
Claude Fable 5 Can Work Alone for Far Longer. Here’s What That Changes for Agents.
Claude Fable 5 Can Work Alone for Far Longer. Here’s What That Changes for Agents.
A few weeks ago I wrote that Claude Opus 4.8 quietly retired a chunk of the scaffolding I’d been writing for agents. I stand by that. But I also said the thing I’d really be watching was whether models could hold it together over long, unsupervised runs — because that’s where agents have always fallen apart.
Claude Fable 5 landed on June 9, 2026, and it’s the first release where that specific number moved in a way I can feel.
Most of the headline benchmarks are the usual “state-of-the-art on nearly everything” story, and they’re real. But the part that matters if you build agents isn’t that Fable 5 is smarter per step. It’s that it stays coherent across many steps — long enough to do work that previously required a human checking in every few minutes. That changes the shape of what you can safely hand to a machine and walk away from.
Let me walk through what shipped, why the autonomy story is the one to care about, and the one operational gotcha — a silent model fallback — that you need to handle in code before you ship anything on it.
What Anthropic actually shipped
The short version first:
- Two models, one brain. Fable 5 is the public model, wrapped in safeguards. Mythos 5 is the same underlying model with those safeguards lifted, available only to vetted partners and researchers. As Anthropic puts it, “the safeguards are what distinguish the two models.” [1]
- Model ID: claude-fable-5, on the API and consumption-based Enterprise plans now.
- Pricing: $10 / $50 per million input/output tokens — less than half the price of the earlier Mythos Preview. [1]
- Coding: Stripe reported it “compressed months of engineering into days,” including a 50-million-line Ruby migration done in a day that would have taken a team two months. Highest score on Cognition’s FrontierCode at medium effort, and more token-efficient than prior Claude models. [1]
- Vision: state-of-the-art — it rebuilt a web app’s source from screenshots alone, and completed Pokémon FireRed with a “minimal, vision-only harness” where earlier Claude models needed elaborate helper tools. [1]
- Autonomy: “can work autonomously for longer than any previous Claude models.” In game-based testing, file-based persistent memory improved its performance 3× more than it did for Opus 4.8, and it reached the final act 3× more often. [1]
- Safety: AI classifiers that detect misuse in cybersecurity, biology/chemistry, and model distillation — and, crucially, a fallback that quietly routes risky requests to Opus 4.8 instead. [1]
If you only remember two things: the autonomy bar moved, and there’s a silent fallback you have to account for. The rest of this post is those two things.
The centerpiece: it stays coherent for longer
Here’s the failure mode that has defined agent-building for two years. The model is great for the first ten steps. Around step fifteen it loses the thread — forgets a constraint it set earlier, repeats a tool call, or quietly drifts off the goal. By step thirty you have a confident, wrong result and no obvious place where it went off the rails. Every “agents are brittle” complaint traces back to this.
The interesting Fable 5 result isn’t a benchmark percentage — it’s the shape of how it uses memory. Anthropic reports that giving it file-based persistent memory improved its performance 3× more than the same memory helped Opus 4.8, and that it reached the final act of a long game 3× more often. [1] Read past the game framing and the implication is concrete: when you give Fable 5 a place to externalize state, it actually uses it to stay on track across a long horizon, instead of slowly losing coherence.
That tracks with the customer quotes Anthropic chose to highlight. Cursor’s CEO said it “opened up a class of long-horizon problems that were out of reach for earlier models.” The 50-million-line migration in a day is the same story at industrial scale: not a smarter single step, but a long chain of steps that doesn’t fall apart. [1]
For me, the practical unlocks are:
- Overnight jobs I don’t babysit. Multi-hour migrations, large refactors, batch document analysis — tasks where the old constraint wasn’t capability per step, it was drift over the run.
- Agents that own a goal, not a turn. I can hand Fable 5 an objective and a scratchpad and trust it to maintain its own state instead of me re-injecting context every few steps.
- Simpler harnesses. The vision-only Pokémon result is the tell. Where I used to wrap a model in navigation helpers, state trackers, and guardrail tools, more of that can move into the model plus a memory file.
The lesson I’m taking: the highest-leverage thing you can give Fable 5 is durable memory, not a cleverer prompt. That’s a different design instinct than the one most of us built up over the last two years.
The operational gotcha: a silent fallback to Opus 4.8
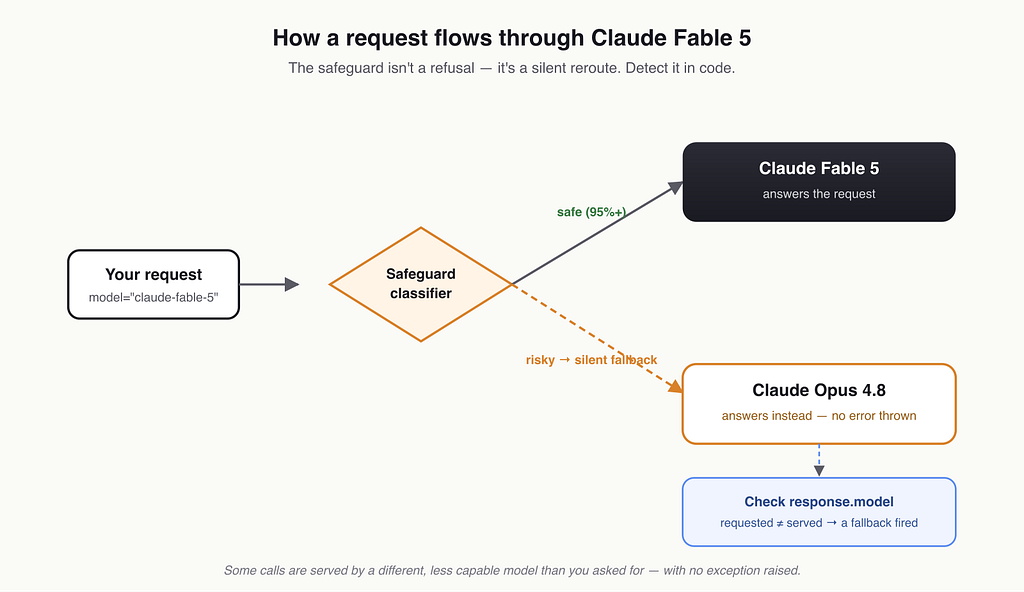
Here’s the part you have to handle in code, and it’s easy to miss.
Fable 5’s safeguards aren’t a hard refusal. When its classifiers flag a request as risky — certain cybersecurity, biology, or chemistry territory — it doesn’t error out. It silently answers via Claude Opus 4.8 instead. Anthropic says more than 95% of Fable sessions involve no fallback at all, and that they “deliberately tuned the safeguards to be cautious,” explicitly acknowledging false positives will “frustrate some users.” [1]
If you’re building agents, sit with what that means. Some fraction of your calls — hopefully small, occasionally not — will be served by a different, less capable model than the one you asked for, with no exception thrown. If your agent depends on a Fable-5-specific capability for a step, and that step happens to trip a classifier, you’ll get an Opus 4.8 answer and your pipeline will quietly behave differently than you tested.
So the first thing I do on a new model like this is verify which model actually served the response. The Messages API returns the model in the response body, so you can compare what came back against what you asked for
import anthropic
client = anthropic.Anthropic()
REQUESTED_MODEL = "claude-fable-5"
response = client.messages.create(
model=REQUESTED_MODEL,
max_tokens=4096,
messages=[{"role": "user", "content": task_prompt}],
)
# Fable 5 silently serves risky requests via Opus 4.8.
# The response reports the model that actually ran — compare it.
served_by = response.model
if served_by != REQUESTED_MODEL:
# A safeguard fallback fired. Decide deliberately:
# - log it for later analysis,
# - retry with a reworded request,
# - or surface "this step was handled by a fallback model" to the user.
log.warning("Fable 5 fell back to %s on this request", served_by)
handle_fallback(response)
answer = "".join(b.text for b in response.content if b.type == "text")
Confirm the exact signal against the current API docs before you rely on it — the announcement describes the behavior but doesn’t spell out a dedicated flag, and response.model is the obvious, documented place the truth shows up. The point isn’t the specific field. The point is: don’t assume the model you requested is the model that answered. Build the check in from day one, log every fallback, and you’ll have the data to tell whether your false-positive rate is in the comfortable 5% range or somewhere that’s quietly degrading your product.
The Fable / Mythos split, briefly
It’s worth understanding the two-model structure even if you’ll only ever touch Fable. Fable 5 and Mythos 5 are the same model. Mythos 5 has the safeguards lifted and is restricted to vetted cybersecurity and biology partners; Fable 5 is the safeguarded version the rest of us get. [1]
Why it matters to a builder: the capability ceiling you’re working under isn’t the model’s — it’s the safeguard layer’s. Anthropic reports the underlying model can do genuinely heavy science (autonomous protein design, week-long autonomous genomics research, novel hypotheses scientists preferred ~80% of the time in blind comparisons). [1] You’re not getting that surface area through Fable, and that’s by design. For ordinary agent work it won’t matter. But it explains why some requests get the cautious treatment, and it sets expectations: Fable is tuned to be conservative on purpose.
What I’d change in my stack
If I were standing up a new agent on Fable 5 today, here’s what’s different from my Opus 4.8 setup:
- Give it a memory file before you give it a better prompt. The 3× memory result says durable external state is where the leverage is now. Design the scratchpad first.
- Instrument the fallback. Log response.model on every call, alert if your fallback rate climbs, and decide per-feature whether an Opus 4.8 answer is acceptable or should be flagged to the user.
- Lengthen the leash, carefully. Tasks I’d have chunked into supervised steps on 4.8 are candidates for longer unsupervised runs now — but I’d roll that out behind metrics, not faith.
- Lean on vision more. If you were bolting helper tools onto a model to compensate for weak visual grounding, retest with raw screenshots. Some of that scaffolding may be dead weight.
- Re-baseline your token budgets. Anthropic claims better token efficiency; verify it on your own traffic before assuming the savings.
What I’m still watching
A few honest unknowns I’ll be testing over the next couple of weeks:
- What’s the real fallback rate on production traffic? 95% no-fallback is an aggregate. The number that matters is your number, on your prompts. Some domains will trip the classifiers far more than others.
- Does long-horizon coherence hold outside the demos? Games and curated migrations are clean. Messy, ambiguous real-world tasks are the actual test of whether the autonomy gain is general.
- How disruptive are false positives in practice? Anthropic told us upfront they’ll happen. Whether they’re a rounding error or a steady tax depends entirely on what you’re building.
- No disclosed context window. The announcement is conspicuously quiet on maximum context length — worth pinning down before you design around long inputs. [1]
The takeaway
Opus 4.8 shrank the gap between what a model can do in one call and what frameworks bolt on top. Fable 5 moves the next constraint: how long a model can run on its own before it loses the plot. That’s the variable that has gated real agent autonomy, and it just moved.
The catch is that the safety layer comes with a silent fallback, so the very first thing you should write on Fable 5 isn’t a clever agent loop — it’s a three-line check that tells you which model actually answered. Get that in, give your agent durable memory, and then start lengthening the leash. That’s the work I’m doing this week.
Sources
[1] Anthropic, “Claude Fable 5 and Claude Mythos 5”, June 9, 2026. All benchmark figures, customer quotes, pricing, safeguard behavior, and capability claims in this article are drawn from the official announcement.
Claude Fable 5 Can Work Alone for Far Longer. Here’s What That Changes for Agents. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.