
Karpathy’s 90-Second Time Machine Through 33 Years of Neural Networks
What one of the world’s best AI educators discovered by recreating a 1989 neural network on his MacBook — and what it tells us about 2055.
90 seconds. That’s how long it took Andrej Karpathy to train a neural network that originally needed 3 full days on a 1989 SUN-4 workstation. 3,000 times faster, running silently on a fanless MacBook Air. But that’s not the interesting part.
The interesting part is what happened when Karpathy asked himself a question that only a time traveler could answer: if I could go back to 1989 with everything I know about deep learning in 2022, how much could I improve that model? The answer: a 60% reduction in errors, achieved by changing nothing fundamental — not the data, not the model size, not the compute budget.

Figure 1: Dataset and model scale — 1989 vs 2022
The 1989 Neural Net, in All Its Glory
I should describe the model because the numbers alone are staggering by today’s standards. Yann LeCun’s 1989 paper — the first ever real-world application of end-to-end backpropagation — used a training set of 7,291 images. Each image was 16×16 pixels. Grayscale. The entire neural network had 9,760 parameters, performed 64,000 multiply-accumulate operations, and held about 1,000 activations.
For comparison, a modern vision model deals with datasets of hundreds of millions of high-resolution color images, networks with small few billion parameters, and roughly 10,000,000x more compute. The pixel information flowing into today’s models is about 100,000,000x greater. And yet — the 1989 paper reads remarkably modern. Dataset, architecture, loss function, optimization, experimental results. It’s all there, just smaller.
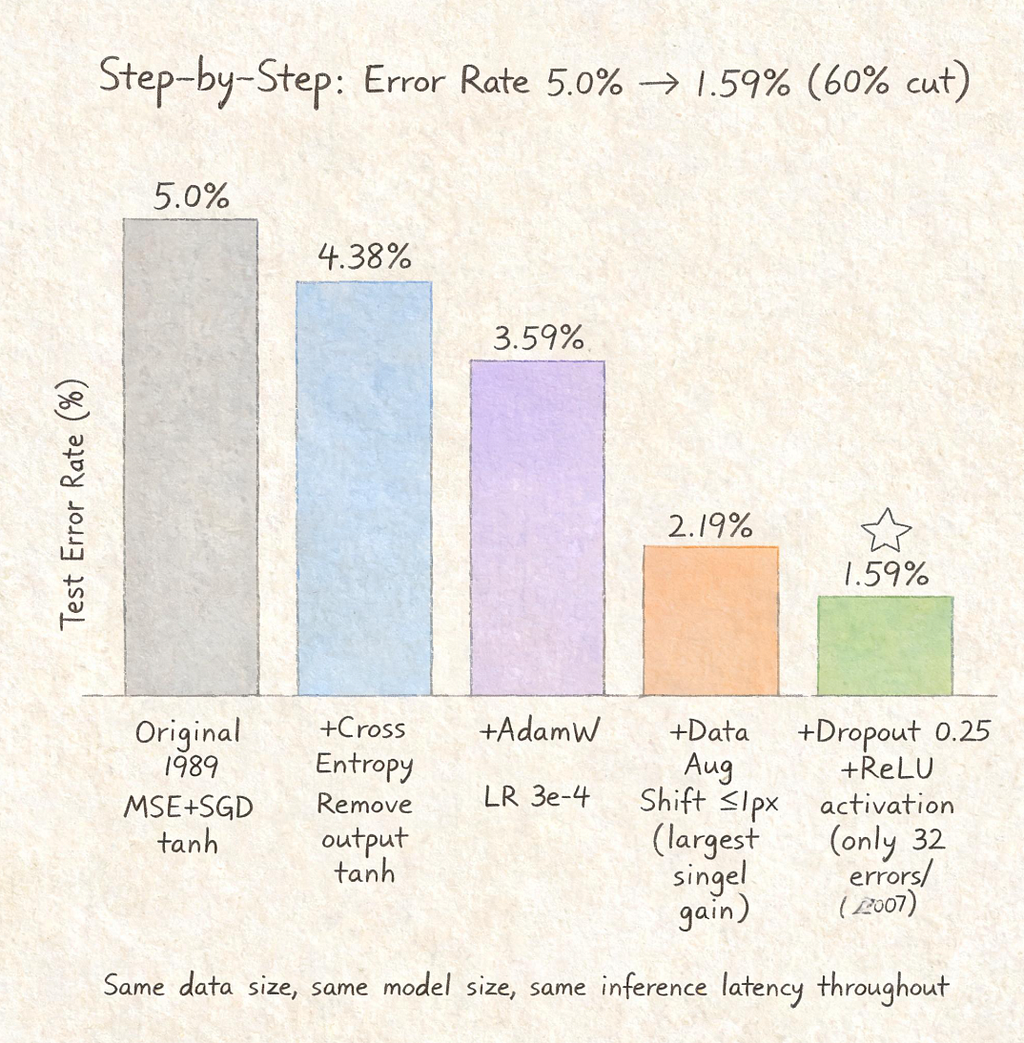
Figure 2: Step-by-step error reduction applying 2022 techniques to a 1989 model
The Surgery
Karpathy’s experiment reads like a surgical log. He applied each modern innovation one at a time, measuring the delta.
Step 1: MSE → CrossEntropy. The original paper treated digit classification as a regression problem with mean squared error. Karpathy swapped in standard cross-entropy loss and removed the saturating tanh from the output layer. The training set immediately overfit to 0% error, but test error inched up slightly to 4.38% — a sign that the optimization surface had fundamentally shifted. [Source: karpathy.github.io]
Step 2: SGD → AdamW. Good old SGD can work, but AdamW with a learning rate of 3e-4 is the universal baseline. Test error dropped to 3.59%.
Step 3: Data augmentation. This was the single largest gain. Simply shifting each input image by up to 1 pixel in a random direction — effectively creating a larger training set — dropped test error from 3.59% to 2.19%. I keep coming back to this number because it’s so clean: the same model, the same data, just a smarter way of presenting it. [Source: karpathy.github.io]
Step 4: Dropout + ReLU. Adding 0.25 dropout before the densest layer and swapping tanh for ReLU pushed the final test error to 1.59% — just 32 mistakes out of 2,007 test images. That’s a 60% reduction from the original 5.0% error rate.
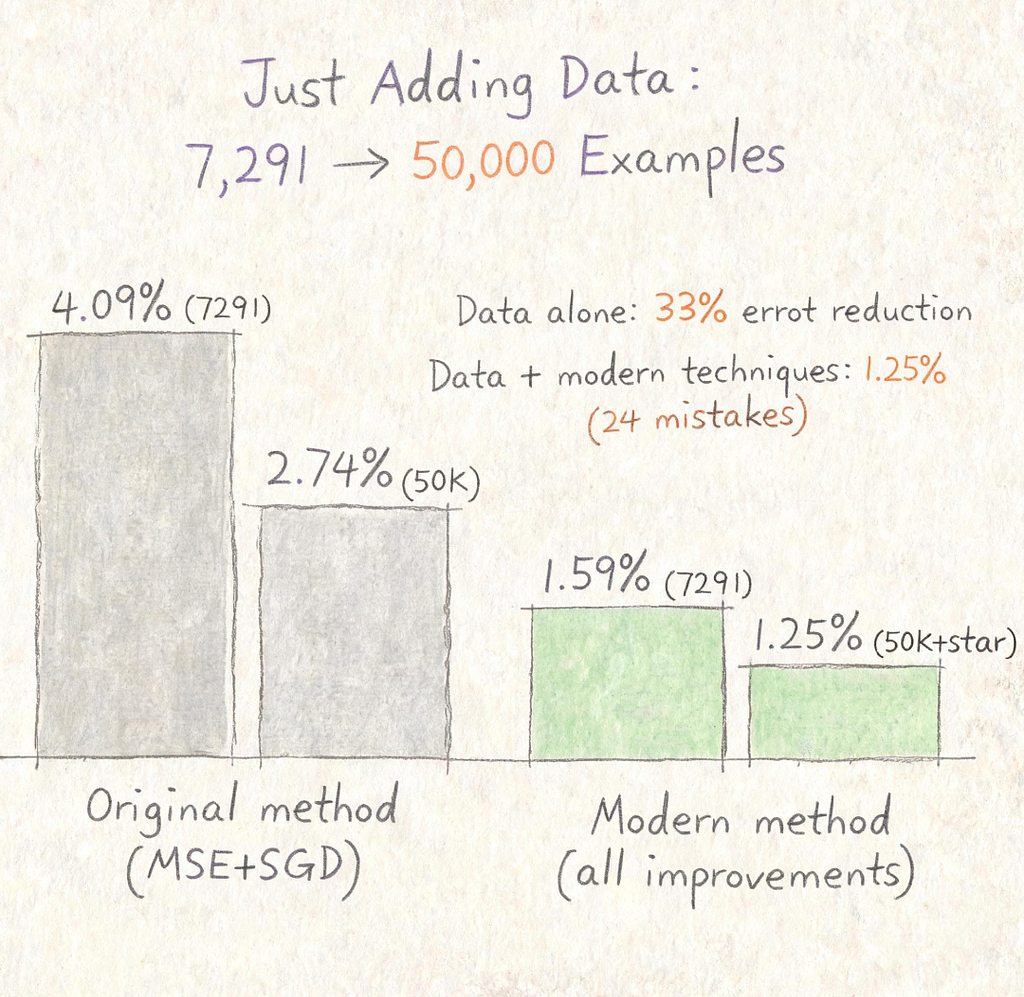
Figure 3: Simply expanding the dataset from 7,291 to 50,000 examples
What Happens When You Just Add Data
Karpathy ran one more experiment that I think doesn’t get enough attention. What if someone in 1989 had simply collected more labeled data? Using the full MNIST dataset (50,000 training examples, roughly 7x the original), the 1989 method alone dropped test error from 4.09% to 2.74%. Combine more data with modern methods, and you hit 1.25% — just 24 mistakes.
The lesson is uncomfortably straightforward: in 1989, someone could have improved the system significantly just by labeling more digits. No algorithmic breakthroughs needed. The bottleneck wasn’t intelligence — it was scale.

Figure 4: From training from scratch to never training at all — three paradigm shifts
The Plot Twist Karpathy Buried at the End
I started this thinking the story was about how much deep learning has progressed in 33 years. I ended up finding something much more disorienting in the final paragraphs.
Karpathy — the man who literally wrote the book on training neural networks, who popularized the “recipe for training neural nets” that thousands of practitioners follow — ends his article by saying: by 2055, you will not want to train any neural networks at all. You will ask a 10,000,000x larger neural net megabrain to perform some task by speaking to it in English. “And if you ask nicely enough, it will oblige. Yes you could train a neural net too… but why would you?”
This isn’t a throwaway line. It’s the logical endpoint of the foundation model trend that GPT, CLIP, and every major model release has been accelerating. Training a model from scratch is becoming like writing an operating system in assembly language — technically possible, increasingly unnecessary, and economically indefensible for most practitioners.
The most useful thing I took from this article, after reading it three times, isn’t the 60% error reduction or the 3,000x speedup. It’s the mental model it forced me to adopt: look at your current training pipeline. How much of it is “1989 thinking” — decisions inherited from a time when models were tiny, data was scarce, and nobody had heard of AdamW? How many percentage points of performance are you leaving on the table by not questioning the defaults?
And second: if Karpathy is right about foundation models, then the most valuable skill in 2026 isn’t knowing how to train a model from scratch. It’s knowing which parts of the stack to stop building yourself.
33 years ago, a neural network with 10,000 parameters was state of the art. 33 years from now, training one might feel like hand-crafting a CPU out of sand. The arc is long, and it bends toward abstraction.
Sources
- Karpathy: Deep Neural Nets: 33 years ago and 33 years from now — karpathy.github.io
- LeCun et al. 1989: Backpropagation Applied to Handwritten Zip Code Recognition — yann.lecun.com
- Karpathy’s lecun1989-repro GitHub — github.com/karpathy
- Foundation Models: Bommasani et al. 2021 — arxiv.org
#AI#DeepLearning#NeuralNetworks#FoundationModels#MachineLearning#ComputerVision#History#Technology
Karpathy’s 90-Second Time Machine Through 33 Years of Neural Networks was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.