")
RoPE Demystified: How Rotary Position Embeddings Actually Work (With GPU optimized PyTorch Code)
Introduction
Imagine trying to read a book where all the words are written on separate pieces of paper, thrown into a hat, and mixed together. To understand the story, you would have to pull out each word, guess where it belongs, and mentally reconstruct the sentences.
This is exactly how a vanilla Transformer model views human language.
When the landmark paper “Attention Is All You Need” dropped in 2017, it fundamentally shifted the AI landscape by introducing Self-Attention. This mechanism allowed neural networks to process all tokens in a sequence simultaneously in parallel, completely shattering the slow, sequential bottlenecks of older Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks.
However, this massive leap in training speed came with a severe structural cost: Transformers are inherently blind to word order.
The Flaw of the 2017 Baseline
To fix this spatial blindness, the original authors introduced Sinusoidal Absolute Positional Encodings. The concept was straightforward: generate a unique static wave vector for each position index (pos in {0, 1, 2, …]) and literally add it directly to the semantic word embeddings:
For even coordinate dimensions:

For odd coordinate dimensions:

While this mathematical patch successfully allowed early models like BERT and GPT-2 to understand text order, it introduced two major engineering bottlenecks:
- Semantic Corruption: High-dimensional vector spaces are incredibly delicate geometric constructs. Forcing a positional signal into semantic word coordinates via raw addition alters the fundamental geometry of the tokens. The network has to dedicate valuable internal weight parameters just to “disentangle” what a word means from where it is located.
- The Context Wall: Absolute embeddings are hardcoded to a fixed coordinate system. If you train a model on a sequence length of 512 tokens, position 1024 is a complete mathematical mystery to it. The model cannot generalize to longer texts at inference time without being completely retrained from scratch.
Enter RoPE (Rotary Position Embeddings)
To bridge the gap between absolute order and flexible relative distances, Jianlin Su and his co-authors introduced Rotary Position Embeddings (RoPE) in 2021.
Instead of treating position as an additive tax, RoPE treats position as a geometric rotation. It maps pairs of numbers within a word vector onto a 2D complex plane and gently rotates them by an angle that scales with the token’s position index.
Today, RoPE has become the undisputed gold standard for state-of-the-art open-source Large Language Models. If you look under the hood of Meta’s LLaMA 3, Mistral, Qwen 2.5, or Google’s Gemma, you won’t find a single additive positional embedding. They all run on RoPE.
In this comprehensive guide, we will break down the exact mathematical mechanics behind this rotation wizardry, strip away the intimidating block-diagonal matrix formulas, and look at a highly optimized Interleaved Slicing Trick in PyTorch from scratch—maximizing memory bandwidth utilization and hardware parallelization per token.
The Intuition: A Multi-Frequency Clock
To understand how RoPE encodes both absolute position and relative distance simultaneously, stop thinking about high-dimensional vectors for a second. Instead, imagine a room filled with traditional wall clocks.
Every word vector in a Transformer is broken down into pairs of numbers. In RoPE, each pair of coordinates is assigned its own unique clock. If your model has an attention head dimension of 64, every token carries a keyring of 32 different clocks.
Token Embedding: [ x1, y1, x2, y2, x3, y3, ... ]
│ │ │ │ │ │
└───┘ └───┘ └───┘
Clock 1 Clock 2 Clock 3
When a token enters the model, its position index determines how many minutes pass on its clocks:
- A token at position 1 moves the hands forward by 1 tick.
- A token at position 5 moves the hands forward by 5 ticks.
This is how absolute position is captured. But here is the secret sauce: every clock in the keyring runs at a completely different speed (frequency).
The Gear System (Frequencies)
- Clock 1 (The Fast Clock): Ticks rapidly. For every position index, its hand rotates by a large angle (for example, 45° per token). It is highly sensitive to immediate, local context.
- Clock 2 (The Medium Clock): Ticks slower. It might only rotate by 15° per token.
- Clock 32 (The Snail Clock): Ticks incredibly slowly. It barely moves a fraction of a degree per token. It is designed to capture long-range relationships across thousands of tokens.
How this solves the “Context Wall”
Because the hands move smoothly along a continuous circle rather than jumping along a fixed absolute coordinate grid, the model doesn’t care if a sequence length is 512 or 8192.
If the model is trained on a context length of 512, it has learned how the clock hands behave relative to one another. If it suddenly encounters position 1024 during inference, the hands just keep spinning smoothly around the clock face. The geometric relationship remains entirely intact.
Why this creates “Relative Distance” Understanding
Imagine Token A is at position 2, and Token B is at position 5. The distance between them is 3.
When the self-attention mechanism compares Token A and Token B (via dot product), it is essentially measuring the angle between their clock hands. Because a rotation of 5 ticks minus a rotation of 2 ticks always leaves a net difference of 3 ticks, the model can naturally deduce exactly how far apart the words are, regardless of where they appear in the sentence.
From 2D Rotation to RoPE
Let’s focus closely on the underlying math of how we rotate vectors in 2D space.

As noted, RoPE doesn’t treat a word vector as one massive entity. Instead, it breaks a d-dimensional embedding into d/2 independent 2D chunks (pairs of coordinates like x and y). For any given pair, we represent it as a vector z on a complex plane with an initial radius r and angle α:

When a token appears at a specific position index m, we want to rotate this vector by a position-dependent angle θ. To do this, we multiply it by a standard 2D rotation matrix:

By expanding this matrix multiplication, we get the explicit coordinates:

Using the trigonometric sum identities for sine and cosine:

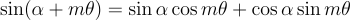
This simplifies perfectly to a vector rotated cleanly by (α + θ). When you apply a different rotation speed (frequency) to each pair of coordinates across the entire embedding, you get RoPE!
The target base frequencies θi for each coordinate pair are precomputed as:
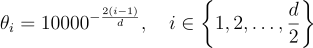
As the channel index i increases toward d/2, the frequency value drops drastically. This ensures our “multi-frequency gear system” works perfectly across the entire hidden dimension.
PyTorch Implementation: The Interleaved Slicing Trick
By replacing sequential Python loops with vectorized 4D tensor broadcasting, shifting strided slicing to contiguous split-half blocks, and leveraging non-persistent PyTorch state buffers, we transition RoPE from an intimidating mathematical equation into an elite, hardware-coalesced engine designed for maximum accelerator memory bandwidth.
Our precomputed RoPE frequency cache lives permanently as a stable 2D tensor of shae(Seq_Len, Head_Dim). However, when processing data through a vectorized multi-head attention block, your hidden states (x) are a 4D tensor of shape (Batch_Size, Num_Heads, Seq_Len, Head_Dim).
To multiply them together, PyTorch evaluates dimensions from right to left. By explicitly expanding the 2D cache into 4D (1, 1, T, head_size) using the broadcasting bridge snippet (if cos.ndim == 2:), we communicate perfectly with PyTorch’s execution engine without allocating duplicate memory footprint.
Here is the fully optimized, production-grade implementation of the vectorized Multi-Head Attention module featuring precomputed buffers and the split-half rotation layout:
https://medium.com/media/2210c8579c12a35a912eeb36c2e53450/href
The Trick Explanation: Split-Half Contiguity
The slicing trick is a pure optimization of hardware memory access.
In the original paper’s raw mathematical definition, elements are rotated in adjacent pairings: [x_1, y_1, x_2, y_2]. Implementing this natively requires a strided memory lookup pattern (like using 0::2 and 1::2 strides), which forces the GPU to jump across scattered memory blocks. This disrupts memory coalescing and degrades hardware execution speed.
The slicing trick completely avoids this. It rearranges the coordinate pairing axis by splitting the entire vector cleanly down its middle boundary into two continuous halves: [x_1, x_2, … , y_1, y_2].
half = x.shape[-1] // 2
x1, x2 = x[..., :half], x[..., half:]
x_rotated = torch.cat((-x2, x1), dim=-1)
Because x1 and x2 are completely continuous blocks of memory, the GPU can leverage its high-bandwidth vector registers to copy, negate, and concatenate the chunks instantly. The underlying dot-product mechanics of self-attention remain mathematically identical, but the training throughput scales significantly.
Conclusion: Your Attention Is All I Need
The complete module code, training configuration setups for both classic transformers and RoPE-specific versions, along with full training scripts for this MiniGPT architecture are fully open-source and available in my repository:
GitHub – NeuralAlchemist-ai/MiniGPT
The project is currently in active development, and I will be implementing FlashAttention alongside Multi-Head Latent Attention (MLA) in the upcoming phases to push this model’s performance to its limits. Stay tuned!
RoPE Demystified: How Rotary Position Embeddings Actually Work (With GPU optimized PyTorch Code) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.