
Why We Stopped Using Classic Metrics to Evaluate Our LLMs
How LLM-as-a-Judge — implemented with Vertex AI Gen AI Evaluation Service — changed how we measure quality in production

Context: I work with AI engineering teams delivering generative AI solutions in production for large financial institutions. This article comes from practice — including the mistakes that cost us time and credibility.
The problem nobody talks about openly
You put an LLM into production. The first few weeks were exciting. But at some point someone asked: “how do we know the model is actually responding well?”
At that moment, most teams reach for what they know: BLEU, ROUGE, embedding similarity. We ran the scripts, the numbers looked reasonable, and we moved on.
A quick note for those not working with NLP evaluation day to day: BLEU (Bilingual Evaluation Understudy) and ROUGE (Recall-Oriented Understudy for Gisting Evaluation) are metrics that measure lexical overlap — they compare words and word sequences between a generated response and a reference answer. BLEU was built for machine translation; ROUGE, for summarization. Both work well when a well-defined reference answer exists and the goal is to check whether the model “got the right words.” The trouble starts when you step outside that scenario.
And that’s exactly what happened to us.
It’s not that these metrics are wrong — they were designed with legitimate purposes, for translation and summarization tasks with well-defined reference answers. The problem is applying them in contexts where there’s no single “correct answer,” where what matters is whether the response is useful, accurate, and trustworthy for someone who will make a decision based on it.
In a RAG pipeline running over technical and regulatory documentation, a ROUGE-L of 0.62 tells you nothing about whether the model is hallucinating. We learned that the hard way.
What LLM-as-a-Judge is — and why it works
The core idea is simple: if humans can evaluate the quality of a response in a nuanced way, and if a sufficiently capable LLM can simulate that reasoning, then it can act as an evaluator for another LLM.
In practice, you use a model — usually more capable or configured differently — to judge the outputs of another model based on explicit criteria. It’s an automated evaluator with reasoning capability.
There are three main patterns:
Single-judge: One LLM evaluates an output against a rubric. “On a scale of 1 to 5, how accurate is this response given the provided context? Justify your score.”
Pairwise comparison: Two outputs are presented to the judge, which decides which is better and why. Useful for comparing prompt versions or different models.
Reference-based: The judge evaluates the output against a reference answer, but with semantic flexibility — unlike ROUGE, which is purely lexical.
What makes this approach powerful isn’t just the automation. It’s that you can capture dimensions classic metrics completely ignore: tone, level of certainty, absence of fabricated information, appropriateness to the regulatory context.
Our evaluation architecture
I’ll describe how we structured the system in our production environment. It’s not the only way to do this, but it’s what worked for us.
The evaluation pipeline runs asynchronously, decoupled from the main inference flow. This matters: you don’t want evaluation adding latency for the end user.
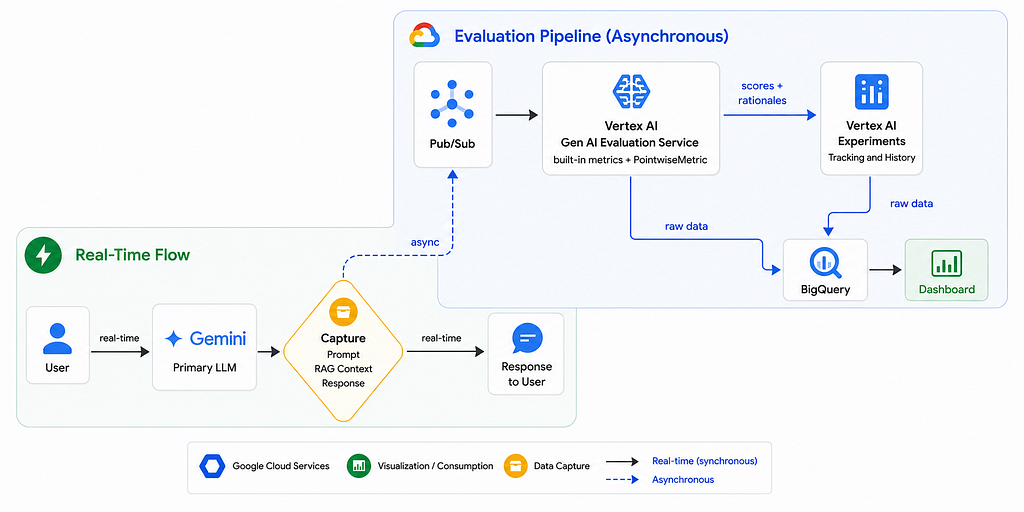
The main model responds to requests in real time. Alongside the response, we capture the context retrieved by the RAG, the full prompt, and request metadata — everything the evaluation service will need.
The evaluation queue receives a package containing {question, context, response} via Pub/Sub, which lets us scale evaluation independently from inference.
The Vertex AI Gen AI Evaluation Service is where the LLM-as-a-Judge actually happens. The service manages the judge model, parallel metric execution, and structured score return — without us having to build that infrastructure from scratch. This was one of the most important decisions we made: stop reinventing the wheel and use what the platform already offers.
Vertex AI Experiments receives the results from each evaluation run and maintains a quality history over time, by model version and prompt type. This gives us traceability without needing complex custom dashboards.
BigQuery persists the raw data for more granular analysis and for cross-referencing evaluation scores with business metrics.
The code that matters
The Vertex AI Gen AI Evaluation Service has two levels we use together: built-in metrics for what’s already well-defined, and custom metrics for criteria specific to our domain.
Built-in metrics: the starting point for RAG
For a RAG pipeline, the most critical metric is groundedness — it evaluates whether the model is answering based on the provided context or fabricating information. The service uses Gemini as the judge internally, and you don’t need to manage any of that.
import pandas as pd
import vertexai
from vertexai.evaluation import EvalTask
vertexai.init(project="your-gcp-project", location="us-central1")
# Evaluation dataset: samples captured from the production queue
eval_dataset = pd.DataFrame({
"prompt": [question_1, question_2, ...],
"response": [response_1, response_2, ...],
"context": [rag_context_1, rag_context_2, ...],
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["groundedness", "coherence", "fluency"],
experiment="rag-pipeline-evaluation", # Vertex AI Experiments
)
results = eval_task.evaluate()
print(results.summary_metrics)
# groundedness/mean: 0.87
# coherence/mean: 0.91
# fluency/mean: 0.94
The experiment parameter connects directly to Vertex AI Experiments — each evaluate() call becomes a traceable run, with a history of scores per model and prompt version.
Custom metrics: where your domain comes in
Built-in metrics cover generic language quality. But a “good response” in our context has criteria the service doesn’t know by default — appropriate certainty level, absence of recommendations that go beyond the regulatory scope, clarity for the target user profile.
For this, we use PointwiseMetric with an explicit rubric:
from vertexai.evaluation import PointwiseMetric, PointwiseMetricPromptTemplate
context_fidelity_metric = PointwiseMetric(
metric="context_fidelity",
metric_prompt_template=PointwiseMetricPromptTemplate(
criteria={
"context_fidelity": (
"Does the response use only information present in the provided context, "
"without introducing external data, claims, or recommendations?"
)
},
rating_rubric={
"5": "Fully faithful. No information outside the context.",
"4": "Mostly faithful, with minimal and safe extrapolations.",
"3": "Some claims not verifiable from the context.",
"2": "Significant mix of context information and external content.",
"1": "Contains hallucinations or clearly fabricated claims.",
},
input_variables=["prompt", "context", "response"],
),
)
# Running alongside the built-in metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["groundedness", context_fidelity_metric],
experiment="rag-pipeline-evaluation",
)
results = eval_task.evaluate()py
Three design decisions in that rubric are worth highlighting.
The criteria are testable, not subjective. “Faithfulness to context” is vague. “Does not introduce data external to the provided context” is verifiable — the judge model can check this consistently.
The rubric has granularity in the middle. A 1-to-5 scale with clear definitions for each point, not just the extremes. This reduces variance in evaluations and makes scores comparable over time.
Built-in and custom metrics run together in the same EvalTask. The service consolidates everything into a single result, and Vertex AI Experiments logs each dimension separately. You can tell whether a problem is generic fluency (built-in) or domain fidelity (custom) — and that completely changes the diagnosis.
The three mistakes that almost cost us dearly
Mistake #1: using the same model as judge of itself
Early on, we used the same model — same version, same system prompt — as the evaluator of its own outputs. Scores were systematically inflated. The model tended to agree with itself.
The fix was using a different model as judge, with a distinct configuration. Not necessarily a more expensive one: sometimes it’s enough to use the same model with much lower temperature and a well-defined critical evaluator persona in the system prompt. The Vertex AI Gen AI Evaluation Service lets you configure the judge model separately — use that to your advantage.
Mistake #2: trusting the score without validating the judge
We built the system, saw high scores, celebrated. Two months later we discovered the judge model had been calibrated too permissively. A portion of responses with obvious hallucinations were receiving a 4/5 on fidelity.
The lesson: you need to validate the judge periodically against human evaluations. Select a random sample of responses every week, do manual evaluation with a consistent rubric, and compare against the automated scores. If the correlation drops, investigate.
Mistake #3: evaluating the response without evaluating the retrieved context
LLM-as-a-Judge evaluates the quality of the response given the context. But if the RAG retrieval is bringing irrelevant or outdated context, the model will “respond well with bad information” — and the judge will give a high score because the response is coherent with the context it received.
We added a second evaluation layer that judges the quality of the retrieval separately. Only then could we distinguish between “LLM problem” and “RAG problem.”
What we learned
LLM-as-a-Judge is not a silver bullet. It’s a powerful tool when used with awareness of its limitations.
What works well: detecting hallucinations, evaluating context fidelity, comparing prompt versions, scaling qualitative evaluation without proportional human cost.
What doesn’t work well: evaluating highly specialized domains where the judge model itself has knowledge gaps, detecting subtle logical reasoning errors, and fully replacing human evaluation for high-risk outputs.
The rule we adopted: automated evaluation for volume and speed, human evaluation for calibration and edge cases. Both need to coexist.
Another important lesson: the investment in the evaluation rubric is the most valuable part of the entire system. A vague rubric produces a vague judge. We spent more time refining the evaluation criteria than writing code — and it was the best-spent time.
Where to start
If you don’t have any evaluation system in production yet, don’t start with the full architecture. Start with the rubric.
Sit down with your team and answer: “what does a good response mean for our specific use case?” Document that in testable criteria. Then build a simple EvalTask with groundedness and run it on 50 real responses captured from production.
# The minimum viable version to start today
eval_task = EvalTask(
dataset=pd.DataFrame({
"prompt": questions,
"response": responses,
"context": contexts,
}),
metrics=["groundedness"],
experiment="initial-evaluation",
)
results = eval_task.evaluate()
You’ll learn more about the quality of your system in that exercise than in weeks staring at dashboards with classic metrics. If groundedness/mean comes in below 0.80, you have a RAG or hallucination problem — and that’s already enough information to prioritize what to fix.
From there, add custom PointwiseMetric entries as you better understand the specific criteria of your domain.
The next article in this series will cover how we automated this pipeline in Vertex AI Pipelines, triggering EvalTask on every new model or prompt version, with alerts configured in Vertex AI Experiments when scores drop below threshold.
If you’re building something similar or have questions about the implementation, reach out in the comments or find me on LinkedIn.
Marcelo Rosa is a Principal GenAI Architect at GFT Technologies, where he leads AI engineering teams delivering generative AI solutions in production for large financial institutions. He works with Vertex AI, Gemini, Google Cloud ADK, and Python.
Why We Stopped Using Classic Metrics to Evaluate Our LLMs was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.