
The Org Chart Has No Box for “AI Behavior Owner”
We built incident response for servers that crash. We have nothing for models that just change their mind.
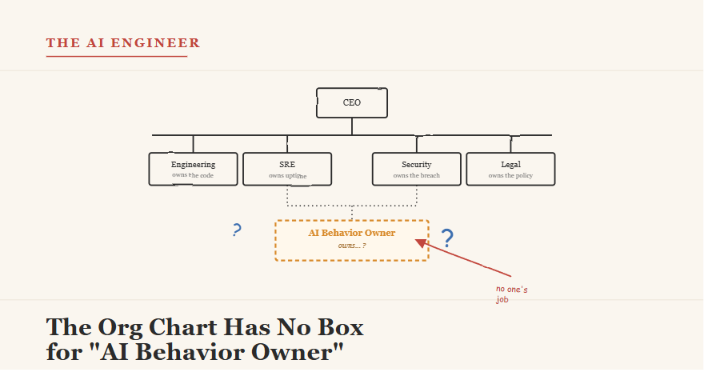
There’s a specific kind of meeting that’s becoming common in engineering orgs, and it has no template yet.
Someone shares a screenshot of an AI feature doing something strange — overly aggressive in a refund negotiation, oddly cold in a support reply, confidently wrong about a policy it used to get right. Six people join the call. An ML engineer says the model wasn’t retrained. A platform engineer says nothing was deployed. A product manager says the spec hasn’t changed. Everyone is telling the truth, and none of it explains what happened.
This meeting keeps happening because of a structural gap, not a people problem. We have decades of organizational muscle memory for software that breaks. We have almost none for software that simply behaves differently while remaining, by every conventional measure, “not broken.”
Two Kinds of Change, One Org Chart
Software organizations are built around a basic assumption: behavior changes when someone changes the code. Want different behavior? Open a pull request. That pull request gets reviewed, tested, deployed, and — critically — attributed. If something goes wrong afterward, there’s a commit history that says exactly who changed what, and when.
AI-powered features quietly broke that assumption, and most org charts haven’t caught up.
A model’s behavior can now change for reasons that have nothing to do with anyone on the team touching anything:
- A foundation model provider ships a routine update to improve average benchmark performance, and your specific use case — built around the model’s previous quirks — shifts underneath you.
- A vector store accumulates new documents, and a RAG system starts retrieving different context for the same query than it did last month, changing answers without anyone editing a prompt.
- A third-party tool an agent calls changes its own response format, and the agent’s downstream reasoning subtly adapts in ways nobody asked for.
- Usage patterns shift, more edge-case queries hit the system, and a model that was “fine” under typical traffic starts revealing weaknesses that were always there but rarely triggered.
None of these are bugs in the traditional sense. There’s no faulty line of code to point to. There’s no commit to revert. The behavior simply is different, and the org chart — built entirely around the idea that someone changed something on purpose — has no natural place to route the question of “why.”
The Incident That Has No Postmortem Template
Standard incident response runs on a reliable sequence: detect, diagnose, fix, write a postmortem that identifies a root cause and a preventive action. This sequence depends on the existence of a root cause that’s findable and a fix that’s applicable.
Behavioral drift in AI systems frequently fails both assumptions.
The “root cause” might be a model provider’s internal update that the company has no visibility into and no contractual right to inspect. The “fix” might not exist at all if the only available model versions are the new one and nothing else — there’s no older, stable build sitting in an artifact registry waiting to be redeployed, the way there would be for a code rollback. Vendors typically don’t promise to maintain old model versions indefinitely.
This leaves engineering teams in an unfamiliar position: a confirmed incident with no clear culprit, no available rollback, and no proven fix — only mitigations, like adjusting prompts to compensate for the new model’s tendencies, or adding guardrail logic to catch outputs that look like regressions. These are reasonable responses, but they’re patches over a structural absence, not solutions to it. And nobody owns deciding when a patch is good enough versus when the feature needs to be pulled entirely.
Why “Just Add Monitoring” Isn’t the Answer
The instinctive fix — “let’s just monitor model outputs more closely” — sounds right and is almost always under-specified in practice.
Monitoring requires deciding what to monitor for. Traditional monitoring tracks quantitative thresholds: latency over X milliseconds, error rate over Y percent. Behavioral drift is often qualitative before it’s quantitative. A model that becomes 5% more verbose, or subtly more willing to speculate when it doesn’t know an answer, or marginally less consistent in how it interprets an ambiguous policy — none of this trips a numeric threshold. It shows up as a vague, gathering sense among support staff or users that “something feels off,” long before it shows up in any dashboard.
Translating that vague sense into something a monitoring system can actually catch requires a function that doesn’t naturally belong to any existing team:
- ML teams build evaluation suites oriented toward model quality at training or fine-tuning time, not continuous post-deployment behavioral comparison.
- Platform and SRE teams build alerting oriented toward system health metrics that AI behavioral drift usually doesn’t trip.
- Product teams notice problems through user complaints, which is a real signal but an extremely lagging one.
Someone has to own building behavioral monitoring as its own discipline — defining what “behaviorally normal” looks like for a given AI feature, instrumenting ways to detect departures from it, and being the person who gets paged not when a server goes down, but when the character of the system’s output changes.
The Authority Problem
Even when behavioral drift is correctly diagnosed, a second gap shows up immediately afterward: who has the authority to act on it?
In traditional software, the authority structure is clear. An SRE with on-call authority can roll back a deploy unilaterally during an active incident, because uptime is understood organization-wide as a non-negotiable priority with pre-delegated authority to protect it.
AI behavioral incidents tend to fall into an authority vacuum. Pausing a feature that’s technically “working” — no errors, no downtime — but behaviorally degraded requires someone to make a judgment call that often touches product roadmap commitments, customer-facing promises, and sometimes legal exposure simultaneously. That’s a decision with stakes that exceed what any single existing role is typically empowered to make alone, and the result is frequently paralysis: the feature stays live while six people debate ownership, because nobody has been pre-delegated the authority to say “turn it off” the way an SRE can say it about a server.
This is the quieter cost of the missing role. It’s not just that nobody is watching for behavioral drift — it’s that even when someone notices, there’s no clear chain of command for responding to it quickly.
A Different Way to Think About the Role
It’s tempting to imagine the AI Behavior Owner as simply “the person who watches the AI.” A more useful framing is that this role is the organizational equivalent of a behavioral change-control board — the function that traditional software gives to code review and deployment gates, applied to a category of change that doesn’t go through either.
In practice, this means treating behavioral consistency as something that’s actively governed rather than passively hoped for:
- Every production AI feature has a documented behavioral baseline, established deliberately rather than discovered accidentally after something goes wrong.
- Every external dependency capable of silently altering that behavior — model providers, retrieval indexes, third-party APIs an agent calls — is tracked as a change-risk surface, with a designated owner responsible for noticing when it shifts.
- A standing, pre-delegated authority exists to pause or roll back a behaviorally degraded feature without requiring an emergency cross-functional negotiation in the middle of an active incident.
- Postmortems for behavioral incidents are written with the explicit understanding that “root cause: vendor changed something we can’t see” is a legitimate and common conclusion — not a failure of investigation, but an accurate description of a new kind of risk that needs its own category of mitigation going forward.
None of this needs to wait for a formal title or a new line on the org chart to start. It can begin as a responsibility, explicitly assigned to an existing person, with the authority that responsibility requires. The title matters less than the fact that, right now, in most organizations, nobody can answer “who owns this” with a straight face.
The Bet Every AI-Driven Company Is Quietly Making
Every company shipping AI-powered features is currently making an implicit bet: that the model’s behavior won’t change in a way that matters before someone notices and someone with authority decides what to do about it. Most of the time, this bet pays off, because most behavioral drift is small enough to go unnoticed or harmless enough to not matter.
But the bet is getting larger as AI systems take on more consequential roles — handling money, communicating directly with customers under the company’s name, making decisions that used to require a human signature. The size of the bet is rising. The number of people explicitly responsible for managing it is not.
Eventually, every company in this position has the meeting described at the start of this piece — the one where six competent people stare at a screenshot and none of them can explain what changed, because the org chart was never drawn with a box for the answer. The companies that come out ahead won’t be the ones with the best model. They’ll be the ones who drew the box before they needed it, instead of after.
The Org Chart Has No Box for “AI Behavior Owner” was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.