
The Invisible Crisis in AI Engineering: Autonomous Agents and Smart Routing Architectures
AI applications are evolving fast. A few years ago, they were simple chatbots that answered questions. Today, they are becoming AI Agents — systems that make their own decisions and autonomously interact with tools like APIs, databases, and terminals. But when companies deploy these agents to production, they run into a jarring financial surprise: uncontrolled, rapidly growing token costs.
Solving a single complex problem with an AI agent can cost hundreds or thousands of times more than a simple API call. This financial pressure has given rise to a new engineering discipline called Smart Routing.
1. The Agent Economy: Why Do Costs Spiral Out of Control?
When a user chats with an AI on a website, the cost is easy to predict. Autonomous agents are a different story — they fundamentally change the cost structure for three reasons.
A. Statelessness and the Snowball Effect
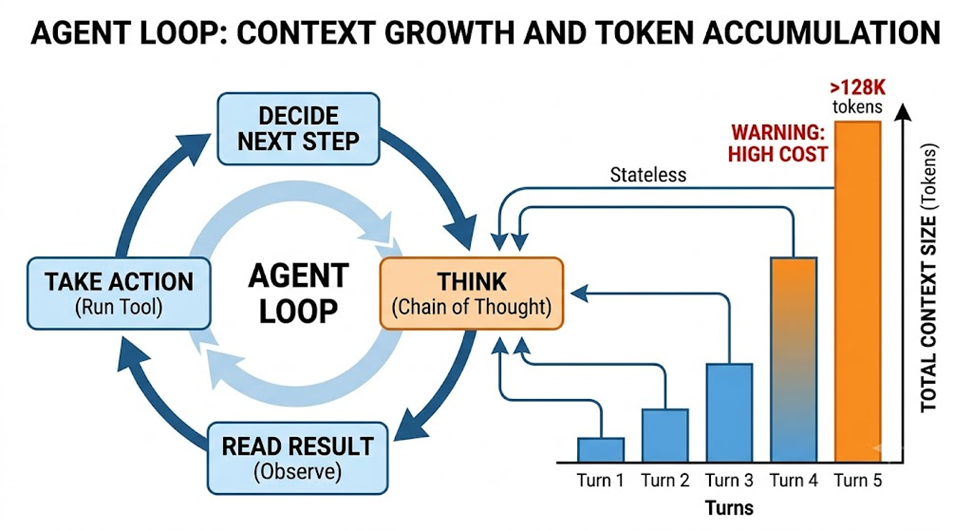
LLMs have no persistent memory. For an agent to execute a multi-step workflow — read a file, identify an error, test a fix, apply it — it must resend the entire conversation history to the model at every single step.
- Step 1: System instructions + user request ≈ 3,000 tokens
- Step 5: Instructions + request + tool outputs + reasoning ≈ 25,000 tokens
- Step 10: Context easily exceeds 100,000 tokens
By the end of the loop, the agent is resending the equivalent of a small book with every API call.
B. No “Human Brake”
Traditional chatbots are naturally throttled by human typing speed. An autonomous agent has no such brake. It can fire dozens of API calls per second. A system that scans a codebase or analyzes data automatically can burn through millions of tokens in minutes.
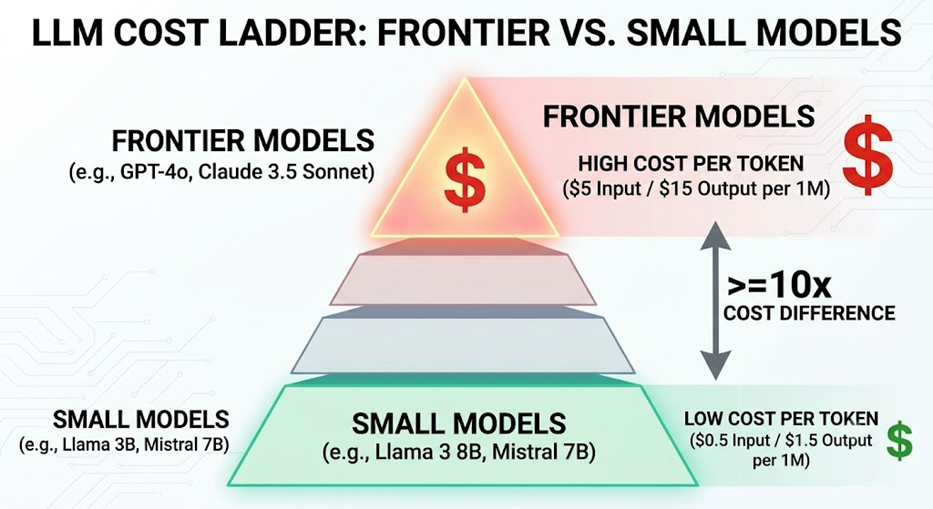
C. The “Most Expensive Model for Everything” Default
To minimize errors, most developers wire their entire system to the most powerful — and most expensive — frontier model on the market. The problem? The vast majority of what an agent actually does (formatting data, summarizing text, simple edits) doesn’t require that level of capability.
2. The Solution: Smart Routing Architecture
Smart routing introduces a middleware layer — a Gateway — that intercepts every incoming request, evaluates its complexity, cost sensitivity, and latency requirements, then routes it to the most appropriate model: the cheapest and fastest one that can reliably handle it.
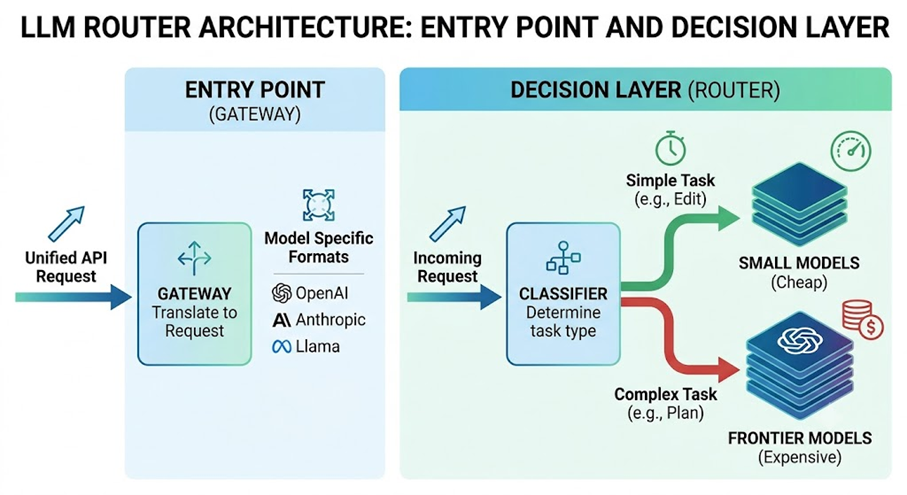
How Does a Router Work?
A well-designed routing system has two core components:
1. Unified API Layer (Gateway) This connects multiple AI providers — OpenAI, Anthropic, Google, or open-source models like Llama and Mistral — under a single standardized interface. Developers can swap models with a one-line change, without touching application logic.
2. Decision Engine This determines which model receives each request, typically using one of two strategies:
- Systematic (Mode-Based) Routing: The system declares what it’s doing at any given moment (e.g., mode: data_entry or mode: architectural_planning). The router maps that label to a pre-assigned model. This approach is fast, predictable, and adds zero latency.
- Predictive (Dynamic) Routing: Before the main model sees the request, a lightweight classifier scans the text, infers task complexity from semantic content, and dynamically selects the best route. A well-known example of this approach is the RouteLLM project, backed by Stanford and UC Berkeley.
3. Savings and Trade-offs
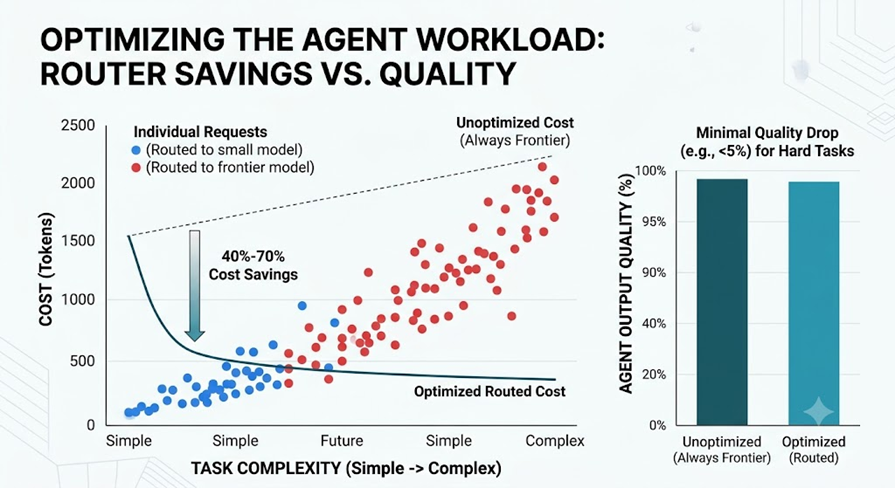
Smart routing can deliver 40–70% cost savings in live production systems. Research suggests that roughly 85% of tasks can be handled successfully by smaller, cheaper models (Small Language Models).
That said, there are genuine trade-offs to consider:
✅ Cost savings: You only pay frontier prices for genuinely hard tasks.
✅ Provider independence: No vendor lock-in to a single AI company.
✅ High availability: Automatic failover if a provider goes down.
⚠️ Added latency: The routing layer introduces a small overhead (milliseconds) per request.
⚠️ Context loss: Switching model families mid-conversation can cause one model to misinterpret another’s internal reasoning.
⚠️ Maintenance overhead: Dynamic routers require ongoing updates as models evolve.
4. Strategic Advice for Production Systems
Remember Jevons’ Paradox. When a resource becomes more efficient — when tokens get cheaper — consumption doesn’t decrease, it increases. Lower per-token costs won’t necessarily shrink your bill, because your agents will simply take on more work. Don’t optimize for cost-per-request in isolation; set a fixed monthly budget and work within it.
Measure token volume, not request count. The feature with the most clicks isn’t necessarily the one consuming the most tokens. Track total token volume (context size × call count), and prioritize optimization where consumption is actually highest.
Combine routing with prompt caching. Smart routing isn’t a silver bullet on its own. Pair it with prompt caching to avoid re-paying for large, repetitive system instructions on every call. These two techniques compound each other.
Don’t underestimate small models. Today’s open-source models — ranging from 8B to 70B parameters — are remarkably capable. When correctly fine-tuned or routed, they can match frontier model performance for a wide range of specific tasks.
Summary
The future of AI agents isn’t determined solely by raw model capability. It’s shaped by how efficiently we manage and orchestrate those models. Smart routing isn’t a nice-to-have optimization — it’s a foundational requirement that makes autonomous agent systems economically viable, operationally sustainable, and genuinely ready to scale.
The Invisible Crisis in AI Engineering: Autonomous Agents and Smart Routing Architectures was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.