
The Agentic Pipeline: Orchestrating Tools Without Context Bloat
How to chain SQL queries, Python sandboxes, and visual charts without ever showing the LLM the raw data.

The Chaining Anti-Pattern (The Problem)
Over the past three articles, we have successfully equipped our agent with isolated tools for memory (The Cache), compute (The Sandbox), and visual presentation (The Chart Engine).
The natural instinct for most developers at this stage is to simply dump all three of these tools into the agent’s prompt and let it figure out the rest. If a user asks, “Query the database for our Q3 transaction logs, run a regression analysis on the outliers, and draw a scatter plot,” we assume the agent will just use the tools in sequence.
It will. But it will also destroy your application in the process. I call this The Chaining Anti-Pattern, and it results in a catastrophic failure mode known as Token Ping-Pong.
The Token Ping-Pong Effect
When an LLM chains tools together naively, it acts as the physical courier for all the data. Let’s look at the actual token flow of a naive multi-tool execution:
- The Extraction: The agent calls execute_sql. The database returns 50,000 tokens of raw transaction data directly into the agent’s context window.
- The Compute: The agent realizes it needs to run a regression. It writes a Python script and calls execute_python(script, data=50,000_tokens). It has just passed the massive payload back out to the Sandbox.
- The Return: The Sandbox finishes the math and returns a slightly modified 50,000-token payload back into the context window.
- The Render: The agent now needs to draw the chart. It calls generate_chart(data=50,000_tokens). It passes the massive payload out for a third time.
In a single conversational turn, the agent has been forced to read, process, and re-transmit the exact same massive dataset multiple times.
The Architecture Collapses
If you build your pipeline this way, three things happen instantly:
- Latency Skyrockets: Passing 50,000 tokens back and forth between APIs takes time. Your Time-To-First-Token (TTFT) will stretch into minutes.
- Context Window Overflow: You will hit your token limit before the agent even reaches the Chart tool, causing the application to crash with a max_tokens_exceeded error.
- Cognitive Degradation: The LLM is essentially being used as a network router instead of a reasoning engine. Buried under the sheer weight of the data transport, it will lose track of the original user prompt and hallucinate the final step.
We do not want the LLM to carry the data. We only want it to direct the traffic.

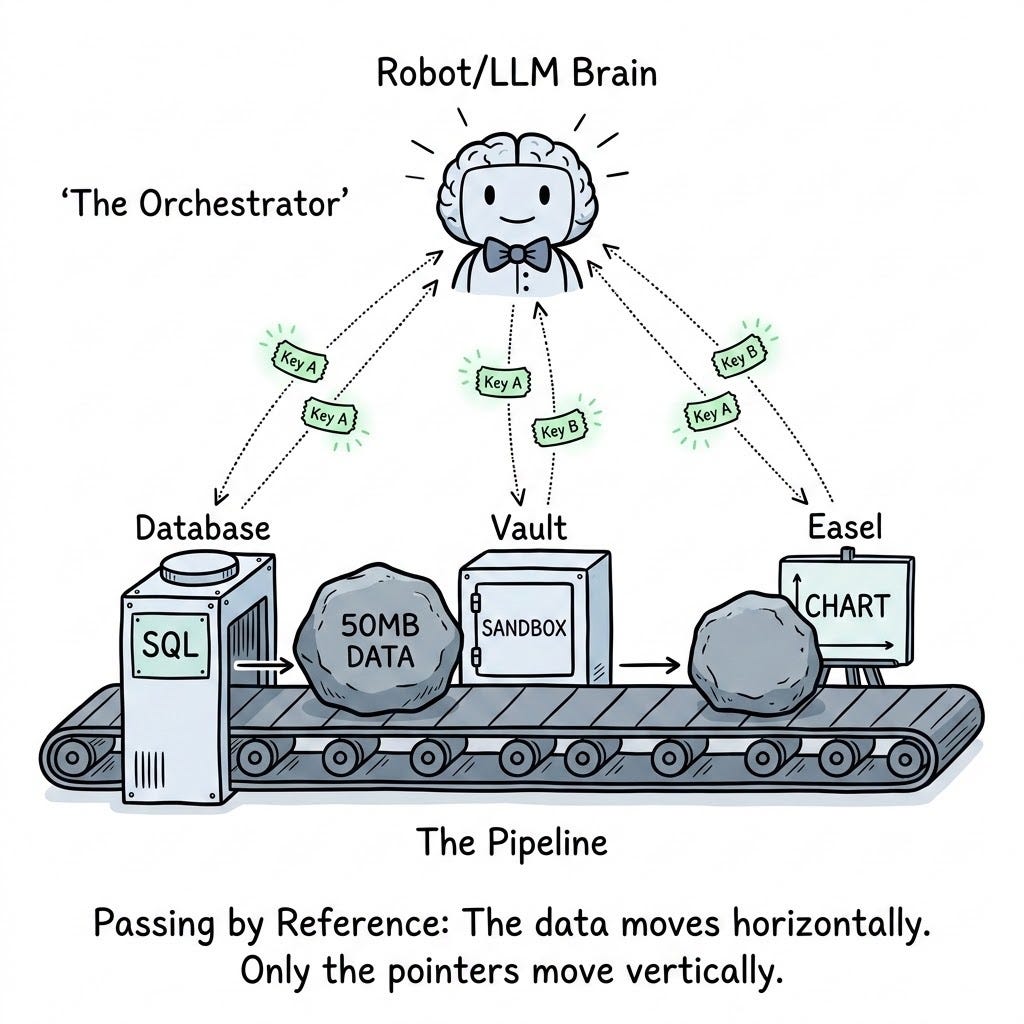
Passing by Reference (The Solution)
To solve the Token Ping-Pong effect, we must look to traditional computer science. When a standard software program needs to pass a massive object between two functions, it does not copy and paste the entire object into memory twice. It passes a memory address — a pointer.
We must enforce this exact paradigm for our AI agents. Instead of the agent carrying the data, the agent should only carry the keys.
We achieve this by taking the Session Cache we built in Article 1 and networking it directly to the Python Sandbox and the Chart Tool, effectively cutting the LLM out of the physical data transfer entirely.
The Orchestrated Token Flow
When you architect a “Pass by Reference” pipeline, the payload never touches the prompt. The workflow transforms into an elegant, highly efficient orchestration:
- The Extraction: The agent calls execute_sql. The database executes the query, but the middleware intercepts the 50MB return payload. It drops the data into the Session Cache and returns a tiny, 10-token string back to the LLM context window: “SUCCESS: Raw data saved to cache_key_alpha.”
- The Compute: The agent now knows where the data lives. It writes a Python script and calls execute_python(script, input_key=”cache_key_alpha”). The Sandbox boots up, internally fetches the massive dataset from the Cache, runs the regression, saves its new output back to the Cache, and tells the LLM: “SUCCESS: Regression complete. Results saved to cache_key_beta.”
- The Render: The agent, ready to present, calls generate_chart(input_key=”cache_key_beta”). The Chart Engine reaches into the cache, grabs the math output, draws the graph, and passes the UI render string back to the user.
The Contextual Liberation
By orchestrating the tools this way, the architectural benefits are staggering.
Your context window remains pristine. Instead of juggling 50,000 tokens per conversational turn, the LLM is only processing a few dozen tokens of metadata (“Data is here, math is here”). Token costs drop by over 95%. Latency becomes practically invisible because the API calls are transmitting strings instead of spreadsheets.
Most importantly, you eliminate the cognitive degradation of the model. Because the LLM is no longer buried under the sheer weight of reading raw JSON, it is free to dedicate 100% of its computational power to its primary job: reasoning, planning, and synthesizing the final answer for the human user.
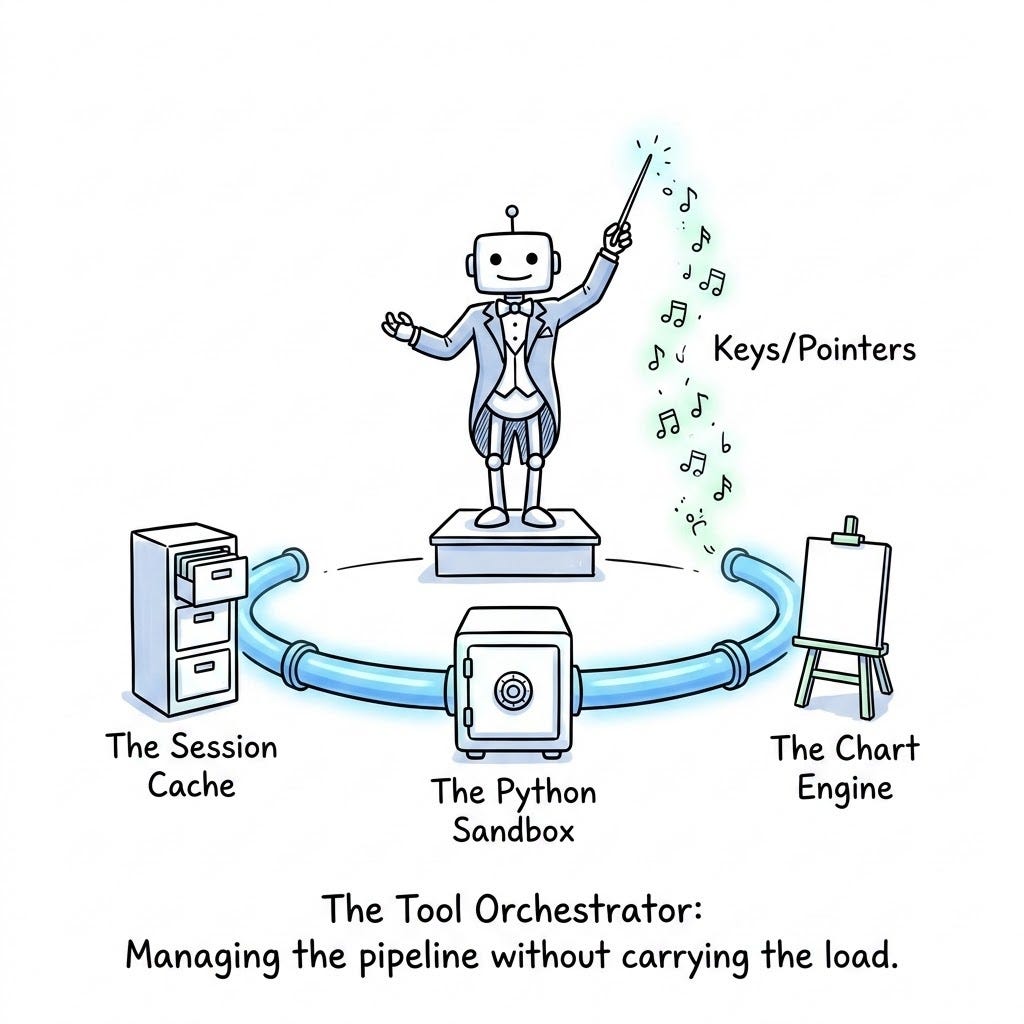
The Code Artifact: The Tool Orchestrator
We have established the theory of passing data by reference. Now, we must build the infrastructure that makes this invisible to the LLM.
To achieve this, we introduce the ToolOrchestrator. This middleware acts as the central nervous system of your agent. It intercepts every tool call before it executes, scans the arguments for cache keys, and dynamically injects the heavy data into the execution environment. When the tool finishes, the Orchestrator catches the heavy output, drops it in the cache, and passes a lightweight pointer back to the LLM.
Below is a Python implementation of this pipeline controller.
import json
from typing import Dict, Any
class ToolOrchestrator:
"""
The central nervous system of the Agentic Pipeline.
Intercepts tool calls, resolves pointers, and hides heavy data from the LLM.
"""
def __init__(self, cache_manager, sandbox, chart_engine):
self.cache = cache_manager
self.sandbox = sandbox
self.chart = chart_engine
def execute_tool(self, tool_name: str, arguments: Dict[str, Any]) -> str:
"""
Intercepts the LLM's tool request and manages the data flow.
"""
# 1. Pointer Resolution (The Magic)
# If the LLM passed a cache key, we swap it for the heavy data BEFORE execution.
resolved_args = self._resolve_pointers(arguments)
try:
# 2. Tool Execution
if tool_name == "execute_python":
# The Sandbox runs with the HEAVY data, not the key
raw_output = self.sandbox.execute_python(
code_string=resolved_args.get("script"),
injected_data=resolved_args.get("data") # This is the 50MB payload
)
# 3. Output Interception
# The Sandbox generated massive results. DO NOT send this to the LLM.
new_key = "cache_key_sandbox_output"
self.cache.write_to_cache(new_key, raw_output)
# 4. Contextual Liberation
# We return a tiny pointer back to the context window
return f"SUCCESS: Python execution complete. Results mathematically verified and saved to '{new_key}'."
elif tool_name == "generate_chart":
# The Chart Engine draws using the resolved heavy data
ui_payload = self.chart.generate_chart(
data_json=resolved_args.get("data"),
chart_type=resolved_args.get("chart_type"),
title="Requested Analysis"
)
return "SUCCESS: Chart rendered. UI Payload ready for user display."
else:
return f"ERROR: Unknown tool '{tool_name}'."
except Exception as e:
return f"ORCHESTRATION ERROR: {str(e)}"
def _resolve_pointers(self, arguments: Dict[str, Any]) -> Dict[str, Any]:
"""
Helper function: Scans LLM arguments for strings starting with 'cache_key_'
and physically replaces them with actual data from the Session Cache.
"""
resolved = {}
for key, value in arguments.items():
if isinstance(value, str) and value.startswith("cache_key_"):
# Fetch the massive payload from the desk quietly
resolved[key] = self.cache.read_raw_data(value)
else:
resolved[key] = value
return resolved
The Outcome
By orchestrating the tools this way, the architectural benefits are staggering.
Your context window remains pristine. Instead of juggling 50,000 tokens per conversational turn, the LLM is only processing a few dozen tokens of metadata (“Data is here, math is here”). Token costs drop by over 95%. Latency becomes practically invisible because the API calls are transmitting tiny strings instead of massive spreadsheets.
Most importantly, you eliminate the cognitive degradation of the model. Because the LLM is no longer buried under the sheer weight of reading raw JSON, it is free to dedicate 100% of its computational power to its primary job: reasoning, planning, and synthesizing the final answer for the human user.
Build the Complete System
This article is part of the Cognitive Agent Architecture series. We are walking through the engineering required to move from a basic chatbot to a secure, deterministic Enterprise Consultant.
To see the full roadmap — including Semantic Graphs (The Brain), Gap Analysis (The Conscience), and Sub-Agent Ecosystems (The Organization) — check out the Master Index below:
The Cognitive Agent Architecture: From Chatbot to Enterprise Consultant
The Agentic Pipeline: Orchestrating Tools Without Context Bloat was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.