
Improving Our LangGraph Agent for Real-World E-Commerce: Enterprise Validation, Business Logic…
Improving Our LangGraph Agent for Real-World E-Commerce: Enterprise Validation, Business Logic Guards, and a Multi-Agent Architecture
The patterns that separate a LangGraph demo from a system you can actually deploy.
The article Murat Geldyev’s comment made inevitable. Building on the original ShopBot, closing every gap, and turning a sandbox agent into something you could actually defend in a production review.
What this article assumes: You have read and understood the original ShopBot article (LINK) . You know the seven-module structure, how tools work, how the ReAct loop runs, and how interrupt() pauses a graph for human approval. If you haven’t built ShopBot yet, build it first. This article is a direct continuation, not a standalone.
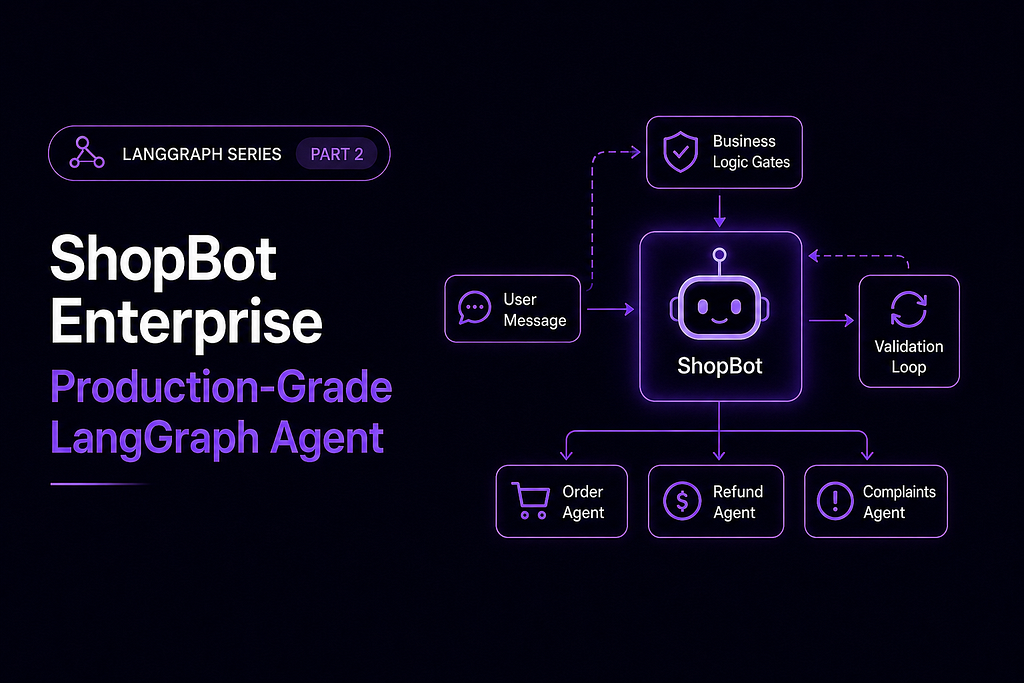
What we are building: The original ShopBot, extended with three new capabilities that the comment section identified as real gaps. Business Logic Gates that validate every LLM output before it touches an external system. A validation loop that automatically corrects hallucinations rather than crashing. A multi-agent architecture that splits ShopBot into three specialist sub-agents orchestrated by a Supervisor. By the end, the codebase looks like something you could walk into a production review with.
The Gap in the Original ShopBot
The original ShopBot was honest about what it was: a complete implementation of everything from Parts 0 through 5of the series. Every concept worked. Every module was in the right place. But it had one silent assumption built into every node, every tool call, every routing decision.
It assumed the LLM was right.
Read through the original code and you will see this assumption everywhere. The agent calls check_refund_eligibility and trusts that the order ID it passes was correctly extracted from the conversation. The review_refund node surfaces the order ID to the human reviewer, but the human is approving or rejecting the action, not validating whether the order ID is even real. The process_refund tool gets called with whatever arguments the LLM decided to use. If the LLM hallucinates “ORD-99X” instead of “ORD-001”, the tool will return an error, the agent will see that error, and something reasonable might happen. But “something reasonable might happen” is not an acceptable description of a financial system’s error handling.
Murat Geldyev named this precisely: in enterprise workflows like automated procurement or compliance checking, you cannot afford probabilistic failures. The fix is not to trust the LLM more. The fix is to stop trusting it at all, and validate every structured output with deterministic Python code before it touches anything external.

That is what this article builds.
What We Are Adding and Why
Three new capabilities, each closing a specific gap:
Business Logic Gates sit inside nodes and validate LLM output before it acts. They are pure Python. They have no LLM calls. They either pass the data through or they reject it with a specific, structured reason. This is deterministic validation in a probabilistic system.
Validation Loops handle gate failures. When a gate rejects something, the graph does not crash and does not silently produce a wrong answer. It routes back to a correction node that feeds the failure reason to the LLM and asks for a corrected output. A retry counter in state prevents infinite loops. A hard maximum triggers an escalation to a human rather than looping forever.
Multi-Agent Architecture splits the single agent_node into three specialist sub-agents: an Order Agent that handles lookups and status queries, a Refund Agent that handles eligibility checking and refund processing, and a Complaints Agent that handles frustrated customers and escalations. A Supervisor node reads each incoming message and routes to the right specialist. Each specialist is its own compiled subgraph.
These three capabilities are not independent. They compose. The Refund Agent has a Business Logic Gate. The gate can trigger a Validation Loop. The Supervisor reads the loop’s outcome and decides whether to retry, escalate, or abort. That composition is what makes the final system genuinely enterprise-grade.
Before We Write Code: The New Plan
The original article made the point that LangGraph rewards planning. It is even more true now that the graph is larger. Draw this before you touch a keyboard.
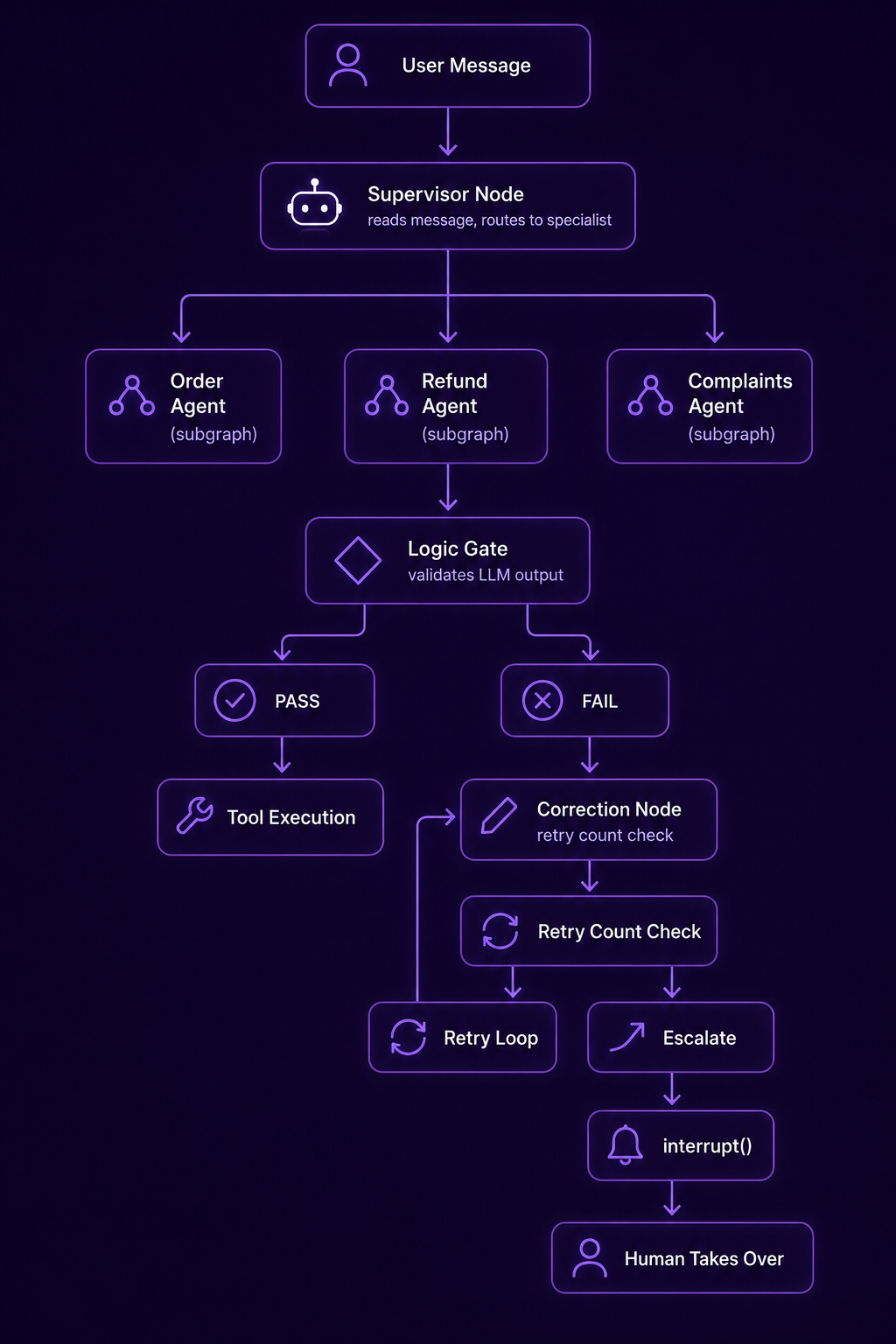
That is the full system. Every box maps to exactly one node or one routing function. Every arrow maps to exactly one edge. Write this down. The code that follows is just translating this picture into Python, module by module, exactly as you have learned.
This tutorial, paired with a Jungle album, is all you need right now. Try it if you don’t believe me 😁✌️ Happy coding!
The New File Structure
The original ShopBot lived in one file: shopbot.py. As the system grows, one file becomes unmanageable. We split into three files:
shopbot_enterprise/
├── gates.py ← Business Logic Gates (pure Python, no LangGraph imports)
├── agents.py ← All three specialist subgraphs
└── shopbot.py ← Supervisor graph + entrypoint (unchanged module structure)
The gates.py file having no LangGraph imports is deliberate. It makes gates independently testable with plain Python unit tests. You do not need an LLM, a graph, or even a running process to test whether your validation logic is correct. You just call the gate function with sample data and assert the result. This is what “deterministic” means in practice.
Module 2 Extended: The New State Schema
Before anything else, the state needs new fields. The original had three custom fields: summary, customer_name, and ticket_category. We add four more.
# ============================================================
# MODULE 2: STATE (Enterprise Version)
# ============================================================
from typing import TypedDict, Annotated
from langgraph.graph import MessagesState
import operator
class SupportState(MessagesState):
# From the original ShopBot - unchanged
summary: str
customer_name: str
ticket_category: str
# NEW: The structured data the LLM extracted from the conversation.
# Gates validate this field. Tools use this field. The LLM never
# writes to external systems directly - it writes here first.
extracted_data: dict
# NEW: The current status of the gate decision for this turn.
# Values: "pending" | "passed" | "failed" | "escalated" | "aborted"
# The supervisor reads this to decide what to do after a gate runs.
gate_status: str
# NEW: A log of every gate failure in this conversation.
# Uses operator.add so entries accumulate rather than replace.
# This is your audit trail. Every compliance system needs one.
validation_errors: Annotated[list[str], operator.add]
# NEW: How many correction attempts have fired in this turn.
# The hard cap is 2. After 2 failed corrections, escalate to human.
# Without this, a broken LLM output creates an infinite loop.
retry_count: int
The most important new field is extracted_data. In the original ShopBot, the LLM produced free-form text and also called tools directly. The agent trusted whatever arguments the LLM put in its tool call. Now, the LLM is asked to produce structured data first. That structured data goes into state[“extracted_data”]. The gate validates it. Only after the gate passes does the data become a tool argument. The LLM no longer has a direct path to external systems.
The validation_errors field being Annotated with operator.add means it accumulates across the entire conversation, not just one turn. If the LLM hallucinated a bad order ID in turn three and a bad refund reason in turn seven, both errors are in the audit log. This matters for compliance reviews.
The New File: gates.py
Business Logic Gates are pure Python validation functions. Each gate takes extracted data as input and returns a tuple: (True, cleaned_data) on success, (False, error_reason) on failure. That’s the entire interface. No LLM calls. No graph dependencies. Just Python.
# ============================================================
# gates.py — Business Logic Gates
# Pure Python. No LangGraph. No LLM calls.
# Each gate returns (bool, data_or_error_string).
# ============================================================
import re
# The same fake database as the original ShopBot.
# In production this would be a database query.
ORDERS_DB = {
"ORD-001": {"customer": "Alex", "product": "Wireless Headphones",
"status": "Delivered", "amount": 89.99,
"delivery_date": "2025-06-10"},
"ORD-002": {"customer": "Sam", "product": "Phone Case",
"status": "In Transit", "amount": 14.99,
"delivery_date": "Expected 2025-06-18"},
"ORD-003": {"customer": "Jordan", "product": "Laptop Stand",
"status": "Processing", "amount": 45.00,
"delivery_date": "Expected 2025-06-20"},
}
MAX_REFUND_AMOUNT = 500.00 # Business rule: auto-refunds above this need director sign-off
MIN_REASON_LENGTH = 10 # Business rule: refund reasons must be substantive
def validate_order_id(extracted_data: dict) -> tuple[bool, dict | str]:
"""
Gate 1: Order ID Validation
Checks that the order ID the LLM extracted actually exists in our system
and follows the correct format. This is the most basic hallucination check
in a support workflow. LLMs frequently confuse order IDs, especially when
a customer has mentioned multiple orders or used an informal format like
"order one" instead of "ORD-001".
Why this matters: if the agent calls a tool with a hallucinated order ID,
the tool returns an error, the agent sees the error, and may hallucinate
a recovery that looks plausible but is wrong. Catching it here, before
the tool call, is the correct place to stop the failure.
"""
order_id = extracted_data.get("order_id", "").strip().upper()
# Check 1: Format validation - must match ORD-XXX pattern
if not re.match(r"^ORD-d{3}$", order_id):
return (
False,
f"Order ID '{order_id}' does not match the required format ORD-XXX "
f"(example: ORD-001). The LLM may have extracted the wrong value. "
f"Ask the customer to confirm their exact order number."
)
# Check 2: Existence validation - must exist in our system
if order_id not in ORDERS_DB:
return (
False,
f"Order ID '{order_id}' passed format validation but does not exist "
f"in the orders database. This is likely a hallucination. "
f"Ask the customer to provide the exact order ID from their confirmation email."
)
# Gate passed: return cleaned data with the normalised order ID
cleaned = {**extracted_data, "order_id": order_id}
return True, cleaned
def validate_refund_request(extracted_data: dict) -> tuple[bool, dict | str]:
"""
Gate 2: Refund Request Validation
A compound gate that checks every business rule that must be true
before a refund can be processed. Runs after validate_order_id passes,
so we can assume order_id is valid at this point.
Business rules checked:
1. The order must exist and have Delivered status
2. The refund amount must be below the auto-approval threshold
3. The reason must be substantive (not empty or one word)
Each failed rule produces a specific error message that gets fed back
to the LLM as a correction instruction. Vague errors produce vague
corrections. Specific errors produce specific corrections.
"""
order_id = extracted_data.get("order_id", "").strip().upper()
reason = extracted_data.get("reason", "").strip()
order = ORDERS_DB.get(order_id, {})
errors = []
# Rule 1: Order must be in Delivered status
if order.get("status") != "Delivered":
errors.append(
f"Order {order_id} has status '{order.get('status')}'. "
f"Refunds can only be processed for Delivered orders. "
f"Inform the customer and do not attempt to process a refund."
)
# Rule 2: Amount must be within auto-approval limit
amount = order.get("amount", 0)
if amount > MAX_REFUND_AMOUNT:
errors.append(
f"Refund amount ${amount:.2f} exceeds the auto-approval limit "
f"of ${MAX_REFUND_AMOUNT:.2f}. This requires director-level sign-off. "
f"Escalate to a senior agent - do not process automatically."
)
# Rule 3: Reason must be substantive
if len(reason) < MIN_REASON_LENGTH:
errors.append(
f"Refund reason '{reason}' is too short (minimum {MIN_REASON_LENGTH} characters). "
f"Ask the customer to provide a more detailed reason for their return request."
)
if errors:
# Return all errors joined - the correction node will feed this
# exact string back to the LLM as a correction instruction
return False, " | ".join(errors)
return True, extracted_data
def validate_complaint(extracted_data: dict) -> tuple[bool, dict | str]:
"""
Gate 3: Complaint Validation
Ensures the complaints agent has enough structured data to work with
before attempting any escalation or response. Complaints without
a clear issue category cannot be routed correctly in a real ticketing system.
"""
issue_summary = extracted_data.get("issue_summary", "").strip()
sentiment = extracted_data.get("sentiment", "").strip().lower()
valid_sentiments = {"frustrated", "angry", "neutral", "disappointed"}
if len(issue_summary) < 20:
return (
False,
f"Complaint issue summary is too vague: '{issue_summary}'. "
f"Ask the customer to describe their problem in more detail before escalating."
)
if sentiment not in valid_sentiments:
return (
False,
f"Sentiment '{sentiment}' is not a recognised value. "
f"Valid values are: {', '.join(valid_sentiments)}. "
f"Re-classify the customer's sentiment and try again."
)
return True, extracted_data
Notice what is not in this file: imports from LangGraph, from LangChain, from any AI library. This is pure Python that any developer on your team can read, test, and modify without understanding agent architecture. When a compliance auditor asks “what exactly validates a refund request before money moves?”, you show them this file. It is readable by non-engineers.
Module 4 Extended: The Validation Loop Pattern
Now the critical new node that makes gates useful: the correction node. When a gate fails, execution does not stop. It routes here. The correction node takes the specific failure reason from state, builds an instruction for the LLM explaining exactly what was wrong, and asks for a corrected structured output.
# ── agents.py (partial) ─────────────────────────────────────
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from pydantic import BaseModel, Field
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# ── Pydantic Models (Structured LLM Output) ──────────────────
# These are the schemas that define what the LLM must return.
# with_structured_output() enforces these - if the LLM returns
# something that doesn't match, Pydantic raises a validation error
# before the output even reaches a gate.
class OrderExtraction(BaseModel):
order_id: str = Field(description="The order ID in the format ORD-XXX, e.g. ORD-001")
query_type: str = Field(description="What the customer wants to know: 'status', 'delivery_date', 'product', or 'general'")
class RefundExtraction(BaseModel):
order_id: str = Field(description="The order ID in the format ORD-XXX")
reason: str = Field(description="The customer's stated reason for wanting a refund, in their own words")
class ComplaintExtraction(BaseModel):
issue_summary: str = Field(description="A one-sentence summary of the customer's complaint")
sentiment: str = Field(description="The customer's emotional state: 'frustrated', 'angry', 'neutral', or 'disappointed'")
# ── The Correction Node ───────────────────────────────────────
def correction_node(state) -> dict:
"""
The validation loop's core. When a Business Logic Gate fails, this
node receives control. It reads the most recent gate failure from
state, builds a precise correction instruction for the LLM, and
asks for a new extraction attempt.
This node is shared across all three specialist agents. The
ticket_category in state tells it which Pydantic model to use
for the re-extraction, so the same node handles order corrections,
refund corrections, and complaint corrections without duplicating logic.
Critical design decision: the correction instruction goes into the
messages list as a HumanMessage, not a SystemMessage. This makes it
part of the visible conversation history. If the LLM makes the same
mistake twice, the history shows both the first failure and the second
correction attempt, which helps diagnose systematic prompt problems.
"""
# Read the most recent validation error from the audit log
errors = state.get("validation_errors", [])
last_error = errors[-1] if errors else "Unknown validation error."
retry_count = state.get("retry_count", 0)
# Hard stop: after 2 retries, do not attempt again - escalate
if retry_count >= 2:
return {
"gate_status": "escalated",
"messages": [
AIMessage(
content=(
f"I was unable to process your request correctly after {retry_count} attempts. "
f"I'm escalating this to a senior support agent who will contact you directly. "
f"I apologise for the inconvenience."
)
)
]
}
# Build the correction instruction - be maximally specific
correction_instruction = (
f"Your previous response contained a validation error that must be corrected "
f"before we can proceed. The exact error was:nn"
f"{last_error}nn"
f"Please re-read the conversation carefully and provide a corrected response "
f"that addresses this specific error. Do not repeat the same mistake."
)
category = state.get("ticket_category", "order_inquiry")
# Choose the right structured output model based on what kind of
# correction is needed
if category == "refund_request":
structured_llm = llm.with_structured_output(RefundExtraction)
elif category == "complaint":
structured_llm = llm.with_structured_output(ComplaintExtraction)
else:
structured_llm = llm.with_structured_output(OrderExtraction)
messages = (
[SystemMessage(content="You are a customer support assistant. Extract the requested information accurately.")]
+ state["messages"]
+ [HumanMessage(content=correction_instruction)]
)
try:
corrected = structured_llm.invoke(messages)
return {
"extracted_data": corrected.model_dump(),
"gate_status": "pending",
"retry_count": retry_count + 1,
"messages": [HumanMessage(content=correction_instruction)],
}
except Exception as e:
# Structured output itself failed (Pydantic validation error)
# Count this as a retry and surface the raw error
return {
"gate_status": "failed",
"retry_count": retry_count + 1,
"validation_errors": [f"Structured output failed: {str(e)}"],
}
The retry_count check at the top of this node is the most important safety mechanism in the entire system. Without it, a genuinely broken input (a customer who refuses to provide a valid order ID, or an LLM configuration that consistently hallucinates) creates an infinite loop between the correction node and the gate. Two retries is a reasonable default for a support agent: it gives the LLM two chances to self-correct before involving a human. Adjust this number based on your tolerance for latency versus accuracy.
Module 4 Continued: The Three Specialist Subgraphs
Each specialist is a compiled subgraph. Each has its own tools, its own extraction logic, its own gate, and its own internal routing. The parent Supervisor graph doesn’t know or care about any of that internal structure — it just sees a node that receives state and returns state.
The Order Agent Subgraph
# ── agents.py (continued) ────────────────────────────────────
from langchain_core.tools import tool
from langgraph.graph import StateGraph, START, END
from langgraph.prebuilt import ToolNode
from gates import validate_order_id, ORDERS_DB
@tool
def lookup_order(order_id: str) -> str:
"""Look up the details of a customer's order by order ID.
Use this when the customer wants to know their order status,
product name, or expected delivery date.
"""
order = ORDERS_DB.get(order_id.upper())
if not order:
return f"No order found with ID '{order_id}'."
return (
f"Order {order_id.upper()}: {order['product']} | "
f"Status: {order['status']} | "
f"Amount: ${order['amount']:.2f} | "
f"Delivery: {order['delivery_date']}"
)
order_tools = [lookup_order]
order_tool_node = ToolNode(order_tools)
order_llm = llm.bind_tools(order_tools)
def order_extract_node(state) -> dict:
"""
Step 1 for the Order Agent: extract the order ID from the conversation
using structured output. The result goes into state['extracted_data'].
The gate runs next. The tool call only happens if the gate passes.
"""
structured_llm = llm.with_structured_output(OrderExtraction)
messages = (
[SystemMessage(content="Extract the order ID and query type from the customer's message.")]
+ state["messages"]
)
try:
result = structured_llm.invoke(messages)
return {
"extracted_data": result.model_dump(),
"gate_status": "pending",
"ticket_category": "order_inquiry",
}
except Exception as e:
return {
"gate_status": "failed",
"validation_errors": [f"Extraction failed: {str(e)}"],
"ticket_category": "order_inquiry",
}
def order_gate_node(state) -> dict:
"""
Step 2: Run the Business Logic Gate on the extracted data.
Either passes gate_status to 'passed' and lets the tool run,
or sets it to 'failed' and logs the reason to validation_errors.
"""
extracted = state.get("extracted_data", {})
passed, result = validate_order_id(extracted)
if passed:
return {"gate_status": "passed", "extracted_data": result}
return {
"gate_status": "failed",
"validation_errors": [result], # operator.add accumulates this
}
def order_agent_node(state) -> dict:
"""
Step 3 (only runs after gate passes): call the LLM with tools bound.
Now the LLM uses the validated order_id from extracted_data rather
than whatever it decided to extract ad hoc.
"""
extracted = state.get("extracted_data", {})
order_id = extracted.get("order_id", "")
messages = (
[SystemMessage(content=(
"You are the Order Agent for ShopBot. Your only job is to look up "
"order information and report it clearly to the customer. "
f"The validated order ID is {order_id}. Use lookup_order to get the details."
))]
+ state["messages"]
)
response = order_llm.invoke(messages)
return {"messages": [response]}
def route_order_gate(state) -> str:
status = state.get("gate_status", "pending")
if status == "passed":
return "order_agent_node"
if state.get("retry_count", 0) >= 2:
return "order_agent_node" # correction_node already added the escalation message
return "correction_node"
def route_order_agent(state) -> str:
last = state["messages"][-1]
if hasattr(last, "tool_calls") and last.tool_calls:
return "order_tools"
return "__end__"
# ── Order subgraph assembly ──────────────────────────────────
order_builder = StateGraph(state_schema=type(None)) # Uses parent state directly
order_builder = StateGraph(dict)
order_builder.add_node("order_extract_node", order_extract_node)
order_builder.add_node("order_gate_node", order_gate_node)
order_builder.add_node("correction_node", correction_node)
order_builder.add_node("order_agent_node", order_agent_node)
order_builder.add_node("order_tools", order_tool_node)
order_builder.add_edge(START, "order_extract_node")
order_builder.add_edge("order_extract_node", "order_gate_node")
order_builder.add_conditional_edges(
"order_gate_node",
route_order_gate,
{"order_agent_node": "order_agent_node", "correction_node": "correction_node"}
)
order_builder.add_edge("correction_node", "order_gate_node")
order_builder.add_conditional_edges(
"order_agent_node",
route_order_agent,
{"order_tools": "order_tools", "__end__": END}
)
order_builder.add_edge("order_tools", "order_agent_node")
order_agent = order_builder.compile()
Notice the loop: order_gate_node feeds into correction_node on failure, and correction_node feeds back into order_gate_node. This is the validation loop. It will run at most twice before the retry counter triggers the escalation message.
The Refund Agent Subgraph
The Refund Agent is the most consequential specialist because it handles money. It has two gates (order ID validation, then full refund validation), and the human approval interrupt from the original ShopBot is preserved inside this subgraph.
# ── agents.py (continued) ────────────────────────────────────
from gates import validate_order_id, validate_refund_request
from langgraph.types import interrupt, Command
from langchain_core.messages import ToolMessage
from datetime import datetime
@tool
def check_refund_eligibility(order_id: str) -> str:
"""Check whether an order is eligible for a refund.
An order is eligible only if its status is Delivered.
"""
order = ORDERS_DB.get(order_id.upper())
if not order:
return f"Cannot check refund: order '{order_id}' not found."
if order["status"] == "Delivered":
return (
f"Order {order_id.upper()} IS eligible for a refund. "
f"Amount: ${order['amount']:.2f}."
)
return (
f"Order {order_id.upper()} is NOT eligible. "
f"Status: {order['status']}."
)
@tool
def process_refund(order_id: str, reason: str) -> str:
"""Process a refund for a delivered order.
Only call this after human approval has been confirmed.
"""
order = ORDERS_DB.get(order_id.upper())
if not order:
return f"Refund failed: order '{order_id}' not found."
ref = f"REF-{order_id.upper()}-{datetime.now().strftime('%H%M%S')}"
return (
f"Refund APPROVED and PROCESSED. Reference: {ref}. "
f"${order['amount']:.2f} will be returned within 3 to 5 business days."
)
refund_tools = [check_refund_eligibility, process_refund]
refund_tool_node = ToolNode(refund_tools)
refund_llm = llm.bind_tools(refund_tools)
def refund_extract_node(state) -> dict:
structured_llm = llm.with_structured_output(RefundExtraction)
messages = (
[SystemMessage(content="Extract the order ID and refund reason from the customer's message.")]
+ state["messages"]
)
try:
result = structured_llm.invoke(messages)
return {
"extracted_data": result.model_dump(),
"gate_status": "pending",
"ticket_category": "refund_request",
}
except Exception as e:
return {
"gate_status": "failed",
"validation_errors": [f"Refund extraction failed: {str(e)}"],
"ticket_category": "refund_request",
}
def refund_gate_node(state) -> dict:
"""
Compound gate: runs both order ID validation and full refund validation.
Both must pass for execution to continue.
"""
extracted = state.get("extracted_data", {})
# Gate 1: Order ID
id_passed, id_result = validate_order_id(extracted)
if not id_passed:
return {"gate_status": "failed", "validation_errors": [id_result]}
# Gate 2: Full refund rules (eligibility, amount, reason)
ref_passed, ref_result = validate_refund_request(id_result)
if not ref_passed:
return {"gate_status": "failed", "validation_errors": [ref_result]}
return {"gate_status": "passed", "extracted_data": ref_result}
def refund_review_node(state) -> dict:
"""
The human approval gate, carried over from the original ShopBot
and now living inside the Refund Agent subgraph.
interrupt() pauses the entire graph here. The parent graph's
checkpointer saves the state. A human reviews the details.
Command(resume=...) restarts from this exact line.
"""
last_message = state["messages"][-1]
refund_tool_call = None
if hasattr(last_message, "tool_calls"):
for tc in last_message.tool_calls:
if "refund" in tc["name"].lower():
refund_tool_call = tc
break
extracted = state.get("extracted_data", {})
human_decision = interrupt({
"message": "Refund approval required",
"order_id": extracted.get("order_id", "Unknown"),
"reason": extracted.get("reason", "Not provided"),
"tool_being_called": refund_tool_call["name"] if refund_tool_call else "process_refund",
"arguments": refund_tool_call["args"] if refund_tool_call else extracted,
"summary": state.get("summary", "No summary yet"),
"options": ["approve", "reject", "escalate"],
})
if human_decision == "approve":
return {}
if human_decision in ("reject", "escalate"):
label = "declined" if human_decision == "reject" else "escalated to a senior agent"
return {
"messages": [
ToolMessage(
content=f"Refund request was {label} by the support team.",
tool_call_id=refund_tool_call["id"] if refund_tool_call else "unknown",
)
]
}
return {}
def refund_agent_node(state) -> dict:
extracted = state.get("extracted_data", {})
messages = (
[SystemMessage(content=(
"You are the Refund Agent for ShopBot. Your job is to check refund "
"eligibility and process approved refunds. "
f"Validated order ID: {extracted.get('order_id', '')}. "
f"Customer reason: {extracted.get('reason', '')}. "
"Always check eligibility first, then process if eligible and approved."
))]
+ state["messages"]
)
response = refund_llm.invoke(messages)
return {"messages": [response]}
def route_refund_gate(state) -> str:
status = state.get("gate_status", "pending")
if status == "passed":
return "refund_agent_node"
if state.get("retry_count", 0) >= 2:
return "refund_agent_node"
return "correction_node"
def route_refund_agent(state) -> str:
last = state["messages"][-1]
if hasattr(last, "tool_calls") and last.tool_calls:
tool_names = [tc["name"] for tc in last.tool_calls]
if "process_refund" in tool_names:
return "refund_review_node"
return "refund_tools"
return "__end__"
def route_after_review(state) -> str:
last = state["messages"][-1]
if isinstance(last, ToolMessage):
return "refund_agent_node"
return "refund_tools"
# ── Refund subgraph assembly ─────────────────────────────────
refund_builder = StateGraph(dict)
refund_builder.add_node("refund_extract_node", refund_extract_node)
refund_builder.add_node("refund_gate_node", refund_gate_node)
refund_builder.add_node("correction_node", correction_node)
refund_builder.add_node("refund_agent_node", refund_agent_node)
refund_builder.add_node("refund_review_node", refund_review_node)
refund_builder.add_node("refund_tools", refund_tool_node)
refund_builder.add_edge(START, "refund_extract_node")
refund_builder.add_edge("refund_extract_node", "refund_gate_node")
refund_builder.add_conditional_edges(
"refund_gate_node",
route_refund_gate,
{"refund_agent_node": "refund_agent_node", "correction_node": "correction_node"}
)
refund_builder.add_edge("correction_node", "refund_gate_node")
refund_builder.add_conditional_edges(
"refund_agent_node",
route_refund_agent,
{
"refund_review_node": "refund_review_node",
"refund_tools": "refund_tools",
"__end__": END,
}
)
refund_builder.add_conditional_edges(
"refund_review_node",
route_after_review,
{"refund_tools": "refund_tools", "refund_agent_node": "refund_agent_node"}
)
refund_builder.add_edge("refund_tools", "refund_agent_node")
refund_agent = refund_builder.compile()
The Complaints Agent Subgraph
The Complaints Agent is the simplest of the three. Its job is to acknowledge the customer’s frustration, validate that there is enough information to open a support ticket, and escalate to a human via interrupt() if the sentiment is strong enough.
# ── agents.py (continued) ────────────────────────────────────
from gates import validate_complaint
complaints_llm = llm # Complaints agent doesn't need tool-calling
def complaints_extract_node(state) -> dict:
structured_llm = llm.with_structured_output(ComplaintExtraction)
messages = (
[SystemMessage(content=(
"Extract the complaint summary and the customer's emotional sentiment "
"from the conversation. Sentiment must be one of: frustrated, angry, "
"neutral, disappointed."
))]
+ state["messages"]
)
try:
result = structured_llm.invoke(messages)
return {
"extracted_data": result.model_dump(),
"gate_status": "pending",
"ticket_category": "complaint",
}
except Exception as e:
return {
"gate_status": "failed",
"validation_errors": [f"Complaint extraction failed: {str(e)}"],
"ticket_category": "complaint",
}
def complaints_gate_node(state) -> dict:
extracted = state.get("extracted_data", {})
passed, result = validate_complaint(extracted)
if passed:
return {"gate_status": "passed", "extracted_data": result}
return {"gate_status": "failed", "validation_errors": [result]}
def complaints_respond_node(state) -> dict:
"""
For high-sentiment complaints (frustrated, angry), trigger a human
escalation via interrupt(). For lower-sentiment complaints, the LLM
responds empathetically and the turn ends.
This mirrors the Part 3 pattern but applied conditionally based on
the validated sentiment field, not a keyword scan of free-form text.
The gate already confirmed the sentiment is a valid value, so this
routing decision is deterministic.
"""
extracted = state.get("extracted_data", {})
sentiment = extracted.get("sentiment", "neutral")
if sentiment in ("frustrated", "angry"):
human_decision = interrupt({
"message": "High-sentiment complaint requires human review",
"issue_summary": extracted.get("issue_summary", ""),
"sentiment": sentiment,
"options": ["escalate_to_senior", "provide_compensation", "close_ticket"],
})
if human_decision == "escalate_to_senior":
response_text = (
"I completely understand your frustration, and I want to make sure "
"you receive the best possible support. I am escalating your case to "
"a senior support agent who will contact you within 2 business hours. "
"Your ticket has been flagged as priority."
)
elif human_decision == "provide_compensation":
response_text = (
"I sincerely apologise for the experience you have had. As a gesture "
"of goodwill, our team will be in touch within 24 hours with a resolution "
"that includes appropriate compensation for the inconvenience caused."
)
else:
response_text = (
"Thank you for bringing this to our attention. Your feedback has been "
"recorded and will help us improve our service."
)
from langchain_core.messages import AIMessage
return {"messages": [AIMessage(content=response_text)]}
# Lower-sentiment complaints: LLM responds empathetically
messages = (
[SystemMessage(content=(
"You are the Complaints Agent for ShopBot. The customer has a complaint. "
"Respond with genuine empathy, acknowledge their specific issue, and "
"explain what steps will be taken. Be warm and professional."
))]
+ state["messages"]
)
response = complaints_llm.invoke(messages)
return {"messages": [response]}
def route_complaints_gate(state) -> str:
status = state.get("gate_status", "pending")
if status == "passed":
return "complaints_respond_node"
if state.get("retry_count", 0) >= 2:
return "complaints_respond_node"
return "correction_node"
# ── Complaints subgraph assembly ─────────────────────────────
complaints_builder = StateGraph(dict)
complaints_builder.add_node("complaints_extract_node", complaints_extract_node)
complaints_builder.add_node("complaints_gate_node", complaints_gate_node)
complaints_builder.add_node("correction_node", correction_node)
complaints_builder.add_node("complaints_respond_node", complaints_respond_node)
complaints_builder.add_edge(START, "complaints_extract_node")
complaints_builder.add_edge("complaints_extract_node", "complaints_gate_node")
complaints_builder.add_conditional_edges(
"complaints_gate_node",
route_complaints_gate,
{
"complaints_respond_node": "complaints_respond_node",
"correction_node": "correction_node",
}
)
complaints_builder.add_edge("correction_node", "complaints_gate_node")
complaints_builder.add_edge("complaints_respond_node", END)
complaints_agent = complaints_builder.compile()
The Main shopbot.py: The Supervisor Graph
With the three subgraphs compiled, the Supervisor graph is remarkably simple. Its only job is routing. It never does specialist work itself. This is the fundamental principle from Part 4’s multi-agent patterns: the supervisor routes, the specialists execute.
# ============================================================
# shopbot.py — Supervisor Graph (Enterprise Version)
# ============================================================
# ── MODULE 1: IMPORTS & CONFIGURATION ───────────────────────
import os
from typing import Literal
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, RemoveMessage, AIMessage
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.checkpoint.memory import MemorySaver
from langgraph.types import Command
# Import the compiled subgraphs from agents.py
from agents import order_agent, refund_agent, complaints_agent
from state import SupportState # The extended state from Module 2 above
load_dotenv()
# The supervisor uses a plain LLM - no tools, just routing decisions
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# ── MODULE 4: SUPERVISOR NODE ────────────────────────────────
SUPERVISOR_SYSTEM = """You are the ShopBot Supervisor. Your only job is to read
the customer's message and decide which specialist should handle it.
Available specialists:
order_agent - handles order status, delivery date, and product questions
refund_agent - handles refund requests and return eligibility
complaints_agent - handles complaints, frustration, and negative feedback
FINISH - use this only when the conversation is fully resolved
Respond with exactly one word: the name of the specialist, or FINISH."""
def supervisor_node(state: SupportState) -> dict:
"""
Reads the full conversation and routes to the correct specialist.
Returns a next_agent string that the routing function reads.
Uses plain LLM with no tools - the supervisor decides, it never acts.
This separation keeps the routing logic deterministic and auditable.
"""
messages = [SystemMessage(content=SUPERVISOR_SYSTEM)] + state["messages"]
response = llm.invoke(messages)
decision = response.content.strip().lower()
# Normalise the response in case the LLM adds punctuation or casing
if "refund" in decision:
next_agent = "refund_agent"
elif "complaint" in decision or "frustrated" in decision:
next_agent = "complaints_agent"
elif "order" in decision:
next_agent = "order_agent"
elif "finish" in decision:
next_agent = "FINISH"
else:
next_agent = "order_agent" # Safe default for ambiguous routing
return {"next_agent": next_agent}
# ── MODULE 4 CONTINUED: SUMMARIZE NODE ───────────────────────
# Carried over from the original ShopBot without changes.
# The enterprise version still needs conversation compression.
def summarize_node(state: SupportState) -> dict:
existing_summary = state.get("summary", "")
instruction = (
f"Current summary:n{existing_summary}nnExtend with new messages. "
"Under 5 sentences. Include customer name, issue, orders mentioned, actions taken."
if existing_summary
else "Summarise this support conversation in under 5 sentences."
)
messages = state["messages"] + [HumanMessage(content=instruction)]
response = llm.invoke(messages)
to_delete = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]
return {"summary": response.content, "messages": to_delete}
# ── MODULE 5: ROUTING ────────────────────────────────────────
def route_supervisor(state: SupportState) -> Literal[
"order_agent", "refund_agent", "complaints_agent", "summarize_node", "__end__"
]:
"""
Reads next_agent from state and routes accordingly.
Also checks whether the conversation is long enough to need summarisation.
"""
next_agent = state.get("next_agent", "order_agent")
if next_agent == "FINISH":
if len(state["messages"]) > 6:
return "summarize_node"
return "__end__"
return next_agent
# ── MODULE 6: GRAPH ASSEMBLY ─────────────────────────────────
graph_builder = StateGraph(SupportState)
graph_builder.add_node("supervisor", supervisor_node)
graph_builder.add_node("order_agent", order_agent) # compiled subgraph
graph_builder.add_node("refund_agent", refund_agent) # compiled subgraph
graph_builder.add_node("complaints_agent", complaints_agent) # compiled subgraph
graph_builder.add_node("summarize_node", summarize_node)
graph_builder.add_edge(START, "supervisor")
graph_builder.add_conditional_edges(
"supervisor",
route_supervisor,
{
"order_agent": "order_agent",
"refund_agent": "refund_agent",
"complaints_agent": "complaints_agent",
"summarize_node": "summarize_node",
"__end__": END,
}
)
# After each specialist finishes, always return to supervisor.
# The supervisor re-evaluates and decides: another specialist, or FINISH.
graph_builder.add_edge("order_agent", "supervisor")
graph_builder.add_edge("refund_agent", "supervisor")
graph_builder.add_edge("complaints_agent", "supervisor")
graph_builder.add_edge("summarize_node", END)
memory = MemorySaver()
shopbot = graph_builder.compile(checkpointer=memory)
# ── MODULE 7: ENTRYPOINT ──────────────────────────────────────
def run_shopbot():
print("=" * 60)
print(" ShopBot Enterprise - Multi-Agent Customer Support")
print("=" * 60)
print("Type your message. Type 'exit' to quit. Type 'audit' to")
print("see the validation error log for this session.n")
config = {"configurable": {"thread_id": "enterprise-session-001"}}
while True:
user_input = input("You: ").strip()
if not user_input:
continue
if user_input.lower() == "exit":
print("ShopBot: Thank you for contacting ShopBot. Have a great day!")
break
if user_input.lower() == "audit":
snapshot = shopbot.get_state(config)
errors = snapshot.values.get("validation_errors", [])
print(f"n[AUDIT LOG] {len(errors)} validation event(s) this session:")
for i, err in enumerate(errors, 1):
print(f" {i}. {err}")
print()
continue
result = shopbot.invoke(
{"messages": [HumanMessage(content=user_input)]},
config=config,
)
while "__interrupt__" in result:
interrupt_data = result["__interrupt__"][0].value
print("n" + "=" * 60)
print(" HUMAN REVIEW REQUIRED")
print("=" * 60)
for key, value in interrupt_data.items():
if key != "options":
print(f" {key.replace('_', ' ').title()}: {value}")
options = interrupt_data.get("options", [])
print(f"n Options: {' | '.join(f'[{o[0]}] {o}' for o in options)}")
raw = input(" Your decision: ").strip().lower()
chosen = next((o for o in options if o.startswith(raw)), options[-1])
result = shopbot.invoke(Command(resume=chosen), config=config)
last = result["messages"][-1]
print(f"nShopBot: {last.content}n")
if __name__ == "__main__":
run_shopbot()
What Is Different Now and Why It Matters
The original ShopBot and the enterprise ShopBot are both correct implementations of the series patterns. But they make different assumptions, and that difference matters when you move from a sandbox to a system with real consequences.
The original agent assumed the LLM was right. If the LLM extracted “ORD-0O1” (a letter O instead of zero), the tool would error, the agent would probably recover gracefully, and the customer might get a slightly confusing response. Probably fine.
The enterprise agent assumes the LLM will sometimes be wrong, and builds a recovery path before that wrongness reaches anything external. The gate catches “ORD-0O1” immediately, produces a specific error message that names exactly what was wrong and why, and the correction node feeds that exact message back to the LLM. The LLM gets a second chance with a precise instruction. If it fails again, a human takes over. No tool was called with bad data. No external system saw the hallucination.
The validation_errors field in state means that when a senior engineer reviews a session that produced a wrong answer, they have a complete log of every gate failure, every correction attempt, and every retry count. They can reproduce the failure, understand what went wrong, and either fix the prompt or tighten the gate. Without that log, debugging a probabilistic system is guesswork.
The three-file structure means a compliance auditor asking “what validates a refund before money moves?” gets shown gates.py. One file. Pure Python. No agent architecture to explain. Just clear, auditable business rules in a language any developer can read.
The Keyword Summary
Everything new in this enterprise version, in one place:
Business Logic Gate — a pure Python function that takes extracted data and returns (True, cleaned_data) or (False, error_reason). Lives in its own file with no LangGraph imports. Runs inside a node before any tool call.
with_structured_output(PydanticModel) — forces the LLM to return data matching a Pydantic schema instead of free-form text. Pydantic validates the schema before the gate even runs. The combination of structured output and a gate gives you two layers of validation.
extracted_data: dict in state — the field where structured LLM output lands before gates validate it. Tools read from here, not directly from the LLM’s raw output.
validation_errors: Annotated[list[str], operator.add] — the audit trail. Every gate failure appends to this list. It accumulates across the whole conversation, not just one turn.
retry_count: int in state — the infinite loop prevention. The correction node increments it. The gate routing function checks it. If it exceeds the maximum, escalate rather than retry.
correction_node — the loop recovery node. Reads the most recent validation error, builds a specific correction instruction, re-invokes the LLM with structured output, and routes back to the gate. Shared across all three specialist agents.
gate_status: str — the communication channel between gate nodes and routing functions. Values: “pending”, “passed”, “failed”, “escalated”, “aborted”. Routing functions read this instead of parsing LLM output directly.
supervisor_node — reads conversation state, returns a specialist name. Never calls tools, never acts. Routes only.
Compiled subgraph as a node — graph_builder.add_node(“name”, compiled_subgraph). The parent graph sees a black box. The subgraph handles its own internal routing, gate logic, and tool calls without the parent knowing the details.
Conclusion: The Gap Is Closed
Read Murat’s comment again. The challenge isn’t the initial graph layout. It’s deterministic error handling and state validation at scale. You cannot afford probabilistic failures. The orchestration layer must be independent of any single LLM vendor.
Every one of those points is addressed in the code above. The gates are deterministic. The validation loop handles failures without crashing. The audit trail makes every decision inspectable. And the orchestration layer — the gates, the routing functions, the supervisor logic, the correction node — contains not a single LLM-vendor-specific import. Swap ChatOpenAI for ChatAnthropic or any other init_chat_model provider in the configuration, and every gate, every routing function, every business rule runs identically. The LLM is a pluggable module. The architecture is not.
The original ShopBot was the map. This is the territory.
Next in the series: Let’s find out in the comments.
Improving Our LangGraph Agent for Real-World E-Commerce: Enterprise Validation, Business Logic… was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.