
Harness in AI Agents
A harness in AI agents is the runtime and control plane that turns a raw model into something that can actually do work. In Anthropic’s wording, an agent harness or scaffold is the system that enables a model to act as an agent by processing inputs, orchestrating tool calls, and returning results, while OpenAI describes the harness as the control plane around the model that owns the loop, tool routing, approvals, tracing, recovery, and run state. LangChain summarizes the same idea as “Agent = Model + Harness,” meaning the model provides intelligence and the harness supplies state, tools, feedback loops, and enforceable constraints.
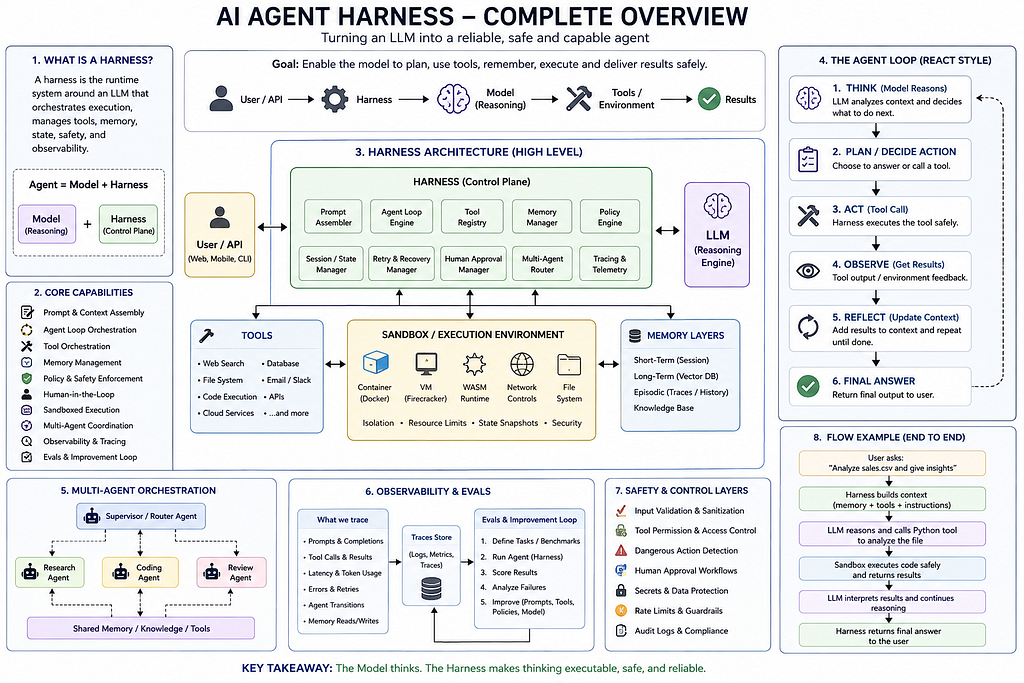
Modern AI agents are not just Large Language Models (LLMs). A raw model alone cannot reliably execute workflows, call APIs, maintain state, recover from failures, coordinate tools, enforce permissions, or operate safely in production systems.
The missing layer between the LLM and the real-world execution environment is called the Harness.
The harness is one of the most important architectural concepts in modern agentic systems. Companies like Anthropic and OpenAI increasingly emphasize that the actual intelligence of an AI agent comes not only from the model itself, but from the surrounding orchestration runtime.
A harness transforms:
LLM → Autonomous Operational Agent
Without a harness, a model is simply generating text.
With a harness, the model becomes capable of:
- Planning
- Tool usage
- Multi-step reasoning
- Memory management
- Task execution
- Environment interaction
- Error recovery
- Human approvals
- Security enforcement
- Long-running operations
- Agent collaboration
- Evaluation and monitoring
The core idea
The cleanest mental model is that the agent loop is not the model itself. The model reasons, selects actions, and proposes outputs, but the harness decides when the model is called, which tools are available, how tool results are returned, how state is preserved, when to stop, and how to recover when something fails. This pattern traces back to ReAct, which showed that interleaving reasoning traces with actions improves task solving, interpretability, and error handling because the model can update plans after observing the environment.
What a harness contains in practice
A harness is the runtime orchestration layer around an AI model that manages execution, tools, memory, state, safety, recovery, and coordination.A production harness usually includes the instruction assembly logic, the tool registry, the execution loop, state management, memory handling, permission checks, approvals, logging, tracing, retries, and recovery. OpenAI explicitly frames the harness as the full contract around the model, including instructions, tools, routing, output requirements, and validation checks. Anthropic similarly emphasizes that tool calls can be executed either by your application or by Anthropic, depending on whether the tool is client side or server side, which is why the harness must understand where execution happens and how results flow back into the loop.
Control Plane + Runtime + Execution Orchestrator
Anthropic’s view of the harness
Anthropic’s current Managed Agents offering is a useful reference point because it packages the harness for you. Anthropic describes it as a pre built, configurable agent harness that runs in managed infrastructure, and says it is best for long running tasks and asynchronous work. In their model, the system is built around four concepts:
the Agent, which includes the model, system prompt, tools, MCP servers, and skills;
the Environment, which is the configured container template;
the Session, which is a running instance for a specific task; and
Events, which are the messages exchanged between your application and the agent.
Anthropic also says Managed Agents provides built in tools, custom tools, and persistent memory stores that can survive across sessions, with session level memory versions for auditability and recovery.
Anthropic’s tool model makes the split concrete. Built in tools include file operations, shell execution, web search, and web fetch, while custom tools are executed by your application and fed back into Claude. Their memory docs also make an important security point: because memory stores can be read write by default, untrusted input can poison later sessions, so read only should be used for reference material or any store the agent does not need to modify. That is exactly the sort of policy a harness must enforce.
OpenAI’s view of the harness
OpenAI uses the same architectural idea but names the boundary very explicitly. In the Agents SDK and sandbox docs, the harness is the control plane around the model, and compute is the sandbox execution plane. The harness owns tool routing, handoffs, approvals, tracing, recovery, and run state, while the sandbox is where files are read and written, commands run, dependencies install, services are exposed, and state snapshots live. OpenAI says sandboxes are especially useful when the agent needs to manipulate files, run commands, produce artifacts, expose a service, or continue stateful work later.
OpenAI’s Codex articles show the same pattern in a coding system. They describe the agent loop as the core logic that orchestrates interaction between the user, the model, and the tools, and explicitly call that runtime the harness. In the improvement loop example, OpenAI says the harness is the full contract around the model, and the flywheel is traces, feedback, evals, and then a developer handoff to Codex to implement the recommended harness changes. That is a very production oriented view of harness engineering, where observability and iteration are first class design goals.
Fundamental Mental Model
The cleanest way to understand the harness is:
Agent = Model + Harness
The model provides:
- Language understanding
- Planning
- Reasoning
- Tool selection
- Decision generation
The harness provides:
- Execution
- State
- Tools
- Safety
- Runtime management
- Coordination
The LLM itself only performs:
Reasoning + Decision Generation
Everything else belongs to the harness.
Why Harnesses Became Necessary
Early LLM systems were simple:
User → Prompt → LLM → Response
This architecture breaks immediately in production because:
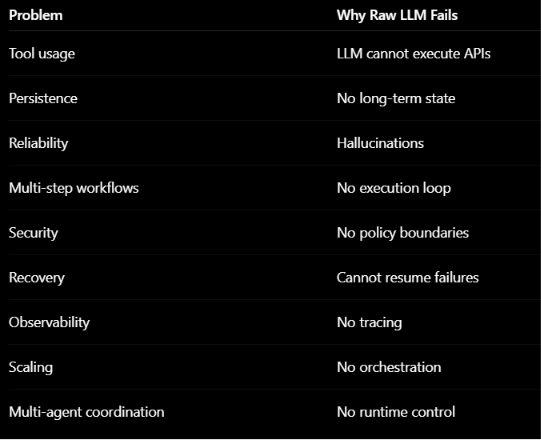
Complete System Architecture
┌─────────────────────┐
│ USER/API │
└──────────┬──────────┘
│
▼
┌─────────────────────────────┐
│ HARNESS │
│─────────────────────────────│
│ Prompt Assembly │
│ Agent Loop │
│ Tool Registry │
│ Memory Manager │
│ Policy Engine │
│ Session State │
│ Retry Logic │
│ Tracing │
│ Human Approval │
│ Multi-Agent Router │
│ Evals │
└──────────┬──────────────────┘
│
┌────────────────┼────────────────┐
│ │ │
▼ ▼ ▼
┌────────────┐ ┌────────────┐ ┌────────────┐
│ TOOLS │ │ SANDBOXES │ │ MEMORY │
└────────────┘ └────────────┘ └────────────┘
│
▼
┌──────────────┐
│ MODEL │
└──────────────┘
Evaluation harness versus runtime harness
People often use harness to mean the runtime, but there is also an evaluation harness. Anthropic defines an evaluation harness as the infrastructure that runs evals end to end, provides instructions and tools, runs tasks concurrently, records every step, grades outputs, and aggregates results. They also state that when you evaluate an agent, you are evaluating the harness and the model together. That distinction matters because a good model inside a weak harness can still fail in production, while a strong harness can make a smaller model dramatically more useful and reliable.
The practical anatomy of a good harness
A strong harness usually has a bounded agent loop, a strict tool contract, explicit context management, a durable session store, a sandbox or other execution boundary, lifecycle hooks, and a safety layer that can block or modify unsafe actions. Arize’s recent field report captures the same industry convergence and describes a harness as a fixed runtime architecture with an iteration loop, context management, tool registry, permission layer, and end to end observability, while Martin Fowler argues that choosing a constrained topology makes a comprehensive harness more achievable because it reduces the variety the system must regulate.
The main engineering tradeoff is flexibility versus control. A permissive harness can do more kinds of work, but it becomes harder to secure, test, and debug. A constrained harness can be much safer and more legible, especially in coding or document workflows, because the environment, tool set, and state transitions are all narrow enough to reason about. OpenAI’s engineering post on Codex says early progress was slower when the environment was underspecified, and that the team had to make the application legible to the agent with structures like repository knowledge, UI logs, and metrics. That is a strong signal that harness quality is often the real bottleneck, not raw model quality.
Core Components of a Harness
Prompt Construction Layer
The harness dynamically assembles prompts from:
- User input
- Session history
- Memory retrieval
- Tool outputs
- Policies
- Agent state
- System instructions
Example:
context = {
"system_prompt": system_rules,
"memory": retrieved_memory,
"tools": available_tools,
"history": conversation_history,
"current_task": task
}
The harness decides what the model sees.
Agent Loop
The loop is the heart of the harness.
Basic loop:
Reason → Decide → Execute → Observe → Repeat
This originated from the ReAct paradigm.
Example Loop
while not done:
response = llm(context)
if response.tool_call:
result = execute_tool(response.tool_call)
context.append(result)
elif response.final_answer:
done = True
This transforms static inference into autonomous behavior.
Tool Orchestration
Tools are external capabilities:

The harness:
- Registers tools
- Validates permissions
- Executes calls
- Returns outputs
- Handles retries
- Normalizes responses
Tool Registry Architecture
TOOLS = {
"search": SearchTool(),
"calculator": CalculatorTool(),
"python": PythonSandboxTool()
}
The harness controls access:
if tool_name not allowed:
deny_execution()
This is critical for security.
Memory Systems
Memory is one of the most misunderstood parts of agent systems.
The harness manages multiple memory layers.
Short-Term Memory
Conversation/session state.
Current task
Recent tool outputs
Recent thoughts
Temporary state
Usually stored in:
- Redis
- In-memory cache
- Session stores
Long-Term Memory
Persistent storage.
Examples:
- Vector databases
- Knowledge graphs
- Document stores
- Relational DBs
Used for:
- User preferences
- Historical tasks
- Organizational knowledge
- Agent learning
Episodic Memory
Stores past execution traces.
Useful for:
- Reflection
- Self-improvement
- Recovery
- Planning
Sandbox Execution
One of the most important modern harness concepts.
The model must never directly execute arbitrary code.
Instead:
Harness → Sandbox → Execution
Sandbox responsibilities:
- Isolated execution
- Resource limits
- Network controls
- File system controls
- Dependency management
- State snapshots
Sandbox Architecture
LLM
│
▼
Harness
│
▼
Container / VM / Firecracker
│
├── Python
├── File System
├── Temporary State
├── API Access
└── Output Artifacts
Technologies:

Policy Enforcement Layer
Critical for enterprise deployment.
The harness validates:
- Tool permissions
- Dangerous actions
- Data access
- Network calls
- Prompt injection
- Secret leakage
- Destructive operations
Example:
if action == "delete_database":
require_human_approval()
Human-in-the-Loop Systems
Modern harnesses often include approval workflows.

Multi-Agent Harnesses
The harness also orchestrates multiple agents.
Architecture
Supervisor Agent
│
┌──────────────┼──────────────┐
▼ ▼ ▼
Research Agent Coding Agent Review Agent
The harness manages:
- Routing
- Shared memory
- Message passing
- Conflict resolution
- Synchronization
Why Multi-Agent Systems Become Dangerous
One of the biggest industry realizations today is:
More agents ≠ Better systems
Problems:

Observability and Tracing
Production harnesses require full observability.
Without tracing, debugging agents becomes impossible.
Tracing Includes
- Prompts
- Tool calls
- Latency
- Token usage
- Failures
- Agent transitions
- Memory retrievals
Popular tools:

Evals Harness
Separate from runtime harness.
Purpose:
Measure reliability and quality
An eval harness:
- Runs benchmark tasks
- Executes agents repeatedly
- Records traces
- Scores outputs
- Detects regressions
Runtime Harness vs Eval Harness

Harness Failure Modes
Infinite Loops
Agent repeatedly calls tools.
Mitigation:
MAX_ITERATIONS = 8
Prompt Injection
External content manipulates the agent.
Mitigation:
- Input sanitization
- Context isolation
- Read-only memory
Tool Abuse
Agent performs unsafe actions.
Mitigation:
- Permission policies
- Sandboxing
- Human approval
Context Explosion
Too much memory causes degradation.
Mitigation:
- Summarization
- Retrieval filtering
- Context windows
Enterprise Harness Architecture
Production Reference Design
API Gateway
│
▼
Harness Orchestrator
│
┌─────────────────┼─────────────────┐
▼ ▼ ▼
Session Store Policy Engine Tracing Layer
│ │ │
▼ ▼ ▼
Vector DB Approval Queue Metrics DB
│
▼
Tool Layer
│
▼
Sandboxes
│
▼
Models
A reference architecture you can implement
A production grade harness usually looks like this: the user sends a task, the harness composes the system prompt and context, the model proposes either a final answer or a tool call, the harness validates the call against policy, executes the tool in a safe environment, captures the result, writes the result back into state, and loops until termination. Termination happens on a final text answer, a max iteration limit, a recoverable stop condition, or an unrecoverable error. This is the common pattern across Anthropic’s tool use model, Anthropic’s managed agents, and OpenAI’s sandbox and agent loop design.
from __future__ import annotations
from dataclasses import dataclass, field
from typing import Any, Callable, Dict, List, Optional, Protocol, Union
class Tool(Protocol):
name: str
def run(self, arguments: Dict[str, Any]) -> Any:
...
@dataclass
class AgentState:
session_id: str
messages: List[Dict[str, Any]] = field(default_factory=list)
scratchpad: Dict[str, Any] = field(default_factory=dict)
iterations: int = 0
max_iterations: int = 8
@dataclass
class ToolResult:
tool_name: str
result: Any
is_error: bool = False
class Harness:
"""
Minimal production-style harness skeleton.
Responsibilities:
1. Build context
2. Ask the model for the next step
3. Validate and execute tools
4. Persist state
5. Stop safely
"""
def __init__(
self,
model_call: Callable[[List[Dict[str, Any]]], Dict[str, Any]],
tools: Dict[str, Tool],
policy_check: Callable[[str, Dict[str, Any]], bool],
state_store: Callable[[AgentState], None],
trace: Optional[Callable[[str, Dict[str, Any]], None]] = None,
) -> None:
self.model_call = model_call
self.tools = tools
self.policy_check = policy_check
self.state_store = state_store
self.trace = trace or (lambda event, payload: None)
def run(self, state: AgentState) -> Dict[str, Any]:
while state.iterations < state.max_iterations:
state.iterations += 1
self.trace("iteration_start", {"iteration": state.iterations})
model_output = self.model_call(state.messages)
self.trace("model_output", model_output)
if model_output.get("type") == "final":
state.messages.append({"role": "assistant", "content": model_output["content"]})
self.state_store(state)
return {"status": "done", "content": model_output["content"]}
if model_output.get("type") != "tool_call":
state.messages.append({"role": "assistant", "content": "Invalid model output."})
self.state_store(state)
return {"status": "error", "reason": "invalid_model_output"}
tool_name = model_output["tool_name"]
arguments = model_output.get("arguments", {})
if tool_name not in self.tools:
state.messages.append({"role": "assistant", "content": f"Unknown tool: {tool_name}"})
self.state_store(state)
return {"status": "error", "reason": "unknown_tool"}
if not self.policy_check(tool_name, arguments):
state.messages.append({"role": "assistant", "content": f"Denied tool: {tool_name}"})
self.state_store(state)
return {"status": "error", "reason": "policy_denied"}
try:
result = self.tools[tool_name].run(arguments)
tool_result = ToolResult(tool_name=tool_name, result=result)
except Exception as exc:
tool_result = ToolResult(tool_name=tool_name, result=str(exc), is_error=True)
state.messages.append(
{
"role": "tool",
"tool_name": tool_name,
"content": tool_result.result,
"is_error": tool_result.is_error,
}
)
self.state_store(state)
self.trace("tool_result", {"tool_name": tool_name, "is_error": tool_result.is_error})
return {"status": "stopped", "reason": "max_iterations"}
How to design it correctly
The biggest architectural decision is the boundary between the harness and compute. OpenAI’s sandbox guidance is very clear that the harness should keep auth, billing, audit logs, human review, and recovery outside the container, while the sandbox should handle the mutable work. Anthropic’s memory guidance points to the same principle from a different angle, since persistent state must be separated by trust level or it can become an injection path. In practice, that means your harness should treat web content, user input, and third party tool output as untrusted, keep secrets out of model visible storage, and use read only memory or scoped mounts whenever possible.
The other major design choice is how much autonomy you allow. Anthropic’s Messages API is positioned for custom agent loops and fine grained control, while Managed Agents is positioned for long running and asynchronous tasks. OpenAI’s sandbox approach also assumes that some work belongs inside a managed execution environment rather than directly in prompt space. So the right harness is usually not the most autonomous one, it is the one that is easiest to control, inspect, and recover when things go wrong.
The evaluation and improvement loop
A real harness is never finished. Anthropic’s eval guidance says the harness and model are evaluated together, which means you must test not just model quality but the entire orchestration stack. OpenAI’s improvement loop recommends using traces to see what happened, feedback to explain what mattered, and evals to make those expectations reusable. That is the right operational model for production: trace every run, turn failures into evals, and use the evals to evolve the harness instead of repeatedly patching prompts by hand.
The harness is responsible for:
Harness Design Principles
Deterministic Infrastructure
The model may be probabilistic.
The infrastructure must not be.
Constrained Autonomy
Never allow unrestricted execution.
Explicit State
All state transitions must be observable.
Separation of Concerns
Relationship with MCP
Anthropic’s Model Context Protocol (MCP) integrates naturally with harnesses.
The harness acts as the MCP orchestrator.
MCP standardizes:
- Tool schemas
- Resource discovery
- Structured capabilities
- Agent interoperability
Modern Agent Stack
Full Stack
Application Layer
│
Harness / Orchestrator
│
Memory + Tools + Policies
│
Sandbox Infrastructure
│
LLM Providers
The Most Important Insight : The industry is realizing something fundamental.
The harness is becoming more important than the model itself.
Why?
Because production reliability depends more on:
- Orchestration
- Tool reliability
- Context engineering
- Safety systems
- Observability
- Recovery
- Memory quality
than raw benchmark intelligence.
Future of Harnesses
Future harnesses will likely include:

A harness is the code and infrastructure around an AI model that makes the model usable as an agent. It includes the loop, the tool system, state and memory, execution boundaries, permissions, tracing, recovery, and evaluation. The model thinks. The harness makes thinking executable, safe, and repeatable
Harness in AI Agents was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.