
I Tried Applying JVM Garbage Collection to AI Memory
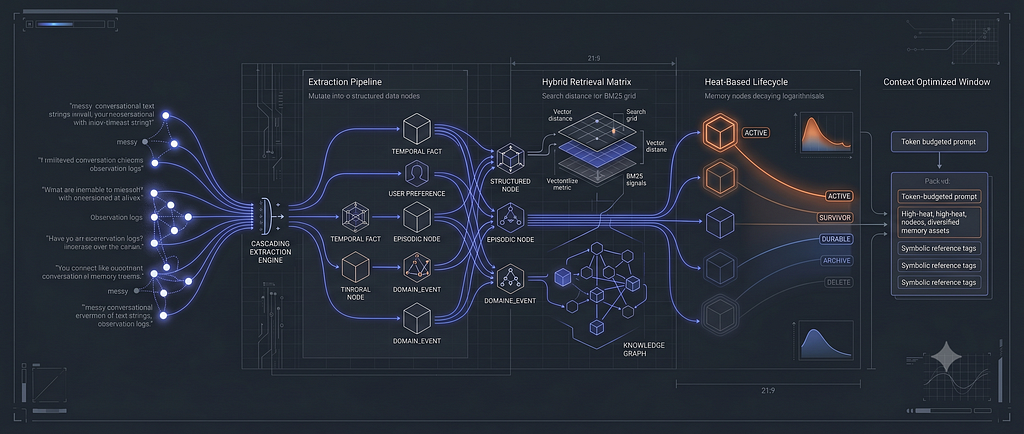
Most AI memory systems focus on one obsessive question: How do we make agents remember more?
While building AMOS (Agent Memory Operating System), I became captivated by a completely different problem:
How do we make them forget?
As AI agents scale, they accumulate thousands of raw conversational logs, shifting preferences, temporal facts, and fleeting observations. Left unchecked, storing this information indefinitely creates severe system degradation:
- The Context Bloat Tax: Prompts swell with stale, contradictory data, driving up LLM cloud costs.
- Retrieval Pollution: Vector database precision drops off a cliff as the haystack grows too large.
- Amnesia over Time: Without a natural lifecycle management system, long-horizon agents inevitably break under the weight of their own history.
The more I explored the problem, the more I realized that database-only architectures weren’t the answer.
Instead, I found myself opening deep documentations on the Java Virtual Machine.
The Accidental Inspiration
The JVM has managed high-concurrency runtime memory efficiently for decades using a beautifully simple empirical observation: Most objects die young.
This principle — the Generational Hypothesis — powers modern garbage collectors.
[New Objects] ──► Ingested into Eden/Young Gen
│ (Does it survive GC cycles?)
▼
Promoted to Old/Tenured Generation
New objects are dirty and short-lived. Only data structures that survive multiple application sweeps get promoted to stable, older storage tiers.
The JVM doesn’t ask: “How old is this byte array?” It asks: “Has this asset proven its utility by surviving?”
That subtle shift changed everything for me. What if we stopped treating agent memory as a permanent dumping ground and started treating it as a dynamic, evolving lifecycle?
Designing an Agent Memory Lifecycle
To bring this concept to life, I mapped out a generational, GC-inspired tiering model within AMOS:
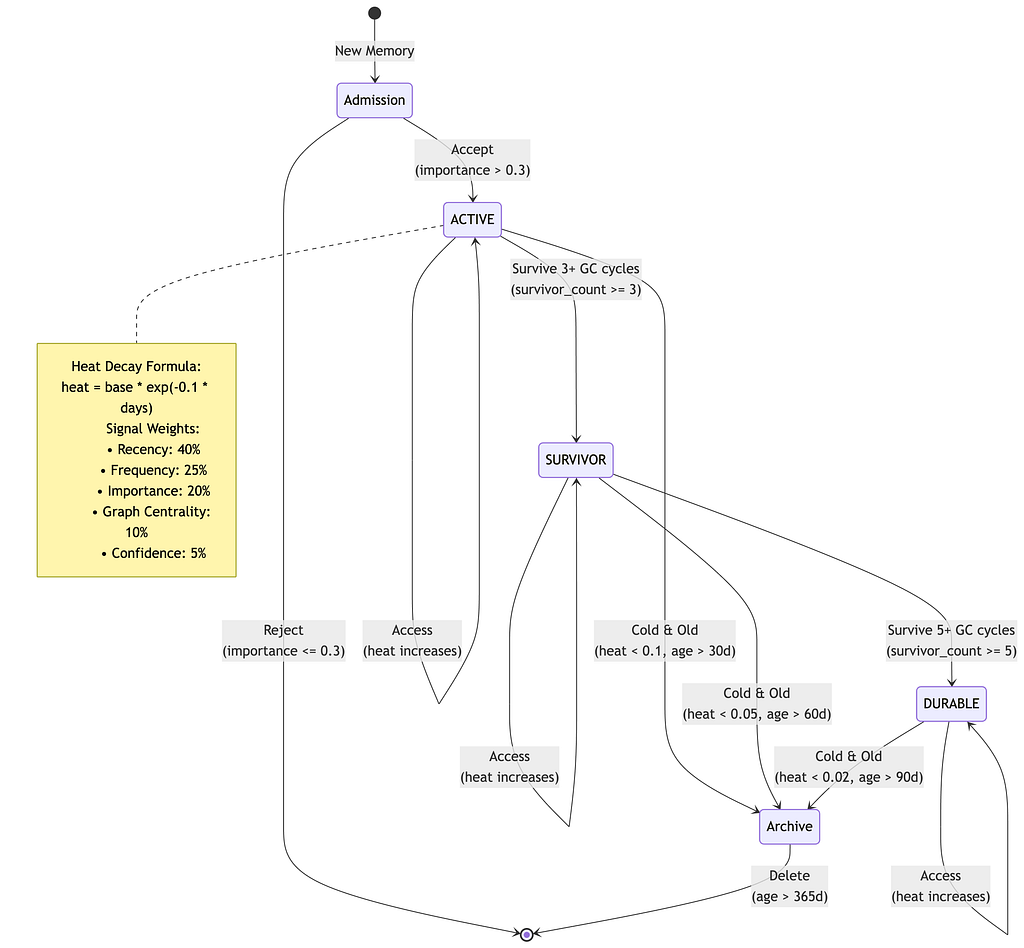
Every incoming user thought or agent action lands directly in the ACTIVE tier.
If it is structurally useful, it survives and migrates upward. Long-lived, deeply integrated memories eventually stabilize into DURABLE knowledge graphs. Cold, highly contextual noise drops gracefully down into the ARCHIVE block for auditing, or faces ultimate deletion.
The goal isn’t to store everything flawlessly. The goal is to discover what deserves to survive.
Why My First Experiment Failed Miserably
My initial prototype looked pristine on paper. I built a straightforward chronological scheduling thread that promoted or evicted memory objects based purely on timestamp deltas:
# The Naive Prototype
if days_since_creation > threshold:
promote_to_older_tier(memory_id)
else:
keep_active(memory_id)
I ran a 30-day accelerated lifecycle simulation using synthetic user data. The results were an architectural disaster.
Almost every single memory chunk piled up in the exact same cold storage tier. Stale, temporary debug inputs were treated with the same permanence as foundational user settings. The system wasn’t executing memory lifecycle management; it was just rewriting database string labels.
The failure exposed a fundamental flaw in my design: Age does not equal value.
Consider two distinct memory strings:
- Memory A: Created yesterday, queried 100 times by the agent to parse a user’s core stack choices.
- Memory B: Created 30 days ago, never accessed a single time since ingestion.
A strict chronological lifecycle promotes Memory B while completely ignoring the active utility of Memory A. To build a robust system, I needed a dynamic metric. I needed Memory Heat.
Calculating the Temperature of a Thought
AMOS assigns a dynamic, multi-dimensional heat metric to every memory node, calculating real-time access frequency, source priority, and network connections:
heat = (Recency × 0.40) + (Frequency × 0.25) + (Importance × 0.20) + (Graph Centrality × 0.10) + (Confidence × 0.05)
To mimic natural cognitive decay, the calculated metric cools down exponentially behind the scenes:
heat_current = heat_base × e^(-0.1 × Δt_days)
This logarithmic cooling model ensures distinct system behaviors:
- Frequently hit user context paths stay permanently hot.
- High-importance structural rules cool down at a heavily suppressed rate.
- Casual conversational noise decays rapidly into the background.
Memory Heat Score (1.0) ──► ──► (No Access) ──► ──► Exponential Decay ──► ──► Archive/Delete (0.0)
Memories no longer shift states because they are old — they migrate because they have earned or lost context relevance.
The AMOS V2 Engine Architecture
Once heat scoring was working, I needed an automated driver to handle the runtime orchestration without introducing heavy resource locks.
The resulting Adaptive Scheduler isolates state promotion from garbage collection sweeps, running as an explicit, background management cycle:
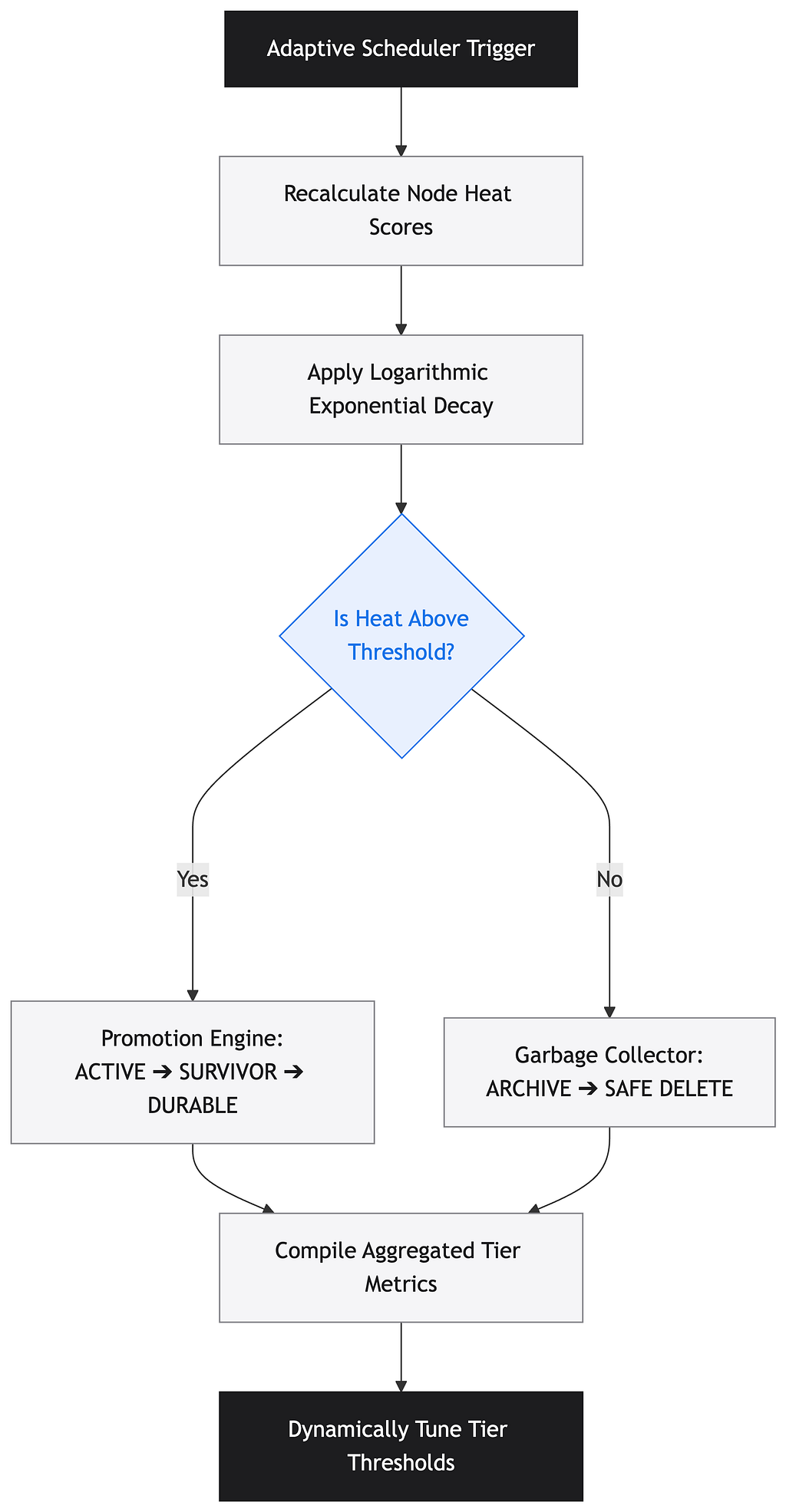
To make this architecture viable for high-concurrency production apps, I concentrated on eliminating the immense operational tax found in contemporary tools:
1. Zero-LLM Cascading Extraction
Most memory frameworks hit external LLMs on every input turn to pull facts, racking up severe API costs and multi-second latency bottlenecks. AMOS runs a fast, local cascading pipeline instead:
- Regex Engines (<0.1ms): Instantly captures explicit structured assignments (e.g., “X is Y”).
- Fuzzy Parsers (~0.3ms): Catches variant syntactic expressions.
- Local Tiny LLM (<100ms Fallback): For complicated edge cases, AMOS routes processing locally to a quantized Qwen2.5-1.5B-Instruct instance using a local vLLM server.

2. Resolving Temporal Mutability
When facts change over multi-session lifetimes (“Alice is a Engineer” becoming “Alice is a Manager”), standard vector storage platforms break down. They retrieve both conflicting string elements and dump them into the prompt window.
AMOS resolves this using a native Temporal Truth Engine, tracking facts as non-overlapping valid time intervals:
[Fact: Alice Title] ──► [Value: Engineer (Valid: 2024 - 2025)] ──► [Value: Manager (Valid: 2025 - Present)]
This lets agents cleanly query exact past states: “What team was Alice managing back in January 2025?”
What I Learned: Memory Is Not a Storage Problem
Building AMOS taught me a crucial lesson about AI architecture: Memory is not a database problem.
Databases are already incredibly efficient at holding records indefinitely. The unresolved engineering hurdle for AI agents is governance.
As architects, we have to start answering cold operational questions at scale:
- Why does this specific memory string still exist in the prompt block?
- What structural dependency prevents this node from being consolidated?
- When exactly did this historical fact become stale and invalid?
These challenges look far less like a standard database query problem and much more like Operating System design.
The future of production-grade agent scaling won’t belong to the frameworks that find a way to ingest the most text into an unconstrained prompt window. It will belong to the engines that learn exactly how to forget intelligently.
📦 Explore the Project
The entire codebase, along with local orchestration benchmarks, mock datasets, and the Model Context Protocol (MCP) server, is completely open-source.
- GitHub Repository: github.com/Nandakumar-Balagopal/amos-memory
Drop an issue or join the discussion if you are actively working on scaling local agent memory infrastructures, generational GC memory architectures, or temporal graph tracking systems!
I Tried Applying JVM Garbage Collection to AI Memory was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.