
AI Agents Have Amnesia. A Bigger Context Window Won’t Cure It.
Why memory is the missing layer of the agent stack, the seven problems any real memory system has to solve, and the shape of an architecture that survives them.
Part 1 of 2 on building memory for AI agents. This part is the “why.” Part 2 is the architecture. ~10 min read.
On Monday you tell your coding agent that your team uses pnpm, not npm. It apologizes, fixes the command, and carries on. On Thursday it runs npm install again.
You explain to your AI assistant, for the third time this month, that you write British English, that “the migration” means the Postgres-to-Snowflake project, and that your weekly report goes out Friday morning. It nods. Tomorrow it will be a stranger again.
Here is the uncomfortable part: the model is not the problem. The model got smarter every quarter. What never changed is that every session starts from zero, because the layer that should carry what the model learned about you, your project, and your decisions simply does not exist in most agent stacks.
I spent the last several months designing that layer for an AI workspace I am building, after shipping a production conversational analytics engine (my earlier four-part series). This pair of articles is the memory half of that work. Before I show the architecture in Part 2, I want to convince you that memory is a real engineering problem with sharp edges, not a vector database you bolt on in a weekend.
TL;DR
- Agents without durable memory measurably degrade: on the LongMemEval benchmark, assistants drop around 30 percent (up to roughly 60 on the hardest abilities) when answers hide in a long history instead of a short one.
- The obvious fixes fall short. A bigger context window is a buffer, not a memory. Instruction files rot silently. A bolted-on vector store returns stale facts with confidence and has no idea what is still true.
- Memory is really seven distinct problems: the unit of memory, when to write, what to keep, how to change your mind, what was true when, when to forget, and where memory lives (and who may see it).
- The shape of the answer: a typed, time-aware record instead of a blob, an asynchronous model-powered write path with a deterministic read path, and forgetting and privacy designed in as structure, not patched on.
The drop is measurable
You do not have to take the amnesia anecdotes on faith. The benchmarks already show the cliff, and it rhymes with the text-to-SQL cliff from my earlier series: the demo conditions hide the hard part.
- LongMemEval (ICLR 2025) asks 500 questions whose answers are buried in long chat histories. It isolates five abilities: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention. Commercial assistants and long-context models drop about 30 percent versus being handed just the relevant sessions, and up to about 60 percent on the hardest abilities.
- Temporal reasoning is a headline failure. Systems confuse when a fact was stored with when it was true, so “what database do we use now” happily returns the answer from before the migration.
- The effect is not hypothetical product polish. Anthropic reported a 39 percent improvement on an agentic evaluation from adding a memory tool plus context editing.
- And a warning while we are here: memory benchmark scores are fragile. The same memory system has been scored at 84, 75, and 58 percent on the same benchmark by different evaluators, because LLM-as-judge setups disagree. Whatever you build, you end up needing your own evaluation harness. Hold that thought for Part 2.
The model did not get dumber as the history grew. The environment changed: the signal it needed was buried in noise it could not organize. That is not an intelligence problem. It is a systems problem.
“Just use a bigger context window” is the wrong layer
The most common objection first. Context windows are now a million tokens. Why build anything?
Four reasons, and each one is structural.
- Cost and latency scale with everything you re-read. Stuffing history into every call means paying for it on every call. Production memory systems report about 90 percent token savings and around 90 percent lower p95 latency versus full-context stuffing (vendor-run numbers, the usual caveat). One published system compresses a 115k-token history into roughly 1.6k tokens of retrieved facts. And even on benchmarks where brute-force context stuffing wins on raw accuracy, it pays roughly ten times the tokens and latency to do it.
- Long context degrades. The same LongMemEval results above are partly a long-context story: models lose precision in the middle of huge prompts. More window is more haystack.
- The window ends, and the agent forgets at the boundary. Long sessions hit compaction: the runtime summarizes old turns to make room, and detail dies in the summary. Every heavy user of coding agents has watched an agent forget a constraint it acknowledged an hour earlier. One open-source agent ingests its instruction file on every loop iteration with no size guard; a real-world 331 KB instructions file consumed about 81 percent of a 128k window before any work began.
- A window is a buffer, not a model of truth. Even infinite context cannot tell you which of two contradictory statements is current, what changed since last sprint, or what you are no longer allowed to see. Those need a data model, not more tokens.
A context window is RAM. Memory is the file system plus the database. Nobody argues their laptop needs no disk because it has a lot of RAM.
What agents do today, and how it decays
The field is not empty. It is fragmented, and each fragment fails a different way.
[ IMAGE PLACEHOLDER, upload diagrams/part5-where-agent-memory-breaks.png ]
Diagram: what agents use for memory today, and how each one decays. In Medium, add an image here, upload that file, then delete this line.
How to read it: each column is a coping mechanism in real use today, and each red box is the way it decays in production. None of the four is wrong. Each is a partial answer that was never designed to be the whole one.
- Static instruction files (CLAUDE.md, AGENTS.md, editor rules) are the workhorse of coding agents, and they are genuinely useful. But they are human-curated, so they rot silently: nothing updates them when reality changes, and the official guidance is to “review periodically to remove outdated or conflicting instructions.” They are also delivered as suggestions, not enforced state.
- Compaction keeps long sessions alive by summarizing old turns. It is lossy by design. What the summary drops is gone, and the GitHub issues of every major coding agent are full of “it forgot what we agreed” reports at exactly that boundary.
- A vector database bolted on gives you semantic recall and three new problems: it returns facts that are similar but stale, it cannot represent “this was true until March,” and contradictory facts coexist until retrieval becomes a coin flip. Worse, tool-based recall only works when the agent chooses to search, which it often does not.
- Hosted assistant memory (the memory features inside consumer assistants) is real progress and the right instinct, but it is opaque, lives on someone else’s server, is scoped to one product, and cannot follow you into your terminal, your editor, and your other tools.
Researchers who study agent context describe four recurring failure modes, and a memory layer has to answer all four: poisoning (a wrong fact gets in and persists), distraction (history outweighs the task), confusion (irrelevant detail leaks into answers), and clash (contradictory facts coexist).
There are also dedicated memory products (Mem0, Zep, Letta, Supermemory, and others), and they are serious work; my design borrows tested ideas from each. But each solves a slice. One ships clean write-time fact extraction but pushed contradiction resolution out to the application. One ships a strong temporal graph but no real forgetting. One ships elegant in-context memory blocks but leaves long-term structure to you. And while some ship access-control lists around memory, none of the open engines makes source-level visibility, and what happens when a grant is revoked, a first-class axis of the memory model itself. For anything beyond a single user, that turns out to be the hardest part.
Memory is seven problems wearing one name
“Add memory” sounds like one feature. When I sat down to design it properly, it decomposed into seven questions, and every one of them changes the architecture. This decomposition is the backbone of Part 2, so I will take them in order.
1. What is the unit of memory?
A transcript is not a memory. If you store raw chat logs and embed them, you have built search over noise.
- The unit has to be a distilled, typed record: a fact (“uses pnpm”), a preference (“terse PR descriptions”), a relationship (“Priya owns the auth service”), a procedure (“how we cut a release”), an identity trait (“writes British English”).
- Different types need different storage and retrieval: exact-lookup facts, semantically searched notes, graph edges you can traverse, procedures you can execute.
- One schema with a type field beats five stores. Every downstream mechanism (decay, sharing, audit) gets written once.
2. When do you write?
Write everything every turn and you get noise, latency, and cost. Write only when the user says “remember this” and you get almost nothing.
- The pattern that works across the research corpus: asynchronous curation. A background pass reads the session and extracts what mattered, off the hot path.
- Be conservative. Benchmarks built on growing histories show over-retention actively hurts accuracy: more memories means more retrieval noise.
- The strongest implicit signal is not what the user said. It is what they did: accepted, edited, rejected, repeated.
3. What do you keep?
The fact, not the transcript. The decision, not the meeting.
- Extraction is model work: read the session, emit salient, self-contained statements with metadata (importance, keywords, a one-line description).
- A finding from the agentic-memory research line that I adopted directly: embed the enriched note (the content plus a model-written description, keywords, and tags), not the bare transcript. Retrieval precision improves measurably, and my design keys retrieval on the one-line description.
- Keep the raw log too, but as a separate, decaying archive you can drill into, never as the thing you search by default.
4. How do you change your mind?
You switched from Postgres to Snowflake. A naive store now holds both “we use Postgres” and “we use Snowflake,” and your agent alternates between them.
- On contradiction, the prior fact must be invalidated, not deleted: marked superseded with a timestamp, kept for history.
- Deleting feels tidy and destroys the audit trail. Invalidation gives you “what did we believe in March” for free, plus undo.
- This is the single clearest divide in the field: destructive updates versus temporal invalidation. I side with invalidation, and Part 2 shows the mechanics.
5. What was true when?
There are two timelines and most systems track neither cleanly.
- World time: when the fact was true in reality (“Postgres until March 2026”).
- System time: when the memory layer learned it (maybe in May, from an old document).
- You need both on every record to answer both “what was true at T” and “what did the agent believe at T.” The first is correctness; the second is audit, and you will want it the first time an agent acts on stale knowledge and someone asks why.
- The published system that took this seriously (a bitemporal knowledge graph) reported the strongest temporal-reasoning numbers published so far (vendor-run, so apply the caveat from earlier). The lesson generalizes either way: stamp both timelines from day one, because retrofitting is brutal.
6. When do you forget?
Forgetting sounds like a bug. It is a feature, and an under-built one.
- Stale and low-value memories are retrieval noise; dropping them from candidate sets raises accuracy. Forgetting is a quality lever, not hygiene.
- Forgetting must be reversible: a retrieval-time down-weight that decays with age and disuse, plus an archive sweep, never silent destruction.
- Not everything decays alike. “Prefers British English” should outlive “busy with the Q3 launch” by an order of magnitude. Decay needs to be configurable per kind of memory, per volatility.
- And here is the research gap that surprised me most: the public benchmarks cannot see any of this. Their scoring is recall-monotonic: remembering more never costs points. A system that hoards everything can top the leaderboard while degrading the real product. Nobody scores forgetting; almost nobody scores personalization. If you build memory seriously, you are building your own evaluation harness, because the public ones reward the wrong behavior.
7. Where does it live, and who may see it?
The question the benchmarks skip entirely, and the one that dominated my design.
- Memory about you and memory about a project have different owners, different privacy expectations, and different lifecycles. You leave a project; the project’s knowledge should stay with the team, and your personal memory should leave with you. A store that mixes them cannot do either.
- Raw conversations are the most sensitive data an agent touches. Distilling them with a model is exactly the step you do not want running on someone else’s server.
- The moment memory is shared (a team, a company), access control collides with it: a fact you learned from a source a colleague cannot see must not surface to them through the side door of “memory.” And when your access to a source is revoked, memories derived from it should stop surfacing too. Almost nothing in the field even attempts this.
Read the seven again and notice what they are not. Only two are retrieval problems. The rest are data-model, time, and governance problems, and that is precisely why “we added a vector database” keeps failing as a memory strategy.
Why the obvious fixes don’t clear the walls
The same table I built for text-to-SQL in my earlier series, redrawn for memory. Every common fix helps; none of them, alone, answers more than two of the seven questions.
- Bigger context window (What it helps: short-term continuity within a session; What it does not solve: cost, long-context degradation, contradictions, time, privacy: a buffer, not a record)
- Instruction files (CLAUDE.md and friends) (What it helps: stable, human-vetted preferences; What it does not solve: rots silently; no extraction, no time model, no scoping; guidance, not state)
- Vector store bolted on (What it helps: semantic recall over past text; What it does not solve: stale-but-similar wins, no invalidation, no decay, recall only if the agent searches)
- Fine-tuning on your data (What it helps: style, vocabulary; What it does not solve: facts change weekly; retraining is the slowest possible write path; nothing is auditable or revocable)
Notice the pattern, because it is the same one from the text-to-SQL series: every fix tries to make the model better, but most of the seven problems are not model problems. They are structure problems, and structure is something you design.
The shape of an answer
Here is the thesis Part 2 builds out, in three ideas.
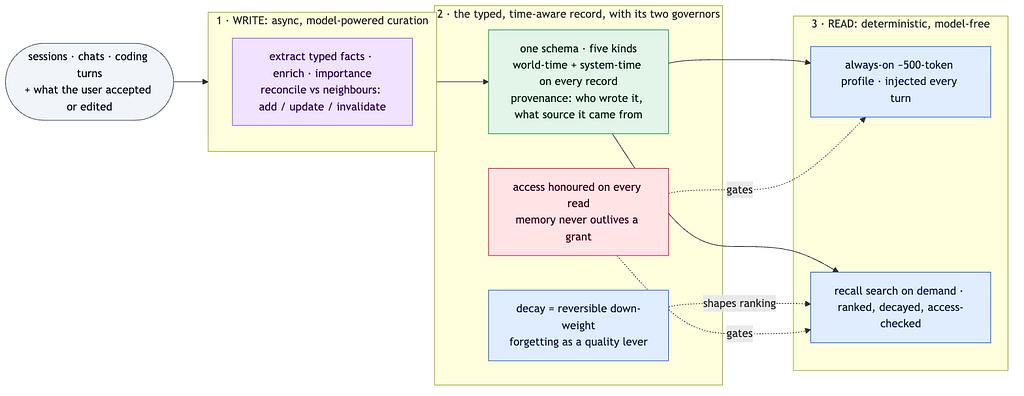
How to read it: model work (purple) happens once, asynchronously, on the write side. The record (green) travels with its two governors: decay (blue, deterministic), which shapes what surfaces, and the access pass (red), which gates every read. The two reads on the right are what the user actually waits on: deterministic search, checked against both governors, every time.
1. Memory is a typed, time-aware system of record, not a blob.
- One uniform record with a small set of kinds: exact facts, semantic notes, graph relationships, procedure references, and an identity block.
- Every record carries both timelines (world time, system time) and provenance (who wrote it, which source it came from). Contradictions invalidate; nothing silently disappears.
2. Split the write path from the read path, hard.
- All model intelligence lives on the asynchronous write path: extract, enrich, reconcile against neighbors, decide add-update-invalidate-or-ignore.
- The read path runs zero model calls. Every turn gets a cached, roughly 500-token profile injected automatically; deeper recall is a deterministic hybrid search (semantic, keyword, graph) with ranking. This is what makes memory fast enough to be ambient: the published systems that did this report retrieval latencies in the low seconds versus tens of seconds for context stuffing, at a tiny fraction of the tokens.
- If you read my earlier series, you have seen this move before: it is the same hard line that made text-to-SQL safe, applied to memory. The model proposes on the slow path; deterministic code serves on the fast path.
3. Forgetting and privacy are structural, not features.
- Decay is a score, not a delete: relevance multiplied by age, importance, and reinforcement, with per-kind half-lives, fully reversible, swept to an archive at the floor.
- Personal memory is local-first: the raw material never leaves infrastructure the user controls for distillation, and the distilled store lives where the user can read, edit, and export it.
- Access is honoured on every read: memory is handed the caller’s current entitlements and filters against them at recall time, so a revoked source means the derived memories stop surfacing. Memory never outlives a grant.
Key takeaways
- Agents without memory measurably degrade, around 30 percent on long-history benchmarks and worse on temporal questions, and users feel it as re-explaining themselves forever.
- A context window is a buffer, not a memory. Cost, degradation, compaction loss, and the absence of any model of truth make “bigger window” the wrong layer for the job.
- Today’s coping mechanisms each decay differently: instruction files rot, compaction forgets at the boundary, vector stores serve stale facts confidently, hosted memory is opaque and siloed.
- Memory decomposes into seven problems, and most are not retrieval: unit, write policy, distillation, contradiction, time, forgetting, and placement plus access. The last three are where the field is thinnest.
- The benchmarks reward hoarding. Recall-monotonic scoring cannot see forgetting or personalization, so building memory seriously means building your own evaluation harness too.
- The shape of the answer: a typed bitemporal record, async model-powered writes, a deterministic model-free read path, decay as reversible ranking, and access checked at every recall.
In Part 2, I get concrete: the two-pool architecture (personal memory versus project memory, and the pointer that joins them), the write and read paths in detail, how memory rides a git repo to become a team brain, why my memory engine refuses to do access control, and the part I find most interesting: how memory stops being a notebook and starts growing skills.
Further reading on the problem space: the LongMemEval benchmark (the five abilities and the cliff), Salesforce’s ConvoMem analysis of when naive context beats memory systems, Zep’s bitemporal memory-graph paper, and the A-MEM paper on agentic memory notes.
Next, Part 2: the architecture. Two pools, one record, three read depths, and memory that grows skills.
AI Agents Have Amnesia. A Bigger Context Window Won’t Cure It. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.