SIZE(:P_EXPECTED_COLS)) DO
col := P_EXPECTED_COLS[i]::VARCHAR;
IF (NOT ARRAY_CONTAINS(col::VARIANT, actual_cols)) THEN
missing := ARRAY_APPEND(missing, col);
END IF;
i := i + 1;
END WHILE;
RETURN OBJECT_CONSTRUCT(
'has_drift', ARRAY_SIZE(:missing) > 0,
'missing_columns', :missing,
'actual_columns', :actual_cols
);
END;
$$;
-- 3B. RBAC privilege checker
CREATE OR REPLACE PROCEDURE PIPELINE_ERROR_HANDLING.PIPELINE.CHECK_ROLE_PRIVILEGE(
P_ROLE VARCHAR, P_PRIVILEGE VARCHAR, P_OBJECT VARCHAR
)
RETURNS VARIANT
LANGUAGE SQL
AS
$$
DECLARE
has_priv BOOLEAN DEFAULT FALSE;
grant_count INT;
BEGIN
SELECT COUNT(*) INTO grant_count
FROM SNOWFLAKE.ACCOUNT_USAGE.GRANTS_TO_ROLES
WHERE GRANTEE_NAME = :P_ROLE
AND PRIVILEGE = :P_PRIVILEGE
AND NAME = SPLIT_PART(:P_OBJECT, '.', -1)
AND DELETED_ON IS NULL;
has_priv := (grant_count > 0);
RETURN OBJECT_CONSTRUCT(
'role', :P_ROLE,
'privilege', :P_PRIVILEGE,
'object', :P_OBJECT,
'has_privilege', :has_priv,
'remediation_sql', CASE WHEN NOT has_priv
THEN 'GRANT ' || P_PRIVILEGE || ' ON TABLE ' || P_OBJECT || ' TO ROLE ' || P_ROLE || ';'
ELSE NULL END
);
END;
$$;
-- 3C. Credit estimator (simplified for trial - uses query history)
CREATE OR REPLACE PROCEDURE PIPELINE_ERROR_HANDLING.PIPELINE.ESTIMATE_QUERY_COST(
P_WAREHOUSE VARCHAR
)
RETURNS VARIANT
LANGUAGE SQL
AS
$$
DECLARE
avg_credits NUMBER(18,6) DEFAULT 0;
max_credits NUMBER(18,6) DEFAULT 0;
BEGIN
SELECT
COALESCE(AVG(CREDITS_USED_CLOUD_SERVICES), 0),
COALESCE(MAX(CREDITS_USED_CLOUD_SERVICES), 0)
INTO avg_credits, max_credits
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY
WHERE WAREHOUSE_NAME = :P_WAREHOUSE
AND START_TIME >= DATEADD('hour', -24, CURRENT_TIMESTAMP())
AND EXECUTION_STATUS = 'SUCCESS';
RETURN OBJECT_CONSTRUCT(
'warehouse', :P_WAREHOUSE,
'avg_credits_24h', :avg_credits,
'max_credits_24h', :max_credits,
'exceeds_threshold', :max_credits > 5.0
);
END;
$$;
ALTER USER SATISH SET RSA_PUBLIC_KEY='xxxxxxyyyyyyy++7R4l5Z6L9I8JcuYBrSzrDDgaW6df9OABFQvypdGS/HKXKBZ0V8q66cE0mGCo0148C1yVSTOahp9ILcAYzEE85Aq+JgSQIguW5kCEMsZ61eaz9jl7F3oHPbom2q6G1+GmnYCaDB4LP0qAXTYYaQfGFJlQy/yO152oYqfVfNzJtMghnNmTVAMMSx/NZQky53nSdl+VPtQ44isLfDnCXtWezZHu33oGAonVVkMrPzPFx1y+H83fjImWWFFNWX/vp9KaYgZm1nguuCBwGWNRkUcSBWv3ghOv0uia1mwLbd2+oS10J0a5R2/teWKlBV7lwoWVKMmi827C29+YmSNQIDAQAB%';
pipeline_observability.sql
-- =============================================================================
-- OBSERVABILITY DASHBOARD QUERIES
-- =============================================================================
-- Run after pipeline executions to monitor error patterns and credit burn.
-- All queries target ACCOUNT_USAGE views + pipeline logging tables.
-- =============================================================================
pipeline_test_harness.sql
-- =============================================================================
-- TEST HARNESS: Validate all 4 error patterns on trial account
-- =============================================================================
-- Run as ACCOUNTADMIN after executing pipeline_infrastructure_sql.sql
-- Each test is independent and labeled by error pattern.
-- =============================================================================
USE ROLE ACCOUNTADMIN;
USE WAREHOUSE COMPUTE_WH;
-- =========================================================
-- Q1: Pipeline error distribution by class
-- =========================================================
SELECT
ERROR_CLASS,
COUNT(*) AS error_count,
AVG(RETRY_COUNT) AS avg_retries,
SUM(CASE WHEN RESOLVED THEN 1 ELSE 0 END) AS resolved_count,
SUM(CASE WHEN NOT RESOLVED THEN 1 ELSE 0 END) AS unresolved_count
FROM PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_STATE_LOG
GROUP BY ERROR_CLASS
ORDER BY error_count DESC;
-- =========================================================
-- Q2: Cortex AI credit consumption (last 7 days)
-- =========================================================
SELECT
DATE_TRUNC('day', START_TIME) AS usage_day,
FUNCTION_NAME,
COUNT(*) AS call_count,
SUM(TOKENS) AS total_tokens,
SUM(TOKEN_CREDITS) AS total_credits
FROM SNOWFLAKE.ACCOUNT_USAGE.CORTEX_FUNCTIONS_USAGE_HISTORY
WHERE START_TIME >= DATEADD('day', -7, CURRENT_TIMESTAMP())
GROUP BY usage_day, FUNCTION_NAME
ORDER BY usage_day DESC, total_credits DESC;
-- =========================================================
-- Q3: Warehouse credit burn rate (hourly, last 24h)
-- =========================================================
SELECT
DATE_TRUNC('hour', START_TIME) AS hour_bucket,
WAREHOUSE_NAME,
SUM(CREDITS_USED_CLOUD_SERVICES) AS cloud_credits,
COUNT(DISTINCT QUERY_ID) AS query_count
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY
WHERE START_TIME >= DATEADD('hour', -24, CURRENT_TIMESTAMP())
AND WAREHOUSE_NAME IS NOT NULL
GROUP BY hour_bucket, WAREHOUSE_NAME
ORDER BY hour_bucket DESC;
-- =========================================================
-- Q4: Failed queries by error type (last 24h)
-- =========================================================
SELECT
ERROR_CODE,
ERROR_MESSAGE,
COUNT(*) AS failure_count,
MIN(START_TIME) AS first_seen,
MAX(START_TIME) AS last_seen
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY
WHERE START_TIME >= DATEADD('hour', -24, CURRENT_TIMESTAMP())
AND EXECUTION_STATUS = 'FAIL'
GROUP BY ERROR_CODE, ERROR_MESSAGE
ORDER BY failure_count DESC
LIMIT 20;
-- =========================================================
-- Q5: Pipeline run summary (join state log with Cortex summaries)
-- =========================================================
SELECT
s.RUN_ID,
COUNT(DISTINCT s.NODE_NAME) AS nodes_touched,
COUNT(*) AS total_errors,
SUM(s.RETRY_COUNT) AS total_retries,
SUM(CASE WHEN s.RESOLVED THEN 1 ELSE 0 END) AS resolved,
c.MODEL_USED,
LEFT(c.SUMMARY_TEXT, 200) AS summary_preview,
c.CREATED_AT AS completed_at
FROM PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_STATE_LOG s
LEFT JOIN PIPELINE_ERROR_HANDLING.PIPELINE.CORTEX_SUMMARIES c
ON s.RUN_ID = c.RUN_ID
GROUP BY s.RUN_ID, c.MODEL_USED, c.SUMMARY_TEXT, c.CREATED_AT
ORDER BY c.CREATED_AT DESC NULLS LAST;
-- =========================================================
-- Q6: Credit efficiency evaluator query
-- =========================================================
WITH run_costs AS (
SELECT
sl.RUN_ID,
SUM(sl.CREDITS_CONSUMED) AS pipeline_credits,
COUNT(*) AS error_count,
SUM(sl.RETRY_COUNT) AS total_retries
FROM PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_STATE_LOG sl
GROUP BY sl.RUN_ID
)
SELECT
RUN_ID,
pipeline_credits,
error_count,
total_retries,
CASE
WHEN pipeline_credits < 1.0 THEN 'EFFICIENT'
WHEN pipeline_credits < 5.0 THEN 'ACCEPTABLE'
ELSE 'OVER_BUDGET'
END AS efficiency_rating
FROM run_costs
ORDER BY pipeline_credits DESC;
-- =========================================================
-- Q7: Cross-region inference check
-- =========================================================
SHOW PARAMETERS LIKE 'CORTEX_ENABLED_CROSS_REGION' IN ACCOUNT;
-- If DISABLED, any model not in your home region will fail silently.
-- Your account (AWS_US_EAST_2) has it set to ANY_REGION - good.
-- Remediation if disabled:
-- ALTER ACCOUNT SET CORTEX_ENABLED_CROSS_REGION = 'ANY_REGION';
-- =========================================================
-- Q8: Cortex per-query cost tracking (joins query history with Cortex usage)
-- =========================================================
SELECT
qh.QUERY_ID,
qh.QUERY_TEXT,
qh.WAREHOUSE_NAME,
qh.EXECUTION_STATUS,
qh.TOTAL_ELAPSED_TIME / 1000.0 AS elapsed_sec,
qh.CREDITS_USED_CLOUD_SERVICES,
cu.TOKENS,
cu.TOKEN_CREDITS AS cortex_credits
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY qh
LEFT JOIN SNOWFLAKE.ACCOUNT_USAGE.CORTEX_FUNCTIONS_QUERY_USAGE_HISTORY cu
ON qh.QUERY_ID = cu.QUERY_ID
WHERE qh.START_TIME >= DATEADD('hour', -6, CURRENT_TIMESTAMP())
AND qh.QUERY_TEXT ILIKE '%AI_COMPLETE%'
ORDER BY qh.START_TIME DESC
LIMIT 50;
--====
USE ROLE ACCOUNTADMIN;
USE WAREHOUSE COMPUTE_WH;
USE SCHEMA PIPELINE_ERROR_HANDLING.PIPELINE;
-- =========================================================
-- TEST 0: Verify infrastructure exists
-- =========================================================
SELECT 'FACT_USAGE' AS test_table, COUNT(*) AS row_count
FROM PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE;
SELECT 'PIPELINE_STATE_LOG' AS test_table, COUNT(*) AS row_count
FROM PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_STATE_LOG;
SELECT 'PIPELINE_CHECKPOINT' AS test_table, COUNT(*) AS row_count
FROM PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_CHECKPOINT;
SELECT 'CORTEX_SUMMARIES' AS test_table, COUNT(*) AS row_count
FROM PIPELINE_ERROR_HANDLING.PIPELINE.CORTEX_SUMMARIES;
-- =========================================================
-- TEST 1: PATTERN 1 - TRANSIENT (Cortex AI_COMPLETE works)
-- =========================================================
-- Validates that AI_COMPLETE is available in your region.
-- If this fails with "Unknown function", cross-region is disabled.
SELECT AI_COMPLETE(
'mistral-large2',
'Respond with exactly: TRANSIENT_TEST_PASS'
) AS pattern1_cortex_test;
-- =========================================================
-- TEST 2: PATTERN 2 - LLM-RECOVERABLE (bad SQL → clear error)
-- =========================================================
-- Simulates what the ToolNode sees: a query against a non-existent column.
-- The error message should be clear enough for the LLM to self-correct.
-- This SHOULD fail with a clear column error:
-- SELECT NONEXISTENT_COLUMN FROM PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE LIMIT 1;
-- This SHOULD succeed (the LLM's corrected version):
SELECT ACCOUNT_ID, USAGE_AMOUNT
FROM PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE
LIMIT 5;
-- =========================================================
-- TEST 3: PATTERN 3A - USER-FIXABLE: Schema Drift Detection
-- =========================================================
CALL PIPELINE_ERROR_HANDLING.PIPELINE.CHECK_SCHEMA_DRIFT(
'PIPELINE_ERROR_HANDLING',
'PIPELINE',
'FACT_USAGE',
ARRAY_CONSTRUCT('ACCOUNT_ID', 'EVENT_TS', 'USAGE_AMOUNT', 'REGION', 'SERVICE_TYPE', 'WAREHOUSE_NAME')
);
-- Expected: has_drift = false (all columns present)
CALL PIPELINE_ERROR_HANDLING.PIPELINE.CHECK_SCHEMA_DRIFT(
'PIPELINE_ERROR_HANDLING',
'PIPELINE',
'FACT_USAGE',
ARRAY_CONSTRUCT('ACCOUNT_ID', 'EVENT_TS', 'USAGE_AMOUNT', 'REGION', 'FAKE_COLUMN_XYZ')
);
-- Expected: has_drift = true, missing_columns = ['FAKE_COLUMN_XYZ']
-- =========================================================
-- TEST 3B: PATTERN 3 - USER-FIXABLE: RBAC Privilege Check
-- =========================================================
CALL PIPELINE_ERROR_HANDLING.PIPELINE.CHECK_ROLE_PRIVILEGE(
'PIPELINE_SVC_ROLE',
'SELECT',
'PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE'
);
-- Expected: has_privilege = true (we granted it in Phase 1)
-- NOTE: GRANTS_TO_ROLES in ACCOUNT_USAGE has up to 2-hour latency.
-- If this returns false on a fresh account, wait and re-run.
CALL PIPELINE_ERROR_HANDLING.PIPELINE.CHECK_ROLE_PRIVILEGE(
'PIPELINE_SVC_ROLE',
'DELETE',
'PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE'
);
-- Expected: has_privilege = false, remediation_sql provided
-- =========================================================
-- TEST 3C: PATTERN 3 - USER-FIXABLE: Credit Estimation
-- =========================================================
CALL PIPELINE_ERROR_HANDLING.PIPELINE.ESTIMATE_QUERY_COST('COMPUTE_WH');
-- Expected: returns avg/max credits for last 24h
-- =========================================================
-- TEST 4: PATTERN 4 - UNEXPECTED: Observability tables work
-- =========================================================
INSERT INTO PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_STATE_LOG
(RUN_ID, NODE_NAME, ERROR_CLASS, ERROR_MESSAGE, RETRY_COUNT, RESOLVED)
VALUES ('test-001', 'ingest', 'TRANSIENT', 'Warehouse resuming from suspend', 2, TRUE);
INSERT INTO PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_STATE_LOG
(RUN_ID, NODE_NAME, ERROR_CLASS, ERROR_MESSAGE, RETRY_COUNT, RESOLVED)
VALUES ('test-001', 'validate', 'USER_FIXABLE', 'Schema drift: FAKE_COLUMN missing', 0, FALSE);
INSERT INTO PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_STATE_LOG
(RUN_ID, NODE_NAME, ERROR_CLASS, ERROR_MESSAGE, RETRY_COUNT, RESOLVED)
VALUES ('test-002', 'transform', 'LLM_RECOVER', 'Bad column name in generated SQL', 1, TRUE);
SELECT RUN_ID, NODE_NAME, ERROR_CLASS, ERROR_MESSAGE, RETRY_COUNT, RESOLVED
FROM PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_STATE_LOG
ORDER BY CREATED_AT;
-- =========================================================
-- TEST 5: End-to-end Cortex summarization (the SUMMARIZE node)
-- =========================================================
SELECT AI_COMPLETE(
'mistral-large2',
'Summarize this Snowflake usage data in 2 sentences: ' ||
'Total rows: 10000, Date range: last 30 days, ' ||
'Top region: US-EAST-1, Top service: WAREHOUSE, ' ||
'Average usage: 25.5 credits per account.'
) AS pattern4_summarize_test;
-- =========================================================
-- TEST 6: CHECKPOINT table - verify state persistence works
-- =========================================================
MERGE INTO PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_CHECKPOINT AS tgt
USING (
SELECT
'test-thread-001' AS THREAD_ID,
'ingest' AS NODE_NAME,
PARSE_JSON('{"query_intent":"test","retry_count":0}') AS STATE_JSON
) AS src
ON tgt.THREAD_ID = src.THREAD_ID AND tgt.NODE_NAME = src.NODE_NAME
WHEN MATCHED THEN UPDATE SET STATE_JSON = src.STATE_JSON, UPDATED_AT = CURRENT_TIMESTAMP()
WHEN NOT MATCHED THEN INSERT (THREAD_ID, NODE_NAME, STATE_JSON) VALUES (src.THREAD_ID, src.NODE_NAME, src.STATE_JSON);
SELECT * FROM PIPELINE_ERROR_HANDLING.PIPELINE.PIPELINE_CHECKPOINT;
-- =========================================================
-- TEST 7: Simulated schema drift then recovery
-- =========================================================
-- Add a column, detect no drift, drop it, detect drift.
ALTER TABLE PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE ADD COLUMN IF NOT EXISTS TEMP_TEST_COL VARCHAR(10);
CALL PIPELINE_ERROR_HANDLING.PIPELINE.CHECK_SCHEMA_DRIFT(
'PIPELINE_ERROR_HANDLING', 'PIPELINE', 'FACT_USAGE',
ARRAY_CONSTRUCT('ACCOUNT_ID', 'EVENT_TS', 'USAGE_AMOUNT', 'REGION', 'SERVICE_TYPE', 'WAREHOUSE_NAME', 'TEMP_TEST_COL')
);
-- Expected: has_drift = false
ALTER TABLE PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE DROP COLUMN IF EXISTS TEMP_TEST_COL;
CALL PIPELINE_ERROR_HANDLING.PIPELINE.CHECK_SCHEMA_DRIFT(
'PIPELINE_ERROR_HANDLING', 'PIPELINE', 'FACT_USAGE',
ARRAY_CONSTRUCT('ACCOUNT_ID', 'EVENT_TS', 'USAGE_AMOUNT', 'REGION', 'SERVICE_TYPE', 'WAREHOUSE_NAME', 'TEMP_TEST_COL')
);
-- Expected: has_drift = true, missing = TEMP_TEST_COL
Setup Guide — File by File
Five files, executed in order. Each section below tells you exactly what the file does, what to edit before running it, how to run it, and what a successful result looks like.
pipeline_infrastructure_sql.sql ← Run first (Snowsight)
snowflake_langgraph_pipeline.py ← Edit + save second (local)
demo_error_patterns.py ← Run third (terminal)
pipeline_test_harness.sql ← Run fourth (Snowsight)
pipeline_observability.sql ← Run last (Snowsight, after pipeline runs)
Prerequisites
Before touching any file, confirm you have:
- A Snowflake trial account — free 30-day signup at snowflake.com, $400 compute credits included
- Python 3.9 or higher (python3 –version)
- openssl available in your terminal (openssl version)
- macOS or Linux (Windows users: use WSL2)
0. One-time: Install Python dependencies
pip install langgraph>=0.3 langchain-core>=0.3 snowflake-connector-python>=3.6 cryptography
Verify:
python3 -c "import langgraph, langchain_core, snowflake.connector, cryptography; print('all imports OK')"
Expected output: all imports OK
0. One-time: Generate key-pair authentication
Snowflake trial accounts enforce MFA for all programmatic logins — password and externalbrowser auth both fail. Key-pair auth is the only reliable method for automation.
Generate the key:
mkdir -p ~/.snowflake
openssl genrsa 2048 | openssl pkcs8 -topk8 -inform PEM -out ~/.snowflake/rsa_key.p8 -nocrypt
openssl rsa -in ~/.snowflake/rsa_key.p8 -pubout -out ~/.snowflake/rsa_key.pub
chmod 600 ~/.snowflake/rsa_key.p8
Copy the public key (no headers, no newlines):
grep -v "PUBLIC KEY" ~/.snowflake/rsa_key.pub | tr -d 'n'
Register the key in Snowsight — open a Snowsight worksheet and run:
ALTER USER <YOUR_USERNAME> SET RSA_PUBLIC_KEY='<paste the base64 string here>';
Replace <YOUR_USERNAME> with your Snowflake login (e.g. SATISH). The key string has no quotes around it other than the single-quote delimiters.
Verify it worked:
DESC USER <YOUR_USERNAME>;
-- Look for RSA_PUBLIC_KEY_FP in the output — it should show a fingerprint, not NULL
File 1 of 5 — pipeline_infrastructure_sql.sql
What it does: Creates everything Snowflake-side — the database, two schemas, the service role with correct grants, four tables (FACT_USAGE, PIPELINE_STATE_LOG, PIPELINE_CHECKPOINT, CORTEX_SUMMARIES), 10,000 rows of sample usage data, and three stored procedures (CHECK_SCHEMA_DRIFT, CHECK_ROLE_PRIVILEGE, ESTIMATE_QUERY_COST).
Nothing to edit — this file runs as-is.
How to run:
- Open Snowsight
- Click Projects → Worksheets → + New Worksheet
- Paste the full contents of pipeline_infrastructure_sql.sql
- Select Run All (the ▶▶ button) or press Cmd+Shift+Enter
Run it in three phases — the file has phase markers. You can run all at once or section by section:
- Phase 1 (lines 1–18): Database, schemas, role, grants
- Phase 2 (lines 21–75): Tables + 10,000 row insert
- Phase 3 (lines 78–180): Three stored procedures
Verify success:
-- Should return 4 rows, each with row_count > 0
SELECT TABLE_NAME, ROW_COUNT
FROM PIPELINE_ERROR_HANDLING.INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'PIPELINE'
ORDER BY TABLE_NAME;
-- Should return 10000
SELECT COUNT(*) FROM PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE;
-- Should return 3 procedures
SHOW PROCEDURES IN SCHEMA PIPELINE_ERROR_HANDLING.PIPELINE;
File 2 of 5 — snowflake_langgraph_pipeline.py
What it does: The core pipeline — all four error patterns live here. Defines the LangGraph StateGraph, all five nodes, the retry policies, the three Snowflake tools, the error classifiers, the interrupt() validators, and the evaluators.
What to edit before running:
Open snowflake_langgraph_pipeline.py and update SNOWFLAKE_CONFIG at line 62:
SNOWFLAKE_CONFIG = {
"account": "YOUR_ACCOUNT.YOUR_REGION.aws", # ← change this
"user": "YOUR_USERNAME", # ← change this
"private_key": _load_private_key(), # ← no change needed
"warehouse": "COMPUTE_WH", # ← change if your WH has a different name
"database": "PIPELINE_ERROR_HANDLING", # ← no change needed
"schema": "PIPELINE", # ← no change needed
"role": "ACCOUNTADMIN", # ← no change needed
}
How to find your account identifier:
-- Run this in Snowsight
SELECT CURRENT_ACCOUNT(), CURRENT_REGION();
The account identifier format is <locator>.<region>.<cloud>, e.g. lw82771.us-east-2.aws. The locator alone (lw82771) returns a 404 — the region suffix is required.
Optional — set via environment variables instead of hardcoding:
export SNOWFLAKE_PRIVATE_KEY_PATH=~/.snowflake/rsa_key.p8
export SNOWFLAKE_PRIVATE_KEY_PASSPHRASE="" # leave blank if key was generated with -nocrypt
Verify the config is correct before running the full pipeline:
python3 -c "
from snowflake_langgraph_pipeline import execute_query
rows = execute_query('SELECT CURRENT_USER(), CURRENT_WAREHOUSE(), CURRENT_DATABASE()')
print(rows[0])
"
Expected output: {‘CURRENT_USER()’: ‘SATISH’, ‘CURRENT_WAREHOUSE()’: ‘COMPUTE_WH’, ‘CURRENT_DATABASE()’: ‘PIPELINE_ERROR_HANDLING’}
If this works, the connection is good and the pipeline will run.
How to run a single pipeline query:
python3 snowflake_langgraph_pipeline.py "What are the top 5 accounts by total usage amount?"
Expected output:
Running pipeline with intent: What are the top 5 accounts by total usage amount?
Run ID: a3f2c1d9
Messages: 4
Errors: 0
Summary:
<Cortex-generated summary of results>
File 3 of 5 — demo_error_patterns.py
What it does: Exercises all four error patterns against your live account in sequence. Each pattern breaks something real (drops a column, revokes a grant, injects bad SQL), shows the pipeline detecting it, then restores the original state. This is the article’s full demo.
Nothing to edit — it imports everything from snowflake_langgraph_pipeline.py. As long as that file is configured correctly, the demo runs.
Prerequisite: snowflake_langgraph_pipeline.py must be in the same directory and its SNOWFLAKE_CONFIG must be updated (File 2 above).
How to run all 4 patterns:
python3 demo_error_patterns.py
How to run a specific pattern:
python3 demo_error_patterns.py --pattern 1 # Transient: retry classifier + warehouse resume
python3 demo_error_patterns.py --pattern 2 # LLM-Recoverable: bad SQL + DDL guard + model error
python3 demo_error_patterns.py --pattern 3 # User-Fixable: schema drift + RBAC gap + credit breach
python3 demo_error_patterns.py --pattern 4 # Unexpected: KeyError + response shape mismatch
python3 demo_error_patterns.py --pattern 5 # Full end-to-end LangGraph pipeline run
What each pattern does to your account:
| Pattern | What It Breaks | Impact Scope | How It Restores |
| ---------------------------------------- | ------------------------------------------------------------ | ---------------------------------------------------- | ---------------------------------------------------------------------- |
| **1 — Transient Failure Simulation** | Simulates an `OperationalError` within the pipeline runtime | No impact on Snowflake objects or data | Not applicable — purely in-process simulation |
| **2 — LLM-Recoverable SQL Error** | Sends intentionally malformed SQL that fails at execution | Query-level failure only (no data or schema changes) | Not applicable — safe, read-only failure |
| **3 — Schema + Privilege Disruption** | Drops `WAREHOUSE_NAME` column and revokes `SELECT` from role | Breaks schema integrity + access control | Automatically restores column and re-grants privileges after detection |
| **4 — Checkpoint Corruption Simulation** | Inserts crash-state records into `PIPELINE_CHECKPOINT` | Affects pipeline state tracking only | No auto-cleanup — leaves records for postmortem analysis |
| **5 — End-to-End Pipeline Execution** | No failure — runs full pipeline workflow | Writes outputs and triggers all stages | Persists summaries into `CORTEX_SUMMARIES` |
How to Read This
- Patterns 1 & 2 → Safe failure simulations (no real impact)
- Pattern 3 → Controlled destructive test (self-healing enabled)
- Pattern 4 → Observability test (intentionally leaves traces)
- Pattern 5 → Happy path (validates full pipeline)
Expected final output (after running all patterns):
======================================================================
DEMO COMPLETE
======================================================================
CLASS COUNT RESOLVED
----------------------------------------
USER_FIXABLE 20 8
LLM_RECOVER 12 12
TRANSIENT 8 8
UNEXPECTED 5 0
UNEXPECTED shows 0 resolved — that is correct behavior. Unexpected errors never auto-resolve; they exist for postmortem.
File 4 of 5 — pipeline_test_harness.sql
What it does: Seven independent SQL tests that validate each layer of the pipeline — infrastructure existence, Cortex availability, schema drift detection, RBAC checks, credit estimation, observability table writes, and a full checkpoint upsert cycle. Run this after File 1 and before running production workloads.
Nothing to edit — runs as-is.
How to run:
- Open a new Snowsight worksheet
- Paste the full contents of pipeline_test_harness.sql
- Run each test block individually using the Run Selected button, or run all at once
The 7 tests and what passing looks like:
| Test | What You Run | Expected Result | What It Proves |
| --------------------------------------- | -------------------------------------------- | ----------------------------------------------------------- | -------------------------------------------------- |
| **TEST 0 — Infrastructure Check** | Validate tables + row count | All 4 tables exist, `FACT_USAGE` contains 10,000 rows | Environment is set up correctly and data is loaded |
| **TEST 1 — Cortex AI_COMPLETE** | Run basic Cortex function | Returns `TRANSIENT_TEST_PASS` | Cortex integration is working |
| **TEST 2 — SQL Recovery Flow** | Execute good SQL after bad SQL | Returns 5 rows from `FACT_USAGE` | Pipeline recovers from query-level failures |
| **TEST 3A — Schema Drift (No Drift)** | Run `CHECK_SCHEMA_DRIFT` with correct schema | `has_drift = false` | Baseline schema validation works |
| **TEST 3A — Schema Drift (With Drift)** | Run with fake column | `has_drift = true`, `missing_columns = ['FAKE_COLUMN_XYZ']` | Drift detection logic is accurate |
| **TEST 3B — Role Privilege (Valid)** | Check `SELECT` privilege | `has_privilege = true` | RBAC validation works for allowed actions |
| **TEST 3B — Role Privilege (Invalid)** | Check `DELETE` privilege | `has_privilege = false`, `remediation_sql` populated | Detects missing access + suggests fix |
| **TEST 3C — Cost Estimation** | Run `ESTIMATE_QUERY_COST` | Returns `avg_credits_24h` and `max_credits_24h` | Cost intelligence logic is functional |
| **TEST 4 — State Logging** | Insert pipeline state events | 3 rows visible in `PIPELINE_STATE_LOG` | Observability layer is capturing execution |
| **TEST 5 — Cortex Summarization** | Run summarization flow | Returns a concise 2-sentence summary | AI summarization pipeline is working |
| **TEST 6 — Checkpoint Upsert** | Insert/update checkpoint | Row visible in `PIPELINE_CHECKPOINT` | Incremental processing state is maintained |
| **TEST 7 — Schema Drift Cycle** | Run drift check before & after column drop | First call: `false`, second call: `true` | End-to-end drift detection lifecycle works |
Common errors:
Error Fix TEST 1 fails: Unknown function AI_COMPLETE Cross-region is disabled — run ALTER ACCOUNT SET CORTEX_ENABLED_CROSS_REGION = ‘ANY_REGION’; TEST 3B returns has_privilege = false immediately after setup GRANTS_TO_ROLES has 2-hour latency. Use SHOW GRANTS ON TABLE directly as a workaround TEST 6 MERGE fails Constraint violation — run DELETE FROM PIPELINE_CHECKPOINT WHERE THREAD_ID = ‘test-thread-001’ first
File 5 of 5 — pipeline_observability.sql
What it does: Eight monitoring queries for post-run analysis — error class distribution, Cortex credit consumption by day, warehouse burn rate by hour, failed queries by error code, pipeline run summaries joined with Cortex outputs, credit efficiency ratings, cross-region parameter check, and per-query Cortex cost tracking.
Run this after at least one full pipeline run (File 3, pattern 5) or after the test harness (File 4) has written some rows.
Nothing to edit — runs as-is.
How to run:
- Open a new Snowsight worksheet
- Paste the full contents of pipeline_observability.sql
- Run queries individually — each is labeled Q1 through Q8
What each query tells you:
| Query | What to Look At | Why It Matters |
| ------------------------------------- | ---------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------ |
| Q1 – Error Distribution | `resolved_count` vs `unresolved_count` per error class. `UNEXPECTED` should always remain 0 resolved. | Helps identify operational stability and whether teams are masking real production issues instead of fixing root causes. |
| Q2 – Cortex Credit Consumption | `total_credits` consumed per Cortex function per day. Watch for sudden spikes. | Spikes usually indicate runaway retries, oversized prompts, prompt loops, or inefficient model usage. |
| Q3 – Warehouse Burn Rate | `cloud_credits` consumed per warehouse per hour. Flat trend = healthy workload. | Sudden increases typically indicate expensive SQL, poorly optimized pipelines, or retry storms. |
| Q4 – Failed Queries Analysis | `failure_count` grouped and ranked by error type or error code. | Repeating error codes usually reveal systemic platform or application-level failures requiring immediate remediation. |
| Q5 – Run Summary Tracking | Join state logs with Cortex summary tables. Review completed vs failed runs and generated LLM summaries. | Provides complete operational lineage and AI execution visibility for troubleshooting and governance. |
| Q6 – Credit Efficiency Classification | Run-level labels such as `EFFICIENT`, `ACCEPTABLE`, and `OVER_BUDGET`. | This becomes the primary AI platform health KPI for tracking optimization and cost governance. |
| Q7 – Cross-Region Cortex Validation | Ensure configuration returns `ANY_REGION`. | If `DISABLED`, Cortex calls to models hosted outside the account’s home region may fail silently or become unavailable. |
| Q8 – Per-Query Cortex Cost Analysis | Join `QUERY_HISTORY` with `CORTEX_FUNCTIONS_QUERY_USAGE_HISTORY` to inspect tokens and credits per `AI_COMPLETE` call. | Enables precise cost attribution, token analysis, prompt optimization, and anomaly detection at query level. |
The canary metric — Q6 credit efficiency over time:
If OVER_BUDGET runs start appearing, check Q4 for repeated errors — it means your retry classifier is wrong and you’re burning credits on errors that should have interrupted immediately. Fix the should_retry_snowflake() classifier in snowflake_langgraph_pipeline.py for the failing error class.
Common errors:
| Error Fix | Resolution |
| ------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Q2 / Q8 return no rows | `CORTEX_FUNCTIONS_USAGE_HISTORY` has ingestion latency. Wait approximately 15–30 minutes after executing a Cortex model call before querying usage views. |
| Q3 returns no rows | `QUERY_HISTORY` inside `ACCOUNT_USAGE` also has latency. Use `INFORMATION_SCHEMA.QUERY_HISTORY` for near-real-time monitoring and troubleshooting. |
| Q5 shows `NULL` for `summary_preview` | No pipeline executions have completed yet. Execute Pattern 5 first so summaries and state logs are generated successfully. |
Full setup sequence — checklist
□ 1. pip install dependencies
□ 2. Generate RSA key pair (~/.snowflake/rsa_key.p8)
□ 3. Register public key in Snowsight (ALTER USER ... SET RSA_PUBLIC_KEY)
□ 4. Run pipeline_infrastructure_sql.sql in Snowsight (Run All)
□ 5. Verify: SELECT COUNT(*) FROM PIPELINE_ERROR_HANDLING.PIPELINE.FACT_USAGE → 10000
□ 6. Edit SNOWFLAKE_CONFIG in snowflake_langgraph_pipeline.py (account + user)
□ 7. Test connection: python3 -c "from snowflake_langgraph_pipeline import execute_query; print(execute_query('SELECT 1'))"
□ 8. Run demo: python3 demo_error_patterns.py
□ 9. Run test harness: pipeline_test_harness.sql in Snowsight (all 7 tests pass)
□ 10. Run observability: pipeline_observability.sql in Snowsight (after demo writes data)
Total setup time: approximately 15–20 minutes on a fresh trial account.
Lessons Learned from Production Testing
1. TRY_COMPLETE doesn’t exist
The Snowflake docs mention it, but SELECT TRY_COMPLETE(…) returns SQL compilation error: Unknown function. Use AI_COMPLETE with Python-side try/except instead.
2. Column names are not what you expect
CORTEX_FUNCTIONS_USAGE_HISTORY has TOKEN_CREDITS, not CREDITS_USED. QUERY_HISTORY only has CREDITS_USED_CLOUD_SERVICES, not CREDITS_USED or CREDITS_USED_COMPUTE. Always DESCRIBE VIEW before writing observability queries.
3. Trial accounts enforce MFA for programmatic access
Password + externalbrowser auth both fail with MFA authentication is required. Key-pair auth is the only reliable method for automation on trial accounts.
4. GRANTS_TO_ROLES has 2-hour latency
If you grant SELECT and immediately check via ACCOUNT_USAGE.GRANTS_TO_ROLES, it returns false. Use SHOW GRANTS ON TABLE for real-time checks in the pipeline; use GRANTS_TO_ROLES only for batch auditing.
5. Snowflake handles warehouse resume internally
Queries submitted to a suspended warehouse with auto-resume are queued — they don’t throw errors. Your connector retry handles network-level failures, not warehouse provisioning.
6. The account identifier needs the region
lw82771 alone returns 404. The full format is lw82771.us-east-2.aws. Check with SELECT CURRENT_REGION().
7. IDENTIFIER() doesn’t support concatenation
IDENTIFIER(:P_DATABASE || ‘.INFORMATION_SCHEMA.COLUMNS’) fails. Use EXECUTE IMMEDIATE with dynamic SQL and RESULTSET/CURSOR instead.
8. Two bugs found on first run — fixed with two sed commands
# Fix 1: Catch AssertionError in Pattern 4 Step 2
sed -i '' 's/except (json.JSONDecodeError, TypeError) as e:/except (json.JSONDecodeError, TypeError, AssertionError) as e:/' demo_error_patterns.py
# Fix 2: Snowflake returns UPPERCASE column aliases
sed -i '' "s/r['preview']/r['PREVIEW']/" demo_error_patterns.py
What’s Next
The credit efficiency evaluator is your canary. If the average credits per run creeps up, your retry classification is wrong and you’re burning compute on errors that should have interrupted. Track credit_efficiency over time — that’s the single metric that tells you whether your error matrix is working.
The natural extension is Cortex cross-region error classification — when CORTEX_ENABLED_CROSS_REGION is DISABLED and you request a model not available in your home region, Cortex fails with a non-obvious error. Classify this as user-fixable, call interrupt() immediately, and include ALTER ACCOUNT SET CORTEX_ENABLED_CROSS_REGION = ‘ANY_REGION’; in the remediation hints.
All code in this article is tested and runs on a Snowflake trial account using Llama 3.3 70B via Cortex AI — fully open-source LLM inference, zero external API keys.
Five files ship with this article: github
snowflake_langgraph_pipeline.py, demo_error_patterns.py, pipeline_infrastructure_sql.sql, pipeline_observability.sql, pipeline_test_harness.sql.
#Snowflake #DataEngineering #LangGraph #CortexAI #CloudArchitecture #AIEngineering #SnowflakeChronicles #Python #MLOps #OpenSource
Production-Grade Error Handling for Snowflake Data Pipelines Using LangGraph and Cortex AI was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.