Beyond Embeddings: Automated Document Validation and Version Control for RAG Knowledge Bases

“I have been working with vector databases and RAGs, and I have realized that identifying same documents with different versions and maintain their data integrity is trickier than I expected. The reason for writing this article is to share how I approach the problem and what I have learnt.”
Introduction
Vector databases store embeddings that capture semantic meaning and are widely used in Retrieval-Augmented Generation (RAG) systems, where PDFs are often the primary knowledge source.
In practice, traditional integrity checks such as file names or file sizes are insufficient. The same document may appear under different names, such as:
- WHS_Act_2013_v2.pdf
- publication_99_final.pdf
This leads to several issues:
- Duplicate embeddings: Unnecessary index growth, increased storage requirements, and reduced retrieval efficiency.
- Version mixing: Retrieval of outdated and current document versions for the same query.
- Conflicting context: Contradictory information provided to the LLM during retrieval.
- Increased hallucination risk: Conflicting or outdated evidence can lead to inaccurate or misleading responses.
Why Metadata Alone Fails
In theory, PDF metadata could solve this problem by storing titles, versions, and publication dates.
In practice, it is unreliable.
Metadata is often:
- Incomplete (missing fields such as dates)
- Inaccurate (wrong or generic titles like “View — NSW Legislation”)
- Absent in scanned or legacy PDFs
- Inconsistent across jurisdictions and publishers
The following example demonstrates the failure of native PDF metadata extraction on the Work Health and Safety (Mines and Petroleum Sites) Act 2013 No. 54 document using Python:
import fitz # PyMuPDF
from pypdf import PdfReader
doc = fitz.open("mining_act_2022.pdf")
metadata = doc.metadata
for key, value in metadata.items():
print(f"{key}: {value} -> {type(value)}")
Output:
format: PDF 1.5 -> <class 'str'>
title: View - NSW legislation -> <class 'str'>
author: -> <class 'str'>
subject: -> <class 'str'>
keywords: PCO, Parliamentary Counsel's Office, ...
creator: -> <class 'str'>
producer: Prince 15.1 (www.princexml.com) -> <class 'str'>
creationDate: -> <class 'str'>
modDate: -> <class 'str'>
trapped: -> <class 'str'>
encryption: None -> <class 'NoneType'>
This makes metadata-based validation insufficient for compliance-grade systems where traceability and correctness are critical, and demonstrate the need to validate documents based on their intrinsic content rather than external file attributes.
Why Regex and LLMs Are Not Enough
A natural first step in extracting key document metadata (e.g. title, version, publication date) is to combine:
- Regex for structured pattern extraction
- LLMs for flexible semantic parsing
The extracted metadata is then used to assess document identity and version. However, both approaches are insufficient as primary validation mechanisms.
Regex is fast and deterministic but brittle — minor formatting changes (extra spaces, line breaks, or date format shifts) can break extraction rules and require constant maintenance.
LLMs, on the other hand, are flexible but probabilistic. They may hallucinate or infer incorrect metadata such as version numbers or publication dates, which introduces silent data corruption risks in compliance systems.
Conclusion: Neither Regex nor LLMs are reliable enough to determine document identity or version equivalence. They are useful only as supporting signals, not decision-makers.
Methodology
To address these limitations, a multi-stage validation pipeline was designed with three components:
- Metadata Extraction
- Content Validation
The pipeline is backed by a knowledge base consisting of two complementary storage systems:
- MongoDB stores document metadata, fingerprints, identifiers, validation results, and other structured information associated with each document.
- Qdrant stores the vector embeddings of all documents recorded in MongoDB.
This hybrid architecture separates document management from vector storage. Since Qdrant stores embeddings for individual document chunks rather than complete documents, document-level operations such as duplicate detection, version replacement, and deletion are difficult to manage directly. MongoDB acts as the single source of truth by maintaining the document lifecycle and storage context, while Qdrant is dedicated to efficient semantic vector search.
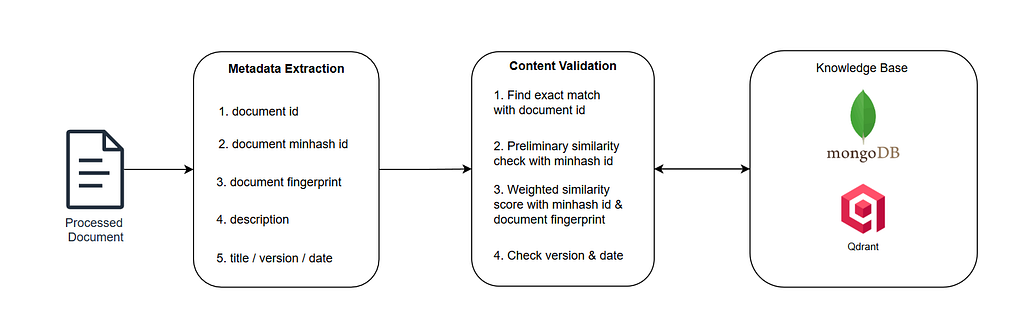
Metadata Extraction
The following metadata will firstly be extracted from a processed document.
- Document ID
- Document Similarity ID
- Document Fingerprint
- Document Description
- Document Title / Version / Date
Document ID
Document ID is a unique identifier generated by deterministic UUIDv5 hashing of the full document content. It is used for exact deduplication.
# Example of document id generation
raw_bytes = Path(pdf_path).read_bytes()
content_hex = raw_bytes.hex()
doc_std_id = str(uuid.uuid5(DOCUMENT_ID_NAMESPACE, content_hex))
Document Similarity ID
A Document Similarity ID is generated using HyperMinHash, an advanced extension of MinHash. MinHash compresses large sets into compact signatures that preserve similarity relationships, enabling efficient comparison of documents without requiring full content processing.
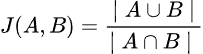
These signatures are used to estimate Jaccard similarity. Jaccard similarity is measured by diving the intersection of two sets of signatures against their union. HyperMinHash extends this approach by incorporating principles from HyperLogLog, significantly reducing memory usage while maintaining accurate similarity estimation at scale.
This makes the approach well-suited for large-scale document indexing, enabling efficient detection of near-duplicate or highly similar documents for deduplication and retrieval optimization.
# Code Example of generating similarity id with minhash encoding
def _compute_doc_similarity_id(self, full_text: str) -> str:
sketch = pyhyperminhash.Sketch()
entry = pyhyperminhash.Entry()
entry.add_bytes(full_text.encode("utf-8"))
sketch.add_entry(entry)
return base64.b64encode(sketch.save()).decode()
Document Fingerprint
# Code Example of DocumentFingerprint Pydantic model class
class DocumentFingerprint(BaseModel):
primary_entity: str
entity_type: str
key_words: list[str]
A Document Fingerprint is a custom structured data object that stores semantic metadata extracted from a document using a Large Language Model (LLM). This typically includes themes, topics, keywords, and other high-level descriptors that characterize the document’s content.
While HyperMinHash is effective at identifying documents with similar token distributions or structural patterns, it may produce false positives when documents share formatting characteristics but differ in subject matter.
The Document Fingerprint enables the system to distinguish between structurally similar but semantically unrelated documents. This improves the accuracy of deduplication, clustering, and similarity-based retrieval.
The following example illustrates the structure of a DocumentFingerprint object for Work Health and Safety (Mines and Petroleum Sites) Act 2013 No 54:
Primary Entity: Work Health and Safety (Mines and Petroleum Sites) Act 2013
Entity Type: Regulation
Keywords: PCO, Parliamentary Counsel’s Office, QLD PCO, QLD , Legislation, Bills of Parliament, Act, amendment, law, legal advice, legislation, Parliament
Description
LLM extraction description for the document.
Document Title / Version / Date
LLM extraction title, version and published date for the document.
Content Validation
Content validation determines whether an incoming document is a duplicate, a newer version, or entirely new before it is indexed. Rather than relying on filenames or metadata, the pipeline validates the document’s intrinsic content, preventing duplicate embeddings, avoiding version conflicts, and ensuring that only high-quality, consistent information is stored in the vector database.
Exact Match Search
The first validation step checks whether the document has already been ingested.
- The system queries MongoDB using the document ID.
- MongoDB stores the metadata of every document that has been indexed in the Qdrant vector database.
- If an exact document ID match is found, the ingestion process is terminated and no upsert operation is performed.
- If no matching document exists, the document proceeds to the MinHash similarity check.
Minhash Similarity Check
# Coding Example for Jaccard similarity computation
import pyhyperminhash
new_sketch_bytes = base64.b64decode(new_doc_similarity_id)
new_sketch = pyhyperminhash.Sketch.load(new_sketch_bytes)
cand_sketch_bytes = base64.b64decode(candidate_similarity_id)
cand_sketch = pyhyperminhash.Sketch.load(cand_sketch_bytes)
jaccard_sim = new_sketch.similarity(cand_sketch)
jaccard_threshold = SIMILARITY_CONFIG["jaccard_threshold"]
if jaccard_sim < jaccard_threshold:
print("New document detected")
"""
Upload as a new document to vector daatabase
"""
else:
print("Similar document detected")
"""
Subsequent identity score calculation...
"""
- A second query is issued to MongoDB to retrieve all Document Similarity IDs associated with the same document theme (e.g. regulations).
- The Jaccard similarity score is then computed between the incoming document’s similarity signature and the retrieved candidates.
- If the similarity score exceeds a predefined threshold, the pipeline proceeds to the next stage of content validation. Otherwise the document is treated as distinct document
Identity Score Calculation
If the MinHash similarity exceeds the configured threshold, a final semantic validation step determines whether the document is a duplicate.
The process is as follows:
- Extract the document fingerprint and document description from both the incoming document and the existing document.
- Convert both fields into embeddings using the configured embedding model.
- Compute the cosine similarity between the document fingerprint embeddings, and the document description embeddings.
- Calculate the final identity score as a weighted combination of the MinHash (Jaccard) similarity score, the document fingerprint similarity score, and the document description similarity score.
The weighted identity score is computed as:
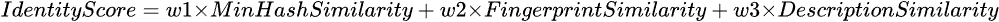
where w1, w2, and w3 are configurable weights that determine the contribution of each similarity measure.
The score is then compared against a threshold to determine document identity.
- Above threshold: The document is classified as a duplicate. Version number and publication year are compared, and the newer version replaces the existing one.
- Below threshold: The document is treated as new and proceeds through ingestion, chunking, and vector storage.
Conclusion
Ensuring data integrity in a RAG knowledge base requires more than embedding generation and indexing. Without a robust validation strategy, duplicate documents and conflicting versions can accumulate, leading to redundant retrieval, inconsistent context, and degraded LLM responses.
This work presents a multi-stage validation pipeline that combines deterministic document IDs, HyperMinHash-based similarity detection, semantic identity scoring, and LLM-assisted metadata comparison. While version and publication extraction remains imperfect, this layered approach provides a scalable framework that integrates deterministic and semantic signals to improve document validation.
As RAG systems move into production use, document validation and version control become increasingly important. Ultimately, the effectiveness of a RAG system depends not only on the embedding model or vector database, but also on the cleanliness and consistency of its underlying knowledge base.
This is my first time publishing on Medium! If you find it helpful, please feel free to leave your experiences, thoughts, or comments below. If you enjoy this article, don’t forget to leave some a few 👏. Thanks for reading!
Beyond Embeddings: Automated Document Validation and Version Control for RAG Knowledge Bases was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.