
The KV Cache Compression Race: TurboQuant vs OSCAR vs EpiCache
Long-context large language models (LLMs) face a memory bottleneck that has nothing to do with model weights. During decoding, transformers cache the key and value (KV) vectors for every token at every layer so they don’t have to recompute attention. This cache grows linearly with sequence length and batch size, and at long context with high concurrency it can dwarf the model’s own footprint.
Consider Llama-3.1-70B in BF16. Its KV cache costs about 0.31 MB per token (80 layers × 8 KV heads × 128 head-dim × 2 tensors × 2 bytes). At 128K tokens that is ~40 GB; at 1M tokens it exceeds 300 GB — more than the 140 GB of weights themselves. Worse, every newly decoded token has to stream the entire cache out of high-bandwidth memory (HBM), which makes decoding memory-bandwidth-bound rather than compute-bound. Shrinking the KV cache is therefore the most direct lever for cutting both cost and decode latency.
Current approaches fall into roughly five families: token eviction (H2O, SnapKV), quantization (KIVI, GEAR), low-rank projection (Palu), merging (KVMerger), and architectural sharing (MLA). Recent 2026 work has pushed hard on the ultra-low-bit quantization frontier. Google and NYU’s TurboQuant (ICLR 2026) and Together AI’s OSCAR attack the same problem from opposite directions, while Apple’s EpiCache tackles a problem neither one addresses.
Most KV quantizers are fighting the same underlying enemy: outlier channels — a handful of channels with disproportionately large magnitudes that dominate the quantization range and squeeze the rest of the signal into just a few representable levels. This is why naive INT2 quantization (only four levels) collapses to near-zero accuracy.
KIVI established the standard baseline here. It showed that key vectors have fixed outlier channels across tokens while value vectors do not, so it quantizes keys per-channel and values per-token. That tuning-free 2-bit recipe cuts end-to-end peak memory (weights included) by about 2.6×, and it is the reference point the newer methods build on.
TurboQuant: data-oblivious and theoretically optimal
TurboQuant handles outliers without ever looking at your data, in two stages:
- Stage one: each vector is randomly rotated so its coordinates become nearly independent and approximately Gaussian, which lets an optimal precomputed scalar (Lloyd–Max) quantizer be applied per coordinate.
- Stage two: a 1-bit Quantized Johnson–Lindenstrauss (QJL) transform is applied to the residual, giving a provably unbiased estimate of attention logits with no normalization-constant overhead.
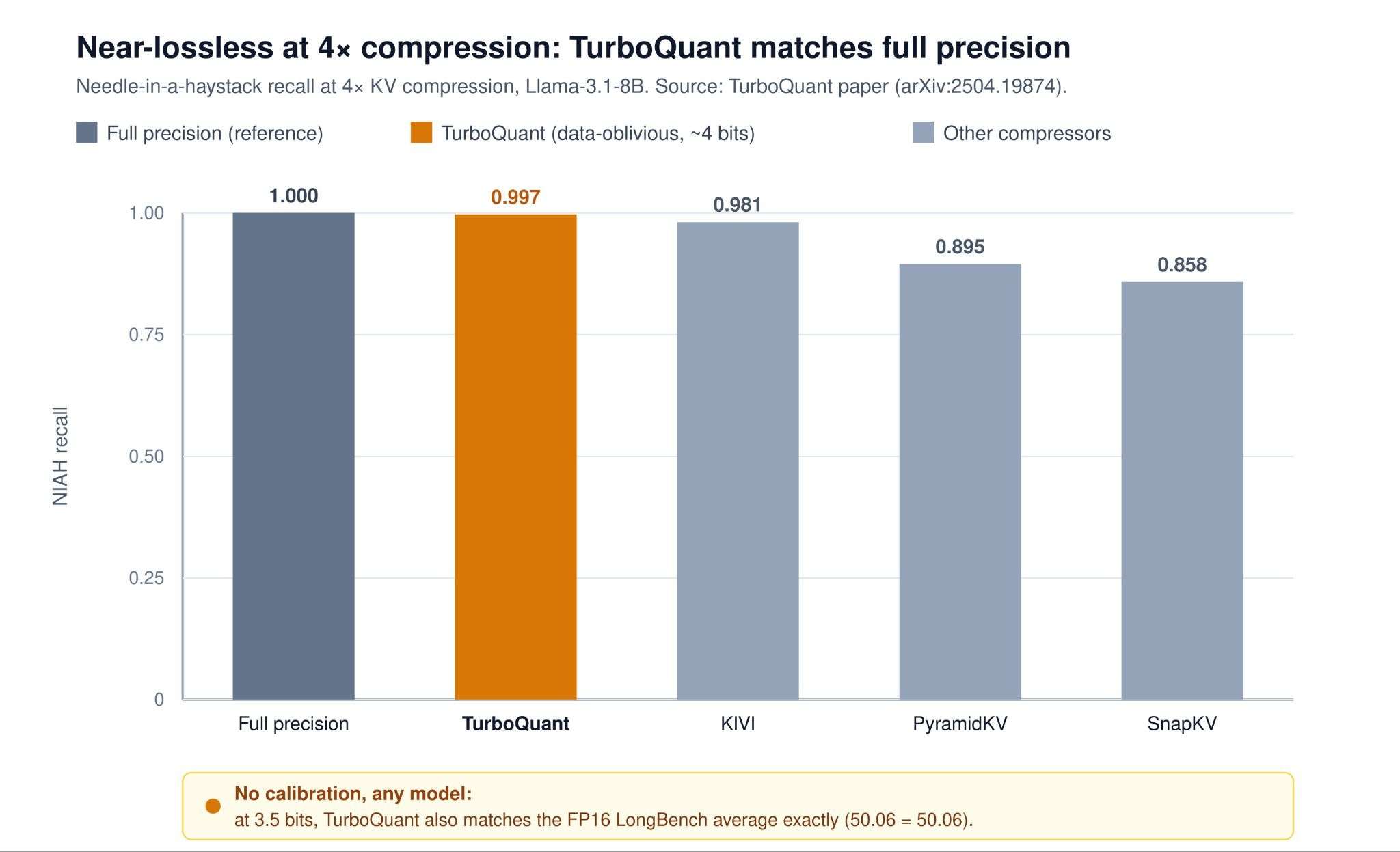
The selling point is theoretical: TurboQuant’s distortion is provably within a small constant factor (≈ 2.7×) of the information-theoretic lower bound. In practice it reaches essentially full-precision recall on Needle-in-a-Haystack at 4× compression, and the paper reports absolute quality neutrality at 3.5 bits and only marginal degradation at 2.5 bits per channel. Because it needs no calibration, it works on any model untouched and doubles as a fast vector-database quantizer.
One caveat worth flagging: the widely repeated “8× faster attention on H100” figure comes from Google’s blog, not the paper, and refers to a narrow attention-logit microbenchmark. TurboQuant’s documented sweet spot is the 3–4 bit near-lossless regime.
OSCAR: attention-aware and deployment-ready
OSCAR bets the opposite way. Its premise is that at INT2’s four levels, a data-oblivious rotation is the wrong tool — blindly smoothing ranges isn’t enough when there’s almost no precision to spare. So OSCAR computes an attention-aware rotation from a one-time offline calibration pass: keys are rotated into the eigenbasis of the query covariance, values into the score-weighted value covariance. A Hadamard transform plus a bit-reversal permutation then spread channel importance evenly across the quantization groups.
What sets OSCAR apart is that it ships as a complete system, not just an algorithm:
- Mixed-precision paged cache: sink and recent tokens stay in BF16 while the history compresses to INT2 — at 128K context only ~0.24% of tokens remain in BF16.
- Fused Triton kernels with full SGLang integration (paged-attention and prefix-cache compatible).
- Precomputed rotations (a “RotationZoo”) for Qwen3-4B/8B/32B, GLM-4.7-FP8, and MiniMax-M2.7 — no recalibration needed.
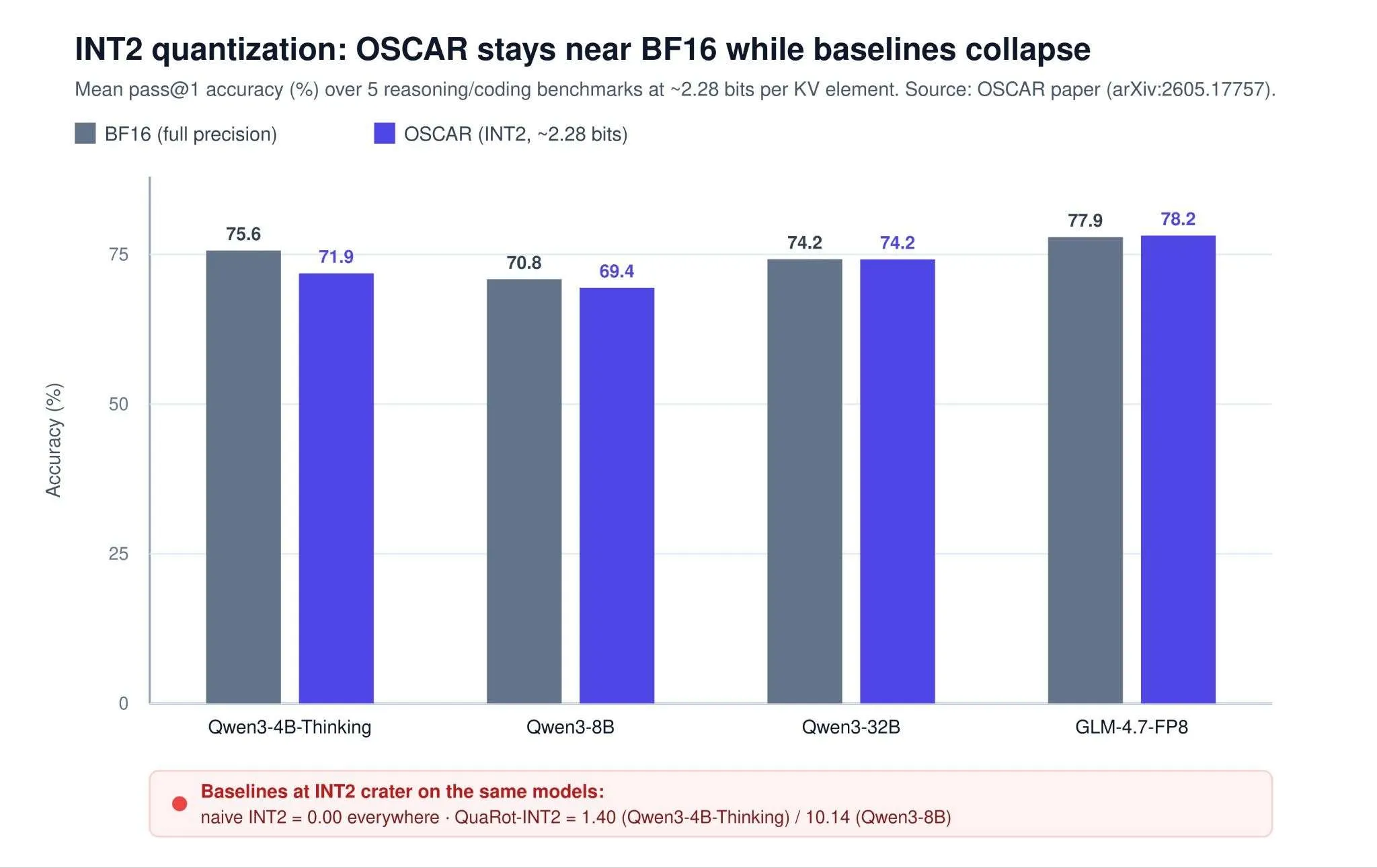
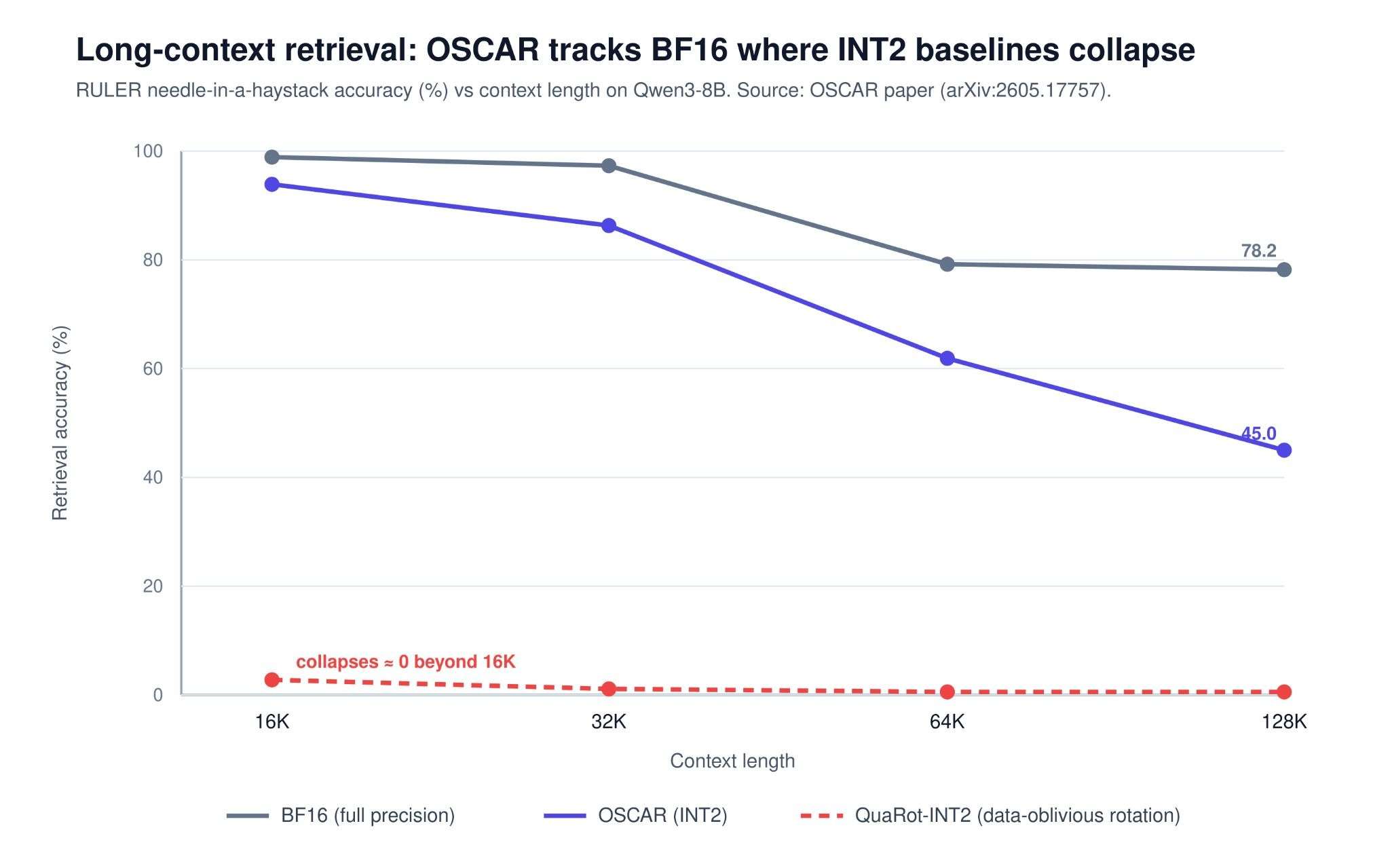
At an effective 2.28 bits, OSCAR lands within 1.42 points of BF16 on Qwen3-8B and is essentially on par on Qwen3-32B (a 0.02-point gap). On GLM-4.7-FP8 — where naive INT2 collapses to zero and data-oblivious baselines reach only low single digits — OSCAR matches BF16 and even edges slightly ahead on the reported benchmarks (within noise). Together AI reports up to 7.83× job-level throughput and roughly 8× KV-cache memory reduction at 100K context, with up to ~3× faster decoding.
So which one wins?
Neither — and that’s the honest answer. For deployable INT2 at 128K tokens on supported models, OSCAR is currently the only demonstrated option that doesn’t collapse, and it comes with production-ready SGLang support. For training-free, model-agnostic quantization in the 3–4 bit regime, TurboQuant offers far broader generality.
OSCAR’s paper reports that TurboQuant drops by more than 40 points at a comparable budget — but that evaluation runs inside OSCAR’s own framework, quantizes all layers, uses a single random seed, and operates well below TurboQuant’s intended bit-width, so it’s a weak basis for a head-to-head verdict. The more interesting possibility is that the two are complementary: pairing a calibration-aware rotation with an optimal scalar quantizer is a promising combination nobody has shipped yet. (Both teams have publicly noted the same idea.)
The third axis: EpiCache
TurboQuant and OSCAR are both built for a single long context. Neither handles extended multi-turn conversations, where history piles up across many exchanges. Apple’s EpiCache is a training-free KV-cache management framework aimed exactly at that gap:
- Block-wise prefill processes history in blocks to keep peak memory bounded.
- Episodic clustering segments the conversation into coherent semantic “episodes,” each with its own compressed cache.
- Episode-matched retrieval routes each query to the most relevant episode at inference time.
- Adaptive layer-wise budget allocation measures each layer’s sensitivity to eviction and distributes the memory budget accordingly.
Across LongMemEval, RealTalk, and LoCoMo, EpiCache reports up to 40% higher accuracy than eviction baselines, near-full-cache accuracy at 4–6× compression, and up to 3.5× lower peak memory (and ~2.4× lower latency). Because it decides which tokens to keep rather than how precisely to store them, it composes directly with OSCAR or TurboQuant for compounding savings.
Key Takeaways
- TurboQuant pushes the theoretical, model-agnostic frontier — the go-to for 3–4 bit near-lossless compression on any model.
- OSCAR leads on deployable INT2, with up to 7.83× throughput and ~8× memory reduction at 100K context on supported models.
- EpiCache solves conversational memory across turns — up to 40% accuracy gains over eviction and 3.5× lower peak memory — and composes with either quantizer.
- Pick by constraint: bit-width budget, model portability, or conversation length, then combine the orthogonal methods that fit. These approaches are more complementary than competitive.
Sources
- TurboQuant (arXiv 2504.19874)
- TurboQuant — Google Research blog
- OSCAR (arXiv 2605.17757)
- OSCAR code — FutureMLS-Lab/OSCAR
- EpiCache (arXiv 2509.17396)
- EpiCache code — apple/ml-epicache
- KIVI (arXiv 2402.02750)
The post The KV Cache Compression Race: TurboQuant vs OSCAR vs EpiCache appeared first on MarkTechPost.