 Suite That Turns LLM Internal Features into Practical Development Tools")
Qwen AI Releases Qwen-Scope: An Open-Source Sparse AutoEncoders (SAE) Suite That Turns LLM Internal Features into Practical Development Tools
Large language models are remarkably capable, yet frustratingly opaque. When a model misbehaves — generating responses in the wrong language, repeating itself endlessly, or refusing safe requests — AI devs have very few tools to diagnose why it happened at the level of internal computations. That’s the problem Qwen-Scope is built to solve.
Qwen Team just released Qwen-Scope, an open-source suite of sparse autoencoders (SAEs) trained on the Qwen3 and Qwen3.5 model families. The release comprises 14 groups of SAE weights across 7 model variants — five dense models (Qwen3-1.7B, Qwen3-8B, Qwen3.5-2B, Qwen3.5-9B, and Qwen3.5-27B) and two mixture-of-experts (MoE) models (Qwen3-30B-A3B and Qwen3.5-35B-A3B).
What is a Sparse Autoencoder, and Why Should You Care?
Think of a sparse autoencoder as a translation layer between raw neural network activations and human-understandable concepts. When an LLM processes text, it produces high-dimensional hidden states — vectors with thousands of numbers — that are difficult to interpret directly. An SAE learns to decompose these activations into a large dictionary of sparse latent features, where each input activates only a small subset of features. Each of those features tends to correspond to a specific, interpretable concept: a language, a style, a safety-relevant behavior.
Concretely, for each backbone and transformer layer, Qwen-Scope trains a separate SAE to reconstruct residual-stream activations using a sparse set of latent features. The SAE encoder maps each activation to an overcomplete latent representation, and a Top-k activation rule keeps only the largest k latent activations for reconstruction (with k set to either 50 or 100 in the release). For dense backbones, the SAE width scales to 16× the model hidden size; for MoE backbones, standard SAEs use 32K width (16× expansion), and wider SAEs up to 128K width (64× expansion) are also released to capture finer-grained representation structure.
The result is a layer-wise feature dictionary for every transformer layer across all seven backbones. One important technical detail: Qwen3.5-27B is the only backbone whose SAEs are trained on the instruct variant; all other six backbones use their base model checkpoints.
Four Ways Qwen-Scope Changes the Development Workflow
1. Inference-Time Steering
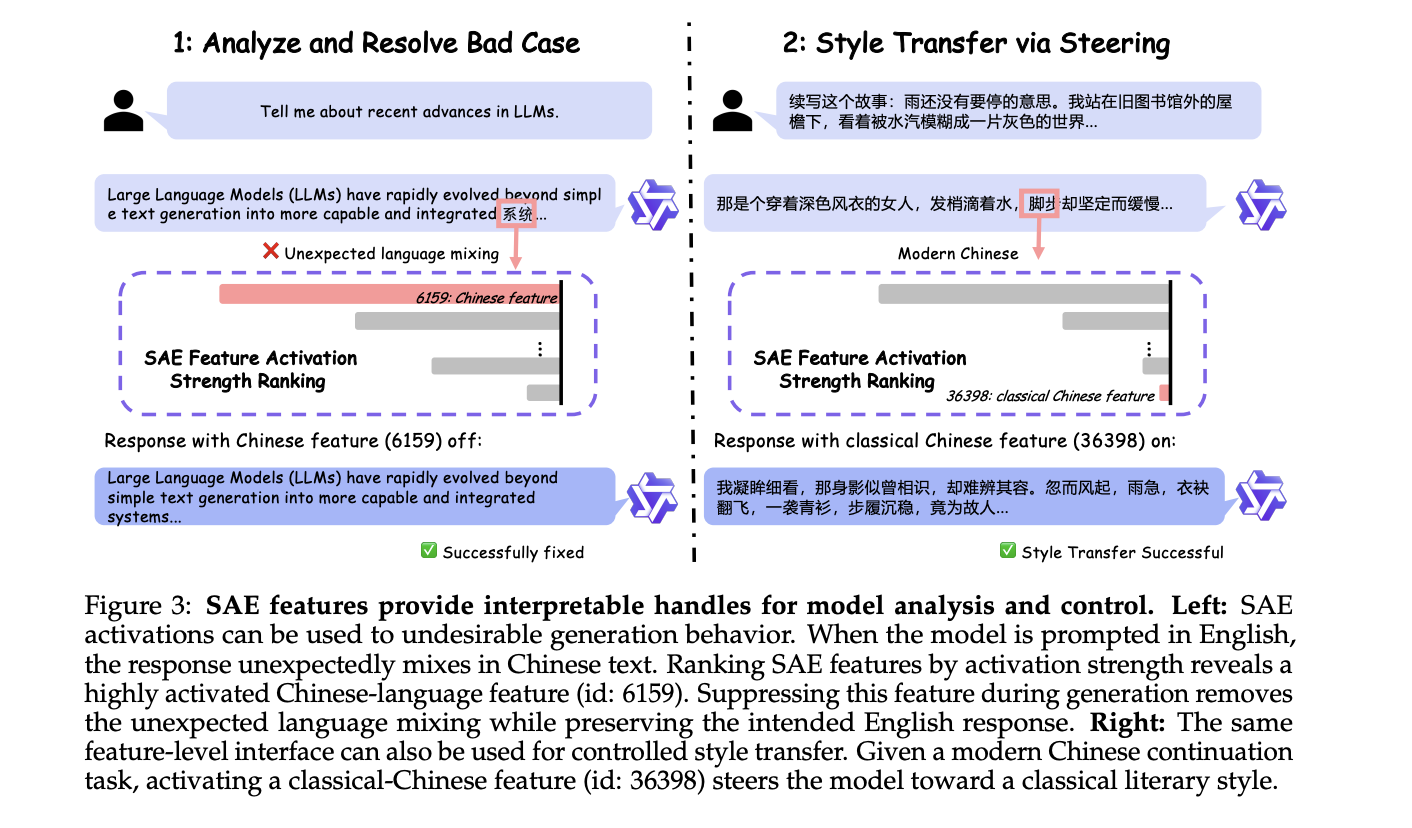
The most immediate application is steering — influencing model output without modifying any model weights. The idea rests on a well-supported hypothesis: high-level behaviors are encoded as directions in the model’s internal representation space. By adding or subtracting a feature direction from the residual stream at inference time using the formula h' ← h + αd, where h is the hidden state, d is the SAE feature direction, and α controls strength, engineers can push the model toward or away from specific behaviors.
The research team demonstrates two case studies on Qwen3 models. In the first, a model prompted in English unexpectedly mixes in Chinese text. Ranking SAE features by activation strength reveals a highly activated Chinese-language feature (id: 6159). Suppressing it during generation removes the language mixing entirely. In the second, activating a classical-Chinese feature (id: 36398) successfully steers a story-continuation task toward a classical literary style. Both examples required zero weight updates.
2. Evaluation Analysis Without Running Models
Evaluating LLMs typically means running many forward passes across large benchmark datasets — expensive in compute and time. Qwen-Scope proposes a cheaper alternative: using SAE feature activations as a representation-level proxy for benchmark analysis.
The core insight is that when a model processes a benchmark sample, the SAE decomposes its activation into a sparse set of active features, each interpretable as a ‘micro-capability.’ A benchmark whose samples all activate the same features is redundant; two benchmarks that activate largely overlapping feature sets are similar. The research team defines a feature redundancy metric that achieves a Spearman rank correlation of ρ ≈ 0.85 with performance-based redundancy across 17 widely-used benchmarks — including MMLU, GSM8K, MATH, EvalPlus, and GPQA-Diamond — without running a single model evaluation. The analysis also reveals that 63% of GSM8K’s features are already covered by MATH, suggesting that evaluation suites containing MATH can safely omit GSM8K with minimal loss of discriminative information.
The framework also extends to inter-benchmark similarity: the research team measures feature overlap between pairs of benchmarks to determine whether they probe the same capabilities. After controlling for general model ability by partialing out MMLU scores, the partial Pearson correlation between feature overlap and performance-based similarity across 28 benchmark pairs improves to 75.5%, providing evidence that feature overlap captures benchmark-specific capability similarity rather than just general model quality. This has a direct practical implication: benchmarks with low mutual feature overlap probe distinct capabilities and should both be retained; benchmarks with high overlap are candidates for consolidation.
3. Data-Centric Workflows: Toxicity Classification and Safety Data Synthesis
SAE features also prove effective as lightweight classifiers. The research team builds a multilingual toxicity classifier across 13 languages using a simple two-stage pipeline: identify SAE features that fire more frequently on toxic examples than clean ones (on a small discovery set), then apply an OR-rule over those features on held-out test data — no additional classifier head, no gradient-based fitting. On English, this achieves an F1 score above 0.90 on both Qwen3-1.7B and Qwen3-8B. The research team further shows that features discovered in English transfer meaningfully to other languages without rediscovery — performance declines with linguistic distance (strongest for European languages like Russian and French, weaker for Arabic, Chinese, and Amharic), and scaling to Qwen3-8B improves both the level and stability of cross-lingual transfer. Crucially, using only 10% of the original discovery data still recovers about 99% of classification performance, demonstrating strong data efficiency.
On the synthesis side, the research team introduces a feature-driven safety data synthesis pipeline: identify safety-relevant SAE features that are missing from existing supervision, generate prompt-completion pairs designed to activate those features, and verify retention in feature space. Under a matched budget, feature-driven synthesis achieves 99.74% coverage of the target safety feature set, compared to the substantially lower coverage achieved by natural sampling or random safety-related synthesis. Adding 4k feature-driven synthetic examples to 4k real safety examples produces a safety accuracy of 77.75 — approaching the performance of training on 120k safety-only examples.
4. Post-Training: Supervised Fine-Tuning and Reinforcement Learning
Perhaps the most technically novel contribution is using SAE features as signals during training, not just inference.
For supervised fine-tuning, the research team addresses unexpected code-switching — where multilingual LLMs spontaneously produce tokens in an unintended language. Their method, called Sparse Autoencoder-guided Supervised Fine-Tuning (SASFT), first identifies language-specific features via a monolinguality score, then introduces an auxiliary regularization loss that suppresses those feature activations during training on non-target-language data. Across five models spanning three model families — Gemma-2, Llama-3.1, and Qwen3 — and three target languages (Chinese, Russian, and Korean), SASFT achieves over 50% reduction in code-switching ratio in the majority of experimental settings, with complete elimination in certain configurations (e.g., Qwen3-1.7B on Korean), while maintaining performance on six multilingual benchmarks.
For reinforcement learning, the research team tackles endless repetition — a low-frequency but disruptive failure mode where models loop in repeated content. Standard online RL rarely encounters repetitive rollouts, so it can’t learn a strong corrective signal. Qwen-Scope addresses this by using SAE feature steering to synthetically generate one repetition-biased rollout per training group, which is then incorporated as a rare negative sample in the DAPO RL pipeline. The result: repetition ratio drops sharply and consistently across Qwen3-1.7B, Qwen3-8B, and Qwen3-30B-A3B, while general benchmark performance remains competitive with vanilla RL.
Check out the Paper, Weights, and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
The post Qwen AI Releases Qwen-Scope: An Open-Source Sparse AutoEncoders (SAE) Suite That Turns LLM Internal Features into Practical Development Tools appeared first on MarkTechPost.