
Physics-Informed AI: Fine-Tuning an LLM to Speak Engineering While the Checker Owns the Physics
Part 2 of a practical series — The model learns the schema. The checker owns the physics. Those are different jobs.
In Part I, I covered the three main architectural approaches for physics-informed AI systems: physics-penalized fine-tuning, retrieval-augmented physics (RAP), and hybrid latent spaces with differentiable physics heads. I also flagged that each approach sits at a different point on the implementation difficulty curve.
Part II delivers the most practical end of that curve: supervised LoRA fine-tuning for structured output, paired with a deterministic physics checker in a hybrid LLM + verifier pipeline. This is not physics-penalized fine-tuning. There is no PDE residual in the training loop, no differentiable numerical head, no lambda scheduling. That work is left for Part III.
What this article does demonstrate is narrower and, I think, more immediately useful: how to make a small language model reliably emit the engineering schema a downstream checker needs. In this controlled demo, schema reliability became the first bottleneck: without the right fields, the checker could not even begin validating the physics.
The demo problem: energy conservation
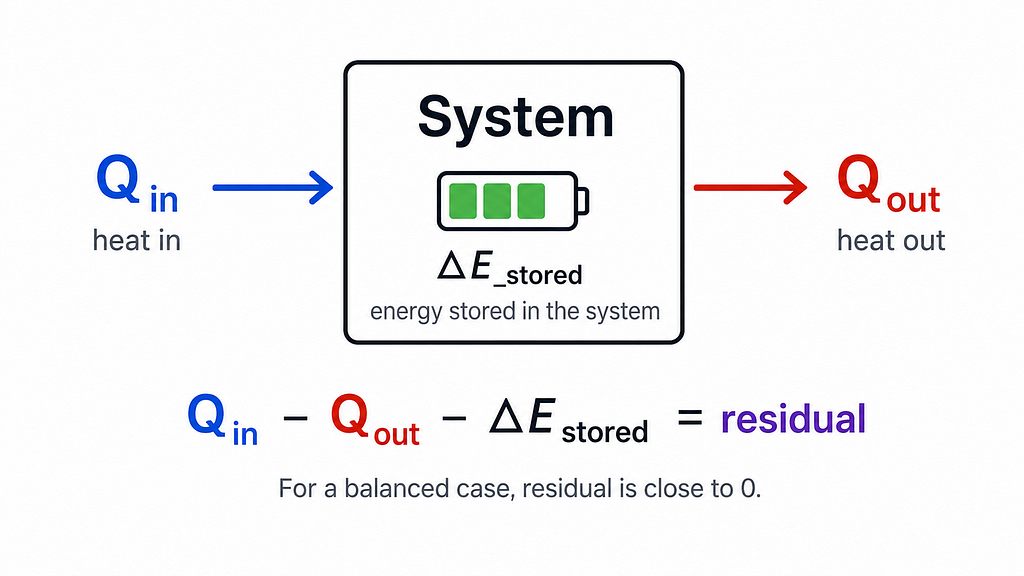
I kept the physics intentionally simple. The system is a thermal energy balance:
The model receives a prompt such as:
Energy input is 120 kJ. Energy output is 90 kJ.
Stored energy change is 30 kJ.
Check whether the system satisfies energy conservation.
The desired output is structured JSON:
{
"energy_in_kj": 120.0,
"energy_out_kj": 90.0,
"stored_energy_change_kj": 30.0,
"residual_kj": 0.0,
"physics_status": "consistent",
"explanation": "Energy input equals energy output plus stored energy change."
}
If the residual exceeds a tolerance of 0.5 kJ, the system is labeled violates_conservation. Starting here makes the architecture easy to inspect and the failure modes easy to reason about. A more complex version could use a heat-equation residual, a pipe-flow solver, or a battery equivalent-circuit model, the architecture does not change, only the checker behind it.
Architecture
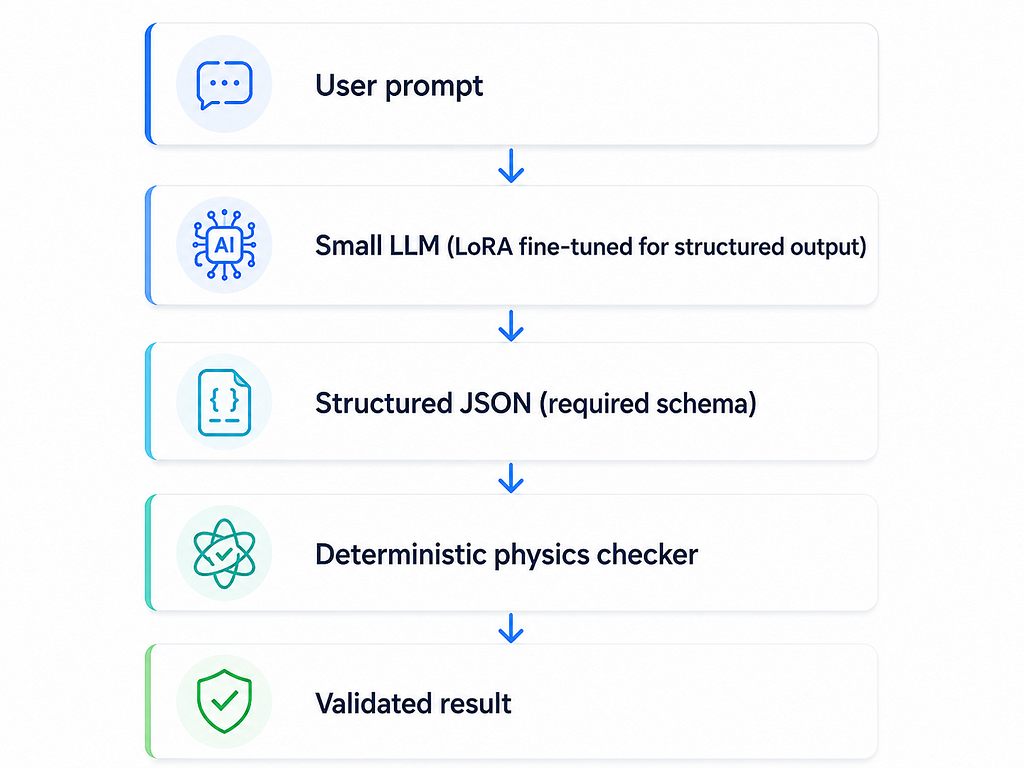
The pipeline is a minimal checker-augmented workflow: the LLM generates structured output, the checker validates the physics.
The checker recomputes the residual independently of what the model reported:
checked_residual = energy_in_kj - energy_out_kj - stored_energy_change_kj
status = "consistent" if abs(checked_residual) <= 0.5 else "violates_conservation"
The LLM is not the authority on physics. It is the component that extracts and structures the values the checker needs. That is its entire job in this pipeline, and it is a job worth doing well.
Model and training setup
Base model: Qwen2.5-0.5B-Instruct
Fine-tuning: LoRA (supervised, no physics loss)
Training examples: 1,500 synthetic JSONL
Validation: 300 examples
Test: 100 examples
Hardware: Tesla T4, Google Colab (~29 min full run)
One practical constraint worth stating upfront: LoRA fine-tuning is not viable on CPU for this model size. The full training run completed in approximately 29 minutes on a T4 GPU. On CPU, the same run would take many hours per epoch, fast enough to verify that the code runs, but too slow to iterate on meaningfully.
The synthetic dataset contained both valid and invalid energy balances. Valid examples had residuals within tolerance. Invalid examples were offset by ±2, ±5, ±10, or ±20 kJ. A training row:
{
"instruction": "Check whether the thermal system satisfies energy conservation.",
"input": "Energy input is 120 kJ. Energy output is 90 kJ. Stored energy change is 30 kJ.",
"output": {
"energy_in_kj": 120.0,
"energy_out_kj": 90.0,
"stored_energy_change_kj": 30.0,
"residual_kj": 0.0,
"physics_status": "consistent",
"explanation": "Energy input equals energy output plus stored energy change."
}
}
The training signal is purely supervised: the model is rewarded for producing the correct token sequence. It is learning the output contract, not the underlying physics.
Why this demo does not backpropagate through physics
This is worth stating clearly, because the broader literature on physics-informed AI can make the boundaries blurry.
This demo uses supervised LoRA fine-tuning. The training loss is a standard next-token prediction loss over the target JSON sequences. There is no PDE residual in the training loop. The model is not penalized for producing a physically incorrect residual_kj value; it is penalized for producing the wrong tokens relative to the training labels. Because the labels contain correct residuals, the model is indirectly exposed to correct physics patterns through imitation, but that is not the same as a physics residual loss.
The conservation residual is computed entirely after generation, by the deterministic checker. The checker is the physics component. The LLM is the language component. They do not share a gradient.
A true physics-penalized implementation would require something the training loop here does not have: a differentiable path from the model’s outputs to a physics residual. In practice that means one of three things. A differentiable numerical head that parses and evaluates the model’s numerical outputs. A hybrid latent space where physics residuals are computed in embedding space before decoding. Or auxiliary regression heads trained jointly with physics loss terms. Each of those approaches carries real implementation complexity: differentiability constraints, gradient scaling between language loss and physics loss, and the risk of the physics objective dominating and corrupting the language modeling objective entirely.
Those trade-offs are what Part III will address. Here, the checker does the job the physics loss would eventually do, but it does it post-hoc, deterministically, without touching the training loop at all.
Why schema matters more than numerical accuracy
The most clarifying step in evaluating this experiment was splitting accuracy into five distinct checks rather than a single number:

Without this breakdown, the base model’s 83% JSON syntax validity looks respectable. The schema validity column reveals what is actually happening:
{
"physics_status": "consistent",
"residual": 12.8
}
That output parses as JSON. It is missing energy_in_kj, energy_out_kj, and stored_energy_change_kj. The checker cannot recompute the residual without those fields, so it cannot run at all. In the end-to-end pipeline, the base model’s checker-validated status accuracy is 0%, because the checker never receives the fields it needs to execute. This is the failure mode I flagged in Part I as “confident, fluent, physically wrong” — except here the wrongness is structural rather than numerical. A human skimming the output might not notice. A downstream tool breaks silently.
Results
After LoRA fine-tuning, the model produced valid JSON and the correct schema on 100% of test examples. Its own numerical reasoning was still imperfect residual accuracy at 45%, status accuracy at 61%. Once the checker recomputed the residual from the now-reliable, structured fields, final status accuracy reached 100%.

The LoRA adapter did not make the LLM a physics solver. It made the model reliably produce the engineering schema. Once the schema was reliable, the deterministic checker could recompute the residual and assign the correct physics status. That separation is not a workaround. It is the architecture.
What fine-tuning actually learned
It is worth being precise about what the model did and did not learn.
The LoRA adapter learned to produce the required output format. It did not learn conservation of energy in any meaningful physical sense; there is no mechanism in the training loop that would cause it to. The model was rewarded for emitting the correct token sequence, and the correct token sequence happened to contain a valid energy balance because the training labels were constructed that way.
This has a practical implication: the model’s residual_kj values are not reliable. At 45% residual accuracy, the model is getting the arithmetic right less than half the time. The physics_status field it generates from its own residual is correct 61% of the time — better than chance, but not trustworthy. Neither of those numbers matters for the final pipeline accuracy, because the checker ignores both and recomputes from scratch.
This is the correct design. If you want physical correctness to come from a model’s weights, you need a training signal that penalizes physical incorrectness. This experiment has no such signal. The checker provides the physical correctness externally, and the model’s job is only to structure the inputs the checker needs.
The checker is the authority
In this demo, the checker is three lines of Python. That is not a limitation; it is the point. The same architecture scales to PDE residual evaluators, SciPy or MATLAB solvers, MPC feasibility checks, or battery equivalent-circuit constraints. In every case, the LLM provides structured inputs and natural language context. The deterministic component provides the physics verdict.
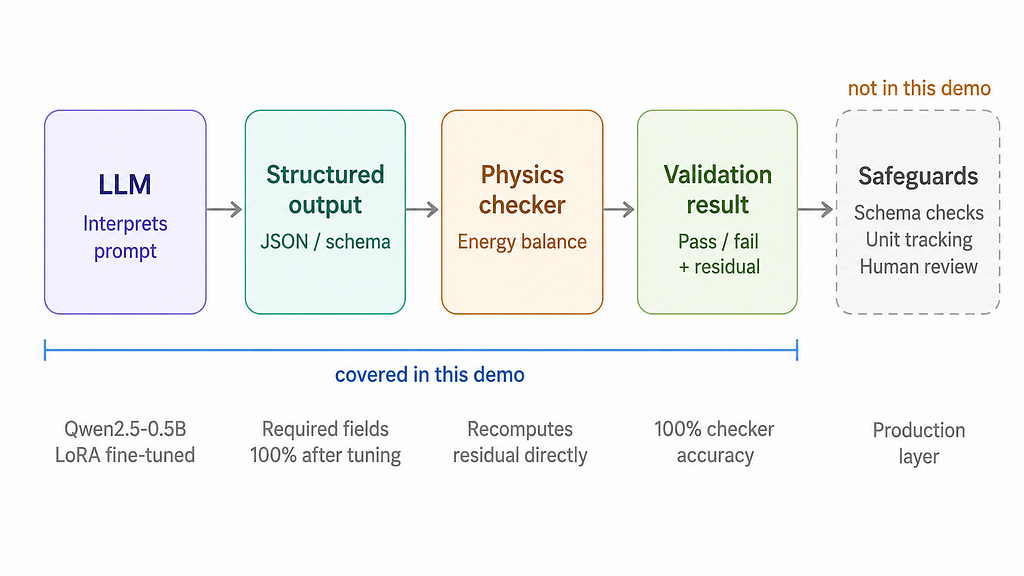
This demo covers only the core pattern: structured output from the LLM, physics validation from the checker. A production deployment would extend the LLM-checker boundary to include schema validation, explicit unit tracking, bounds checking on extracted values, out-of-distribution detection, and human review for high-consequence outputs. Those are not in scope here, but they are the natural next layer around the same architecture.
Setting up Part III
This experiment intentionally stops before differentiable physics-loss training. The results show that, on this synthetic test set, supervised fine-tuning for schema compliance combined with deterministic post-hoc validation was sufficient to achieve 100% checker-validated status accuracy. They also show that schema compliance, not numerical reasoning, was the bottleneck the base model failed on.
Part III will address the harder problem: how to attach differentiable numerical heads to language models, how to schedule physics-loss weights during training, and how to balance language loss against physical residuals without corrupting either objective. That is where the architecture moves from reliable structured output to models that are actually penalized, at training time, for violating physics. The gap between those two things is larger than it might appear, and it is worth being precise about where this experiment sits relative to it.
Physics-Informed AI: Fine-Tuning an LLM to Speak Engineering While the Checker Owns the Physics was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.