
When Should AI Step Aside?: Teaching Agents When Humans Want to Intervene
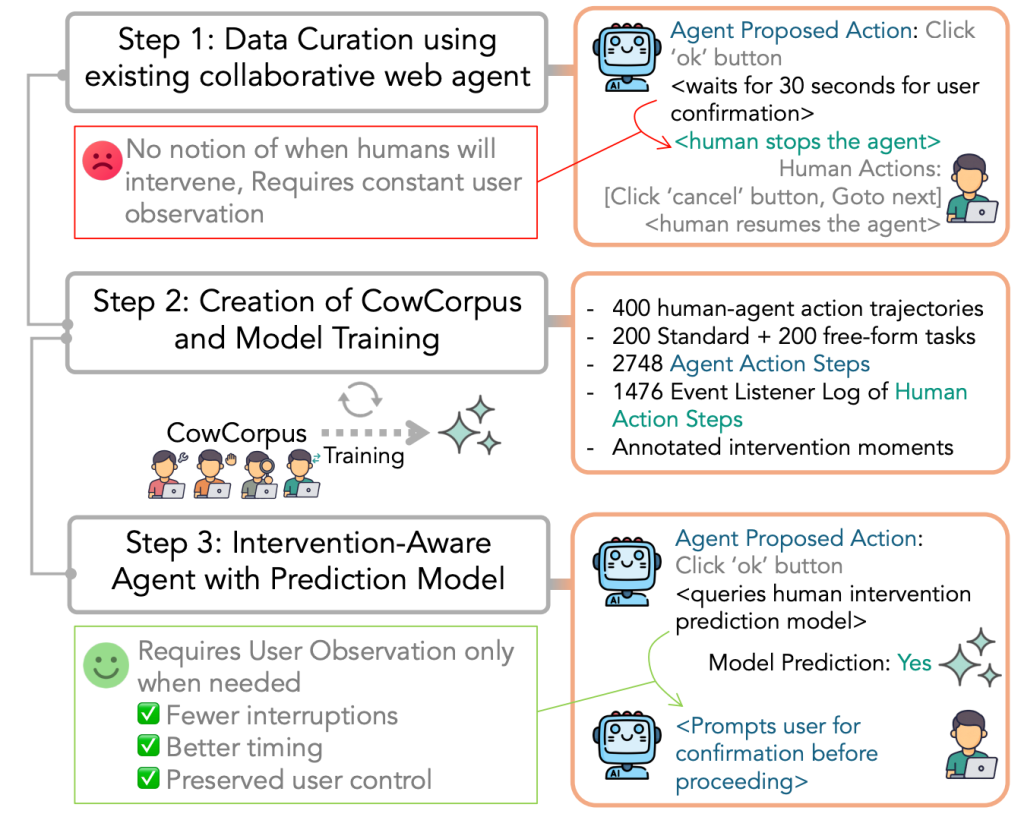
Recent advances in large language models (LLMs) have enabled AI agents to perform increasingly complex tasks in web navigation. Despite this progress, effective use of such agents continues to rely on human involvement to correct misinterpretations or adjust outputs that diverge from their preferences. However, current agentic systems lack an understanding of when and why humans intervene. As a result, they might overlook user needs and proceed incorrectly, or interrupt users too frequently with unnecessary confirmation requests.
This blogpost is based on our recent work — Modeling Distinct Human Interaction in Web Agents — where we shift the focus from autonomy to collaboration. Instead of optimizing agents solely for an end-to-end autonomous pipeline, we ask: Can agents anticipate when humans are likely to intervene?
CowCorpus: Learning from Real Interaction
To formulate this task, we collect CowCorpus – a novel dataset of interleaved human and agent action trajectories. Compared to existing datasets comprising either only agent trajectory or human trajectory, CowCorpus captures the collaborative task execution by a team of a human and an agent. In total, CowCorpus has:
- 400 real human–agent web sessions
- 4,200+ interleaved actions
- Step-level annotations of intervention moments
We curate CowCorpus from 20 real-world users using CowPilot, an open-source artifact by the same research team. CowPilot is built as a generalizable Chrome extension, which is accessible to any arbitrary website. It is also easy to install, making the annotation process simpler for our participants. In CowPilot, we showed how collaboration works. In PlowPilot, we want to make it adaptive.
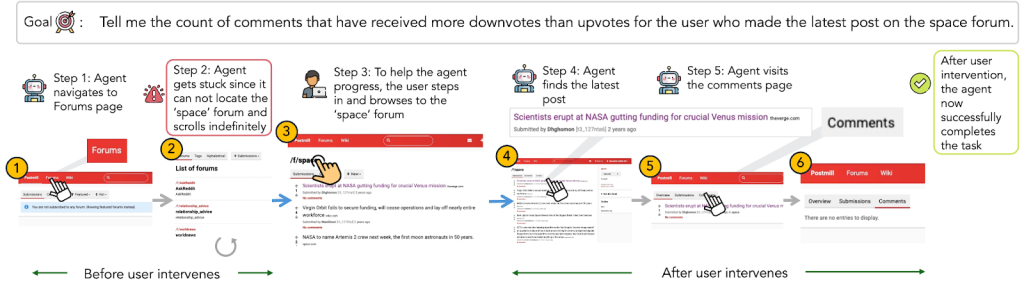
To ensure CowCorpus is consistent with established benchmarks and reflects individual user preferences, we designate a mixture of free-form tasks and benchmark tasks in our dataset —
- 10 standard tasks from the Mind2Web dataset (Deng et al., 2024): Helps us to understand how the collaborative nature varies among participants under the fixed task setup.
- 10 free-form tasks of the participants’ own choice: Helps us to understand what kind of web tasks people wish to automate.
In total, CowCorpus covers 9 types of task categories:


Task-Level Interaction Patterns
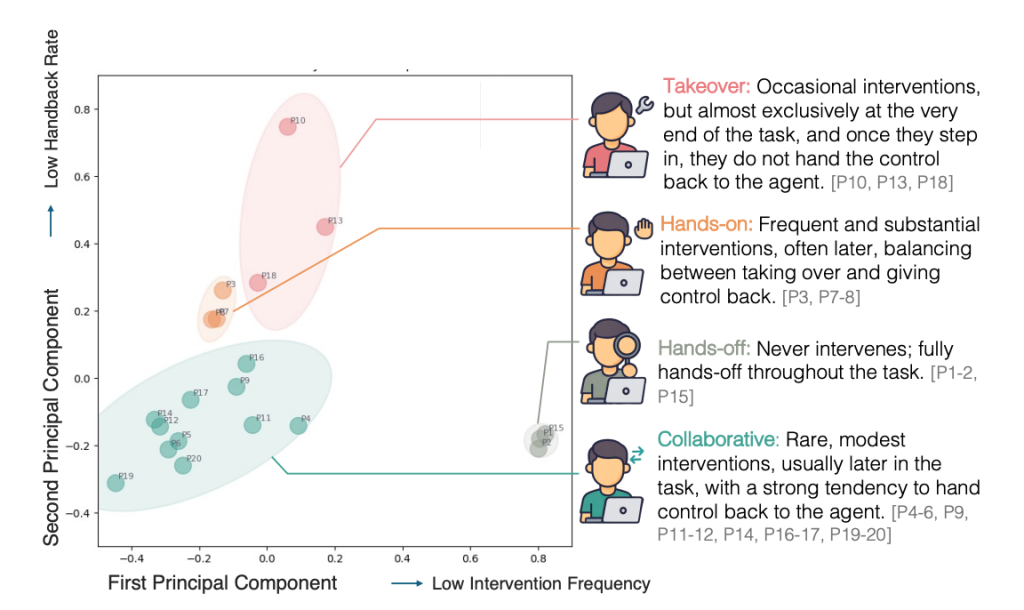
We analyze when human interventions occur during collaborative task execution and how such temporal patterns vary across users. Using participant-level measures, we cluster users by interaction behavior with 𝑘-means (𝑘=4). This analysis reveals four distinct and stable groups of users with qualitatively different patterns of intervention timing and control sharing. Based on cluster centroids and representative trajectories, we characterize the four groups as follows:
- Takeover: Users intervene infrequently and typically late in the task. When they do step in, they tend to retain control rather than returning it to the agent, resulting in low handback rates. These interventions often coincide with completing the task themselves rather than correcting the agent mid-execution.
- Hands-on: Users intervene frequently and with high intensity. Their interventions tend to occur relatively late in the trajectory, but unlike Takeover users, they regularly alternate control with the agent, leading to medium handback rates and sustained joint execution.
- Hands-off: Users rarely intervene throughout the task. They exhibit low intervention frequency and intensity, allowing the agent to execute most trajectories end-to-end with minimal human involvement.
- Collaborative: Users intervene selectively and consistently return control to the agent. This group is characterized by high handback rates and earlier intervention positions, reflecting targeted, short-lived interventions that support ongoing collaboration.
Overall, users exhibit systematic differences in when interventions occur, how much they intervene, and whether control is relinquished afterward. Such temporal intervention patterns are consistent across tasks and motivate modeling distinct human–agent interaction patterns.
Modeling Intervention as Prediction
We model human–agent collaboration as a Partially Observable Markov Decision Process (POMDP). Given a task instruction, both the agent and human take turns executing actions based on their policies, forming a trajectory over time. At each step, the system observes the current state as a multimodal input consisting of the webpage screenshot and accessibility tree. The agent proposes an action conditioned on the observation and past trajectory. The human may intervene at any step, represented as a binary variable.
We formulate intervention prediction as a step-wise binary classification problem that estimates the probability of human intervention given the current state, agent action, and history. To solve this, we use a large multimodal model trained via supervised fine-tuning. The model takes as input the trajectory history, current observation, and proposed action, and outputs a decision to either request human input or allow the agent to continue.
We train (1) a general intervention-aware model using all training data and (2) style-conditioned models tailored to each interaction group using the corresponding subset of trajectories. To evaluate effectiveness, we compare these models against both prompting-based proprietary LMs and fine-tuned open-weight models on the Human Intervention Prediction task. Across all models, main takeaways are:
- Proprietary Models remain overly conservative: We evaluate three families of closed-source LMs (Claude 4 Sonnet, GPT-4o, and Gemini 2.5 Pro) using zero-shot without reasoning. They struggle with the temporal dynamics necessary for accurate human intervention prediction. Notably, GPT-4o achieves high performance on non-intervention steps (Non-intervention F1: 0.846), but it fails on active interventions (Intervention F1: 0.198). The drastic F1 disparity indicates that generalist models are overly conservative and struggle to balance the dynamic with the need for proactive assistance.
- Fine-tuned Open-weight Models with Specialized Data Beats Scale: In contrast, finetuning open-weight models on CowCorpus yields the most significant performance gains, surpassing proprietary models. Our fine-tuned Gemma-27B (SFT) achieves the state-of-the-art PTS (0.303), outperforming Claude 4 Sonnet (0.293), while the smaller LLaVA-8B (SFT) achieves a competitive PTS (0.201), beating GPT-4o (0.147). These results demonstrate that fine-tuning on high-quality interaction traces effectively bridges the alignment gap, allowing smaller models to master the nuance of intervention timing where generalized giant models fail

From Modeling to Deployment: PlowPilot
We integrated our intervention-aware model into a live web agent, PlowPilot. Instead of asking for confirmation at every step, the agent now: 1) Predicts when intervention is likely; 2) Prompts only at high-risk moments or where user confirmation is likely to happen; 3) Proceeds automatically otherwise.
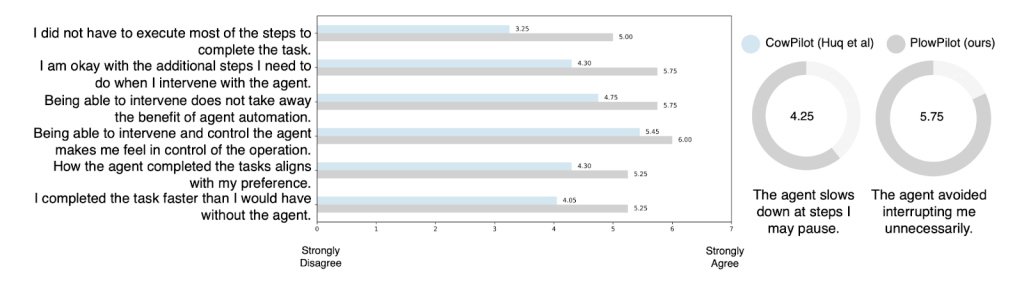
We reinvited our annotators and asked them to rate our new system. On average, we noticed a +26.5% increase in user-rated usefulness. The following figure highlights individual responses to each of 8 answers asked to them. Importantly, the underlying execution agent remains unchanged from CowPilot.; PlowPilot differs only by the addition of the intervention-aware module. The observed gains therefore, arise solely from proactively modeling human intervention. These findings provide initial evidence that anticipating user intervention can substantially improve the effectiveness and usability of collaborative agent systems in practice.
Final Thought
Intervention is a signal of preference and collaboration style. If agents can model that signal, they become adaptive partners rather than just autonomous tools.
Rather than maximizing full autonomy, we advocate optimizing the human–agent boundary. Agents should learn not only to act, but to defer—proactively handing control back when appropriate. This boundary should be adaptive, capturing user-specific interaction and intervention patterns. By learning when to involve the user, agents enable more efficient and personalized collaboration. Optimizing this adaptive handoff shifts the goal from autonomy to collaborative intelligence, reducing oversight while preserving control.
For more details:
- Modeling Distinct Human Interaction in Web Agents
- CowPilot: A Framework for Autonomous and Human-Agent Collaborative Web Navigation