
Sliding Windows Forget: Why Long-Running LLM Apps Need Memory Policy
Most long-running LLM failures are not pure reasoning failures. They are state-selection failures: the next model call gets incomplete, stale, or irrelevant context.
In short chats, appending recent messages often works. In persistent sessions, that breaks down because durable facts vanish, stale updates return, and routine traffic consumes the prompt budget.
The real question becomes:
Which pieces of prior state deserve to be in the next model call?
I built LLM-Context-Optimization-Engine to explore that question. It is a prototype that compares full history, sliding windows, summaries, retrieval, hybrid context, adaptive context selection, and importance-based memory retention.
The contribution here is not a new memory architecture. It is an inspectable benchmark harness that compares context policies before the model call and exposes how each one fails.
This problem is becoming more important as agent platforms move toward persistent memory. Once agents can remember across sessions, the hard question is not whether memory exists, but how stored state is selected, invalidated, trusted, and injected at inference time.
The short version:
- Sliding windows are cheap, but they forget durable facts.
- Full history maximizes recall, but carries stale and noisy evidence.
- Retrieval improves recall, but high recall can still poison the prompt if stale facts come with it.
- In a synthetic 10k-turn benchmark, importance-based selection retained 90.7% of current critical facts under a 600-message budget; sliding window retained 10.8%.
- The key lesson: long-running LLM apps need memory policy, not just memory storage.
This does not claim to solve long-term memory. It provides a controlled benchmark harness for comparing context policies and inspecting how they fail under limited prompt budgets.
Why Long-Running LLM Apps Fail
Before getting into implementation, the core problem is that different kinds of state compete for the same limited prompt budget.
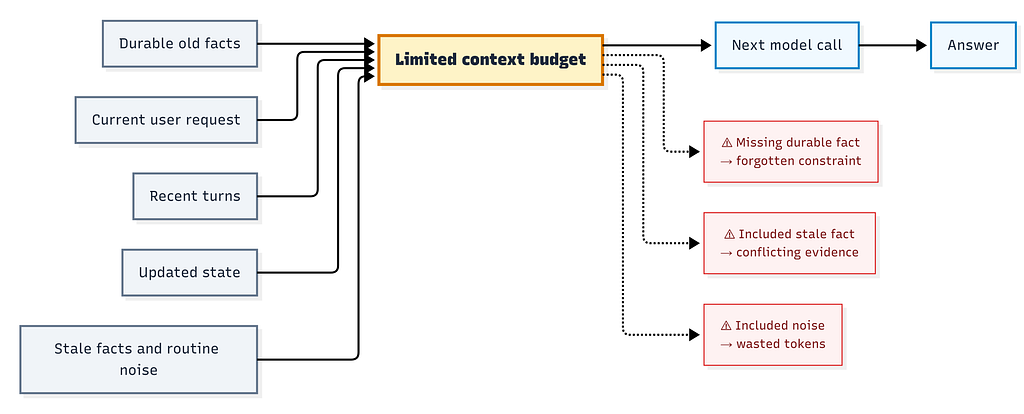
Old does not mean irrelevant. Recent does not mean sufficient.
A user preference from 200 turns ago can matter more than a recent routine message. A recent update can invalidate an older fact. A retrieved memory can be relevant and still dangerous if it brings stale evidence with it.
That is why long-running LLM systems need context policy, not just context storage.
A Concrete Failure Example
Imagine a long-running assistant session for project planning.
Early in the session:
Turn 18: The user’s preferred lunch option for offsites is vegetarian.
Later:
Turn 142: Updated preference: the user is now vegan, not just vegetarian.
Later still:
Turn 260: Project Atlas launch moved from Wednesday to Friday.
At turn 310, the user asks:
Can you plan the Friday launch lunch for Atlas?
The evidence needed for the answer is split across time. One fact is old but still valid, one fact supersedes an older preference, and one fact updates the current launch state.

Different policies fail differently.

This is the core issue: a fact can be old and still important, while a recent fact can be irrelevant. A memory policy has to rank facts, not just turns.
Why Common Policies Fail
Full history looks safe because it maximizes recall, but it can also carry stale and noisy evidence into the prompt.
Sliding windows are cheap and predictable, but they confuse recency with importance.
Summaries reduce token load, but compression can drift. A summary that drops a constraint has silently changed the application’s state.
Retrieval recovers older facts, but it is not automatically safe. A retriever can return the right fact and a nearby wrong fact in the same top-k set.
High recall is not enough if the prompt also contains stale evidence.
How State Becomes Context
The engine is organized around a single runtime path: store messages, index memories, decide which context sources to use, assemble the prompt, call the model, and record usage.

For a long session, the context builder can use recent messages, an incremental summary, retrieved prior facts, pinned source context, memory metadata, and the current user query.
The default configuration keeps 15 recent messages, retrieves up to 6 prior snippets, uses a minimum retrieval score of 0.08, and caps summaries at 2,000 tokens. SQLite keeps the benchmark reproducible. Production would need a different storage and latency profile.
How Memories Were Scored
Every stored message is indexed and scored. The scorer is deterministic and rule-based, so the benchmark is easy to inspect.
The scoring function combines recency, durable wording, user preferences, entity mentions, retrieval frequency, update terms, episodic-event terms, length, role, stale markers, and noise markers.
The simplified scoring formula looks like this:
recency = exp(-age / 500)
retrieval_frequency = log1p(retrieval_count) / log(10)
score = role_signal * (
0.13 * recency
+ 0.18 * persistence
+ 0.18 * preference
+ 0.15 * entity_importance
+ 0.14 * retrieval_frequency
+ 0.12 * contradiction_risk
+ 0.06 * episodic_event
+ 0.04 * length_signal
)
score -= 0.22 * noise
score -= 0.32 * stale_marker * (1.0 - retrieval_frequency)
The weights are manually chosen, not optimized. The scorer is intentionally brittle: useful because it is inspectable, not because these weights should be deployed unchanged.
That caveat matters. If a synthetic benchmark generates critical facts with recognizable preference, update, and entity patterns, then a rule-based scorer that looks for those signals has an advantage. A production evolution would likely feed these features into a lightweight reranker or classifier trained on real user corrections.
Action and layer assignment are also rule-based: preserve high-scoring durable memories, compress mid-value entity/event memories, evict low-value memories, and place items into working, episodic, semantic, or archived layers.
Benchmark 1: Token And Cost Growth
The first benchmark simulated a 100-turn conversation with 200 messages. Costs were estimated with the configured x-ai/grok-4-fast pricing in the project.
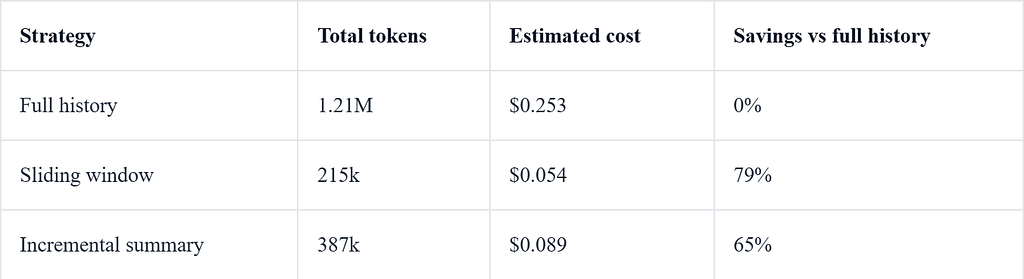
This benchmark is not an interesting result. It only establishes the cost pressure that forces context selection. The harder question is what each policy forgets or pollutes.
Benchmark 2: Evidence Quality Before The Model Call
The memory-quality benchmark uses eight deterministic stress cases: long-range preference recall, temporal updates, multi-hop project state recall, abstention, distractor retrieval, similar-entity disambiguation, recent overrides, and summary drift.
This is not a human evaluation, nor is it LLM-as-judge. The scoring is deterministic:
quality = required_term_recall - 0.35 * conflict_pressure
required_term_recall checks whether the assembled context includes the required evidence.
conflict_pressure checks whether known stale or conflicting evidence is also present.
The benchmark evaluates the context package before the model call.
That matters because if the assembled context is wrong, the answer is already compromised.
Rounded results:
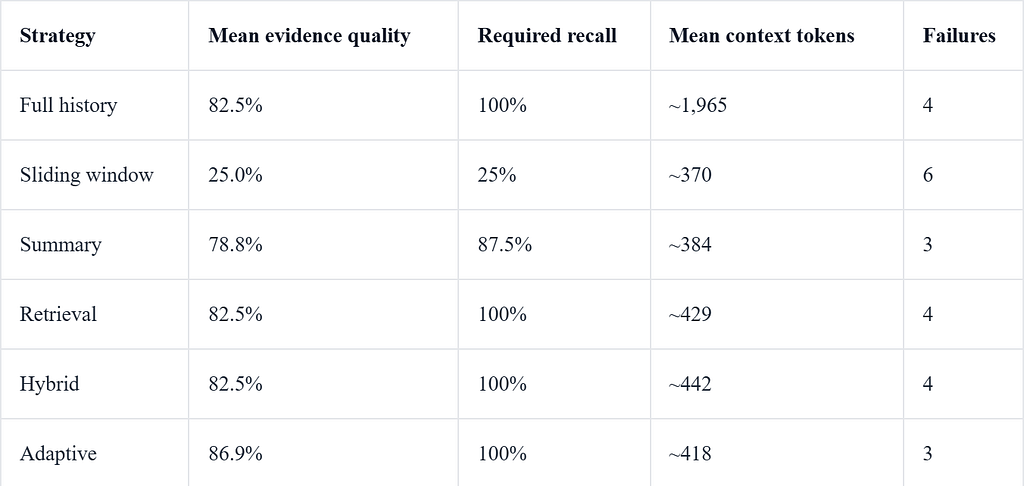
The useful part is the failure pattern: full history had high recall but carried stale evidence; sliding windows were cheap but lost long-range facts; summary failed when compression omitted an early constraint; retrieval recovered old facts but could bring stale evidence back.
Benchmark 3: 10k-Turn Memory Scaling
The strongest result came from the memory-scaling benchmark.
The synthetic session generator creates routine filler plus durable facts, evolving preferences, entity drift, retrieval noise, forgotten constraints, and stale updates. I tested 1k, 5k, and 10k turns across three policies: full archive, sliding window, and importance-based selection.
At 10k turns, the benchmark had roughly 200 current critical facts, 500 stale facts, 9.3k noise messages, and a 600-message budget for both sliding window and importance selection.
Rounded 10k-turn results:
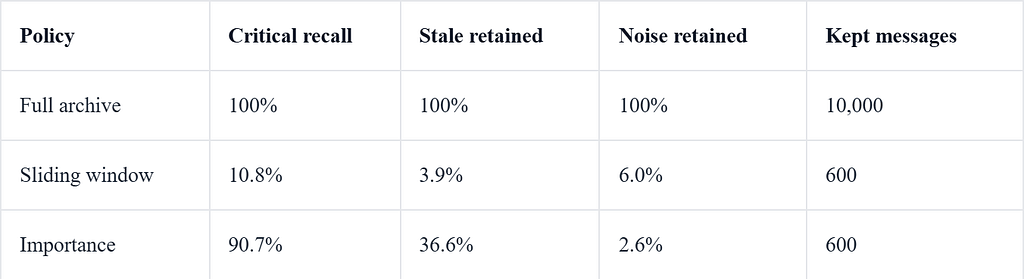
In a controlled synthetic benchmark designed to test structural state drift, importance-based selection retained 90.7% of current critical facts under the same 600-message budget, where sliding window retained 10.8%.
I treat that result narrowly. The synthetic generator created facts with recognizable preference, update, and entity patterns, and the rule-based scorer explicitly used similar signals. So this is not evidence that the exact scorer generalizes to messy real-world conversations. It is evidence that pure recency is a weak baseline when durable state, stale updates, and routine noise are spread across a long session.
The limitation is also visible: the important selection retained too many stale facts. It did much better than recency on critical recall and noise suppression, but stale memory still needs better contradiction handling, supersession tracking, and explicit invalidation.
Retrieval: Recall Helps, But Conflict Still Matters
The retrieval benchmark is smaller, so I treat it as supporting evidence rather than the main claim. It uses ten cases, including semantic paraphrase retrieval, entity abbreviation, stale launch-region evidence, near-name entity collisions, and distractor badge-color snippets.
Retrieval supports lexical BM25, embedding-only retrieval, and a weighted hybrid. For tests and CI, the project can use deterministic hash embeddings. For stronger retrieval checks, it can use local embedding models or OpenAI embeddings.
On the current suite:
- BM25 and the deterministic hash baseline recovered most relevant evidence, but missed some semantic cases.
- BGE and OpenAI embedding-only retrieval achieved 100% Recall@6 on this synthetic benchmark suite.
- Precision@6 was still low, around 18.5%, because the top six often included extra non-relevant snippets.
- Hybrid retrieval did not beat BGE embedding-only with the current weights.
The retrieval failure is usually not “nothing was found.” It is often “the right fact was found together with a nearby wrong fact.”
One typical failure pattern looks like this:
Query:
Which launch region belongs to Project Atlas?
Relevant memory:
Project Atlas launches in the north region.
Potential distractor:
Project Atala launches in the south region.
Failure mode:
A lexical or weak entity match can pull both Atlas and Atala into context.
The correct fact is present, but the prompt now also contains a nearby conflicting entity.
“Hybrid” is not automatically better. Weighting lexical and vector signals needs tuning, and retrieval quality should be measured separately from generation quality. In production, I would not dump top-k retrieval directly into the prompt; I would add stale-aware reranking, entity matching, and contradiction checks before context assembly.
Lightweight Query-Aware Routing
The router is intentionally lightweight. It is not an LLM router, a trained classifier, or an agentic planner. It uses keyword hints plus retrieval confidence.
MEMORY_QUERY_HINTS = (
"remember", "recall", "earlier", "previous", "mentioned",
"favorite", "prefer", "who is", "what is", "when did"
)
BROAD_QUERY_HINTS = (
"summarize", "recap", "so far", "overall",
"state", "status", "current", "all"
)
CURRENT_STATE_HINTS = ("current", "latest", "now", "today", "updated")
The rule is simple: current-state queries avoid broad retrieval because retrieval can pull stale state; memory/fact queries use retrieval when evidence is strong; broad recap queries can combine summary and retrieval.
Production Recommendations
A production memory system should not have one memory mode. It should route between recent context, summaries, retrieval, pinned facts, and invalidation metadata based on query intent.
One practical mapping looks like this:
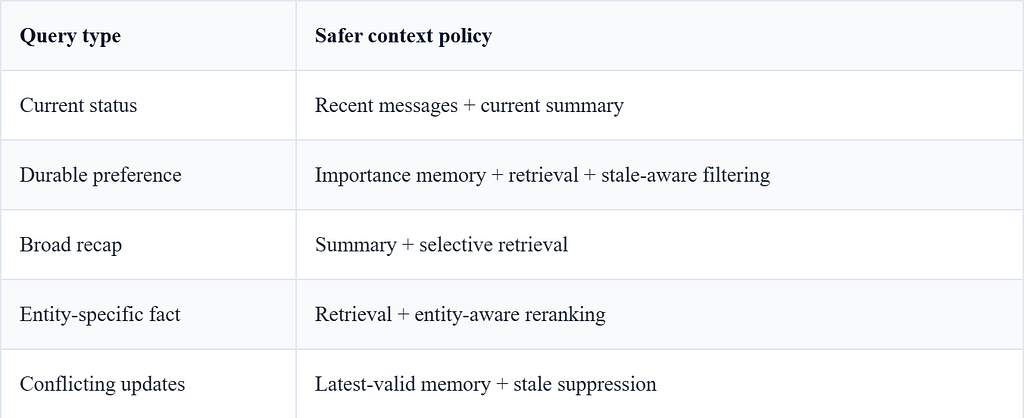
In production, I would separate the system into four paths: synchronous context assembly, asynchronous memory extraction, background embedding/index refresh, and offline evaluation. The online path should only do cheap routing, top-k retrieval, stale-aware reranking, and final prompt assembly. Expensive summarization and memory consolidation should happen asynchronously.
The likely cost centers are retrieval, reranking, summary refresh, and full request assembly. SQLite vector scanning is fine for this benchmark, but a production system would need an ANN-backed vector store such as pgvector or Qdrant, Redis or another cache layer, background workers, and latency measurements for each stage.
For some memory types, retrieval is the wrong abstraction. Durable user attributes such as dietary restrictions, timezone, role, or account preferences may belong in a structured state, not only in semantic memory. A production system should combine structured profiles, summaries, retrieval, and invalidation metadata rather than relying on one memory store.
Threats To Validity
The biggest threat to validity is that the synthetic generator and the rule-based scorer may reward the same signals. If critical facts are written with preference, update, and entity markers, a rule-based scorer can recover them more easily than it would recover messy real-world memories.
That is why I treat the 91% result as evidence that recency is weak, not proof that this scorer generalizes.
The benchmark conversations are synthetic, the quality metric is intentionally simple, the retrieval suite is small, and SQLite vector scanning is not production retrieval infrastructure. Those limitations are real, but the result was still useful: context selection needs to account for importance, staleness, retrieval quality, and query intent.
Takeaway
Long-running LLM systems need a memory policy, not just memory storage.
Storing everything is easy. Deciding what should enter the next model call is the hard part.
For factual memory questions, retrieval may be worth the risk. For current-state questions, recent messages and summaries may be safer. For durable preferences, importance-based selection can beat pure recency under a fixed budget.
The larger lesson is that context assembly changes model behavior. If the system gives the model stale, missing, or conflicting evidence, the answer is already compromised before generation starts.
In long-running LLM apps, context assembly is not plumbing. It is application logic.
References
- Anthropic: Effective Context Engineering for AI Agents
- Anthropic: Managing Context on the Claude Developer Platform
- Lost in the Middle: How Language Models Use Long Contexts
- Chroma: Context Rot
- MemGPT: Towards LLMs as Operating Systems
- LangChain Memory Overview
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- LLMLingua: Compressing Prompts for Accelerated Inference
Code and benchmark scripts: GitHub link
Sliding Windows Forget: Why Long-Running LLM Apps Need Memory Policy was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.