
The Multimodal Lakehouse: Data Engineering’s Answer to AI’s Messiest Problem
The architecture data teams are betting on to make AI-ready sense of enterprise data’s messiest 80%.
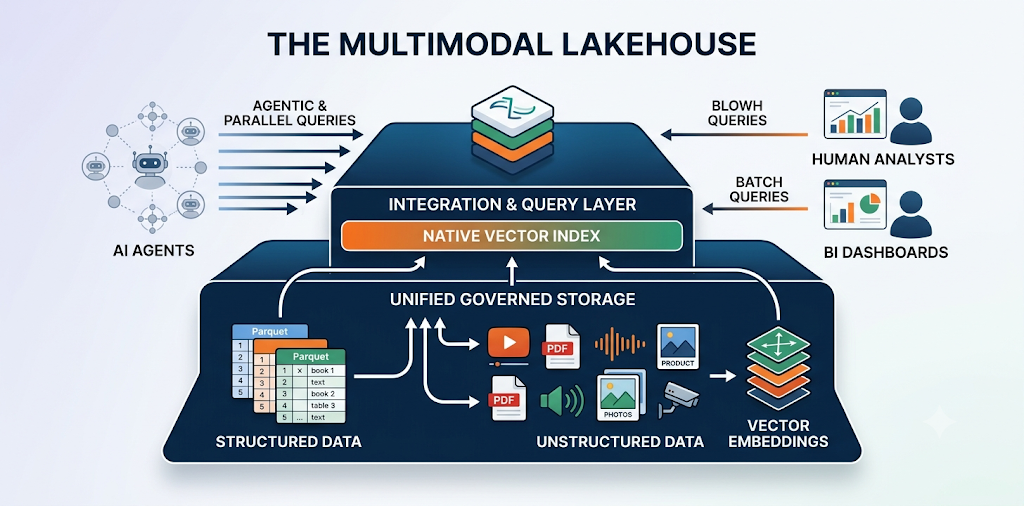
Table of Contents
- The Problem Nobody Budgeted For
- What a Multimodal Lakehouse Actually Is
- Why the Old Stack Broke
- Old Stack vs. Multimodal Lakehouse
- Who’s Actually Building This
- The Growth Curve Nobody’s Pricing In
- The Governance Catch
- What This Means for Engineers Right Now
- The takeaway
The Problem Nobody Budgeted For
Every data warehouse ever built was designed for rows and columns. Every AI system being built right now runs on something else entirely: PDFs, call recordings, product photos, security footage, Slack threads, and the embeddings generated from all of it.
Gartner has been tracking this imbalance for years, and the numbers haven’t gotten friendlier. Unstructured data now accounts for somewhere between 80% and 90% of all new enterprise data, and it’s growing at roughly three times the rate of structured data — an annual growth rate in the 55–65% range. IDC’s older but still-cited projections put total global data volume at 175 zettabytes by 2025, with only a fraction of it ever actually stored in a usable form, let alone analyzed.
None of that was a crisis when the main consumer of enterprise data was a BI dashboard. Dashboards want tables. Dashboards can wait for a nightly batch job. AI agents want none of that. They want to search a contract, a product image, and a support ticket in the same query, get back a ranked, reasoned answer, and do it hundreds of times a minute across a fleet of parallel tasks — not once, from a human typing slowly into a search bar.
That mismatch is the mess this article is about. And the architecture data teams are converging on to fix it has a name that sounds like marketing but is turning into a real category: the multimodal lakehouse.
What a Multimodal Lakehouse Actually Is
The original “lakehouse,” as popularized by Databricks starting around 2020, solved a narrower problem: it let organizations stop choosing between a data warehouse (fast, structured, expensive) and a data lake (cheap, flexible, messy) by combining open file formats on object storage with warehouse-grade features — ACID transactions, schema enforcement, governance, and BI support.
That architecture assumed the underlying unit of data was still fundamentally tabular. A “row” meant a row: numbers, strings, timestamps.
AI broke that assumption. As Chang She — a co-creator of the pandas library and now CEO of LanceDB — put it in a recent conversation with dbt Labs, a modern row now routinely includes text, images, video, and high-dimensional vectors, and these aren’t side assets anymore; they’re the primary data. A multimodal lakehouse is the attempt to build storage and compute that treats all of that as first-class, in one governed system, instead of bolting a vector index onto a warehouse and calling it done.
LanceDB’s own trajectory is a useful illustration of why this is harder than it sounds. The team originally tried building on Parquet, the industry-standard columnar format, and found it couldn’t keep up with AI workloads — search, training, and preprocessing all stalled. That led to Lance, a new AI-native file format built specifically to support random access at the scale agentic search and model training require, without forcing teams into a separate, siloed vector database.
The pattern repeats across the industry under different names — “AI-native data platform,” “intelligent lakehouse,” “agentic lakehouse” — but the underlying idea is consistent: one storage layer, one governance model, every modality.
Why the Old Stack Broke
It’s worth being specific about what actually broke, because “AI needs more data” undersells it.
Query volume and pattern changed. Analyst Ben Lorica’s Gradient Flow newsletter has been tracking this shift closely: reasoning-focused models now account for more than half of token traffic on OpenRouter, and average prompt sizes have grown roughly fourfold since early 2024. Retrieval-augmented generation used to be one-shot — ask, retrieve, answer. Agents iterate. They decompose a problem into sub-questions, refine their own queries, and run steps in parallel, which means the query load a data platform sees from a single agentic task can look like hundreds of human search sessions compressed into seconds.
The infrastructure layer is being driven by agents, not people. Lorica’s reporting cites a striking data point from Databricks: more than 80% of new databases created on its platform are now being launched by AI agents rather than human engineers. When the primary “user” of your data platform is a machine issuing rapid, varied, occasionally malformed requests, a stack built around human-paced dashboards and nightly ETL starts to look structurally wrong, not just slow.
Formats built for scans choke on random access. Traditional formats like Parquet are optimized for sequential scans — the classic BI pattern. AI training and embedding generation need high-rate random access instead. When that mismatch hits, GPUs sit idle waiting on I/O, which is an expensive way to find out your storage format is the bottleneck, not your model.
Fragmentation has a name now: the fragmentation tax. Lorica describes this as the cost an organization pays when data workflows are split across incompatible notebooks, build tools, and runtime environments. A human engineer can debug a pipeline that “works in dev, fails in prod.” An autonomous agent generally can’t — it hallucinates or stalls instead. That raises the bar: version control, automated tests, and a unified execution environment need to apply not just to code, but to tables, embeddings, and media-backed datasets alike.
Google Cloud made a similar diagnosis explicit when it announced its next-generation cross-cloud lakehouse in April 2026, describing traditional lakehouses as engineered for an era of reporting rather than the high-velocity, multimodal demands of AI agents — arguing the fix requires an AI-native foundation with continuous feedback loops in place of batch processing.
Old Stack vs. Multimodal Lakehouse
DimensionTraditional Fragmented StackMultimodal LakehouseStorage formatParquet (tabular, scan-optimized)Lance / Iceberg (random-access, multimodal-native)Vector searchSeparate vector databaseNative vector index inside the lakehouseUnstructured dataBlob store, disconnected from analyticsUnified object + governance layerGovernancePer-system, duplicated policiesSingle governance and lineage layerPrimary consumerHuman analysts, BI toolsAI agents issuing parallel, iterative queriesFailure modeData silos, “fragmentation tax”Schema drift across modalities, migration costCompute patternBatch ETL, nightly refreshContinuous, streaming, agent-triggeredReliability approachManual debugging when pipelines breakVersion control, tests, and contracts for tables and embeddings
Who’s Actually Building This
This isn’t a single vendor’s pitch — it’s converging from multiple directions at once, which is usually a sign a category is real rather than manufactured.
PlayerWhat they’re doingDatabricksPopularized the original lakehouse pattern; unifying analytics, ML, and AI workloads with Delta Lake and Unity Catalog governanceGoogle CloudAnnounced (April 2026) a cross-cloud lakehouse using managed Apache Iceberg plus BigQuery ObjectRefs to merge structured Iceberg tables with unstructured Cloud Storage data for unified multimodal analysisLanceDBBuilt Lance, an AI-native file format, positioning itself as a lakehouse for multimodal data rather than a narrow vector databaseDremioPitching an “agentic lakehouse” with a semantic layer and MCP server access so AI agents query governed data directly, aiming to reduce hallucination from ungoverned metric definitionsMicrosoft FabricUnifying lakehouse, warehouse, BI, and governance under a single OneLake foundationSnowflakeExtending its cloud data warehouse dominance into lakehouse and multimodal territory as adoption pressure builds
Apache Iceberg is emerging as the open table format most of this converges around, precisely because it lets multiple engines — Spark, Trino, Flink, BigQuery, Databricks, Snowflake — read and write the same underlying data without duplication. That interoperability matters more once “the data” includes video and embeddings, because nobody wants five copies of a training corpus scattered across five proprietary formats.
FRAGMENTED STACK (before)
[ Human Analyst ] [ AI Agent ]
| |
v v
[ BI Dashboard ] [ Vector DB ]---[ Blob Store ]---[ Warehouse ]
| | | |
v v v v
[ Parquet Tables ] (separate index, separate governance, separate copy)
UNIFIED MULTIMODAL LAKEHOUSE (now)
[ Human Analyst ] [ AI Agent ] [ Training Pipeline ]
_______________________|___________________/
|
v
[ Governed Lakehouse: Iceberg / Lance ]
text · images · video · audio · vectors · tables
|
v
[ Single lineage + access layer ]
The Growth Curve Nobody’s Pricing In
The case for urgency isn’t hypothetical — it’s a trend line. Here’s a simplified Chart.js configuration showing the divergence between structured and unstructured data growth that’s driving this shift (drop this into a CodePen or Gist embed for the live version):
javascript
new Chart(document.getElementById('dataGrowthChart'), {
type: 'line',
data: {
labels: ['2023', '2024', '2025', '2026 (proj.)'],
datasets: [
{
label: 'Structured data volume (index)',
data: [100, 115, 132, 150],
borderColor: '#2E6FF2',
fill: false
},
{
label: 'Unstructured data volume (index)',
data: [100, 158, 250, 396],
borderColor: '#FF6F59',
fill: false
}
]
},
options: {
plugins: {
title: {
display: true,
text: 'Unstructured data is compounding at roughly 3x the rate of structured data (Gartner)'
}
},
scales: {
y: { title: { display: true, text: 'Relative index (2023 = 100)' } }
}
}
});
The indexed values above are illustrative, built from Gartner’s widely cited 55–65% annual unstructured growth rate against a much flatter structured-data curve — but the shape of the line is the point. Every year an organization delays unifying its data layer, the ratio it’s ignoring gets more lopsided, not less.
On the adoption side, the pattern is already mainstream rather than early: more than 50% of data teams report implementing lakehouse patterns as of 2026, and over 90% of mid-to-large organizations now run a cloud data warehouse, according to market tracking from Folio3. Apache Iceberg adoption is accelerating in parallel as the open standard that makes multi-engine, multimodal access practical.
The Governance Catch
Here’s the part that doesn’t make it into vendor keynotes: unifying the data layer doesn’t unify the responsibility for the data. If anything, it raises the stakes.
At Gartner’s Data & Analytics Summit in London this past May, analyst Mark Beyer reiterated that 70–90% of enterprise data is unstructured and argued that governing it well is now central to how quickly and accurately organizations can make decisions. Gartner’s guidance on the topic lays out a five-step approach to unstructured data governance, starting with prioritizing sources by business value and AI relevance — which is a polite way of saying most organizations currently have no idea what’s actually in their unstructured data, let alone whether it’s sensitive.
That’s a real risk multiplied, not solved, by a multimodal lakehouse. When your video files, contracts, and customer chat logs sit in the same governed system as your financial tables, a single access-control mistake has a much bigger blast radius than it did when that data was scattered — and harder to find — across disconnected blob stores. Komprise’s data management research has found a large share of IT leaders already worried their infrastructure isn’t ready for the current rate of unstructured data growth; consolidating that data into one platform without first solving classification, sensitivity tagging, and lineage just moves the failure point rather than removing it.
There’s also a fair critique buried in LanceDB’s own framing of the category: the “vector database” label, as originally sold, was often too narrow for what teams actually needed, and now the “lakehouse” label risks becoming the next term stretched to cover whatever a vendor is already selling. Not every product wearing the multimodal lakehouse label has actually solved the hard distributed-systems problems of high-rate random access across petabytes of mixed media. Some are Parquet-based platforms with a vector index bolted on and a new marketing page — which is exactly the fragmentation this architecture is supposed to replace, just repackaged as unification.
What This Means for Engineers Right Now
None of this requires a rip-and-replace migration to be useful advice. A few things worth doing regardless of which vendor’s lakehouse you eventually land on:
- Audit where your fragmentation tax actually lives. Map every place a single logical dataset — a customer record, a product catalog entry — currently exists as separate copies across a vector index, a blob store, and a warehouse table. That map is your migration priority list, not a vendor’s roadmap.
- Treat embeddings and media like you treat tables. Version them, test them, put them behind the same access controls and lineage tracking as your structured data. An agent that hallucinates because a stale embedding never got invalidated is a data engineering failure, not a model failure.
- Evaluate Iceberg before you evaluate a platform. Because Iceberg is becoming the interoperability layer multiple engines read and write against, standardizing on it early reduces how locked in you are to whichever multimodal lakehouse vendor wins your organization’s next RFP.
- Classify before you consolidate. Gartner’s governance-first framing exists for a reason: unifying storage before you’ve classified sensitivity and ownership just centralizes your risk instead of your value.
- Be skeptical of the label. Ask any vendor pitching “multimodal lakehouse” whether they’ve solved random-access performance at scale for training workloads, or whether it’s a vector index attached to an existing warehouse. The answer determines whether you’re buying an architecture or a rebrand.
The takeaway
The multimodal lakehouse isn’t a buzzword invented to sell another platform migration — it’s a reasonably direct response to a fact that’s been true for years and only now has teeth: most enterprise data was never structured, AI is the first major workload that actually needs to use all of it at once, and the storage formats built for BI dashboards weren’t built for that job.
The architecture is real, multiple independent vendors are converging on similar answers, and the interoperability layer (Iceberg) is maturing fast enough to make this more than hype. But the governance problem it surfaces — knowing what’s actually in your unstructured data before you unify access to it — is still mostly unsolved, and no storage format fixes that on its own.
The Multimodal Lakehouse: Data Engineering’s Answer to AI’s Messiest Problem was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.