
N-Grams and Markov Assumptions: The First Predictive Models of Language
Before language models could generate essays, answer questions, or imitate conversation, they had to solve a much smaller problem.
Given a few words, what word is likely to come next?
That question sounds modest now. But it was one of the earliest serious entry points into language intelligence. Because once you ask a machine to predict the next word, you are no longer treating language as a static object. You are treating it as a sequence that unfolds in time.
That shift matters.
Earlier ideas in NLP often focused on representing text: counting words, comparing documents, building vocabularies, measuring frequency. But prediction introduces a different challenge. The machine must now make a guess while the sentence is still in motion. It must use what it has already seen to estimate what should come next.
This is where one of the first concrete predictive frameworks entered the story:
n-grams.
They were simple. They were elegant. They were surprisingly useful. And they also revealed, very early, why language is harder than local pattern matching.
The first predictive instinct
Suppose you read the phrase:
“peanut butter and …”
Even without thinking much, your mind already expects a few likely continuations. Maybe jam. Maybe jelly. Maybe bread. Some completions feel natural; others feel strange. Now imagine teaching this intuition to a machine.
The earliest solution was beautifully direct:
look at a large body of text, count how often word sequences occur, and use those counts to estimate what usually comes next.
If the phrase “peanut butter and jam” appears many times, and “peanut butter and engine” appears never, then the machine should assign higher probability to jam than to engine.
That is the basic spirit of n-grams. Language prediction begins as counting.
What is an n-gram?
An n-gram is simply a sequence of n consecutive words.
A unigram is one word: the
A bigram is two words: the cat
A trigram is three words: the cat sat
A 4-gram is four words: the cat sat there
And so on.

The idea is not just to store these sequences, but to use them for prediction. If you are trying to predict the next word, you look at the recent words and ask:
How often did this local pattern occur before, and what usually followed it?
So if your current context is: “I want to drink”
a trigram-based or 4-gram-based model might search its training data for similar sequences and estimate which words most often came next:
water, tea, coffee, and so on.
In other words, an n-gram model tries to predict the future of a sentence from a short slice of its past.
From counts to probabilities
This is where the idea becomes more mathematical. Suppose we want the probability of seeing the word tea after the phrase: “I want”
A bigram model would simplify the task and ask only:
How often does tea follow want?
A trigram model would ask:
How often does tea follow I want?
So the model estimates probabilities from counts like this:

That may look formal, but the idea is simple. If the phrase “I want tea” appears 50 times, and “I want” appears 200 times, then:

So the model says there is a 25% chance that tea comes next after I want.
This was the first real machinery of next-word prediction:
not meanings, not deep understanding, not abstract reasoning — just statistics over local sequences.
And that was already powerful enough to matter.

Why this was a genuine breakthrough
It is easy to underestimate n-grams now because they feel primitive compared to modern models. But conceptually, they made an important move.
They treated language as something that unfolds one step at a time.
That is a major shift. A sentence is no longer just a bag of words. It becomes a path.
And prediction becomes the task of estimating where that path is likely to go next. This changed the framing of language technology. Instead of merely asking, “What words are in this document?”, we began asking, “Given what has already happened, what is likely to happen next?”
That predictive framing eventually leads toward neural language models, RNNs, LSTMs, transformers, and everything that follows. But at the beginning, the machine’s memory was tiny. And that tiny memory was formalized through one of the most famous simplifying assumptions in language modeling: the Markov assumption.
The Markov assumption: a small memory for a large problem
The Markov assumption says, in effect:
To predict the next word, you do not need the entire past. You only need a limited recent window.
That is a huge simplification.
Because in real language, the meaning of the current word may depend on something that happened many words earlier. Or even many sentences earlier. But if we try to use the entire past every time, the problem becomes computationally explosive.
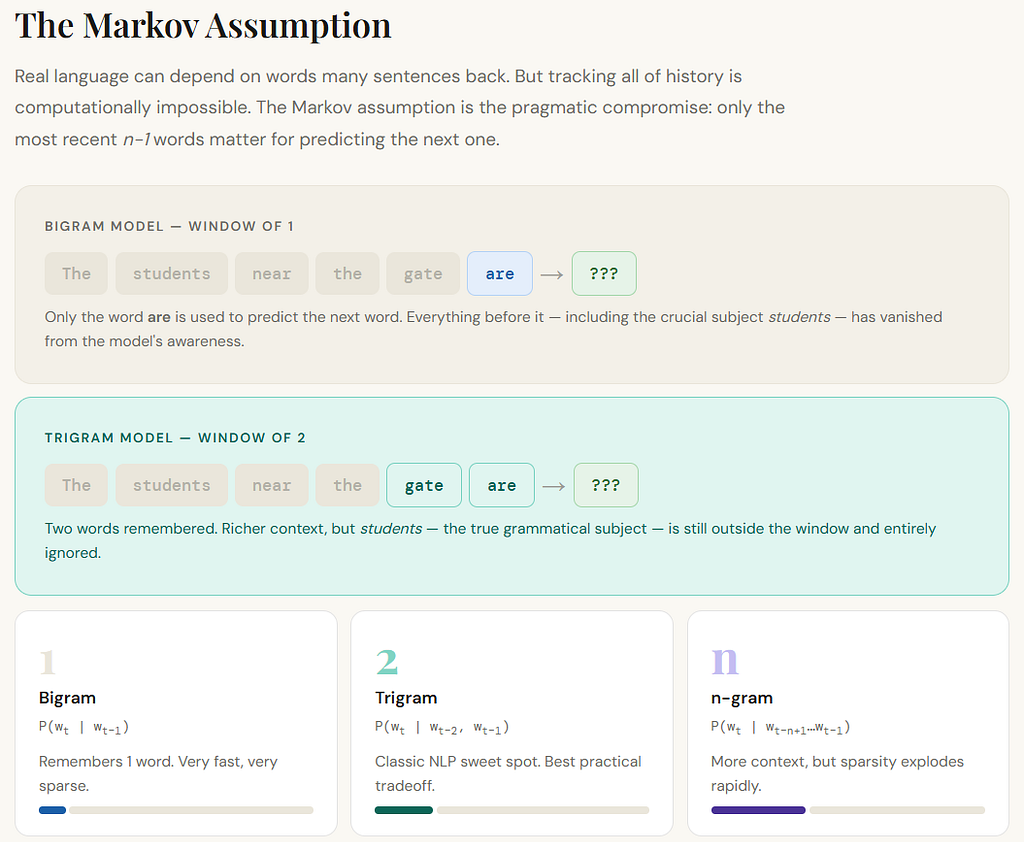
So early models made a compromise.
A bigram model assumes that the next word depends only on the previous one word.

A trigram model assumes that the next word depends only on the previous two words.
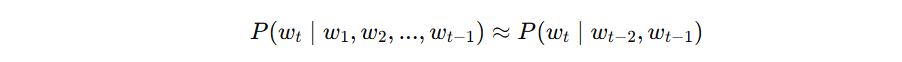
More generally, an n-gram model assumes that the next word depends only on the last n-1 words.
This is the Markov idea applied to language: the recent local past is treated as enough. And sometimes that works surprisingly well. If the phrase is:
“New York is”
then the next word probably does depend strongly on the last couple of words.
If the phrase is: “peanut butter and”
the local context is already very informative. So the Markov assumption was not foolish. It was practical. But language is not always local. And that is where the cracks begin.
Why short windows help — and fail
N-grams work best when language behaves locally.
Some patterns are indeed short-range:
“United States of”
“as a result”
“machine learning model”
“once upon a”
These are predictable because short fragments carry strong regularity.
But real language is full of dependencies that stretch further.
Consider this sentence:
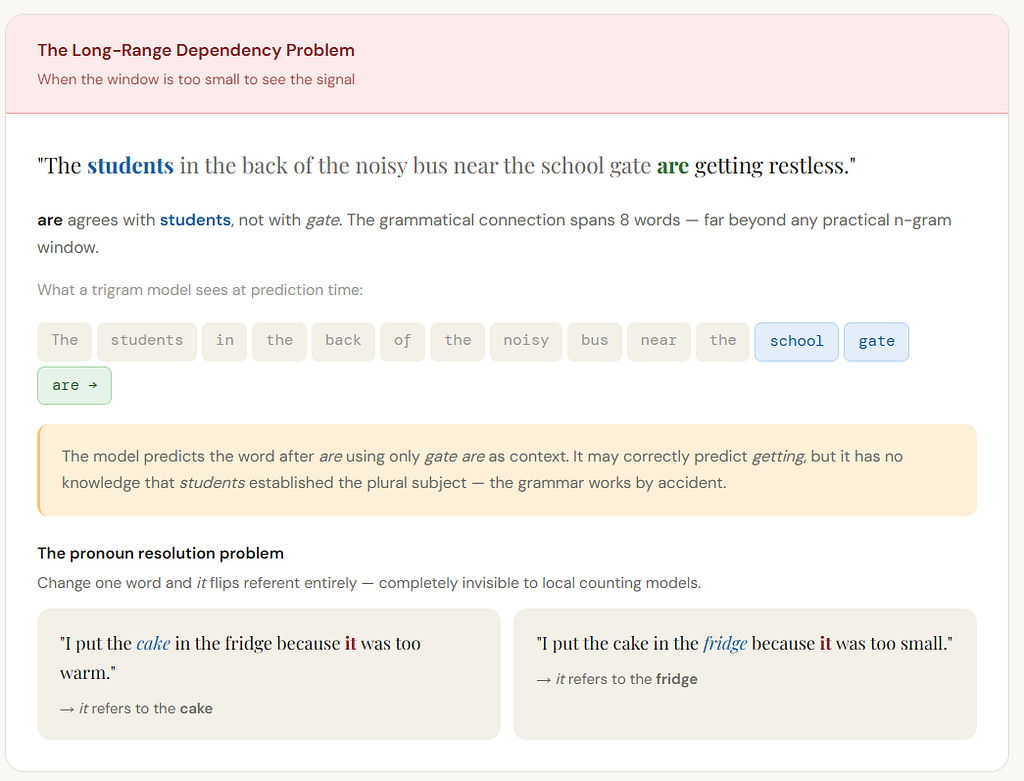
The students in the back of the noisy bus near the school gate are getting restless.
The verb are agrees with students, not with bus or gate. A short-window model may get confused because the relevant connection is not simply between adjacent words. The important relationship survives across interruption.
Or take this:
I put the cake in the fridge because it was too warm.
What was too warm? The cake. Now change one word:
I put the cake in the fridge because it was too small.
Now it refers to the fridge.
The nearby words alone do not fully settle meaning. The sentence must be interpreted as a structured whole.
This is one of the deep lessons that n-grams exposed:
language is not just a chain of neighboring words.
It contains dependencies, agreements, references, and meanings that may stretch beyond a short local window.
So even though n-grams were the first predictive models of language, they also revealed why prediction is harder than frequency over fragments.
The sparsity problem
There was another problem, and it was brutal.
Even if language were mostly local, the number of possible word sequences grows extremely fast.
Suppose your vocabulary has 10,000 words.
Then the number of possible bigrams is:
10,000 × 10,000 = 100 million
The number of possible trigrams is:
10,00⁰³ = 1 trillion
And most of those combinations will never appear in your training text.
That means your model will constantly face sequences it has never seen before.
This is called sparsity.
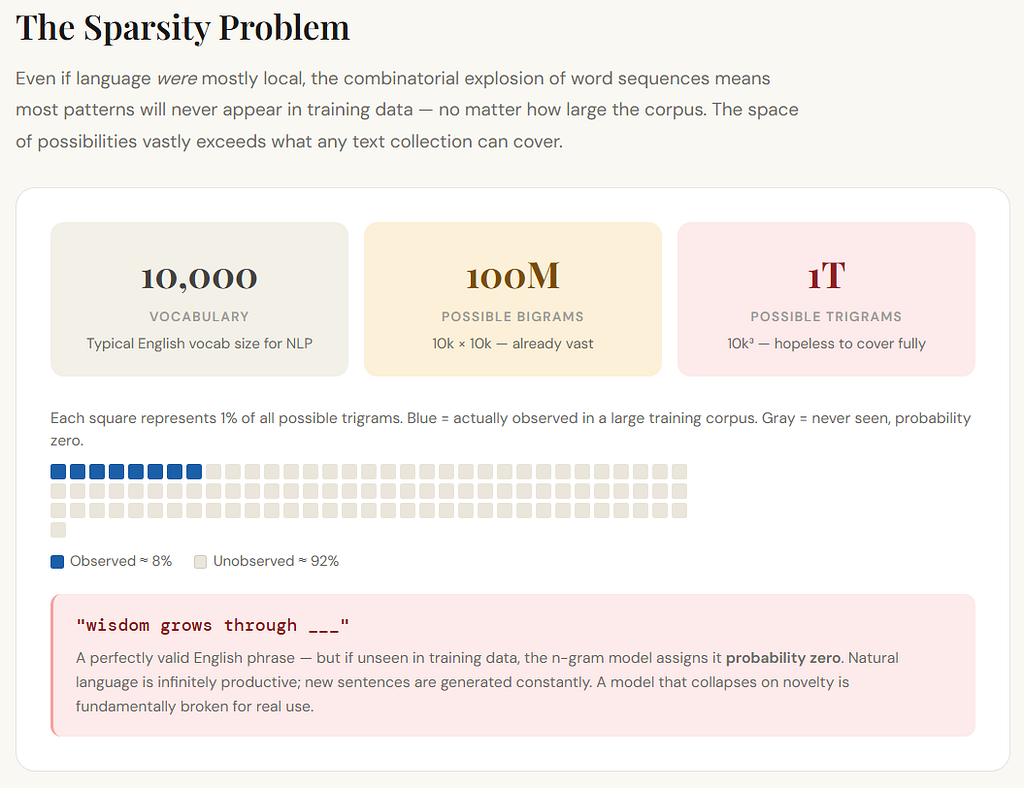
The data is sparse because the space of possible sequences is enormous, but the actual observed examples are limited.
So if your trigram model encounters:
“wisdom grows through”
and it has never seen that exact phrase before, it may assign zero probability to perfectly reasonable continuations.
That is disastrous.
Because natural language is productive. People constantly create sentences that have never appeared before. A useful language model cannot collapse every time it meets novelty.
But n-gram models were tied to exact observed sequences. If the pattern was unseen, the model had very little to say.
This is one of the reasons later methods had to move beyond raw counting into distributed representations and learned generalization.
Why counts alone are not enough
At first glance, counting seems rational.
If something happened often before, maybe it is likely to happen again.
And that is true to some extent.
But counts do not understand similarity.
Suppose the model has seen:
“the dog barked loudly”
many times,
but has never seen:
“the puppy barked loudly”
A count-based n-gram model treats these as different sequences. It does not automatically know that dog and puppy are related.
That is a huge limitation.
Humans generalize because we do not store each phrase as an isolated fragment. We sense relationships between words. We know that similar words can behave similarly in similar contexts.
N-grams do not naturally have that ability.
They store surface patterns, not deeper semantic relations.
So they can be good at memorizing local habits of language, but weak at generalizing meaningfully beyond what they have directly observed.
This is the pressure that eventually pushed NLP toward embeddings and neural language models.

A helpful intuition: n-grams as local memory
One useful way to understand n-grams is this:
they give the machine a very short memory.
A bigram model remembers one step back.
A trigram model remembers two steps back.
A 5-gram model remembers four steps back.
That is all.
So the model is always peeking through a tiny rear-view mirror while trying to move forward through language.
Sometimes that is enough.
Often it is not.
Because real understanding may require remembering the subject introduced many words ago, the topic introduced sentences ago, or the broader discourse of the entire paragraph.
N-grams do not really track that.
They do not build an internal evolving representation of meaning.
They just match short windows against remembered counts.
That was the first workable predictive machinery. But it was not yet a true theory of flowing context.

Why this stage still matters
Even today, n-grams matter conceptually because they teach several permanent lessons.
First, they show that language modeling can be framed as next-word prediction.
That idea never disappeared. Modern language models still predict tokens.
Second, they show that probability can be estimated from experience.
The model becomes a statistical learner from text.
Third, they reveal the first serious limits:
short memory, sparsity, weak generalization, and the failure of purely local context.
So n-grams are important not because they solved language, but because they made the problem concrete.
They were the first machinery that could say:
“I have seen patterns before. Based on those patterns, this continuation seems more likely than that one.”
That is the seed of language modeling.
But it is still a shallow seed.
Because language is not merely repetition of nearby fragments. It is structure unfolding through time, with memory, dependency, ambiguity, and meaning that often exceed the local window.
And once researchers truly felt that limitation, the next question became unavoidable:
What kind of model can carry context forward more intelligently than a fixed short window?
That question leads directly toward neural language models, recurrent networks, and the long struggle to build memory into sequence processing.
The real answer to our guiding question
So how did we first try to implement next-word prediction?
We did it by counting short word sequences in large text corpora, estimating conditional probabilities from those counts, and assuming that only a limited recent context mattered.
That is the world of n-grams and Markov assumptions.
It was the first serious predictive model of language.

It taught us that local context is useful.
It taught us that prediction can be statistical.
And it taught us, very quickly, that language is too rich to be captured by short windows alone.
That is why this stage matters.
It is the first time language stopped being merely stored and started being anticipated.
Memory hook:
N-grams tried to predict language by remembering only a tiny nearby window — and that is exactly why they worked a little, but understood very little.
N-Grams and Markov Assumptions: The First Predictive Models of Language was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.