
Pre-Training Isn’t Bitter Enough
Richard Sutton’s “Bitter Lesson” is usually read as a warning against building too much human knowledge into AI systems. Over the long run, the methods that win are not the ones that encode our clever intuition most directly, but the ones that scale: search, learning, and other general methods that can absorb more compute and data.
Modern foundation model pre-training looks, at first glance, like a triumph of that lesson. We take a general architecture, expose it to massive data, and train it with a simple self-supervised objective. Language models predict the next token. Vision models reconstruct masked patches, align views, or match teacher representations. The recipe is simple and scalable.
But there is a catch.
Pre-training may follow the Bitter Lesson in how it trains the models, but not how it chooses what the model should be trained on. The objective is still chosen outside the training loop. We conduct a large pre-training run, evaluate downstream performance, adjust the recipe, and run again. The learner optimizes one self-supervised learning objective but the downstream feedback actually arrives only after the whole training process. This is a very coarse control loop.
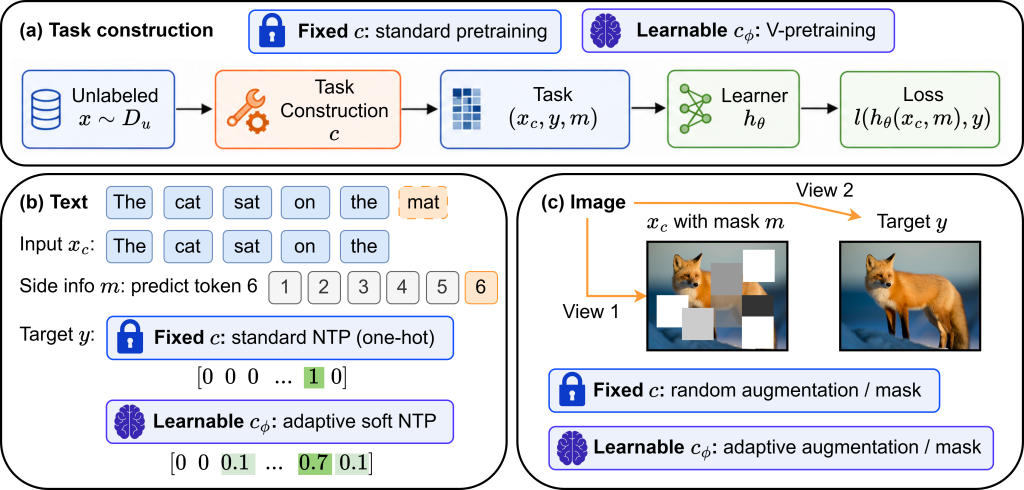
This paper asks whether that loop can be made more direct and tighter. Our question is: given an unlabeled data stream, and a small set of verifiable downstream examples, can we use those examples during continued pre-training? The proposed answer is value-based pre-training with downstream feedback (V-pretraining). The key idea is to separate two roles that are usually collapsed. There is still a learner, the foundation model being pretrained. But there is also a lightweight task designer. The learner is updated only by a self-supervised loss on unlabeled data. The designer, however, learns how to construct the self-supervised task: which target distribution to use in language modeling, or which views and masks to use in self-supervised vision training.
Figure 1 makes this distinction clear. Standard continued pretraining fixes a construction rule before training starts: for text, the next-token target is a one-hot token; for vision, the crop, mask, or augmentation pipeline is fixed. V-pretraining replaces that fixed rule with a learnable designer, while keeping the learner’s update self-supervised.
This distinction matters. V-pretraining is not supervised fine-tuning, preference optimization, or reinforcement learning from feedback. In those methods, downstream labels, preferences, or rewards directly update the learner. In V-pretraining, downstream examples are used only to train the task designer. The learner never receives a downstream supervised gradient. The feedback path is indirect.
One-step estimation
The technical question is how the designer knows which self-supervised task is useful. Ideally, we would choose task constructions that lead to the best downstream model after a full continued-pretraining trajectory. But differentiating through an entire pretraining run is not practical. V-pretraining uses a local surrogate instead.
Suppose a candidate self-supervised task produces a pretraining gradient, (g_{rm pre}). A small feedback batch produces a downstream gradient, (g_{rm down}). If we took a small learner step using (g_{rm pre}), the downstream loss would change approximately as:
$$L_{rm down}(theta-eta g_{rm pre})approx L_{rm down}(theta) – eta g_{rm down}^{top} g_{rm pre}$$
So the inner product (g_{rm down}^{top} g_{rm pre}) estimates whether this unlabeled self-supervised update is likely to reduce downstream loss. V-pretraining trains the designer to construct tasks whose learner gradients align with the downstream gradient. After that, the constructed targets or views are detached, and the learner takes an ordinary self-supervised update.
Instantiations and main results
The concrete instantiations are simple and revealing. In language, we instantiate the task design with adaptive top-K soft target construction. Standard next-token prediction uses a one-hot target: the true next token gets probability one. V-pretraining keeps the same text stream and context, but allows the designer to place a bounded amount of probability mass over a small candidate set that always includes the true next token plus high-probability alternatives from the current learner. The learner still trains by cross-entropy on continued-pretraining text; the feedback examples only shape the target distribution through the designer.
In the main language experiments, the learner is continued-pretrained on NuminaMath-CoT, while 1,024 GSM8K training examples are used only as feedback for the task designer. Under matched wall-clock training budgets, V-pretraining improves GSM8K Pass@1 across tested Qwen models. The largest reported single-run gain is for Qwen2.5-0.5B, improving from 22.20 to 29.60. In replicated Qwen1.5 runs, V-pretraining improves 0.5B, 4B, and 7B models, with the 4B model moving from 56.48±1.56 to 58.98±1.03.

In vision, the same principle is applied to self-supervised view construction. The learner is a DINO-style visual backbone trained on unlabeled ImageNet images. The designer modifies instance-wise views or masks so that the resulting self-supervised gradient better aligns with downstream dense-prediction feedback from ADE20K segmentation and NYUv2 depth estimation. The backbone itself is still updated only by the self-supervised DINO loss.
The main vision results show the same pattern: target downstream capabilities improve without obvious collapse of general representations. For DINOv3-ViT-L, ADE20K mIoU improves from 51.33 to 52.47, NYUv2 RMSE improves from 0.5752 to 0.5522, and ImageNet-1K linear accuracy improves from 84.07 to 84.59. The paper also reports transfer checks on image retrieval, where dense-task feedback improves most Oxford/Paris retrieval protocols, though not uniformly.
A natural concern is that this is just a shortcut. Maybe the continued-pretraining data contains benchmark duplicates. Maybe soft labels help regardless of feedback. Maybe the designer is secretly smuggling supervision into the learner.
The paper includes several controls against these explanations. After decontaminating NuminaMath-CoT by removing near-duplicates of GSM8K and MATH, V-pretraining still remains above the baseline, although with a smaller margin. Random feedback and uniform top-K smoothing perform worse than the baseline in the Qwen1.5-4B ablation, while self-distillation improves but does not match V-pretraining. These controls suggest that the gain is not just label smoothing, self-distillation, contamination, or extra stochasticity; the downstream-aligned value signal is doing work.
Does this extend the Bitter Lesson?
This brings us back to the Bitter Lesson. A shallow reading of the lesson might say: do not inject downstream knowledge into pre-training; just scale next-token prediction. But that is not quite the point. The lesson is not that feedback is bad. It is that hand-designed structure tends to lose to general methods that can learn from scalable signals.
Current pre-training is only partly “bitter.” The learner is trained by a scalable self-supervised objective, but the task recipe is still usually fixed by hand. We choose the data mixture, masking rule, augmentation pipeline, target format, and curriculum outside the training loop. Downstream feedback then arrives only after a run is evaluated.
V-pretraining makes one part of that recipe learnable. The learner still updates only on unlabeled self-supervised data, but a task designer uses downstream feedback to decide which self-supervised prediction problems are likely to be useful. In the paper’s terms, feedback changes the task construction rather than directly supervising the learner.
That is the more bitter version of pre-training: not just scaling a fixed proxy task, but learning which proxy tasks produce valuable updates. Pre-training should not only learn from data. It should learn what to predict.
For more details: Value-Based Pre-Training with Downstream Feedback