479 Blog Posts To Learn About Large Language Models
Let’s learn about Large Language Models via these 479 free blog posts. They are ordered by HackerNoon reader engagement data. Visit the Learn Repo or LearnRepo.com to find the most read blog posts about any technology.
Large language models (LLMs) are AI models trained on vast text datasets to understand, generate, and translate human-like text, enabling sophisticated natural language applications. They are critical for advancements in AI assistants, content creation, and intelligent automation.
1. Why Is GPT Better Than BERT? A Detailed Review of Transformer Architectures

Details of Transformer Architectures Illustrated by BERT and GPT Model
2. Open-Source: The Next Step in AI Revolution

Explore the open-source revolution in AI development, distinguishing between genuine innovation and ‘open-washing’ attempts by Big Tech.
3. Decoding Transformers’ Superiority over RNNs in NLP Tasks
![]()
Explore the intriguing journey from Recurrent Neural Networks (RNNs) to Transformers in the world of Natural Language Processing in our latest piece: ‘The Trans
4. What are the Best Free AI Art Generators of 2023?

Generative AI has made groundbreaking strides in the past few months, and Generative AI models have risen in general popularity.
5. How to Use Ollama: Hands-On With Local LLMs and Building a Chatbot

In the space of local LLMs, I first ran into LMStudio. While the app itself is easy to use, I liked the simplicity and maneuverability that Ollama provides.
6. A Practical 5-Step Guide to Do Semantic Search on Your Private Data With the Help of LLMs
In this practical guide, I will show you 5 simple steps to implement semantic search with help of LangChain, vector databases, and large language models.
7. A Detailed Guide to Fine-Tuning for Specific Tasks
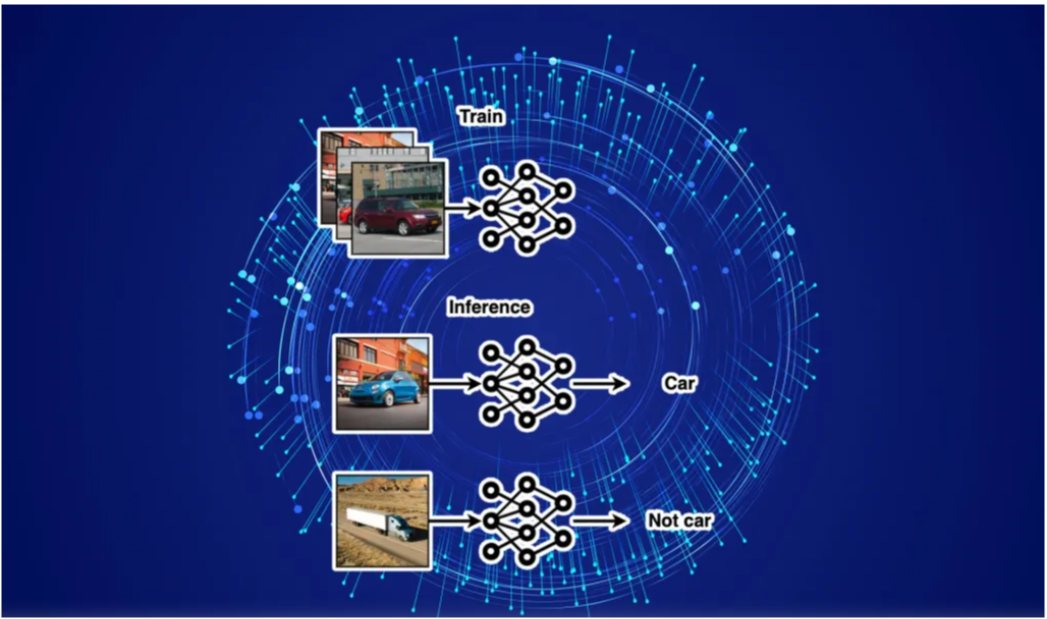
Large Language Models (LLMs) like GPT, BERT, and RoBERTa have reshaped industries, but their true potential lies in fine-tuning for specialized tasks.
8. Gptrim: Reduce Your GPT Prompt Size by 50% For Free!

Introducing gptrim, a free web app that will reduce the size of your prompts by 40%-60% while preserving most of the original information for GPT to process.
9. The Cheapskate’s Guide to Fine-Tuning LLaMA-2 and Running It on Your Laptop

Everyone is GPU-poor these days So my mission is to fine-tune a LLaMA-2 model with only one GPU and run on my laptop
10. The Challenges, Costs, and Considerations of Building or Fine-Tuning an LLM

The road to building or fine-tuning an LLM for your company can be a complex one. Your team needs a guide to start.
11. Hallucinations by Design: Part 4 – Fine-tuning Your Way Out of Vector Nightmares

Discover how to fine-tune embedding models to eliminate hallucinations in AI systems.Boost your RAG systems and semantic search with these proven techniques.
12. Analyzing the Pros, Cons, and Risks of LLMs

LLMs cannot think, understand or reason. This is the fundamental limitation of LLMs.
13. Make LLM for Text Summarisation Great Again

In recent months, LLMs have gained popularity and are now widely used in various applications. Data collection is essential for building these models, and crowd
14. The Next Era of AI: Inside the Breakthrough GPT-4 Model
GPT-4 represents a leap forward in large language model capabilities. It builds on the architecture and strengths of GPT-3 while achieving new levels of scale.
15. The Revolutionary Potential of 1-Bit Language Models (LLMs)

The Revolutionary Potential of 1-Bit Language Models
16. The Future of AI Writing Contest by Gadfly AI

Gadfly AI and HackerNoon are super excited to bring our AI community ‘The Future of AI Contest’ this August for Cyberscape Zine.
17. How to Make Any LLM More Accurate with Just a Few Lines of Code

A look at using the open-source Cleanlab package to automatically boost the accuracy of LLMs with a few lines of code.
18. How to Build a Web Page Summarization App With Next.js, OpenAI, LangChain, and Supabase

An app that can understand the context of any web page. We’ll show you how to create a handy web app that can summarize the content of any web page
19. Sentiment Analysis and AI: Everything You Need to Know in 2025

Discover how AI-powered sentiment analysis tools deliver accurate insights from customer reviews and feedback to help improve your business strategy.
20. Analyzing Common Vulnerabilities Introduced by Code-Generative AI

Auto-generated code cannot be blindly trusted, and still requires a security review to avoid introducing software vulnerabilities.
21. ChatSQL: Enabling ChatGPT to Generate SQL Queries from Plain Text

ChatGPT was released in June 2020 that it is developed by OpenAI. It has led to revolutionary developments in many areas. One of these areas is the creation of
22. A Look Into 5 Use Cases for Vector Search from Major Tech Companies

A deep dive into 5 early adopters of vector search- Pinterest, Spotify, eBay, Airbnb and Doordash- who have integrated AI into their applications.
23. How to Run Your Own Local LLM: Updated for 2024 – Version 2

An expansion on an article that’s doing really well – Not 7 but 15 open source tools in total to run local LLMs on your own machine!
24. AI Will Not Replace You, But The Person Using AI Will

“In a world where AI’s impact on jobs is undeniable, this insightful exploration unveils how AI serves as both a catalyst and a weapon, transforming industries
25. 🎬 Introducing MetaGPT: Unleashing the Power of AI Agents for Complex Tasks

Imagine having at your disposal an AI-powered assistant that not only comprehends your queries but can also seamlessly interact with various applications.
26. Hallucinations by Design – (Part 3): Trusting Vectors Without Testing Them

Embedding and LLM’s needs to be tested and evaluated or hallucinations will happen. Experimentation and evaluation on custom data is a must – openai and genai
27. Why the Book Publishing Industry Is Terrified of AI

AI isn’t all bad, but it could potentially destroy the publishing industry. Are publisher fears of AI justified or unwarranted?
28. No Coding Required: 5 Mind-Blowing Uses of GPT-4

What can actually be done using GPT-4?
29. AI Shouldn’t Have to Waste Time Reinventing ETL

This article describes the challenges of data movement for AI, the need for extraction and loading pipelines and the benefits of using existing solutions.
30. Dissecting the Research Behind BadGPT-4o, a Model That Removes Guardrails from GPT Models

Enter BadGPT-4o: a model that has had its safety measures neatly stripped away not through direct weight hacking (as with the open-weight “Badllama” approach).
31. AutoGPT — LangChain — Deep Lake — MetaGPT: Building the Ultimate LLM App

What is the future of the LLM technology? How do we convert today’s LLMs to automated agents acting like human beings? You can find the answer in this article!
32. PrivateGPT: ChatGPT but Private and Compliant

Privacy is a top concern when discussing ChatGPT-like tools with professionals.
33. Bard and ChatGPT — A Head To Head Comparison

Comparing both large language models side by side and also explaining which one is the better of the two.
34. GPT-LLM Trainer: Enabling Task-Specific LLM Training with a Single Sentence

Revolutionize AI model training with gpt-llm-trainer: Your ultimate shortcut to effortless, high-performing models. Say goodbye to complexities and hello to inn
35. 10 Tips to Take Your ChatGPT Prompts to the Next Level

Maximize your ChatGPT experience with 10 expert tips for crafting precise prompts and queries, enhancing interaction quality.
36. A Big Step for AI: 3D-LLM Unleashes Language Models into the 3D World
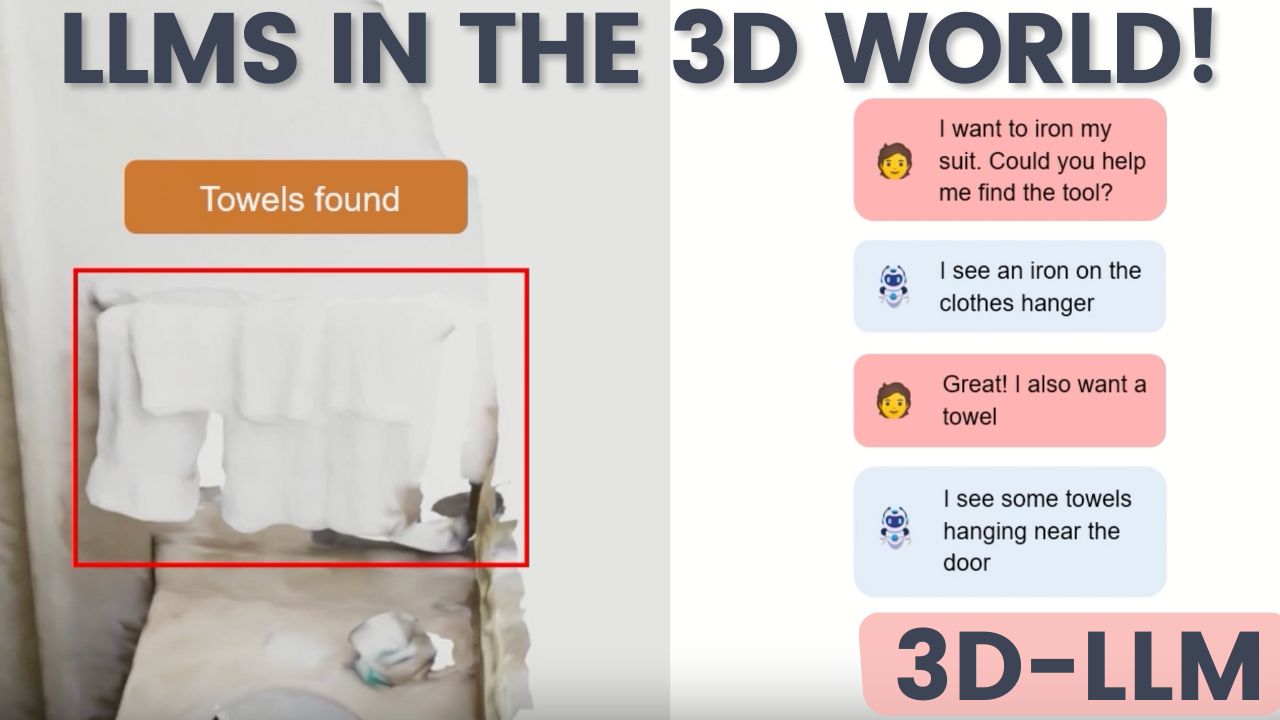
3D-LLM is a novel model that bridges the gap between language and the 3D realm we inhabit.
37. Evaluating TnT-LLM Text Classification: Human Agreement and Scalable LLM Metrics

We evaluate TnT-LLM’s text classification using human annotation agreement and scalable LLM-based metrics for accuracy and performance at scale.
38. I Was Ready to Return My DGX Spark. Then NVIDIA’s January Update Changed Everything.

I almost returned the $4,000 DGX Spark. Then NVIDIA dropped 30 playbooks, 2.5x performance gains, and hybrid routing.
39. Can AI Hallucinations Be Stopped? A Look at 3 Ways to Do So

An examination of three methods to stop LLMs from hallucinating: Retrieval-augmented generation (RAG), reasoning, and iterative querying.
40. TnT-LLM: Presenting Prompt Templates

In this section, we present the prompt templates that were used for conversation summarization, label assignment, and taxonomy generation, updation, and review.
41. AI for Knowledge Management: Iterating on RAG with the QE-RAG Architecture

We iterate on a popular LLM architecture to build a better AI knowledge management system.
42. Making LLMs Efficient: Reducing Memory Usage Without Breaking Quality

Optimal memory-quality tradeoffs for efficient language models.
43. Primer on Large Language Model (LLM) Inference Optimizations: 1. Background and Problem Formulation

Overview of Large Language Model (LLM) inference, its importance, challenges, and key problem formulation.
44. What Is LlamaIndex? A Comprehensive Exploration of LLM Orchestration Frameworks

In this post, we’ll explain how LlamaIndex can be used as a framework for data integration, data organization, and data retrieval for private data Gen AI needs.
45. The Current State of GPT4All

Today, GPT4All is focused on improving the accessibility of open source language models.
46. A Detailed Overview of How AI Detectors Work

Interested in finding out how AI detection works? Well, you are in for a treat. I’ll keep it as simple as possible so that anyone can understand.
47. Scaling Laws in Large Language Models

Explore scaling laws in AI, which reveal how model performance improves with larger models, more data, and compute power.
48. Embeddings for RAG – A Complete Overview

Embedding is a crucial and fundamental step towards building a Retrieval Augmented Generation(RAG) pipeline. BERT & SBERT are state-of-the-art embedding models.
49. Essential AI Tools for Developers in 2023: 20 Must-Try Solutions

In this article, we’ll see a few AI-powered tools that are set to revolutionize development and make the life of developers easy in 2023.
50. TnT-LLM: Automating Text Taxonomy Generation and Classification With Large Language Models

This paper presents TnT-LLM, a framework leveraging LLMs to automate large-scale text analysis, including automated label generation and efficient classifier tr
51. MCP Is Dead. The CLI Is Winning the AI Agent Stack

Why developers are ditching bloated agent protocols and turning to the CLI as the most practical foundation for building AI agents in 2026.
52. AI Won’t Replace Me Yet, But It Might Prove I Was Never That Original

AI won’t replace me yet. But it might prove I was never that original. A witty, unsettling look at formulaic writing in the age of large language models.
53. Beginner’s Roadmap to Large Language Models (LLMOps) in 2023: All free!

This guide isn’t just a compilation of LLM resources; it’s a curated journey through the most valuable skills in the industry.
54. Unlocking Powerful Use Cases: How Multi-Agent LLMs Revolutionize AI Systems

Delving into the integration of human-in-the-loop (HITL) approaches within multi-agent AI systems to unlock the full potential of LLMs.
55. A Tale of Two LLMs: Open Source vs the US Military’s LLM Trials

This article explores the security posture of open-source LLM projects and the US military’s trials of classified LLMs, prominent in the world of AI.
56. How to Converse With PDF Files Using Computer Vision and Opensource Language Models

Tutorial to build a chatbot with opensource language models.
57. The Limits of Coauthoring With ChatGPT

ChatGPT is a useful tool for exploring creative writing, but it also has its limitations. The algorithm has certain restrictions yet it is fun to use
58. Manners Matter? – The Impact of Politeness on Human-LLM Interaction

Exploring whether politeness impacts the results of human-LLM interactions.
59. Experts Remain Divided on ChatGPT’s Effectiveness Despite Claims of Readiness for Mass Adoption
This text discusses the hype around ChatGPT, a language model developed by OpenAI, and argues that despite its ability to generate human-like text, it’s limited
60. The Transformer Neural Network (TNN) is Much, Much Bigger Than Even AGI

We’ve just realized how LLMs work internally – a legible, scientific hypothesis. But that has huge implications for the AI industry and indeed for the world!
61. Developer Advocate at OpenAI Explains How to Best Use GPT and ChatGPT

Logan Kilpatrick is working at OpenAI in developer relations. He shares his insights on large language models, ChatGPT, and the developer landscape with OpenAI.
62. Engineering a Trillion-Parameter Architecture on Consumer Hardware

A deep dive into how one researcher trained a Trillion-Parameter-Scale AI model on an RTX 4080 laptop, proving the democratization of of LLMs is possible.
63. How to Achieve 1000x LLM Speed for Efficient and Cost-Effective Training, Testing, and Deployment

Have you ever wondered how you could accelerate the training of LLMs? Well – worry no more – We present a simple but ingenious method to accelerate LLMOps.
64. 7 Essential AI Engineering Libraries to Replace Boilerplate
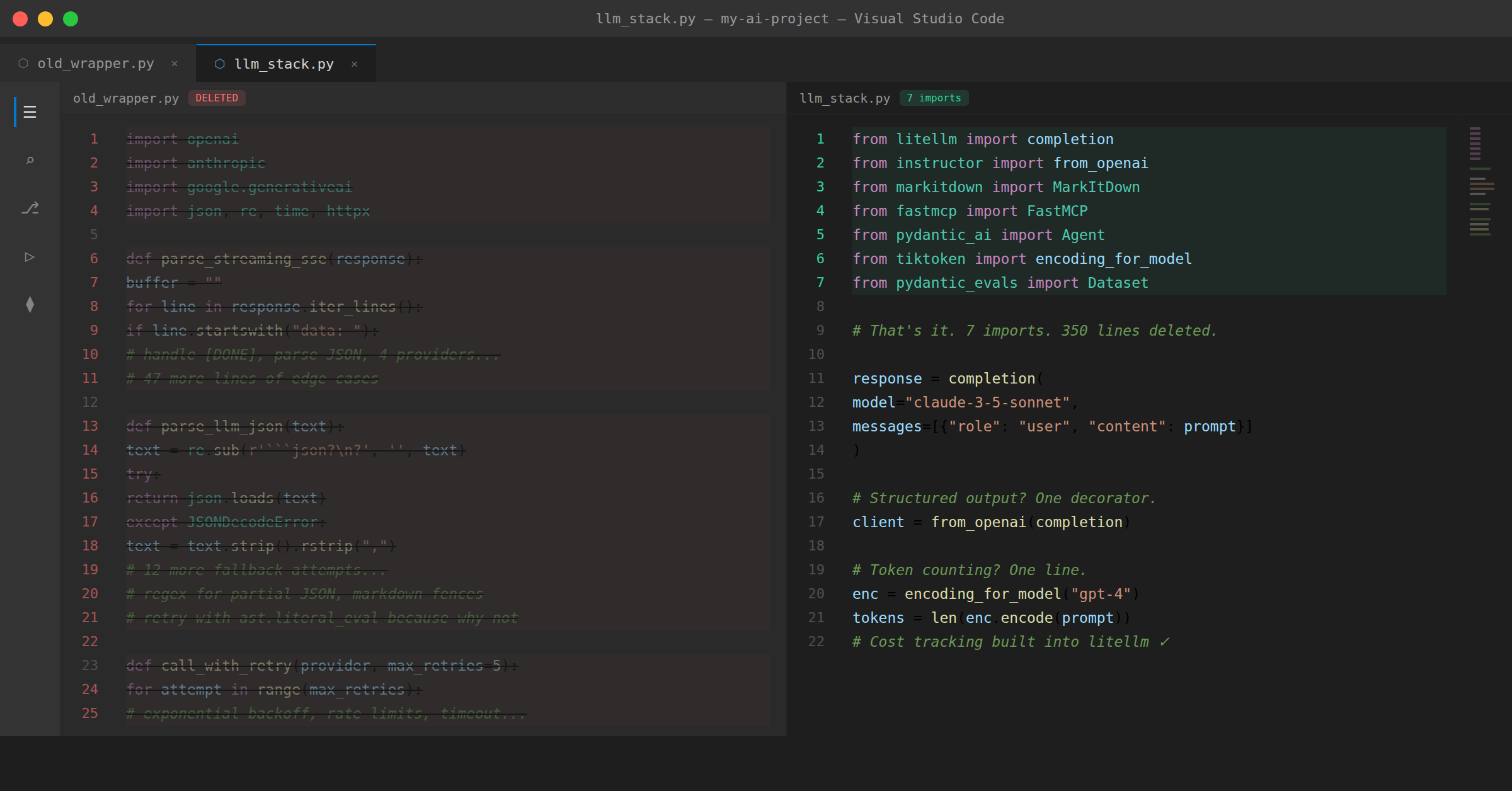
Replace custom LLM wrappers with 7 production-tested Python libraries. Covers LiteLLM, Instructor, FastMCP, PydanticAI, tiktoken, and more with code examples.
65. AIs Will Be Dangerous Because Unbounded Optimizing Power Leads to Existential Risk

Serious concerns from the experts about future, powerful AI. Information that is not covered in general media.
66. Mamba Architecture: What Is It and Can It Beat Transformers?

Explore Mamba, an innovative architecture surpassing Transformers in efficiency for long sequences, promising advancements in AI with its flexible design.
67. Amazon Falcon Lite vs OpenAI ChatGPT – The Large Language Model Battle

Comparing Amazon Falcon Lite and OpenAI ChatGPT: A Comprehensive Review of Large Language Models
68. From Crappy Autocomplete to ChatGPT: The Evolution of Language Models
An easy explanation of how self-attention works and a brief look at the evolution of large language models.
69. AI Says My Schtick is Bigger Than Yours!
Are AI top lists and AI recommendations better than search results? how can you track them?
70. Langchain: Explained and Getting Started

Langchain is a crucial component for developing LLM models. It helps in orchestration and act as building block
71. ChatGPT Vs. ChatGPT: How to Detect Text Generated Using the AI Language Model

ChatGPT can help you assess if a text has been written by an LLM.
72. Five Questions About AI Bias You Probably Wanted to Ask
5 main questions from a panel discussion on bias in AI. Panelists offer insights into the sources of bias, the responsibility of developers and Ai’s future.
73. The EU AI Act: Implications for SEO on LLMs

This article untangles the tech jargon and charts a simple course for understanding the implications of EU’s regulation for SEO on LLMs.
74. Should Conversational AI Rely on Large Language Models?

Large language models (LLMs) are conversational AI chatbots taking the world by storm.
75. LLMs Are Transforming AI Apps: Here’s How

Building apps with unreal levels of personalized context has become a reality for anyone who has the right database, a few lines of code, and an LLM like GPT-4.
76. BYOK (BringYourOwnKey) in Generative AI is a Double-edged Sword

Do you know what Bring Your Own Key (BYOK) in generative AI is? Read on and learn more about this new AI concept.
77. Security Threats to High Impact Open Source Large Language Models

The rapid growth of Open-source LLM projects often exhibit an immature security posture, which necessitates the adoption of enhanced security standards.
78. AI Memory Systems: The Approaches You Need to Know

created my own open source system, called Elroy, and have been interacting with it for about 3 years. It helps me brainstorm and much more.
79. On AI Winters and What it Means for the Future

The full history of AI winters is reviewed in great detail. The comprehensive coverage that we didn’t find anywhere else.
80. Could China’s DeepSeek Shatter the ‘More GPUs, More Power’ Theory?

It’s early 2025, and we may already be witnessing a redefining moment for AI as we’ve come to know it in the last couple of years.
81. Meta Strikes Back: Introducing LLaMA

Meta introduces LLaMA, a 65B parameter model to compete with ChatGPT, while OpenAI plans for AGI, creating a race for advanced language models.
82. How I Cut Agentic Workflow Latency by 3-5x Without Increasing Model Costs

Learn how to speed up and optimize agentic workflows with smart step-cutting, parallelization, caching, and model right-sizing.
83. Primer on Large Language Model (LLM) Inference Optimizations: 2. Introduction to Artificial Intelligence (AI) Accelerators

This post explores AI accelerators and their impact on deploying Large Language Models (LLMs) at scale.
84. The Story of a Brain: AI Anxiety and the Illusion of the Mind

Are LLMs conscious, or just complex calculators? How a forgotten 1981 sci-fi thought experiment accidentally predicted the modern AI existential crisis.
85. Behind the Scenes of Large Language Models: A Conversation with Jay Alammar

In this 16th episode of “The What’s AI Podcast,” I had the privilege of speaking with Jay Alammar, a prominent AI educator, and blogger.
86. Large Language Models: A Beginner’s Journey—Part 1

Explore the world of Large Language Models (LLMs) in our comprehensive guide. From understanding their capabilities to overcoming limitations, discover how LLMs
87. How to Drive Personalized Retail Offers with Vector Search

Learn how vector search to drive results with customer promotions at a big-box retailer.
88. Will ChatGPT Incriminate Itself? Reporters Weigh In, and ChatGPT Defends Itself
![]()
Will ChatGPT incriminate itself when it comes to questions of copyright compliance and its training data? Is what ChatGPT generates new or merely derivative?
89. How to Build a Basic Recommendation Engine without Machine Learning

Explore the intricacies of building a recommendation engine without relying on machine learning models.
90. Here’s Why AI Can’t Replace You

Why AI can’t replace people: insights from real projects showing how data quality, curation, and human expertise still make the difference.
91. Navigating the Ethical Landscape of LLMs

Explore the ethical challenges surrounding the use and development of Large language models.
92. Is ChatGPT Sentient?

While Chat GPT can create pieces of text that sound competent in many fields, its field of know-how only goes as far as its training data set.
93. TnT-LLM: LLMs for Automated Text Taxonomy and Classification

This paper presents TnT-LLM, a framework leveraging LLMs to automate large-scale text analysis, including label generation and efficient classifier training.
94. The GPT-5 Prompt Gap: The Hidden Reason Your AI Outputs Suck

Boost GPT-5 results with 15,000 expert prompts that turn bland AI outputs into high-impact content for entrepreneurs, marketers, and creators.
95. How Large Language Models Enhance Cybersecurity: From Threat Detection to Compliance Analysis

Explore the diverse applications of Large Language Models (LLMs) in cybersecurity.
96. How AI will Transform Product Management

Explore how AI is transforming product management roles, from rapid prototyping to user feedback analysis, empowering PMs to innovate and stay competitive.
97. TnT-LLM: Text Mining at Scale With Large Language Models

Transforming unstructured text into structured and meaningful forms is a fundamental step in text mining for downstream analysis and application.
98. Best Practices for Integrating LLMs with Malware Analysis Tools
LLMs can complement deobfuscators in threat pipelines, filling gaps, summarizing code, and mapping MITRE ATT&CK, but must minimize hallucinations.
99. From Black Box to Transparent: How to Read the Inner Logic of LLMs

Explore how LLMs work from the inside: from token‑prediction fundamentals to Transformer architecture, training stages and reasoning chains. Learn how to prompt
100. Evaluating TnT-LLM: Automatic, Human, and LLM-Based Assessment

Due to the unsupervised nature of the problem we study and the lack of a benchmark standard, performing quantitative evaluation on end-to-end taxonomy generatio
101. Prior Approaches to Text Mining: Taxonomy, Clustering, and LLM Annotation

An overview of related research in text taxonomy generation, text clustering, and the use of LLMs for automated text annotation.
102. The Transformative Influence of AI: 6 Revolutionary Breakthroughs

Explore the Impact of AI in Industries: AI’s Impact on Business, Customer Experience, Healthcare, Finance, Transportation & More!
103. Dear AI: We Still Don’t Trust You

In recent months, millions of people seem to be increasingly enthused by AI and chatbots. There’s a particular story that caught my eye…
104. How to reframe product packaging with AI for growth hacking

Product packaging influences 72% of Americans in purchasing decisions alongside a sustainable packaging market expanding at a CAGR of 8.5% during 2023-2031.
105. Our Proposed Framework: Using LLMs for Thematic Analysis

The framework relies on OpenAI’s GPT-4 model’s capabilities to perform complex NLP tasks in zero-shot settings
106. Should You Risk Using an AI Browser?

AI seems to be the next step for web browsers — but security risks and hallucinations are real concerns. Here are the pros and cons of AI browsers.
107. Using the Power of AI for Tailored and Personalized Experiences

Learn how AI helps create personalized experiences in various services.
108. LLM & RAG: A Valentine’s Day Love Story

Love is in the air, and so are the perfect AI partners: LLMs and RAG!
109. The Future of Malware Analysis: LLMs and Automated Deobfuscation

LLMs show strong potential for automating malware deobfuscation, efficiently analyzing real Emotet scripts and enhancing future threat intelligence pipelines
110. AI Knows Best—But Only If You Agree With It

AI’s efficiency may unintentionally narrow human knowledge, leading to “knowledge collapse.” Learn how this shift affects innovation and cultural diversity.
111. Yoshua Bengio Weighs in on the Pause and Building a World Model

This week I talked to Yoshua Bengio, one of the founders of deep learning about augmenting large language models
112. How to Build Your First MCP Server using FastMCP

Learn how to build your first MCP server using FastMCP and connect it to a large language model to perform real-world tasks through code.
113. An Intro to MedPaLM: ChatGPT’s Healthcare-Focused “Cousin”

ChatGPT for healthcare? Learn everything you need to know about MedPaLM, a new LLM developed by Google specifically for medical and clinical applications.
114. Reflecting on AI in 2023: Magic, Hope, Innovation and Disruption

Discover the transformative force of Artificial Intelligence. Explore the latest trends from NL to deep learning that are shaping the future of AI.
115. ChatGPT Translator VS Mine: Which One Is Better?

Does ChatGPT Translator really so good as mentioned in many posts ?
116. Retrieval-Augmented Generation: AI Hallucinations Be Gone!

Retrieval Augmented Generation (RAG), shows promise in efficiently increasing the knowledge of LLMs and reducing the impact of AI hallucinations.
117. The Model Context Protocol (MCP): The New Standard for Secure AI Interoperability
MCP is the crucial “middleware protocol” that sits between a large language model and the entire enterprise environment.
118. Democratizing Access to AI Has Become More Important Than Ever

As AI’s influence grows, so do the disparities in who has access to its transformative potential.
119. Here Are 10 Prompt Engineering Techniques to Transform Your Approach to AI

Discover 10 advanced prompt engineering techniques: recursive expansion, token optimization, DRY principle, persona emulation for superior AI outputs.
120. Chat Is a Terrible Interface for Agents—and 2026 Will Prove It

Building AI Agents? I tried Angular, HTMX & Python. They failed. Discover why A2UI is the declarative protocol to replace basic chatbots.
121. OpenAI Makes it Easier to Build Your Own AI Agents With API

You can create sophisticated AI assistants that seamlessly handle everything from reversing strings to querying internal databases.
122. AI Makes Tech Less Terrifying For “Word People”

Discover how AI is reshaping the world for writers and creatives. Dive into how Natural Language Interfaces are making tech more accessible.
123. How I Got Llama 3 to Revere God!

Ever wondered what an AI would think about God? Now you can know. Read this article to find out!
124. Automatic Brand Sentiment Analysis with Generative AI

Learn how to monitor your brand on social media like Reddit, Twitter, Linkedin, Hacker News… and automatically analyze the sentiment thanks to generative AI.
125. The Game AI Problem Computers Were Never Built to Solve

An explainer on why brute-force AI fails at grand strategy games, and how hybrid LLM architectures enable long-horizon strategic reasoning.
126. GPT4All: An Ecosystem of Open-Source Compressed Language Models

In this paper, we tell the story of GPT4All, a popular open source repository that aims to democratize access to LLMs.
127. AI Is Playing Favorite With Numbers

LLMs are as smart—and as biased—as the humans who trained them. Although AI can’t think for itself, we’re just beginning to explore the depths of LLM psychology
128. From Backlinks to Data Depth: How LLMs Are Rewriting Content Authority

Large Language Models (LLMs) are replacing Google-era content authority. LLMs are designed to find content that explains, defines, compares, or solves.
129. Streamlining LLM Implementation: How to Enhance Specific Business Solutions with RAG

Learn how to enhance your LLMs with retrieval-augmented generation, using LlamaIndex and LangChain for data context, deploying your application to Heroku.
130. Simplifying Vector Search: Part 1

Every wonder how Spotify or any number of dating sites figure out what or who you like? They use vector based searching. This is vector search simplified.
131. The Em Dash Rorschach Test

Is your em dash usage a tell for AI authorship? How this humble punctuation mark became a cultural flashpoint in the age of large language models.
132. GPTerm: Creating Intelligent Terminal Apps with ChatGPT and LLM Models

In this article, the exciting realm of making terminal applications smarter is delved into by integrating ChatGPT, a cutting-edge language model.
133. The Pros and Cons of LLMs in Cybersecurity Practice

LLMs boost cybersecurity by automating threat detection, analysis, and compliance, but can also be misused for attacks and malware development.
134. How to Start a Career as a Junior Developer in 2026
The “Junior Developer” role is collapsing (down 46%), but a new path is emerging.

135. LLMs Excel in NLP: Enabling Sophisticated Search Functionalities in E-commerce Platforms

Provide exceptional shopping experiences, businesses must leverage the power of LLMs as the e-commerce industry continues to evolve.
136. Their Margin is AI’s Opportunity

Could a “ChatCEO” reduce costs and improve business?
137. LLM-Augmented Text Classification: Distilling GPT-4 Labels into Efficient Classifiers

We explore using GPT-4 for large-scale text annotation and train lightweight classifiers on these labels, comparing their accuracy and efficiency
138. How AI and Social Media Shape Knowledge Through Echo Chambers and Filter Bubbles

AI and social media algorithms shape knowledge by reinforcing biases and limiting exposure to diverse ideas, leading to echo chambers and knowledge distortion.
139. Do y’AI mind?

large language models raise questions around the nature of minds, old philosophical question, solipsism or one mind, hard to answer
140. AI Framework has You Covered on Image-to-Text Workflows

Learn how to use AnyModal, a modular framework for integrating vision and language models, to build and train your own LaTeX OCR system. Perfect for AI research
141. With New AI Model, Meta Hopes Imperfect Hands Will be a Thing of the Past

Meta is heating up the AI arms race with the launch of a new artificial intelligence model that can help users analyze and complete unfinished images.
142. From Zero to AI-Ready: How I Taught Myself Machine Learning (And What I would Tell You Now)

You don’t need a PhD to learn AI, just structure, curiosity, and small steps that make sense. Here’s how I learned machine learning from scratch.
143. Policy-Driven AI: Designing Configuration-Driven Model Selection for Enterprise Systems

Hardcoding AI model calls is the new technical debt. This article walks through how to architect a configuration-driven model selection layer
144. When To Use Small Language Models Over Large Language Models

Wondering where to start using small language models? Find top use cases where small language models would be better than large language models.
145. Why It’s Harder: The Unique Hurdles For Non-Experts Using AI Coding Tools

AI coding tools could be a game-changer for non-expert end-users. Exploring the unique challenges that arise when applying LLMs to programming
146. On Grok and the Weight of Design

Grok’s recent output issues reveal deeper structural problems in model alignment.
147. Additional Results: Cross-Lingual Taxonomy Evaluation and In-Depth Classification Analysis
Explore further results on cross-lingual taxonomy performance, detailed annotation agreement analysis, and comprehensive classification metrics for TnT-LLM.
148. Model Performance and Pitfalls in Automated Malware Deobfuscation

Testing four LLMs on Emotet scripts, GPT-4 led in deobfuscation, but all models struggled with hallucinations and prompt limitations.
149. TnT-LLM: High-Quality Automated Text Mining and Efficient LLM-Augmented Classification

Summary of TnT-LLM findings: automated taxonomy generation outperforms clustering, LLMs are effective evaluators (with caveats), and more
150. Sparse Activation in MoE Models: Extending ReLUfication to Mixture-of-Experts

Discover how this discovery enables massive FLOP reductions through MoE ReLUfication.
151. TnT-LLM Generated Taxonomies: User Intent and Conversation Domain Labels

View the user intent and conversation domain taxonomies automatically generated by TnT-LLM and refined by human calibration for text classification.
152. The Soft Bigotry of AI Doom: Because Users Are Just Too Incompetent

A satirical takedown of AI doom narratives: critical thinking won’t vanish, institutions won’t auto-collapse, and “doom” assumes users are incompetent.
153. AI Detectives and the Case of the Disguised Droppers

Using 2,000 real Emotet dropper scripts, the experiment tests LLMs’ ability to deobfuscate malware and extract threat intel at scale.
154. Agents 101 — Build and Deploy AI Agents to Production using LangChain
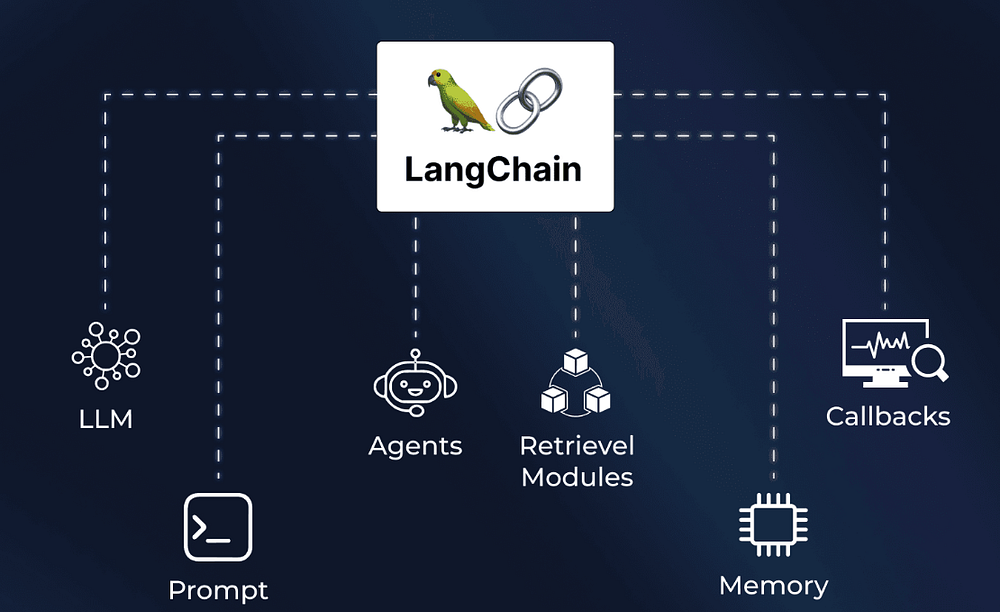
Learn how Langchain turns a simple prompt into a fully functional AI agent that can think, act and remember.
155. TnT-LLM: Democratizing Text Mining with Automated Taxonomy and Scalable Classification

TnT-LLM automates text mining, enabling efficient taxonomy generation, LLM-augmented classification, and democratized access to text insights
156. Beyond ReconVLA: Annotation-Free Visual Grounding via Language-Attention Masked Reconstruction
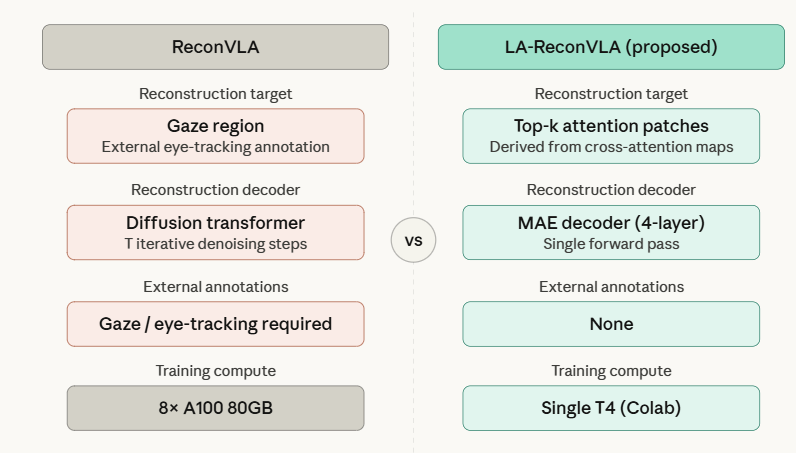
A new approach replaces gaze annotations with language-driven attention masking, improving robot perception while reducing training overhead.
157. Stop Drowning in AI Models: A 3-Pillar Framework for Evaluation
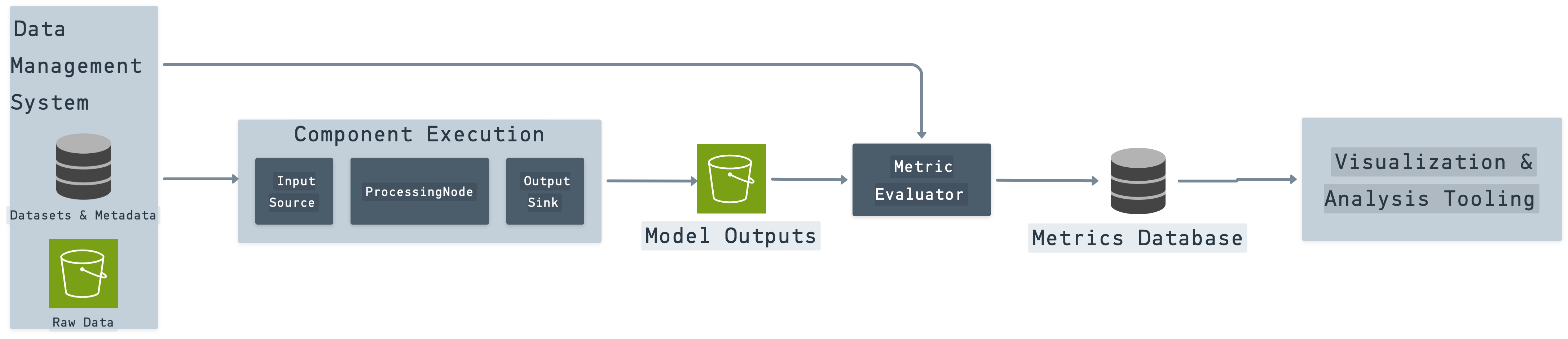
A practical 3-pillar framework for evaluating computer vision models in production.
158. The Future Job Market Amid Automation and Large Language Models

🕵️♀️👷Your job isn’t getting automated by ChatGPT 🤖, well not only that – this is a poke under the hood of the real issues that have led us to today.
159. A Quick Guide To LLM Code Generation Technology And Its Limits

This overview provides a fast-track guide to the technology behind LLMs for code generation, covering the Transformer architecture
160. Beyond The Final Answer: Why Non-Experts Can’t Spot Bad AI Code

Explore the critical problem of verifying AI-generated code for non-expert programmers. Discover why they rely on ‘eyeballing’ the final output
161. 100 Complex LLM Terminology Explained in One Single & One Simple Sentence

Every single technical term about Large Language Models and Generative AI explained first concisely, then again, simply, to reinforce your understanding.
162. TnT-LLM Implementation Details: Pipeline Design, Robustness, and Efficiency

Explore the technical implementation of TnT-LLM, including pipeline design, techniques for ensuring robustness, and model selection strategies
163. Five Architectural Patterns That Fix What’s Broken in RAG

Semantic RAG assumes the query embedding lands near the answer embedding.
164. Data Scraping: Do Large Language Models Cross Boundaries by Training on Content from Everyone
While scraping enabled models to get where they are, cleanly sourced data is going to become more and important
165. Researchers in UAE Create AI That Can Describe Images in Perfect Detail

Researchers at the Mohamed bin Zayed University developed an AI model that can create text-based conversations tied to specific objects or regions in an image.
166. The Topology of Meaning: Towards a “Unified Field Theory” for Artificial Intelligence

A bold argument that AI must move beyond language and tokens toward a unified topological model where words, faces, and sounds share the same meaning space.
167. Extracting Hidden Malware Payloads with AI-Powered LLMs

LLMs can automate extracting obfuscated malware payloads, streamlining threat intelligence even as attackers change packing and obfuscation tactics.
168. How to Use Large Language Models to Support Thematic Analysis in Empirical Legal Studies

We propose a novel framework facilitating effective collaboration of a legal expert with a large language model (LLM) for generating initial codes
169. Extracting User Needs With Chat-GPT for Dialogue Recommendation

Explore the integration of ChatGPT into interactive recommendation systems, where it serves as both a dialogue model and a recommendation engine.
170. Open Source LLMs: Evaluating and Building Applications on Open Source

How do you choose the most appropriate model for your application? An analysis on evaluating and building applications on open source large language models.
171. Building a Flexible Framework for Multimodal Data Input in Large Language Models

Discover AnyModal, the flexible framework that simplifies training multimodal large language models (LLMs). Integrate text, images, and audio seamlessly.
172. Why Static Analysis Struggles Against Modern Malware

Malware uses packers, cryptors, and obfuscators to evade static analysis, challenging analysts to adapt detection and analysis methods.
173. Sentience: AI, LLMs—Artificial Consciousness?
A key difference in the moments after death, from the last moments of life, is that the ability for the individual to know has closed.
174. The FrankenPHP Version Trap: Why Your Laravel Octane Stack Isn’t Using PHP 8.5
Debugging the version mismatch that Octane doesn’t tell you about.

175. Maximizing NLP Capabilities with Large Language Models

While NLP effectively facilitates machines to understand human language, the LLM capabilities have been greatly enhanced. Read this blog post to learn more.
176. The Ethics of Local LLMs: Responding to Zuckerberg’s “Open Source AI Manifesto”

This post explains the reason why Zuckerberg integrated Fediverse and open-sourced LLaMA, and it is not because of his virtue.
177. The UI: Why It’s the Real AI Agent Bottleneck

We need to stop treating the UI as an afterthought. It’s a critical component for unlocking the value of AI agents in the enterprise.
178. Towards Automatic Satellite Images Captions Generation Using LLMs: Abstract & Introduction
Researchers present ARSIC, a method for remote sensing image captioning using LLMs and APIs, improving accuracy and reducing human annotation needs.
179. Why Diffusion Models Fail B2B Hair Styling

Solving the $100B Hair Industry’s AI Problem. Learn how a two-stage “Architect-Builder” pipeline achieves 3D consistency in GenAI for B2B SaaS products.
180. The Capabilities of Large Language Models: Hacking or Helping?

Exploring the Capabilities of LLM Agents: A Study on Website Hacking
181. Thinking Like A Computer: The Missing Skill For Non-Experts Using AI

Exploring a critical challenge for end-user programmers: the lack of computational thinking. Discover how LLM-assisted tools need to be smarter
182. From Script to Summary: A Smarter Way to Condense Movies

A scalable AI summarization pipeline that extracts and condenses essential scenes from movie scripts with high accuracy.
183. Using Large Language Models to Support Thematic Analysis: Acknowledgment and What Comes Next?

We proposed a novel LLM-powered framework supporting thematic analysis, and evaluated its performance on an analysis of criminal courts’ opinions
184. The 7-Layer Blueprint for Serving, Securing, and Observing AI Agents at Scale

From PoC to Factory: Deconstructing the 7-layer architecture of a production-grade AI Agent Platform for enterprise scalability and control.
185. A Quick Guide to Quantization for LLMs

Quantization is a technique that reduces the precision of a model’s weights and activations.
186. A Summarize-then-Search Method for Long Video Question Answering: Conclusion

In this paper, researchers explore zero-shot video QA using GPT-3, outperforming supervised models, leveraging narrative summaries and visual matching.
187. What Is LoRA? The Low-Ranking Adaptation of LLMs Explained

To get Large Language Models to work within your budged both in terms of compute and memory, LoRA is a fundamental quantisation algorithm.
188. Can Anyone Code Now? Exploring AI Help for Non-Programmers

Come see how coding is changing with AI language models. Sharing real-world stories and studies showing just how different it is to program with these tools
189. The Case for CLI Tools Over MCP Servers in Agentic AI
I built 31 open-source Rust CLI tools for AI agents and measured 35x better token efficiency vs MCP servers. Here’s the stack, the design decisions, and why …

190. How to Create Realistic AI Conversations
Understand the plugin-based paradigm for customizable AI assistants and the role of GPT-4 in generating natural interactions.
191. Managing Your Online Reputation in the Age of AI

Online reputation management now not only includes the opinions of people, but also the opinions of AIs. Tracking your reputation in AI Answers is the new SEO!
192. Turns Out 30% of Your AI Model Is Just Wasted Space
AI models aren’t actually too big. New research shows nearly 30% of their size is wasted due to outdated storage assumptions.

193. Making Code Make Sense: The Challenge Of Comprehension In AI-Driven Programming

Exploring a major hurdle for AI-driven programming: code comprehension. Discover why generated code is hard to understand and how this affects accuracy
194. Should Machine Output Qualify for Free Speech Protections?

As generative AI systems produce increasingly sophisticated content, a complex question emerges: should their outputs qualify for free-speech protections?
195. The Sword of Words: the Evolution of Prompt Injection

Explore the 3-level evolution of prompt injection: from social engineering in Tensor Trust to BPE fragmentation and RAG-driven logic overrides in Web3 games.
196. Where Glitch Tokens Hide: Common Patterns in LLM Tokenizer Vocabularies

Untrained tokens often stem from unused byte tokens, merged fragments, and special tokens-patterns found across major LLMs regardless of architecture.
197. How to Build a Chatbot That Tells Medieval Tales Using Oracle’s AI Platform

The Oracle Cloud Infrastructure is one of the big cloud platforms currently available in the market together with AWS, Google Cloud, and Azure.
198. A Look At The Data: Blogs, Forums, And The Rise Of LLM Tools

This appendix contains a list of blog posts and Hacker News threads that were analyzed to understand the real-world experiences of developers using Copilot.
199. The Great Transformation: How LLMs Remake Every Programming Activity

This conclusion explores the profound transformation LLM assistance brings to the entire programming experience.
200. Towards Automatic Satellite Images Captions Generation Using LLMs: Methodology

Researchers present ARSIC, a method for remote sensing image captioning using LLMs and APIs, improving accuracy and reducing human annotation needs.
201. Incorporating NLP Capabilities Into an Existing Application Stack Is Easier Than Ever: Here’s Why

Speed development, create content and speed data-driven decisions with new ML tools that make it easy to incorporate NLP into your tech stack.
202. Navigation with Large Language Models: Implementation Details
In this paper we study how the “semantic guesswork” produced by language models can be utilized as a guiding heuristic for planning algorithms.
203. Instagram Is Overrun With AI-Generated Fetish Content, and Meta Doesn’t Seem to Care

A network of AI-generated influencers depicted with Down Syndrome are being monetized through adult content on platforms like Fanvue.
204. The Data Infrastructure Behind Every Successful AI Startup
95% of AI startups fail because their data breaks first. Here’s how real winners build solid data infrastructure using Bright Data to stay alive.
205. Excel vs. Python: How The Target Language Changes Everything For Non-Experts

Discussing why a tool might choose Python for its rich APIs, even if a user is more familiar with Excel formulas, and the challenges that creates.
206. Criticism of ‘AI-Sounding’ Writing Overlooks Deeper Cultural Biases

We should not let AI models take away parts of our language.
207. How AI Is Narrowing Our View of the World
Generative AI can reduce the diversity of knowledge, leading to knowledge collapse.
208. Psychedelics | LLMs: Is Mental Illness also a Disease of Myelinated Axons, Saltatory Conduction?
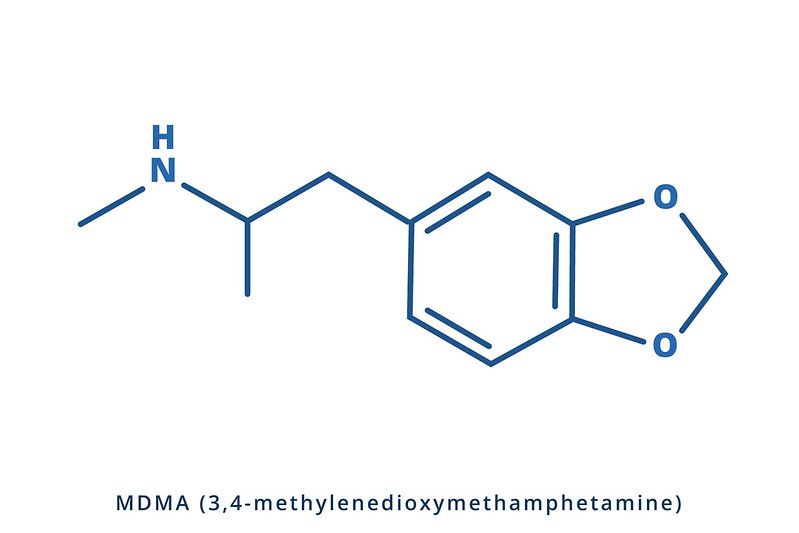
Uncover the link between psychedelics, LLMs, and mental illness.
209. The Uncanny Valley Of Code: Why AI-Generated Code Is So Hard To Debug

Developers are divided on whether AI-generated code is truly a time-saver. Exploring the trade-offs of faster code writing versus the time and effort needed
210. MIVPG: Multi-Instance Visual Prompt Generator for MLLMs

MIVPG enhances MLLMs by using Multi-Instance Learning to incorporate correlated visual data.
211. Can Large Language Models Develop Gambling Addiction?
Instead of vague fixes like “add safety guardrails to your prompts,” we have a mechanistic understanding that lets us design targeted interventions.

212. Holodeck Heroes: Building AI Companions for the Final Frontier

LLMs are data models trained on colossal amounts of text data, ingesting books, articles, code, and other forms of written content.
213. Large Language Models (LLMs) for Educational Applications

Explore the growing role of GPT models in education, detailing their use through prompting and fine-tuning for tasks like feedback generation
214. Nobody Is QA Testing Their LLM Apps (That’s Going to Be a Problem)

Most teams ship LLM and RAG applications with no real test suite — this is the six-layer testing framework that fixes that.
215. The Strength of Dynamic Encoding: RECKONING Outperforms Zero-Shot GPT-3.5 in Distractor Robustness

RECKONING’s performance significantly surpasses both zero-shot and few-shot GPT-3.5 prompting.
216. Rewarding the Rare: How Uniqueness-Aware RL Fixes Exploration Collapse

This is a Plain English Papers summary of a research paper called Rewarding the Rare: Uniqueness-Aware RL for Creative Problem Solving in LLMs [https://www.aimodels.fyi/papers/arxiv/rewarding-rare-uniqueness-aware-rl-creative-problem?utmsource=hackernoon&utmmedium=referral]. If you like these kinds of analysis, join AIModels.fyi [https://www.aimodels.fyi/?utmsource=hackernoon&utmmedium=referral] or follow us on Twitter [https://x.com/aimodelsfyi].
THE EXPLORATION COLLAPSE PROBLEM
When you train a language model with reinforcement learning to solve math problems, something counterintuitive happens. You reward correct answers. The model finds one reliable path to correctness and then, essentially, stops exploring. Every rollout becomes a slight variation on the same theme. Pass@1 looks great, you’re solving problems consistently. But pass@k stalls. If you sample a hundred times, you don’t get a hundred different solutions, you get a hundred versions of the same solution.
This is exploration collapse, and it reveals something broken about how we’ve been thinking about RL for language models. The standard approach assigns rewards at the token level, during generation. When a token contributes to a correct final answer, it gets reinforced. Over time, the policy learns the sequence of tokens that most reliably produces reward. Other valid paths exist, but they don’t have the same reinforcement history. They don’t accumulate confidence in the same way. So the policy narrows.
The tension is real. A model that finds one good strategy reliably is, from a pass@1 perspective, doing exactly what you asked. But from a practical standpoint, it’s wasted potential. If you’re willing to sample multiple times, a diverse model should give you more chances to find a correct answer. Instead, you get redundancy. This gap between what the metric measures and what the capability should provide is where the problem lives.
WHY WE MEASURE THE WRONG THING
The implicit assumption driving most RL work on language models is that better local rewards create better global diversity. Train each token to make good decisions, and the rollouts will naturally be diverse. This is intuitive. It’s also false.
What actually happens is that good local decisions reinforce themselves. A token choice that contributes to a correct answer gets positive signal. The next time the model needs to solve a similar problem, that token choice is slightly more likely. And the time after that, even more likely. The gradient is always pointing toward the same attractor. The policy doesn’t fail to explore, it explores efficiently right into a single basin.
The root cause isn’t randomness or insufficient training. It’s a fundamental mismatch between what we measure and what we want. We measure token-level behavior and hope for rollout-level diversity. These aren’t the same thing. Token diversity (different word choices) doesn’t guarantee strategy diversity (different approaches). A model can paraphrase the same method infinitely while exploring nothing new.
Understanding this mismatch is crucial because it means the fix can’t be marginal. You can’t schedule exploration differently or add entropy regularization and solve this. You need to change what’s actually being rewarded at the rollout level. You need to make rollout-level novelty an explicit part of the objective.
UNIQUENESS-AWARE REINFORCEMENT LEARNING
The core idea is straightforward: reward correct solutions that use rare strategies more than correct solutions that repeat common strategies. Make the policy internalize that finding a novel correct answer is more valuable than finding a redundant one.
The method operates in concrete steps. First, generate many rollouts for a single problem. Second, use a language model to cluster these rollouts by their high-level reasoning strategy. Not by their final numbers or notation, but by the logical approach underneath. One cluster for solutions that use substitution, another for solutions that use geometric reasoning, another for calculus-based approaches. Third, calculate cluster sizes. A strategy discovered by 2 out of 100 rollouts is rare. A strategy discovered by 50 out of 100 is common. Finally, reweight the reward signal inversely with cluster size.
The advantage function, which tells the policy how much better this rollout was compared to average, gets scaled down for solutions in large clusters and scaled up for solutions in small clusters. A correct solution using a rare strategy becomes worth significantly more reward than a correct solution using a dominant strategy.
This directly targets the incentive structure. Instead of hoping diversity emerges as a side effect of token-level training, the policy now has an explicit reason to explore: rare correct strategies are literally more rewarding. The objective shifts from “find any correct answer” to “find answers that use approaches you haven’t found yet.”
CLUSTERING STRATEGIES THE RIGHT WAY
There’s a practical problem lurking here. How do you define “high-level strategy”? Cluster too coarsely, and you lump genuinely different approaches together. Cluster too finely, and you treat superficial variations (using variable x versus y) as fundamentally different strategies. Cluster at the wrong granularity and the reward signal falls apart.
The paper uses a language model as the judge. Rather than hand-coding what counts as a distinct strategy, you ask an LLM to read two solutions and determine whether they use the same high-level approach. This is surprisingly effective. Language models are good at semantic equivalence. Two solutions using the same logical steps but different notation get recognized as similar. Two solutions using genuinely different approaches get recognized as different.
This sidesteps a major failure mode. Rigid clustering based on syntactic features would miss important distinctions or over-subdivide the space. Using an LLM judge provides flexibility while keeping the clustering semantic and interpretable. The granularity emerges naturally from what the model understands as a “different approach,” rather than being imposed by hand.
MEASURING WHAT MATTERS
The validation spans three domains: mathematics, physics, and medical reasoning. The metrics matter because they tell different stories.
Pass@1 measures single-shot performance. The model gets one try. This shouldn’t degrade, because nothing about uniqueness-aware RL should break basic competence.
Pass@k measures the probability that at least one correct answer appears in k samples. This is what should improve. If the policy becomes more diverse, sampling more times should yield more correct answers.
AUC@K is the area under the pass@k curve as you vary k across a sampling budget. This is the most stringent test. It asks whether the approach provides consistent, sustained gains as you sample more, not just a spike at some particular k value.
The expected pattern is that uniqueness-aware RL improves pass@k and AUC@K while maintaining or slightly improving pass@1. This happens because the method doesn’t change what “correct” means. It just makes correct solutions using rare strategies more rewarding. The policy becomes better at discovering multiple valid approaches while remaining competent on the first shot.
These results validate the core hypothesis: exploration collapse was a real structural problem, and addressing it at the rollout level works. The gains aren’t marginal tweaks to an already-working system. They’re evidence that the training objective shapes what kinds of solutions get discovered and reinforced, and changing that objective unlocks genuinely different behavior.
BROADER CONTEXT IN LANGUAGE MODEL TRAINING
This work connects to larger questions in how we train language models. There’s a growing body of research on how the structure of the reward signal shapes what models learn. Work on outcome-based exploration in LLM reasoning [https://aimodels.fyi/papers/arxiv/outcome-based-exploration-llm-reasoning?utmsource=hackernoon&utmmedium=referral] has shown that focusing on final correctness rather than process changes what strategies emerge. Similarly, research on how filtering affects exploration [https://aimodels.fyi/papers/arxiv/whatever-remains-must-be-true-filtering-drives?utmsource=hackernoon&utmmedium=referral] suggests that the data we select during training cascades into the policies we end up with.
The contribution here is precise and implementable. It’s not a claim that language models are “creative” in any deep sense. Rather, it shows that the training objective matters enormously for whether diverse solutions get discovered. If you reward only correctness, you get convergence. If you reward correct and rare, you get exploration. The difference is the granularity at which you assign the reward signal.
There’s also a connection to practical efficiency in exploration techniques for reinforcement learning with LLMs [https://aimodels.fyi/papers/arxiv/enhancing-efficiency-exploration-reinforcement-learning-llms?utmsource=hackernoon&utmmedium=referral]. Rather than adding randomness or entropy bonuses that might degrade performance, uniqueness-aware RL aligns exploration with actual utility. The model explores toward solutions that are both correct and different. It’s exploration that’s structurally incentivized, not imposed from outside.
The elegance of the approach lies in its simplicity. You don’t need new architectures or complex exploration schedules. You need one change: shift from rewarding token behavior to rewarding rollout-level novelty. That single shift addresses a real problem at its source, and the evidence suggests it works across diverse domains consistently.
Original post: Read on AIModels.fyi [https://www.aimodels.fyi/papers/arxiv/rewarding-rare-uniqueness-aware-rl-creative-problem?utmsource=hackernoon&utmmedium=referral]
217. Solving Coding Puzzles: The Evolution of Programmer Assistance Tools

From simplifying tasks with direct manipulation to generating code from examples, tracing how intelligent tools have always helped programmers
218. Let’s Hear From The Developers: What It’s Really Like To Code With AI

Join the debate. This section summarizes programmer reports on whether using Copilot is a new programming language or just a sign of bad tooling. We explore how
219. 102 Languages, One Model: The Multimodal AI Breakthrough You Need to Know

A multi-modal retrieval system using LLMs matches speech and text across 102 languages, outperforming prior methods with multilingual understanding.
220. Getting the Most out of a Large Language Model

LLM is a powerful tool when used efficiently using prompt engineering and inference parameter tuning
221. Few-shot In-Context Preference Learning Using Large Language Models: Full Prompts and ICPL Details
Full Prompts and ICPL Details for study Few-shot in-context preference learning with LLMs
222. Stop Guessing What Your LLM Is Doing—This Tool Shows You Everything

OpenLLM Monitor is an open source toolkit for monitoring, debugging, and optimizing Large Language Model (LLM) applications.
223. FreeEval: The Ethical Concerns

In this paper, we introduce FreeEval, a modular and extensible framework for trustworthy and efficient automatic evaluation of LLMs.
224. The AI Gardener: A New Role For Experts In A World Of Automated Code

Exploring the changing role of “gardeners” in a world where AI can answer most questions. Will their new role be to educate users on how to leverage AI tools?
225. ToolTalk: Benchmarking the Future of Tool-Using AI Assistants

Discover ToolTalk, a new benchmark designed to evaluate AI assistants like GPT-3.5 and GPT-4 on complex, multi-step tool usage with conversational interactions
226. Building LLMs with the Right Data Mix

Discover LLMs’ significance and how Bright Data saves time and money by providing comprehensive, compliant data for superior AI model training. Learn more now!
227. Large Language Models Being Used In Thematic Analysis: How It Works

There have been several studies exploring the use of LLMs in thematic analysis. De Paoli evaluated to what extent GPT-3.5 can carry out a full blown on
228. Alibaba’s Claude Killer Enters the Ring

Alibaba has officially released QVQ-Max, their first production version of a visual reasoning model.
229. GitHub Copilot Leads The Charge In Commercial LLM-Assisted Programming

This section provides a look at the commercial landscape of LLM-assisted programming, from the full-solution synthesis of GitHub Copilot
230. TnT-LLM for Automated Taxonomy Generation: Outperforming Clustering Baselines

We evaluate TnT-LLM for automated text taxonomy generation, comparing its accuracy and relevance against embedding-based clustering methods using human and LLM
231. Whisper Wars: Will AI Prompts Become the Secret Recipes of the Future?

As businesses recognize the value of optimized AI prompts, a new debate emerges: can prompts become trade secrets, and what does that mean for innovation?
232. Who’s Harry Potter? Approximate Unlearning in LLMs: Description of our technique

In this paper, researchers propose a novel technique for unlearning a subset of the training data from a LLM without having to retrain it from scratch.
233. The Benefits of Applying Constraints to LLM Outputs

Beyond the aforementioned use cases, our survey respondents reported a range of benefits that the ability of constraining LLM output could offer.
234. Advancing Conversational AI with Complex Tool Orchestration

Explore ToolTalk, a benchmark for evaluating tool-augmented LLMs in conversational AI settings.
235. Building a Production-Ready LLM Cost and Risk Optimization System

A deep dive into building a production-ready LLM cost and risk optimization system with token analytics, prompt risk detection, and real-time monitoring.
236. Speaking in Code: How AI Simulates Language Evolution on Regulated Social Media

How Large Language Models simulate language evolution under social media censorship, revealing adaptive communication strategies in regulated environments.
237. How to Deploy LLMs With MindsDB and OpenAI: An Essential Guide

In this article, you will learn how to deploy LLMs with MindsDB and OpenAI.
238. The Hidden Auditory Knowledge Inside Language Models
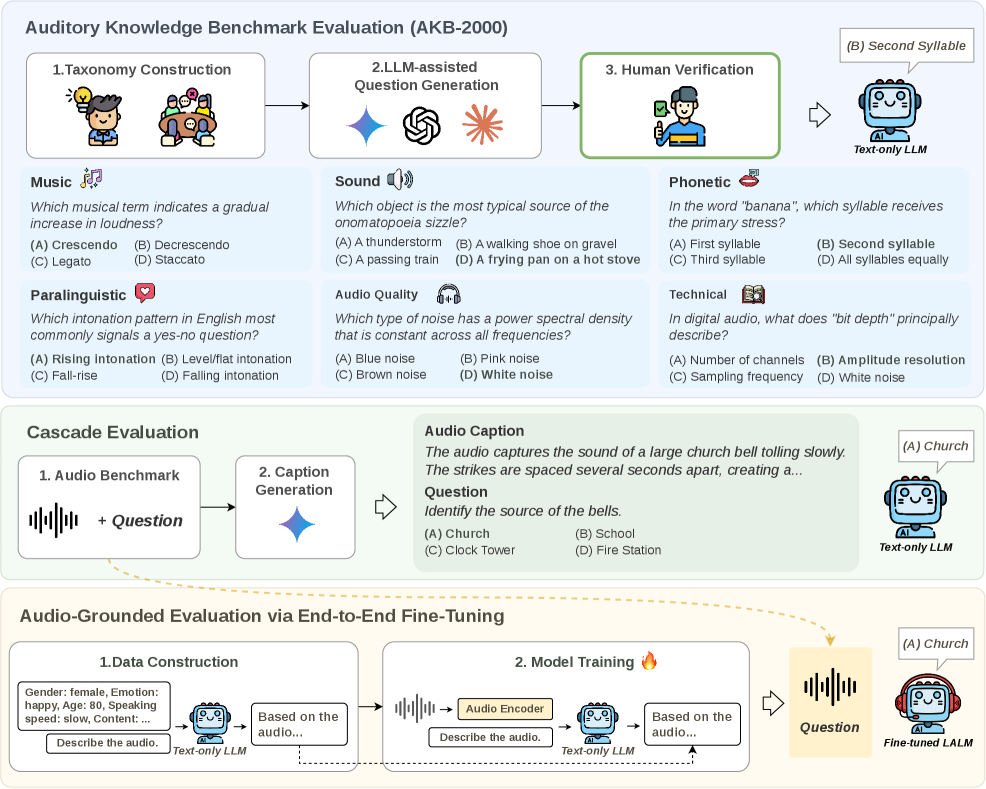
This is a Plain English Papers summary of a research paper called How Auditory Knowledge in LLM Backbones Shapes Audio Language Models: A Holistic Evaluation…
239. The Potential Impact of AI-driven Language Models on Search Ad Revenue

How will LLMs change the commercial Ad ecosystem?
240. New Method Could Unlock AI’s Power to See and Describe Images with Unmatched Detail

Researchers at the Mohamed bin Zayed University developed an AI model that can create text-based conversations tied to specific objects or regions in an image.
241. Navigation with Large Language Models: Abstract & Introduction
In this paper we study how the “semantic guesswork” produced by language models can be utilized as a guiding heuristic for planning algorithms.
242. Navigation with Large Language Models: LLM Heuristics for Goal-Directed Exploration
In this paper we study how the “semantic guesswork” produced by language models can be utilized as a guiding heuristic for planning algorithms.
243. Who’s Harry Potter? Approximate Unlearning in LLMs: Results

In this paper, researchers propose a novel technique for unlearning a subset of the training data from a LLM without having to retrain it from scratch.
244. Improving Multi-Step Reasoning in Large Language Models

By using a learned Q-value model to guide each step, Q improves LLM reasoning by increasing math and coding accuracy without requiring fine-tuning.
245. Few-shot In-Context Preference Learning Using Large Language Models: Environment Details

Discover the key environment details, task descriptions, and metrics for 9 tasks in IsaacGym, as outlined in this paper.
246. Building GPT-2 from Scratch in Rust – A Software Engineer’s Deep Dive into Transformers and Tensors
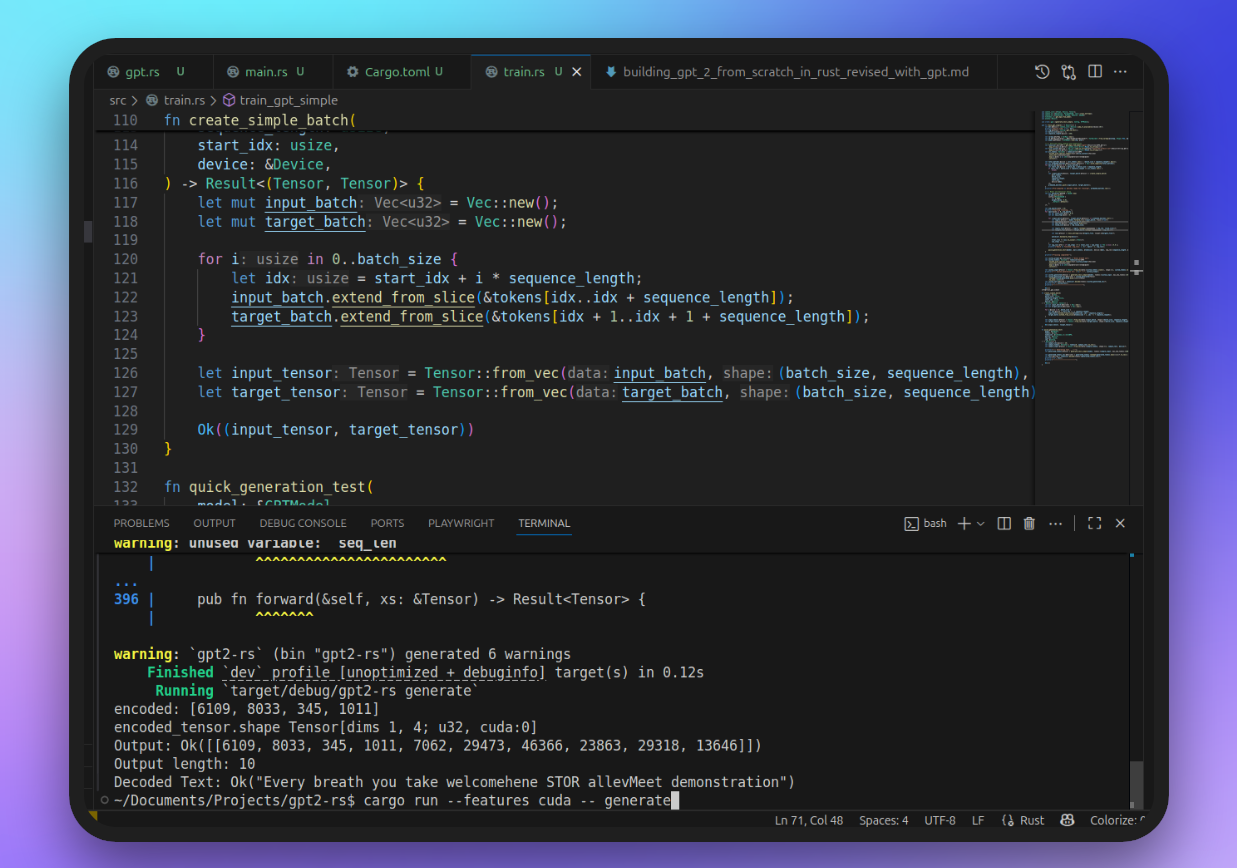
Learn how a software engineer built a working GPT-2 clone from scratch in Rust on Ubuntu. This deep dive covers embeddings, attention, residuals, training, and
247. How Many Examples Does AI Really Need? New Research Reveals Surprising Scaling Laws

Gemini 1.5 Pro shows log-linear gains up to ~1K examples (+38% accuracy). Batching reduces costs 45x and latency 35x with minimal performance loss.
248. NExT-GPT: Any-to-Any Multimodal LLM: Instruction Tuning

In this study, researchers present an end-to-end general-purpose any-to-any MM-LLM system called NExT-GPT.
249. OPT-175B is Comparable to GPT-3 While Requiring Only 1/7th the Carbon Footprint

OPT provides open access to GPT-3 scale language models, enabling responsible AI research with lower compute costs and reproducible experiments.
250. Evaluating Sentiment Analysis Performance: LLMs vs Classical ML

This story compares sentiment analysis performance of large language models (LLMs) to classical ML methods like SVM and decision trees
251. Your Smart Home Probably Isn’t As Reliable As You Think: Here Is Why

AI is entering our homes, but beneath the hype lie real architectural questions about reliability, edge computing, and what intelligence actually means
252. Secret Tokens, Secret Trouble: The Hidden Flaws Lurking in Big-Name AIs
Glitch tokens persist in closed and open models; aligning tokenizer and training data, plus targeted checks, are key to safer, more efficient LLMs.
253. Neurobiology: Like LLMs, the Brain Isn’t Predicting
When it is said that the brain generates predictions, how does that happen? Is it the neurobiology of brain, with tissue grooves, elevations or blood vessels?
254. What Makes a Scene Important? This AI Knows

Enhancing movie script summarization with scene saliency detection for better content selection and efficient storytelling.
255. Navigation with Large Language Models: Semantic Guesswork as a Heuristic for Planning: Prompts
In this paper we study how the “semantic guesswork” produced by language models can be utilized as a guiding heuristic for planning algorithms.
256. Where does In-context Translation Happen in Large Language Models: Further Analysis

In this study, researchers attempt to characterize the region where large language models transition from in-context learners to translation models.
257. ICPL Baseline Methods: Disagreement Sampling and PrefPPO for Reward Learning

Learn how disagreement sampling and PrefPPO optimize reward learning in reinforcement learning.
258. Building Chatbots from Scratch: Understanding and Harnessing Large Language Models (LLMs)

Imagine having a super smart friend who has read every book, article, and blog post on the internet.
259. New Anthropic Research Suggests AI Can Conceal Risk Internally

New Anthropic research suggests AI can hide risky internal states while producing calm, polished output, exposing a major gap in safety testing.
260. Comprehensive Detection of Untrained Tokens in Language Model Tokenizers

Presents new methods for detecting ‘glitch tokens’ in LLMs-untrained tokens that cause unwanted behavior-and tools for safer, more robust language models.
261. Where does In-context Translation Happen in Large Language Models: Where does In-context MT happen?

In this study, researchers attempt to characterize the region where large language models transition from in-context learners to translation models.
262. ToolTalk: Benchmarking Tool-Augmented LLMs in Conversational AI

Explore ToolTalk, a benchmark for evaluating tool-augmented LLMs in conversational AI settings.
263. Teaching AI to Say “I Don’t Know”: A Four-Step Guide to Contextual Data Imputation

CLAIM converts tabular data to natural language, then uses an LLM to generate contextual text descriptors for missing values to improve downstream tasks.
264. Can GPT Outsmart Social Media Regulations? Inside an AI Language Evolution Experiment

See how Large Language Models creatively adapt language strategies under supervision, effectively evading detection and communicating covert information.
265. Who’s Harry Potter? Approximate Unlearning in LLMs: Abstract and Introduction

In this paper, researchers propose a novel technique for unlearning a subset of the training data from a LLM without having to retrain it from scratch.
266. Google’s 540B AI Model Is Changing How Machines Think: Here’s Why It Matters

Google’s PaLM AI uses 540B parameters to achieve breakthrough reasoning, few-shot learning, and multilingual performance at unprecedented scale.
267. Recommendations by Concise User Profiles from Review Text: Abstract and Introduction

This work addresses the difficult and underexplored case of supporting users who have very sparse interactions but post informative review texts.
268. How AI Might Be Recycling—and Shrinking—Knowledge
Knowledge collapse occurs when information narrows over time, reducing diversity in thought and discovery.
269. Leveraging LLMs for Generation of Unusual Text Inputs in Mobile App Tests: Abstract and Introduction

Using InputBlaster, a novel approach in leveraging LLMs for automated generation of diverse text inputs in mobile app testing.
270. Hack Your Own RAG Stack in Under an Hour

Learn how to build a fast, offline semantic search API using PostgreSQL + pgvector, Transformers.js, and Fastify — perfect for RAG pipelines and AI apps.
271. The Science Behind Many-Shot Learning: Testing AI Across 10 Different Vision Domains

Evaluates GPT-4o vs Gemini 1.5 Pro on 10 vision datasets with many-shot ICL, using stratified sampling and standard accuracy/F1 metrics.
272. Cited Works: AI in Education, Natural Language Processing, and Tutoring Research

A list of academic references at the intersection of artificial intelligence in education and natural language processing techniques
273. DreamLLM: Additional Related Works to Look Out For

This breakthrough garnered a lot of attention and paved the way for further research and development in the field.
274. CulturaX: A High-Quality, Multilingual Dataset for LLMs – Abstract and Introduction

Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
275. Unified Speech and Language Models Can Be Vulnerable to Adversarial Attacks

Discover how adversarial attacks expose safety gaps in speech language models and how countermeasures can curb jailbreaking risks.
276. Leveraging LLMs for Generation of Unusual Text Inputs in Mobile App Tests: Experiment Design

Using InputBlaster, a novel approach in leveraging LLMs for automated generation of diverse text inputs in mobile app testing.
277. Scientists Just Found a Way to Skip AI Training Entirely. Here’s How

Many-shot ICL enables quick model adaptation without fine-tuning, improving accessibility. Future work: other tasks, open models, bias reduction.
278. Navigation with Large Language Models: LFG: Scoring Subgoals by Polling LLMs
In this paper we study how the “semantic guesswork” produced by language models can be utilized as a guiding heuristic for planning algorithms.
279. Empirical Validation of Multi-Token Prediction for LLMs

Explore extensive large-scale experiments demonstrating the efficacy of multi-token prediction in improving LLM performance across model sizes
280. Action vs Non-action Tools: Evaluating AI Assistant Correctness

Discover ToolTalk’s detailed evaluation methodology for assessing AI assistants’ accuracy in tool usage
281. The Grammar of Desire: What Our Prompts Really Say About Us

A speculative look at how AI prompts mirror our inner lives, turning wants and fears into data points in a growing meta-literature of human wish fulfillment.
282. The Dark Side Of AI: Reliability, Safety, And Security In Code Generation

This section argues that traditional benchmarks like HumanEval and MBPP are insufficient. We explore the nuanced challenges in evaluating AI-generated code
283. Understanding Related Research on Tool-Augmented Learning

Learn about related research on tool-augmented LLMs, comparative analysis, existing benchmarks, datasets, and task-oriented dialogue systems.
284. Approaches to Counterspeech Detection and Generation Using NLP Techniques

Counterspeech detection uses binary or multi-label classification; generation leverages LLMs like GPT-2, facing evaluation and deployment challenges.
285. Your Next Slang Phrase Might be Created by an AI

Explore how Large Language Models advance slang detection, simulate language evolution, and shape social interactions through innovative AI-driven methods.
286. Navigation with Large Language Models: Discussion and References
In this paper we study how the “semantic guesswork” produced by language models can be utilized as a guiding heuristic for planning algorithms.
287. Personalized Soups: LLM Alignment Via Parameter Merging – Conclusion & References

This paper introduces RLPHF, which aligns large language models with personalized human preferences via multi-objective RL and parameter merging.
288. Let’s Talk Usability: Unpacking The User Experience Of AI-Assisted Programming

Dive into research on how tools like Copilot truly impact developer productivity, revealing a nuanced picture on task time and acceptance rates
289. LLaMA: Open and Efficient Foundation Language Models

LLaMA offers 7B–65B parameter language models trained on public data, outperforming GPT-3 and enabling open, scalable AI research.
290. A Summarize-then-Search Method for Long Video Question Answerin Experiment Details

In this paper, researchers explore zero-shot video QA using GPT-3, outperforming supervised models, leveraging narrative summaries and visual matching.
291. Navigation with Large Language Models: Semantic Guesswork as a Heuristic for Planning: Related Work
In this paper we study how the “semantic guesswork” produced by language models can be utilized as a guiding heuristic for planning algorithms.
292. Training Time Comparison: Multi-Token vs. Next-Token Prediction

This table (S5) quantifies the training time overhead of multi-token prediction relative to next-token prediction
293. Customize ChatGPT for Coding: GPTutor Gives Developers Full Control in VS Code

GPTutor is a customizable, open-source AI coding tool for VS Code, helping devs fine-tune ChatGPT prompts for better code generation and support.
294. You Can Leverage Deep Research to Build Your Online Presence

Deep research is one of the aspects AI companies are willing to implement and integrate with their current AI systems. Use cases of deep research are massive..
295. GPTutor Lets Developers Fine-Tune AI Coding Help Inside VS Code

GPTutor is a customizable, open-source AI coding tool for VS Code, helping devs fine-tune ChatGPT prompts for better code generation and support.
296. Understanding Knowledge Collapse and Its Relation to Historical and Current Knowledge
Explore how AI, technology, and epistemic horizons contribute to knowledge collapse, affecting our access to historical and current knowledge.
297. Analyzing AI Assistant Performance: Lessons from ToolTalk’s Analysis of GPT-3.5 and GPT-4

Explore ToolTalk’s experiments and analysis, evaluating GPT-3.5 and GPT-4 in AI tool usage.
298. LLMs: What Is the Mechanism of Sentience and Intelligence?

Consciousness is simply the interactions of the components of the human mind. When the components interact, they help to know.
299. Enhancing Genetic Improvement Mutations: Conclusions and Future Work

Conclusions drawn from integrating Large Language Models (LLMs) into Genetic Improvement (GI) experiments and exploring future prospects for software evolution.
300. SpeechVerse Unites Audio Encoder and LLM for Superior Spoken QA

Discover how SpeechVerse uses a 24-layer Conformer and LLMs like Flan-T5 and Mistral to boost spoken QA performance.
301. Behind the Scenes: The Prompts and Tricks That Made Many-Shot ICL Work

Appendix details prompts, selection robustness tests, GPT4V-Turbo comparisons, and medical QA extensions validating many-shot ICL methodology.
302. Integrated Speech Language Models Face Critical Safety Vulnerabilities

Adversarial attacks easily bypass safety in SLMs, urging robust defenses and further research to secure multimodal speech-language systems.
303. CulturaX: A High-Quality, Multilingual Dataset for LLMs – Multilingual Dataset Creation

Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
304. FOD 39: Truly Open – We Explore Who Stands Behind OLMo’s Release

We review OLMo, an AI breakthrough by AI2, that promises true open-source: full package access. Plus the latest updates from the AI world.
305. How Many Glitch Tokens Hide in Popular LLMs? Revelations from Large-Scale Testing

Under-trained token indicators efficiently flag risky tokens in LLMs, with cross-model results showing 0.1–1% of vocabularies consistently problematic.
306. How I Grew My Twitter Audience From 0 to 500 Followers in Just 30 Days
I rebuilt my Twitter from zero after a ban. Here’s exactly how I grew to 500 followers in 30 days with replies, real takes, and no cross-promo deals

307. Where does In-context Translation Happen in Large Language Models: Conclusion

In this study, researchers attempt to characterize the region where large language models transition from in-context learners to translation models.
308. Where does In-context Translation Happen in Large Language Models: Inference Efficiency

In this study, researchers attempt to characterize the region where large language models transition from in-context learners to translation models.
309. CulturaX: A High-Quality, Multilingual Dataset for LLMs – Conclusion and References

Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
310. Towards Automatic Satellite Images Captions Generation Using LLMs: References
Researchers present ARSIC, a method for remote sensing image captioning using LLMs and APIs, improving accuracy and reducing human annotation needs.
311. The Nuts and Bolts of Token Testing: Prompt Variations and Decoding in Practice

Robust, repetitive prompts and UTF-8 understanding are key for accurately verifying and diagnosing under-trained tokens across language models.
312. Large Language Models on Memory-Constrained Devices Using Flash Memory: Conclusion & Discussion

Efficiently run large language models on devices with limited DRAM by optimizing flash memory use, reducing data transfer, and enhancing throughput.
313. Personalized Soups: LLM Alignment Via Parameter Merging – Abstract & Introduction

This paper introduces RLPHF, which aligns large language models with personalized human preferences via multi-objective RL and parameter merging.
314. DreamLLM: Additional Qualitative Examples That Show Off Its Power

These figures illustrate DREAMLLM’s proficiency in comprehending and generating long-context multimodal information in various input and output formats.
315. Where does In-context Translation Happen in Large Language Models: Characterising Redundancy in Laye

In this study, researchers attempt to characterize the region where large language models transition from in-context learners to translation models.
316. Recommendations by Concise User Profiles from Review Text: Related Work

This work addresses the difficult and underexplored case of supporting users who have very sparse interactions but post informative review texts.
317. NExT-GPT: Any-to-Any Multimodal LLM: Abstract and Intro

In this study, researchers present an end-to-end general-purpose any-to-any MM-LLM system called NExT-GPT.
318. The Data We Acquired From Using LLMs to Support Thematic Analysis

In our experiments, we used a dataset of 785 facts descriptions from cases of Czech courts decided in 2017.
319. Why Thousands of Examples Beat Dozens Every Time

Many-shot multimodal ICL with thousands of examples improves LMM performance. Gemini 1.5 Pro shows log-linear gains; batching reduces costs.
320. The HackerNoon Newsletter: So.. How Does One REALLY Determine AI Is Conscious? (2/8/2025)

2/8/2025: Top 5 stories on the HackerNoon homepage!
321. Adaptive Attacks Expose SLM Vulnerabilities and Qualitative Insights

Adaptive attacks require larger perturbations to overcome TDNF defenses in SLMs, reducing jailbreak success; qualitative examples highlight strengths and limita
322. Large Language Models on Memory-Constrained Devices Using Flash Memory: Abstract and Intro

Efficiently run large language models on devices with limited DRAM by optimizing flash memory use, reducing data transfer, and enhancing throughput.
323. The End of the Guessing Game? Why Describing Data Beats Estimating It

CLAIM surpasses statistical and ML methods by using LLMs for contextual imputation, though future work must address scalability and domain specificity.
324. FreeEval: A Modular Framework for Trustworthy and Efficient Evaluation of Large Language Models

FreeEval is designed with a high-performance infrastructure, including distributed computation and caching strategies
325. How ICPL Enhances Reward Function Efficiency and Tackles Complex RL Tasks
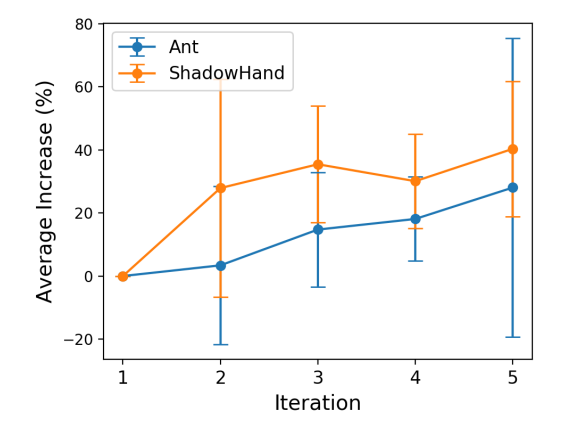
ICPL enhances reinforcement learning by integrating LLMs and human preferences for efficient reward function synthesis.
326. Large Language Models on Memory-Constrained Devices Using Flash Memory: Results

Efficiently run large language models on devices with limited DRAM by optimizing flash memory use, reducing data transfer, and enhancing throughput.
327. AI Use in Manuscript Preparation for Academic Journals: Appendix for Perceptions and Detection

In this study, researchers investigate whether academics view it as necessary to report AI use in manuscript preparation.
328. Navigation with Large Language Models: System Evaluation
In this paper we study how the “semantic guesswork” produced by language models can be utilized as a guiding heuristic for planning algorithms.
329. GPT Models for Sequence Labeling: Prompt Engineering & Fine-tuning

Explore how our study utilizes prompt engineering and fine-tuning strategies to adapt GPT-3.5 and GPT-4 models for identifying praise components
330. How Tokenizer Choices Shape Hidden Risks in Popular Language Models

Model-specific analysis reveals GPT-2, NeoX, and OLMo tokenizers each harbor unique under-trained tokens, influenced by training data and tokenizer choices.
331. A Meta-Evaluation of LLMs

Meta-evaluation refers to the process of evaluating the fairness, reliability, and validity of evaluation protocols themselves.
332. Navigation with Large Language Models: Problem Formulation and Overview
In this paper we study how the “semantic guesswork” produced by language models can be utilized as a guiding heuristic for planning algorithms.
333. Multi-Token Prediction: Higher Sample Efficiency for Large Language Models

Discover how training LLMs to predict multiple future tokens simultaneously boosts sample efficiency and improves downstream capabilities
334. This Model Knows Which Movie Scenes Matter Most

AI model identifies key scenes in movie scripts to create accurate summaries, reducing length while improving narrative clarity.
335. Where does In-context Translation Happen in Large Language Models: Appendix

In this study, researchers attempt to characterize the region where large language models transition from in-context learners to translation models.
336. “We Need Structured Output”: Towards User-Centered Constraints on Large Language Model Output

We conclude with a discussion on user preferences and needs towards articulating intended constraints for LLMs
337. Personalized Soups: LLM Alignment Via Parameter Merging – Related Work

This paper introduces RLPHF, which aligns large language models with personalized human preferences via multi-objective RL and parameter merging.
338. How I Built a Personal Assistant Using Google Cloud and Vertex AI: mAIdAI

I realized I needed something different. Not another generic team bot, but a Personal AI Assistant — one that knows my specific context, my preferred shortcuts
339. Researchers Uncover Breakthrough in Human-In-the-Loop AI Training with ICPL

Discover ICPL, a novel approach that leverages Large Language Models to enhance reward learning efficiency in reinforcement learning.
340. The Danger of AI-Generated Information
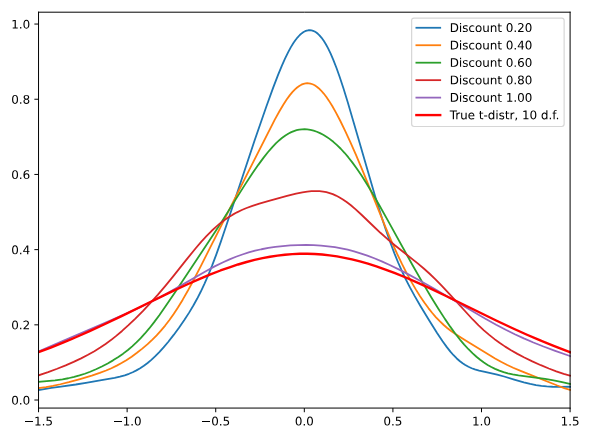
AI can reduce the cost of accessing information, but over-reliance on AI-generated content leads to knowledge collapse.
341. Adversarial Attacks Challenge the Integrity of Speech Language Models

Discover how white-box, black-box, and transfer attacks expose vulnerabilities in speech LLMs and how noise flooding defends against them.
342. Large Language Models on Memory-Constrained Devices Using Flash Memory: Optimized Data in DRAM

Efficiently run large language models on devices with limited DRAM by optimizing flash memory use, reducing data transfer, and enhancing throughput.
343. Recommendations by Concise User Profiles from Review Text: Methodology

This work addresses the difficult and underexplored case of supporting users who have very sparse interactions but post informative review texts.
344. CLAIM: A Contextual Language Model for Accurate Imputation of Missing Tabular Data

CLAIM uses LLMs to fill missing tabular data with contextual text, outperforming traditional methods and improving downstream task accuracy.
345. Safety Alignment and Jailbreak Attacks Challenge Modern LLMs

Explore how safety alignment and adversarial jailbreak attacks expose vulnerabilities in multimodal LLMs and speech language models.
346. The Role of Human-in-the-Loop Preferences in Reward Function Learning for Humanoid Tasks
Explore how human-in-the-loop preferences refine reward functions in tasks like humanoid running and jumping.
347. Real-World Use Cases That Necessitate Output Constraints

Below, we discuss a number of interesting insights that emerged from our analysis of the use cases
348. FreeEval: Efficient Inference Backends

FreeEval’s high-performance inference backends are designed to efficiently handle the computational demands of large-scale LLM evaluations.
349. A Summarize-then-Search Method for Long Video Question Answering: Related Work

In this paper, researchers explore zero-shot video QA using GPT-3, outperforming supervised models, leveraging narrative summaries and visual matching.
350. Enhancing Genetic Improvement Mutations: Acknowledgements & References

References for Integrating Large Language Models (LLMs) into Genetic Improvement (GI) experiments.
351. How LLMs Have Transformed Working with Computers

Why are LLMs such a big deal? How are LLMs game-changers? Can you communicate with a computer using plain English? Find all the answers in this article!
352. Recommendations by Concise User Profiles from Review Text: Experimental Results

This work addresses the difficult and underexplored case of supporting users who have very sparse interactions but post informative review texts.
353. Standard GI Mutations vs. LLM Edits in Random Sampling and Local Search
Discover the outcomes of experiments comparing standard Genetic Improvement mutations with LLM edits in both random sampling and local search scenarios.
354. New AI Can Talk About Your Artwork Like a Professional Critic

Researchers at the Mohamed bin Zayed University developed an AI model that can create text-based conversations tied to specific objects or regions in an image.
355. Satisfying UI and Product Requirements and Improving User Experience, Trust, and Adoption

Satisfying UI and Product Requirements Respondents stressed that it is essential to constrain LLM output to meet UI and product specifications
356. Leveraging LLMs for Generation of Unusual Text Inputs in Mobile App Tests: Related Work

Using InputBlaster, a novel approach in leveraging LLMs for automated generation of diverse text inputs in mobile app testing.
357. This New AI Model Is Excelling in Understanding and Interacting with Images

Researchers at the Mohamed bin Zayed University developed an AI model that can create text-based conversations tied to specific objects or regions in an image.
358. Using Courier and GPT2 to Generate a Motivational Quote of the Day
Learn to use a machine learning model and the Hugging Face model to generate a quote on demand with Courier and GPT2
359. Communication Isn’t the Problem. Retrieval Is.

Management failures are often retrieval failures: the information existed, but the system failed to surface it to the right person in time.
360. FLock.io Partners With Alibaba Cloud On Advanced AI Model Co-Creation

361. Give Your AI Coding Assistant a Domain Expert Brain in 30 Seconds

A free, open-source collection of 38 role-based AI persona packs for Claude Code, Cursor, and VS Code.
362. TnT-LLM for User Intent and Conversational Domain Labeling in Bing Copilot

We evaluate TnT-LLM on real-world Bing Copilot chat transcripts for user intent detection and conversational domain labeling and detailing our data sampling.
363. A Summarize-then-Search Method for Long Video Question Answering: Method

In this paper, researchers explore zero-shot video QA using GPT-3, outperforming supervised models, leveraging narrative summaries and visual matching.
364. Improving NLQ Accuracy Over Enterprise Data Warehouses Through Contextual Metadata Enrichment

NLQ failures over enterprise data warehouses are a metadata problem, not a model problem. A practical three-stage demonstration using Kiro-CLI and Redshift.
365. When AI Rewrites the Internet, What Do We Lose?

AI-generated content affects knowledge distribution by influencing information cascades, network effects, and model collapse, leading to potential biases & more
366. Leveraging LLMs for Generation of Unusual Text Inputs in Mobile App Tests: Approach

Using InputBlaster, a novel approach in leveraging LLMs for automated generation of diverse text inputs in mobile app testing.
367. If You Like DreamLLM, Check These Works Out

Rapid developments have been witnessed in extending LLMs like LLaMA to multimodal comprehension that enables human interaction with words and visual content.
368. A Summarize-then-Search Method for Long Video Question Answering: Prompt Samples

In this paper, researchers explore zero-shot video QA using GPT-3, outperforming supervised models, leveraging narrative summaries and visual matching.
369. Background and Automatic Evaluation Methods for LLMs

In this section, we provide an overview of the current landscape of LLM evaluation methods and the challenges posed by data contamination
370. Where does In-context Translation Happen in Large Language Models: Abstract and Background

In this study, researchers attempt to characterize the region where large language models transition from in-context learners to translation models.
371. Large Language Models on Memory-Constrained Devices Using Flash Memory: Improving Throughput

Efficiently run large language models on devices with limited DRAM by optimizing flash memory use, reducing data transfer, and enhancing throughput.
372. New AI Model Could Redefine How Machines Describe Images

Researchers at the Mohamed bin Zayed University developed an AI model that can create text-based conversations tied to specific objects or regions in an image.
373. AI Use in Manuscript Preparation for Academic Journals: Methods

In this study, researchers investigate whether academics view it as necessary to report AI use in manuscript preparation.
374. Recommendations by Concise User Profiles from Review Text: Conclusion

This work addresses the difficult and underexplored case of supporting users who have very sparse interactions but post informative review texts.
375. How AI Learns to Summarize Movies Like a Human

A two-stage model that selects key movie scenes and summarizes scripts more effectively using a novel human-annotated saliency dataset.
376. NExT-GPT: Any-to-Any Multimodal LLM: Instruction Dataset

In this study, researchers present an end-to-end general-purpose any-to-any MM-LLM system called NExT-GPT.
377. A Summarize-then-Search Method for Long Video Question Answering: Abstract & Intro

In this paper, researchers explore zero-shot video QA using GPT-3, outperforming supervised models, leveraging narrative summaries and visual matching.
378. Recommendations by Concise User Profiles from Review Text: Experimental Results

This work addresses the difficult and underexplored case of supporting users who have very sparse interactions but post informative review texts.
379. Personalized Soups: LLM Alignment Via Parameter Merging – Personalized Human Feedback

This paper introduces RLPHF, which aligns large language models with personalized human preferences via multi-objective RL and parameter merging.
380. How to Bridge the Gap Between Specs and Agents: MLOps Coding Skills

Despite the minor friction, Agent Skills are excellent “Low Hanging Fruit” for any engineering team.
381. How Do We Teach Reinforcement Learning Agents Human Preferences?

Explore how ICPL builds on foundational works like EUREKA to redefine reward design in reinforcement learning.
382. Hacking Reinforcement Learning with a Little Help from Humans (and LLMs)

Explore how ICPL builds on foundational works like EUREKA to redefine reward design in reinforcement learning.
383. CulturaX: A High-Quality, Multilingual Dataset for LLMs – Data Analysis and Experiments

Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
384. Recommendations by Concise User Profiles from Review Text: Ethics Statement and References

This work addresses the difficult and underexplored case of supporting users who have very sparse interactions but post informative review texts.
385. Enhancing Genetic Improvement Mutations Using Large Language Models

Discover the innovative application of large language models (LLMs) in Genetic Improvement (GI) for software engineering tasks.
386. How to Articulate Output Constraints to LLMS

An overarching observation is that respondents preferred using GUI to specify low-level constraints and natural language to express high-level constraints.
387. Leveraging LLMs for Generation of Unusual Text Inputs in Mobile App Tests: Study and Background

Using InputBlaster, a novel approach in leveraging LLMs for automated generation of diverse text inputs in mobile app testing.
388. CulturaX: A High-Quality, Multilingual Dataset for LLMs – Related Work

Introducing CulturaX: a 6.3 trillion-token multilingual dataset in 167 languages, meticulously cleaned and deduplicated for training high-performing LLMs.
389. Large Language Models on Memory-Constrained Devices Using Flash Memory: Results for Falcon 7B Model

Efficiently run large language models on devices with limited DRAM by optimizing flash memory use, reducing data transfer, and enhancing throughput.
390. Multi-Token Prediction: Performance Scales with LLM Size

Discover how training large language models with multi-token prediction significantly boosts performance for larger model sizes
391. The Case for NL: More Intuitive and Expressive for Complex Constraints

Respondents found natural language easier for specifying complex constraints than GUIs
392. Transfer Attacks Reveal SLM Vulnerabilities and Effective Noise Defenses

Cross-model attacks expose SLM weaknesses, while noise-based defenses substantially reduce jailbreak risks with minimal impact on performance.
393. Personalized Soups: LLM Alignment Via Parameter Merging – Experiments

This paper introduces RLPHF, which aligns large language models with personalized human preferences via multi-objective RL and parameter merging.
394. FreeEval Architecture Overview and Extensible Modular Design

FreeEval’s architecture features a modular design that could be separated into Evaluation Methods, Meta-Evaluation, and LLM Inference Backends.
395. The Design and Implementation of FreeEval

In this section, we present the design and implementation of FreeEval, we discuss the framework’s architecture and its key components
396. Enhancing Data Quality: How low-quality data affects the performance of Collaborative Training

In this study, researchers propose a data quality control pipeline for federated fine-tuning of foundation models.
397. Smart Summaries: Teaching AI to Pick Key Scenes from Scripts

A new summarization method pinpoints critical movie scenes for faster, more effective script-to-summary generation using AI.
398. How FreeEval Incorporates A Range of Metaevaluation Modules

FreeEval prioritizes trustworthiness and fairness in evaluations by incorporating a range of metaevaluation modules that validates the evaluation results
399. The HackerNoon Newsletter: Managing Stress May Be A Lot Simpler Than You Think (12/17/2024)

12/17/2024: Top 5 stories on the HackerNoon homepage!
400. Enhancing Data Quality: Conclusion and Future Work, and References

In this study, researchers propose a data quality control pipeline for federated fine-tuning of foundation models.
401. Leveraging LLMs for Generation of Unusual Text Inputs in Mobile App Tests: Results and Analysis

Using InputBlaster, a novel approach in leveraging LLMs for automated generation of diverse text inputs in mobile app testing.
402. The Fastest Way to Prototype Agents: Declare the “What,” Let ADK Run the “How”

Speed up AI development with Ackgent, a declarative starter kit using Google ADK Agent Config to build agents via YAML, not boilerplate.
403. New AI Dataset Pushes Boundaries While Tackling Challenges in Ethics and Precision

Researchers at the Mohamed bin Zayed University developed an AI model that can create text-based conversations tied to specific objects or regions in an image.
404. The Fast-Paced Competition in Pursuit of the Ultimate LLM

Big tech is charging ahead in LLM development. Around a decade after virtual assistants like Siri and Alexa were introduced, a new wave of AI helpers.
405. Enhancing Data Quality: Ablation Study of Unified Scoring With Anchor Data

In this study, researchers propose a data quality control pipeline for federated fine-tuning of foundation models.
406. Your AI Has a Favorite Opinion—And It’s Not Yours

Large language models inherit biases from training data, struggle with long-tail knowledge, and favor mainstream viewpoints.
407. Tracking Reward Function Improvement with Proxy Human Preferences in ICPL

Explore how In-Context Preference Learning (ICPL) progressively refined reward functions in humanoid tasks using proxy human preferences.
408. Cross-Prompt Attacks and Data Ablations Impact SLM Robustness

Examine how cross-prompt attacks, training data ablations, and random noise influence the robustness, helpfulness, and safety of speech language models.
409. The HackerNoon Newsletter: Swift: Master of Decoding Messy json (2/26/2026)

2/26/2026: Top 5 stories on the HackerNoon homepage!
410. Not Just A Compiler: What Makes AI Code Generation So Different?

Forget the old abstraction ladder! Explaining how LLM-assisted programming is a new kind of tool that allows developers to “teleport” to arbitrary levels
411. Leveraging LLMs for Generation of Unusual Text Inputs in Mobile App Tests: Conclusion and References

412. NExT-GPT: Any-to-Any Multimodal LLM: Conclusion and References

In this study, researchers present an end-to-end general-purpose any-to-any MM-LLM system called NExT-GPT.
413. Large Language Models on Memory-Constrained Devices Using Flash Memory: Flash Memory & LLM Inference

Efficiently run large language models on devices with limited DRAM by optimizing flash memory use, reducing data transfer, and enhancing throughput.
414. A Summarize-then-Search Method for Long Video Question Answering: Limitations & References

In this paper, researchers explore zero-shot video QA using GPT-3, outperforming supervised models, leveraging narrative summaries and visual matching.
415. FOD 37: Can We Genuinely Trust LLMs?

Froth on the Daydream (FOD) – Weekly AI newsletter summary connecting the dots in AI evolution. Insights on AI safety, inclusivity, efficiency, and human-centri
416. Researchers Just Built a Plug-and-Play Brain for LLMs

With a plug-and-play value model, Q★ improves LLM reasoning and achieves cutting-edge coding and math correctness without the need for fine-tuning.
417. Teaching LLMs How to “Think Twice”
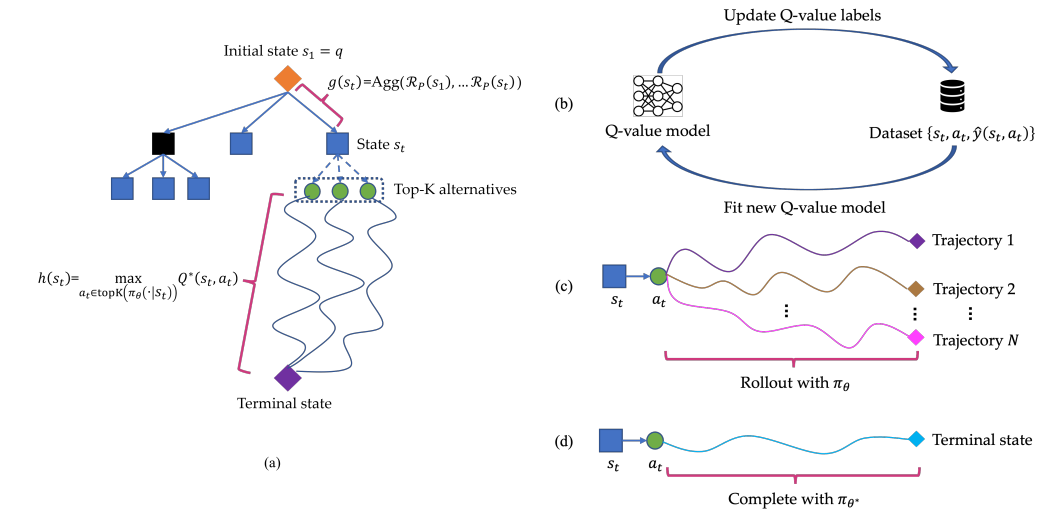
Q* merges A* search with LLMs to boost multi-step reasoning, reduce hallucinations, and enable smarter AI deliberation.
418. It’s Not Just What’s Missing, It’s How You Say It: CLAIM’s Winning Formula
Experiments show CLAIM outperforms baselines like k-NN and MICE across all missingness patterns, with context-specific descriptors proving most effective.
419. AI Use in Manuscript Preparation for Academic Journals: References

In this study, researchers investigate whether academics view it as necessary to report AI use in manuscript preparation.
420. Researchers Develop Groundbreaking Method to Teach AI to ‘Understand’ Images Like Never Before

Researchers at the Mohamed bin Zayed University developed an AI model that can create text-based conversations tied to specific objects or regions in an image.
421. Who’s Harry Potter? Approximate Unlearning in LLMs: Conclusion, Acknowledgment, and References

In this paper, researchers propose a novel technique for unlearning a subset of the training data from a LLM without having to retrain it from scratch.
422. Will Meta’s New LLamA Usher in a New Wave of Competition?

Brace yourselves; the AI revolution is not just upon us – it’s already redefining the rules of the game.
423. Turning Movie Scripts into Short Summaries—Smarter and Faster

Automatically summarize movie scripts by selecting only the most relevant scenes, powered by a human-annotated dataset.
424. How We Deployed an Online Survey to Users of an Internal Prompt-Based Prototyping Platform

To get a broad range of insights from people who have experience with prompting and building LLM-powered applications, we deployed an online survey to users
425. Leveraging LLMs for Generation of Unusual Text Inputs in Mobile App Tests: Discussion and Validity

Using InputBlaster, a novel approach in leveraging LLMs for automated generation of diverse text inputs in mobile app testing.
426. LLMs: Without the Human Mind, Would AI Regulation Work?
What exactly in the human mind that represents intelligence, has AI copied? How does the human mind work that lets anything external have an effect?
427. How ICPL Addresses the Core Problem of RL Reward Design

ICPL integrates LLMs with human preferences to iteratively synthesize reward functions, offering an efficient, feedback-driven approach to RL reward design.
428. Large Language Models on Memory-Constrained Devices Using Flash Memory: Reducing Data Transfer

Efficiently run large language models on devices with limited DRAM by optimizing flash memory use, reducing data transfer, and enhancing throughput.
429. Who’s Harry Potter? Approximate Unlearning in LLMs: Evaluation methodology

In this paper, researchers propose a novel technique for unlearning a subset of the training data from a LLM without having to retrain it from scratch.
430. Tree-Diffusion: A New Approach to Code Generation with Neural Diffusion Models

This article introduces Tree-Diffusion, a novel method for code generation that uses neural diffusion models on syntax trees.
431. SLMs Outperform Competitors Yet Suffer Rapid Adversarial Jailbreaks

Results show our SLMs outperform public models in safety and relevance but remain highly vulnerable to fast adversarial attacks.
432. Audio Encoder Pre-training and Evaluation Enhance SLM Safety

Discover our 24-layer Conformer pre-training details and evaluation methods using Claude 2.1 to ensure safety, relevance, and helpfulness in SLMs.
433. UAE Researchers Spill the Beans on How Their AI Comprehends Images in Detail

Researchers at the Mohamed bin Zayed University developed an AI model that can create text-based conversations tied to specific objects or regions in an image.
434. Conclusion: GPT Models for Automated Explanatory Feedback

We conclude our study on enhancing automated feedback systems using GPT models, demonstrating the effectiveness of prompting and fine-tuning for tutor training.
435. Where does In-context Translation Happen in Large Language Models: Data and Settings

In this study, researchers attempt to characterize the region where large language models transition from in-context learners to translation models.
436. Large Language Models on Memory-Constrained Devices Using Flash Memory: Related Works

Efficiently run large language models on devices with limited DRAM by optimizing flash memory use, reducing data transfer, and enhancing throughput.
437. Discussing GPT Models for Automated Explanatory Feedback in Tutor Training

Our discussion covers GPT’s role in delivering automated explanatory feedback for tutors, comparing prompting and fine-tuning approaches,
438. The HackerNoon Newsletter: AI Knows Best—But Only If You Agree With It (2/18/2025)

2/18/2025: Top 5 stories on the HackerNoon homepage!
439. You.com: A Glimpse into the Future of AI and Search Innovation

You.com showcases the state of AI today.
440. A New Chapter In Coding: How AI Is Profoundly Changing Programmer Practices

This conclusion explores the profound impact of AI-assisted programming, showing how it’s not just a new feature but a fundamental shift
441. NExT-GPT: Any-to-Any Multimodal LLM: Any-to-any Multimodal Generation

In this study, researchers present an end-to-end general-purpose any-to-any MM-LLM system called NExT-GPT.
442. AI Use in Manuscript Preparation for Academic Journals: Abstract and Introduction

In this study, researchers investigate whether academics view it as necessary to report AI use in manuscript preparation.
443. A Summarize-then-Search Method for Long Video Question Answering: Experiments

In this paper, researchers explore zero-shot video QA using GPT-3, outperforming supervised models, leveraging narrative summaries and visual matching.
444. Enhancing Data Quality in Federated Fine-Tuning of Foundation Models: Experiments

In this study, researchers propose a data quality control pipeline for federated fine-tuning of foundation models.
445. Who’s Harry Potter? Approximate Unlearning in LLMs: Appendix

In this paper, researchers propose a novel technique for unlearning a subset of the training data from a LLM without having to retrain it from scratch.
446. Adversarial Settings and Random Noise Reveal Speech LLM Vulnerabilities

Discover how precise attack parameters and random noise baselines test and expose safety flaws in speech language models.
447. Datasets and Evaluation Define the Robustness of Speech Language Models

Explore how curated ASR and TTS datasets and rigorous evaluation metrics benchmark the safety and utility of multimodal speech language models.
448. NExT-GPT: Any-to-Any Multimodal LLM: Related Work

In this study, researchers present an end-to-end general-purpose any-to-any MM-LLM system called NExT-GPT.
449. AI Use in Manuscript Preparation for Academic Journals: Results

In this study, researchers investigate whether academics view it as necessary to report AI use in manuscript preparation.
450. It’s Not Your AI Partner: The Superficial Analogy Of Pair Programming

Explore the unique experience of a solo programmer with an AI assistant. Discussing how a single person fluidly shifts between “driver” and “navigator” roles
451. What’s Next for AI in Regulated Social Media?

Discover an AI-driven multi-agent simulation framework illuminating how language evolves creatively under social media regulations, and explore future direction
452. Large Language Models on Memory-Constrained Devices Using Flash Memory: Results for OPT 6.7B Model

Efficiently run large language models on devices with limited DRAM by optimizing flash memory use, reducing data transfer, and enhancing throughput.
453. The Real Cost of the ADHD Generalist Life

What 17 years of ADHD hyperfocus taught me about hobbies, careers, identity, and why some interests actually stick.
454. The LLM Hype Train: You Should Know the Truth

What if I told you ChatGPT is the end of software engineering? Would you believe it? Three years ago, OpenAI changed the game in the AI field with ChatGPT.
455. UAE Researchers Reveal the Secrets Behind an AI That Truly Understands Images

Researchers at the Mohamed bin Zayed University developed an AI model that can create text-based conversations tied to specific objects or regions in an image.
456. How We Integrated Downstream Processes and Workflows

This suggests that it could be more advantageous for models to accept output constraints independent of the prompt
457. Peace, War, and Artificial Intelligence

With AI and pursuit of more advanced autonomy for weaponry, we must ask, what intentions will humanity send on rockets to other stars?
458. Large Language Models on Memory-Constrained Devices Using Flash Memory: Load From Flash

Efficiently run large language models on devices with limited DRAM by optimizing flash memory use, reducing data transfer, and enhancing throughput.
459. Large Language Models on Memory-Constrained Devices Using Flash Memory: Read Throughput

Efficiently run large language models on devices with limited DRAM by optimizing flash memory use, reducing data transfer, and enhancing throughput.
460. Building On Giants: A Look At The Research That Shaped This Paper

This comprehensive list of references spans the academic context of our work, from foundational research in program synthesis and HCI to modern topics like AI
461. Enhancing Data Quality in Federated Fine-Tuning of Foundation Models: Related Work

In this study, researchers propose a data quality control pipeline for federated fine-tuning of foundation models.
462. MegaTrain Makes 100B Model Training Possible on One GPU

This is a Plain English Papers summary of a research paper called MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU…
463. Enhancing Data Quality: Examples for Low-and High-quality Data

In this study, researchers propose a data quality control pipeline for federated fine-tuning of foundation models.
464. Optimizing Genetic Improvement with GPT 3.5 Turbo

Delve into the experimental setup utilizing GPT 3.5 Turbo and the Gin toolbox for Genetic Improvement experiments.
465. NExT-GPT: Any-to-Any Multimodal LLM: Overall Architecture

In this study, researchers present an end-to-end general-purpose any-to-any MM-LLM system called NExT-GPT.
466. Is It Search Or Is It AI? The Real Differences In How Programmers Get Help

This section unpacks how LLM-assisted programming is more than just a smarter search. Highlighting the key differences
467. The Architecture Behind Smarter AI Agents

Modern AI agents succeed through architecture, not just scale. This paper maps the systems that extend model capabilities.
468. SaaS-pocalypse Part 3: Which SaaS Moats Survive AI?

AI is reshaping SaaS moats fast. See which of Helmer’s 7 powers are eroding, strengthening, or shifting in the AI era.
469. AI Use in Manuscript Preparation for Academic Journals: Discussion

In this study, researchers investigate whether academics view it as necessary to report AI use in manuscript preparation.
470. This New AI Can See, Talk, and Even Edit Images in a Single Conversation

Researchers at the Mohamed bin Zayed University developed an AI model that can create text-based conversations tied to specific objects or regions in an image.
471. Enhancing Data Quality in Federated Fine-Tuning of Foundation Models: Heterogeneity Settings

In this study, researchers propose a data quality control pipeline for federated fine-tuning of foundation models.
472. How to Extend the Expressiveness of AI Agents: Building With A2UI

This is the promise of A2UI (Agent-to-User Interface): a protocol that allows agents to “speak” UI natively.
473. NExT-GPT: Any-to-Any Multimodal LLM: Lightweight Multimodal Alignment Learning

In this study, researchers present an end-to-end general-purpose any-to-any MM-LLM system called NExT-GPT.
474. Your Social Media Supervisor Could Soon Be an AI, And It’s Getting Smarter

Discover an innovative LLM-based multi-agent framework that simulates language evolution under social media supervision, merging AI with evolutionary concepts.
475. The HackerNoon Newsletter: Why Does ETH 3.0 Need Lumozs ZK Computing Network? (12/22/2024)

12/22/2024: Top 5 stories on the HackerNoon homepage!
476. Enhancing Data Quality: Proposed Workflow for Data Quality Control

In this study, researchers propose a data quality control pipeline for federated fine-tuning of foundation models.
477. Enhancing Data Quality in Federated Fine-Tuning of Foundation Models: Abstract and Introduction

In this study, researchers propose a data quality control pipeline for federated fine-tuning of foundation models.
478. Enhancing Data Quality in Federated Fine-Tuning of Foundation Models: Experimental Details

In this study, researchers propose a data quality control pipeline for federated fine-tuning of foundation models.
479. Borderless TTS Fixes Context-Starved Speech

This is a Plain English Papers summary of a research paper called Borderless Long Speech Synthesis [https://www.aimodels.fyi/papers/arxiv/borderless-long-spe…
Thank you for checking out the 479 most read blog posts about Large Language Models on HackerNoon.
Visit the /Learn Repo to find the most read blog posts about any technology.