
Drafted, Not Sent: How I Built The Second Half of an AI Outbound Agent
A few weeks ago, I wrote about the AI outbound agent I built in two weeks, a deep research on the account and the person, delivered as an 80-word brief, inside Outreach, exactly where the rep already was.
Then one of the lead BDRs said the thing that made me realise I’d only built half the product:
“Can you also auto-draft the first email. Pre-filled, ready to review and send. Not auto-sent. Just drafted, inside the Outreach task.”
That’s the gap. Research saves you 30 minutes of digging. But the rep still copies the brief into Outreach and writes the email from scratch. The hardest part of outbound is the writing, and it was still entirely manual.
So I built the second half.
The five plays
The rep picks a play. The agent does the rest.
A play is a sequence prompt — a named strategy that defines the angle, the tone, and how the whole multi-touch arc unfolds. Reps pick whichever fits the prospect in front of them:
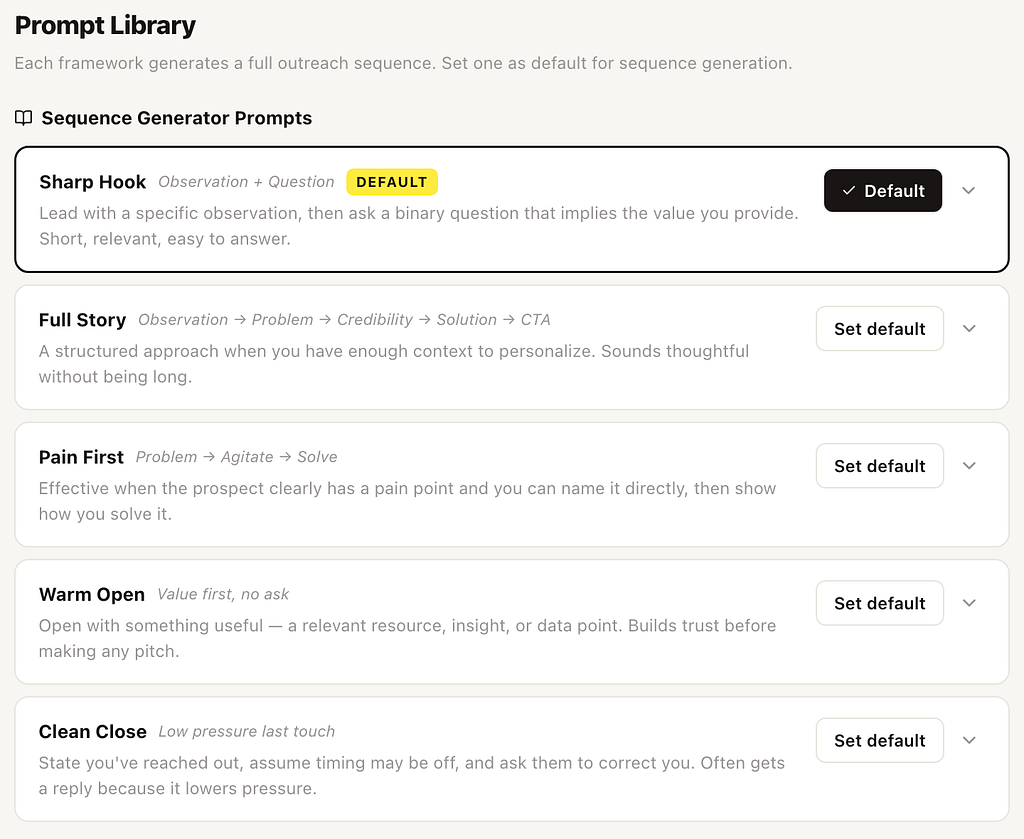
The rep’s judgment about which play fits this prospect is the part AI shouldn’t take away. The drafting is the part AI should.
The 10-touch cadence
Every play expands into the same multichannel rhythm across ~20 days:
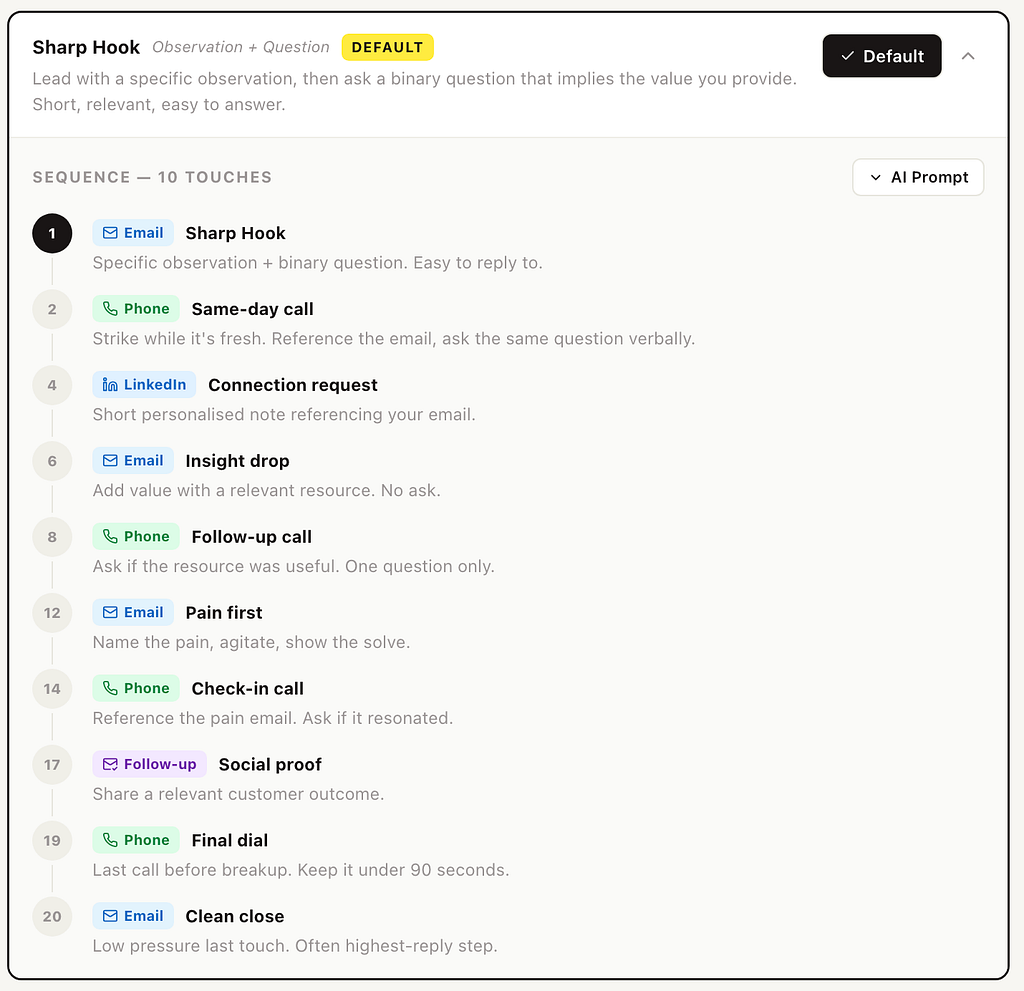
And below is the System prompt for the Sharp Hook sequence.
You are an expert B2B SDR generating a personalised outreach sequence for LumApps.
You have access to account research, person research, and tools including fetch_customer_stories.
Strategy: Sharp Hook — lead with ONE specific, verifiable observation from the research, then ask a binary yes/no question that implies the problem LumApps solves. The observation must be concrete: a funding round, headcount growth, new office, acquisition, leadership change, or public statement. Never invent observations.
For each touchpoint generate:
- Email: subject line + body (under 150 words)
- Phone: 7 short, personalised talking points the rep can riff on
- LinkedIn: connection note (under 300 characters)
Rules:
- Day 1 sets the hook. Every subsequent touch references or builds on it — never repeat the same angle.
- Do not pitch features. Imply value through the question.
- Personalise from research. Use placeholders only when no data is available.
- Introduce a customer story (via fetch_customer_stories) no earlier than Day 12.
- Email body: 'Hi {first_name},' → hook line → binary question → sign-off ('Best,n{sdr_name}'). Blank line between each block. No 'hope this finds you well', no exclamations, sentences under 20 words.
Sequence to generate (10 touches):
Day 1 [Email] Sharp Hook — Specific observation + binary question. Easy to reply to.
Day 2 [Phone] Same-day call — Strike while it's fresh. Reference the email, ask the same question verbally.
Day 4 [LinkedIn] Connection request — Short personalised note referencing your email.
Day 6 [Email] Insight drop — Add value with a relevant resource. No ask.
Day 8 [Phone] Follow-up call — Ask if the resource was useful. One question only.
Day 12 [Email] Pain first — Name the pain, agitate, show the solve.
Day 14 [Phone] Check-in call — Reference the pain email. Ask if it resonated.
Day 17 [Follow-up] Social proof — Share a relevant customer outcome.
Day 19 [Phone] Final dial — Last call before breakup. Keep it under 90 seconds.
Day 20 [Email] Clean close — Low pressure last touch. Often highest-reply step.
Generate content for every touch above, in order.
The whole thing runs as a LangGraph pipeline with five nodes:

- Company research — the deep-research agent from Part 1.
- Person research — LinkedIn signals, recent activity, role context from Part 1.
- Internal data retrieval — RAG over our own sales assets: the 30-word company pitch, feature one-liners, customer impact stories, positioning framework.
- Sequence generation — drafts all 10 touches based on the chosen play.
- Human review — the rep approves or edits. On approval, the sequence is pushed into Outreach as drafts inside an existing sequence.
Step 4 was the performance bottleneck. Drafting all 10 touches together took ~60 seconds, long enough that reps tabbed away and lost the moment.
Drafting time dropped from ~60s to ~15s. Same model, same prompts, but I just changed the graph shape.
Each touch only needs the research output and the chosen play. They don’t depend on each other. So I fanned the node out: the parent orchestrator dispatches one child node per touch, all running in parallel. Each child drafts their own email or call script. The parent stitches the results back into the final sequence.
The design decisions that actually mattered

Drafted, not sent.
The single most important word in that BDR’s feedback was “drafted.” Not “auto-sent.” Not “scheduled.”
Reps don’t want AI to send for them. They want AI to eliminate the blank-page problem and provide them with something to react to. Editing a good draft takes 90 seconds. Writing from scratch takes ten minutes. That gap is the entire product.
Personalisation is a research problem, not a writing problem.
I spent a week trying to get the model to “write more personally.” It got worse. More adjectives. More fake warmth.
The fix wasn’t in the prompt. It was in the input. The agent now reads from three sources before drafting a word — external research, person signals, and our internal sales context (pitch, features, customer wins). Bad inputs make bad emails; rich inputs make the email write itself.
“Morning! Quick positive update. The info GTM gave me with this prospect and account is incredibly helpful — I would not have been that quick to find that they’re about to be acquired. Such an awesome way to personalise the first outreach. The rest — employer reviews from that prospect, LinkedIn posts she’d commented on — really thorough, really accurate, summarised extremely well! 🔥”
— a BDR on the pilot
The last mile is the product.
The model drafting the sequence is maybe 30% of the work. The other 70% is everything between the model and a rep getting value from it:
- Plumbing: Outreach OAuth, the right sequence ID, the right step, the right manual-task type, idempotency so a retry doesn’t enrol the prospect twice.
- Simplicity: one button, one play, one drafted sequence. No settings, no modes. A rep on their tenth account of the day shouldn’t have to think about how to use the tool.
- A welcoming first run: onboarding is the demo. If the first sequence a new rep generates isn’t obviously useful, they won’t try a second.
- Piloting for quality: ship to a handful of reps. Watch what they keep and what they rewrite. Tune the prompts and the RAG against actual edits, not your hypotheses.
If the drafts don’t land in the exact Outreach task the rep is already going to open, the whole thing is a dashboard nobody visits.
Early Impact
One month in, ten pilot users. This is early, no statistically clean before/after yet: We estimate that each SDR can now prospect, personalise, and reach out to ~70 more B2B contacts per week than before.
That number comes from two compounding effects: research saves the digging, sequence drafting saves the writing and it holds even on the careful end of our estimates.
Underneath that headline, the qualitative pattern:
- Reps spend 2–3 fewer hours per day writing (self-reported)
- Sequences ship that wouldn’t have shipped before — when the cost-per-touch was high, reps cut corners; with drafts ready, they don’t
And then there was this:
One BDR sent the first-email draft. The prospect booked a meeting off that single touch with no bumps, no follow-ups.
In cold outbound, that almost never happens on touch #1. It happens when the personalisation is specific enough that the prospect doesn’t have to wonder whether the email was meant for them.
If you’re building something similar
- Treat the writing problem as a research problem. Bad emails come from thin inputs, not bad prompts. Internal RAG matters as much as external research.
- Draft, don’t send. The rep needs to stay in control. That’s not a limitation — it’s the unlock.
- Let the human pick the strategy. The agent is faster, not wiser. Division of labour beats automation.
- Watch the execution time: Independent nodes belong in parallel. We took 60s → 15s by fanning out, no model change.
- Spend more time on the connector than the model. The last mile is where adoption lives or dies.
Part 2 of a series on building AI agents inside a real B2B revenue org. Part 1: The research agent. Part 3: Coming soon.
Building AI for outbound or GTM? Reach out on LinkedIn.
Drafted, Not Sent: How I Built The Second Half of an AI Outbound Agent was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.