
Claude Fable 5 just dropped. Here’s how it stacks against Opus 4.8, GPT-5.5, Gemini, and Kimi.
Anthropic’s new flagship comes with a twist nobody else has tried. It’s one model wearing two names, and one of them you can’t have. Under the hood, the coding numbers are genuinely startling. The price tag is too. Here’s the honest map of where it lands against GPT-5.5, Gemini, Kimi, and the model most people are actually using right now, Opus 4.8.
Another month, another frontier model. I get it, the launches blur together at this point. But this one’s worth slowing down for, because Anthropic did something structurally odd with it, and because the benchmark gaps it opened up aren’t the usual two-point squabbles. Some of them are twenty points wide.
First, the odd part. Claude Fable 5 and Claude Mythos 5 are the same underlying model. Same brain, two doors. Fable 5 is the version anyone can use, shipped with extra guardrails around dual-use capabilities, the stuff that could cut both ways in the wrong hands. Mythos 5 is the unrestricted version, and it’s only available to approved organizations. Anthropic actually ran this play in slow motion all spring. The original Mythos preview went out in April to a small circle of defensive cybersecurity teams and critical-infrastructure operators before the public ever touched it. Now the general release lands as Fable, and the gated tier stays gated.
Whatever you think of that approach, it’s new. No other lab has split its flagship into “the one you get” and “the one you have to qualify for.” It tells you something about where Anthropic thinks frontier capability is heading, and it’s why you’ll see two names floating around for what is, functionally, one model.
Okay. So is the model actually good?
The coding numbers are the headline, and they’re not close
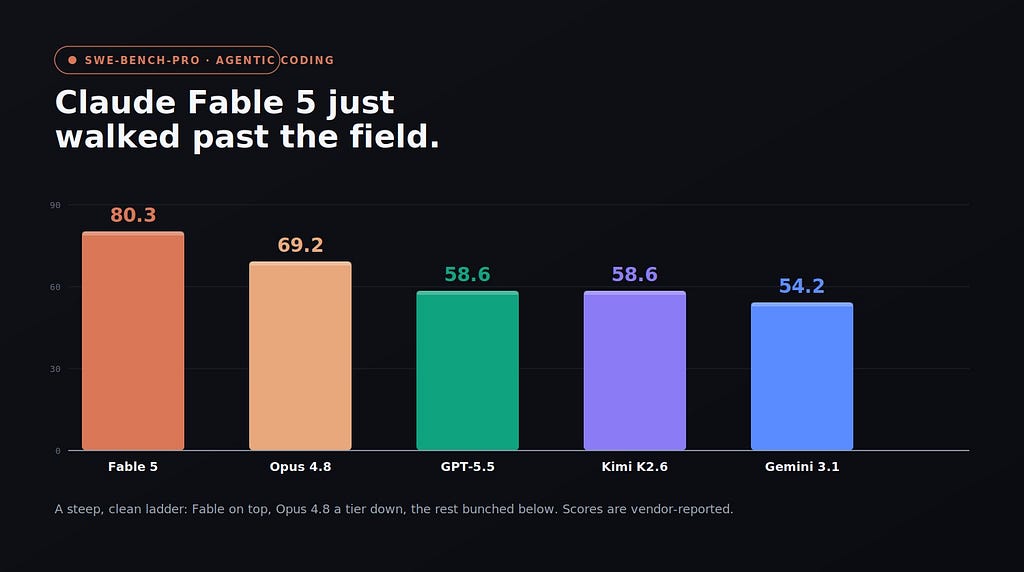
Let’s start where the gap is biggest, because it’s the thing everyone will be talking about.
On SWE-Bench-Pro, the benchmark that measures whether a model can do real agentic coding work on real repositories, Fable 5 scored 80.3%. The interesting middle marker is Claude Opus 4.8, the model most people are actually coding with today, which lands at 69.2%. Then comes the rest of the field, with GPT-5.5 at 58.6% and Gemini 3.1 Pro at 54.2%. So the hierarchy is clean and steep: Fable on top, Opus 4.8 a solid ten points back, and the rest bunched another ten points below that. For context on how fast this is moving, Kimi K2.6, the open-weights darling from April, ties GPT-5.5 down in that lower cluster. Fable didn’t just edge the field, it walked twenty points past everything except its own younger sibling.
Independent testers back up the vibe. Hex, the analytics company, said Fable 5 was the first model to break 90% on its internal benchmark of complex, long-running analytical tasks, a ten-point jump over the earlier Opus models. Their testers described it as showing strong judgment and attention to nuance, which matches the general theme here. This model was built for long, messy, multi-step work, the agentic stuff, and that’s exactly where it pulls away.
And against its own family? That ten-point jump over Opus matters, because Opus 4.8 was already Anthropic’s workhorse and a genuinely strong coder. Earlier Opus versions held the top of SWE-bench Verified in the high 80s. The Mythos-class model pushed that to roughly 94% when the preview landed, the top spot at the time. So even inside Anthropic’s lineup, this isn’t a refresh. It’s a tier above, which is literally how they’re positioning it.
Now, the honest asterisks, because there are two and they matter. Benchmark tables at launch are always the lab’s chosen battlefield. When the Mythos preview shipped, Anthropic reported wins on 17 of the 18 benchmarks it measured, and the one miss was effectively a tie with Gemini. Impressive, sure, but labs don’t publish the tables they lose. And SWE-bench specifically carries a known memorization concern, the worry that models have effectively seen the test. To Anthropic’s credit, it published a re-scored analysis on decontaminated subsets showing the margin holds, which is more than most labs bother to do. Still, hold the numbers loosely until the fully independent indexes catch up with the new release.
Don’t sleep on Opus 4.8, the one you’re probably already using
Before writing off everything below Fable, it’s worth pausing on Opus 4.8, because for most people it’s the actually-relevant model. It shipped at the end of May and quietly did something notable: it took the number one spot on the Artificial Analysis Intelligence Index at 61.4, nudging past GPT-5.5’s 60.2. So the best publicly rankable model, by that composite, is already a Claude, even before you get to the gated tier.
What makes Opus 4.8 the sensible default is the combination. It leads SWE-Bench-Pro by more than ten points over GPT-5.5, it’s strong on knowledge work and computer use, and notably it posts far lower hallucination rates than its rivals on independent tests, which matters more than raw scores for anything you actually ship. It’s priced at $5 input and $25 output per million tokens, which undercuts GPT-5.5’s output price, though there’s a real catch: Opus is verbose, using something like three times the output tokens per task, so the cheaper sticker price can quietly cost you more on the bill. And it isn’t flawless. GPT-5.5 still beats it on terminal-driven workflows, and Opus 4.8’s own system card showed a small regression in resistance to prompt injection, worth knowing if you’re wiring it into anything exposed.
The clean way to hold it in your head: Opus 4.8 is the best model you can just pick up and use today, Fable is the tier above it for the genuinely hard jobs, and the gap between them, that ten-point coding jump, is exactly what you’re paying a steep premium for.
Where it doesn’t win, because it doesn’t win everywhere
Here’s the part the launch coverage will skim, and it’s the part that actually helps you decide anything.
GPT-5.5 beats it in places. On expert cybersecurity tasks, GPT-5.5 scored 71.4% against the Mythos-class model’s 68.6%, and it famously cracked a reverse-engineering challenge in ten minutes for under two dollars. On GDPval, OpenAI’s knowledge-work benchmark, GPT-5.5 posts 84.9% and Anthropic simply didn’t report a number. On desktop computer use the two are within a point of each other. And GPT-5.5’s real weapon isn’t any single score, it’s efficiency. It uses dramatically fewer output tokens than its predecessor to finish the same work, and OpenAI’s whole pitch, backed by Artificial Analysis cost curves, is frontier intelligence at roughly half the cost of competing coding models.
Which brings us to the number that should give every engineering team pause. The Mythos-class pricing came in at $25 per million input tokens and $125 per million output. GPT-5.5 is $5 and $30. That’s roughly four times the output cost. Even if Fable 5 is meaningfully better at the work, you have to ask whether it’s four-times-the-bill better for your workload, and for a lot of teams the honest answer will be “only for the hardest tasks.” If you’ve been following the shift to metered AI billing, you already know where this goes. The meter is running, and this model spins it fast.
Gemini 3.1 Pro, meanwhile, owns a different hill entirely. It leads the pure-reasoning benchmarks, with 77.1% on ARC-AGI-2 and 94.3% on GPQA, it carries a two-million-token context window that nobody else matches, and it’s the cheapest of the closed flagships. If your work is long-document reasoning rather than repository surgery, Gemini’s case is genuinely strong, and on raw academic reasoning even GPT-5.5 hasn’t closed the gap with it.
So the field sorts itself by strength, not by rank. Fable owns coding and long-horizon agentic work. GPT-5.5 owns cost-efficient agentic breadth and, narrowly, cyber. Gemini owns reasoning and context. Anyone selling you a single “best model” is selling something.
Then there’s Kimi, the uncomfortable one
Kimi K2.6 doesn’t fit the closed-flagship frame at all, which is exactly why it belongs in this comparison.
It’s a trillion-parameter open-weights model from Moonshot AI that scores 54 on the Artificial Analysis Intelligence Index, only a few points behind the closed flagships’ cluster around 57, and it ties GPT-5.5 on SWE-Bench-Pro while costing somewhere between 80 and 90 percent less per token. You can download the weights and run it yourself. For teams whose ceiling is “very good” rather than “absolute frontier,” that math is brutal for everyone charging flagship prices, and it’s the same open-versus-closed squeeze that’s been narrowing all year.
Two catches keep it honest. Per-token cheap isn’t per-task cheap, and K2.6 has a documented habit of burning enormous thinking traces to reach an answer, which eats into the discount on real workloads. And there’s an awkward backstory between these specific companies, since Anthropic accused Moonshot earlier this year of using thousands of fraudulent accounts to harvest Claude’s outputs at scale, an accusation worth knowing about as context for how heated the open-versus-closed race has become. Neither catch changes the core fact. The gap between a $125-per-million flagship and a $4-per-million open model is now small enough on many tasks that you have to justify the flagship, not the other way around.
So what do you actually do with all this
The same thing the smart teams have been converging on all year. You stop asking “which model is best” and start routing.
Fable 5 makes sense as the model you reach for when the task is genuinely hard, long-horizon coding, multi-step agentic work that runs for hours, the jobs where a failed run costs more than the tokens did. Its lead there is real and large. Opus 4.8 is the smart default for serious work that doesn’t quite need the top tier, since it’s the strongest model you can just use and it’s meaningfully cheaper than Fable. GPT-5.5 makes sense as the everyday agentic workhorse and for terminal-heavy automation, because the cost-per-result math is the best in the closed tier. Gemini takes the long-context and heavy-reasoning lane. And Kimi, or one of its open-weights siblings, takes everything where very-good-and-cheap beats perfect-and-pricey, which is more of your workload than pride wants to admit.
The two-door structure is the thing I’d watch going forward. Anthropic just established that the most capable version of a frontier model might not be publicly available at all, with capability itself becoming a gated product tier. If that becomes the industry norm, the question “how good is the best model” quietly turns into “how good is the best model you’re allowed to use,” and those are different questions with different answers.
One last honesty note, the same one that applies to every launch week. These numbers are days old, some are vendor-reported, and the fully independent rankings haven’t digested Fable 5 yet. The right move is the boring one. Wait for the Artificial Analysis index to post its score, run your own evals on your own workload, and trust the twenty-point gaps more than the two-point ones. The twenty-point gaps tend to be real.
If you’ve already run Fable 5 against your own workload, drop a comment with what you found, especially where it didn’t live up to the table. Launch-week numbers are a map. Your evals are the territory.
Resources
- Artificial Analysis model index, for the independent scores as they land: https://artificialanalysis.ai/models
- BenchLM head-to-head comparisons across the frontier models: https://benchlm.ai
- Anthropic’s Fable 5 and Mythos 5 announcement: https://www.anthropic.com/news/claude-fable-5-mythos-5
- SWE-Bench-Pro, the agentic coding benchmark behind the headline numbers: https://www.swebench.com
- Kimi K2.6 weights and documentation, the open-weights comparison point: https://huggingface.co/moonshotai
Claude Fable 5 just dropped. Here’s how it stacks against Opus 4.8, GPT-5.5, Gemini, and Kimi. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.