
Mechanistic Interpretability: We Built the Most Powerful Minds in History. We Can’t Read Them.
Mechanistic Interpretability: We Built the Most Powerful Minds in History. We Can’t Read Them.
We are flying blind inside the most powerful systems ever built. Here is the map being drawn in real time.
14 min read · AI Research
I want to be honest about what pulled me into this topic.
I had been following AI developments closely for a couple of years — reading papers, tinkering with APIs, following the usual discourse about benchmarks and model releases. And at some point I realised I had absorbed a comfortable but completely hollow understanding of how these systems actually work. I could explain transformers at a high level. I could describe attention mechanisms. But if someone pushed me — what is the model actually doing when it reasons through a hard problem? — I had nothing. Just a vague gesture at “emergent behaviour from training on data.”
That bothered me more the longer I sat with it. Because the same systems I couldn’t explain were being deployed in hospitals, courtrooms, and financial institutions. We were — and still are — making civilisation-level decisions based on outputs we cannot trace, from systems we cannot audit.
That is when I found mechanistic interpretability. And I have not been able to stop reading about it since.
Here is the question at the heart of it — one that should bother you more than it probably does.
We have built machines that write poetry, debug code, pass medical licensing exams, and score in the top 5% of humans on reasoning tests. And we have almost no idea how they actually work.
Not in the hand-wavy “it’s complicated” sense. In the literal sense: when you ask an AI model a question, billions of numbers interact in ways that produce an answer — and the people who built those systems cannot fully explain why that particular answer came out. They can describe the architecture. They can describe the training process. But the actual computation? The specific chain of cause and effect from your input to the output? That is largely invisible.
This is the black box problem. And a small, intense, genuinely fascinating field of research called mechanistic interpretability is trying to crack it open.

Why “It Learned From Data” Is Not an Explanation
When people ask how AI works, the usual answer is something like: “It was trained on vast amounts of text and learned to predict patterns.”
That is technically true and almost completely useless as an explanation.
It is the equivalent of saying a human brain works because neurons fire when stimulated. Correct. Not explanatory.
What we actually want to know is: when an AI reasons through a logic puzzle, what is it doing internally? When it makes a factual error, what went wrong and where? When it refuses a harmful request, what mechanism is responsible — and can that mechanism be bypassed?
These are not academic questions. As AI systems take on higher-stakes roles, the inability to answer them becomes a serious problem. You cannot audit what you cannot read. You cannot fix what you cannot see.
Mechanistic interpretability is the field building the tools to see.
The Two Core Problems: Superposition and Polysemanticity
To understand why reading a neural network is hard, you need to understand two deeply strange things about how they store information. When I first encountered these concepts, I expected them to feel abstract and mathematical. They do not. Once you get the intuition, they feel almost obvious — which makes it all the more surprising that they went largely unrecognised for so long.
Problem 1: Superposition
A neural network has a fixed number of neurons. But the world has far more concepts than any network has neurons to represent them. Evolution found a solution to an analogous problem in biological brains, and AI networks appear to have found something similar: superposition.
Rather than dedicating one neuron to one concept, networks cram multiple concepts into the same neurons simultaneously — representing them as overlapping directions in a high-dimensional space. The network can still distinguish between them most of the time because the overlapping patterns are structured in clever ways. But it means you cannot simply look at a neuron and say “this one detects cats.”
Think of it like a busy CCTV camera pointed at a city intersection. Every frame captures dozens of things simultaneously — pedestrians, cars, weather, signage, shadows. If you wanted to understand what happened at that intersection on a specific afternoon, you can’t just “look at the footage” and isolate one thing. Everything is layered on top of everything else. Superposition is essentially the same problem, but in a space with millions of dimensions instead of two.
Problem 2: Polysemanticity
As a direct consequence of superposition, most neurons in a large language model are polysemantic — they respond to multiple, seemingly unrelated concepts at once. A single neuron might activate for the word “bank,” the concept of a riverbank, financial institutions, and the verb “to store” — all at the same time, in different proportions depending on context.
This is the part that genuinely surprised me when I first read about it. I had assumed that after training, neurons would specialise — that you’d find a “Paris neuron” or a “negation neuron.” Occasionally you do. But the vast majority are messy, multi-purpose, context-dependent. The meaning is distributed, overlapping and deeply entangled.
This makes reverse-engineering a model extraordinarily difficult. You cannot map neurons to concepts one-to-one. You cannot look at a neuron firing and know what it means without understanding the full context of everything else firing around it.
These two problems are why simply “looking inside” a neural network with basic tools tells you almost nothing useful — and why the breakthrough I am about to describe matters so much.

The Breakthrough: Sparse Autoencoders and Features
The mechanistic interpretability community’s most significant recent advance is a technique for cutting through the noise of polysemanticity: sparse autoencoders (SAEs).
The core idea is elegant. Instead of trying to interpret the raw neurons — which are messy and polysemantic — you train a separate, smaller network to decompose the model’s internal representations into a much larger set of features: directions in activation space that each correspond to a single, human-interpretable concept.
Think of it like this. A neuron is a blurry photograph where many things are overlaid on top of each other. A feature is a clean, single image extracted from that blur.
Anthropic’s research has demonstrated that this approach works remarkably well. Using sparse autoencoders on Claude, researchers have identified features corresponding to specific, recognisable concepts — from concrete entities like the Golden Gate Bridge and Michael Jordan, to abstract concepts like “deception” or “uncertainty,” to subtle properties like “this text is from a legal document.”
Each of these features, once identified, can be individually activated, suppressed, or measured. Suddenly, a part of the black box becomes readable.
Circuits: The Grammar of AI Thought
Identifying features is only the first step. The more ambitious goal is understanding how features interact — the circuits of computation through which information flows from input to output.
A circuit, in this context, is a specific pathway through the network: a sequence of features activating each other, combining, and ultimately contributing to the model’s output. Finding circuits means understanding not just what the model knows, but how it reasons.
In March 2025, Anthropic introduced a major new technique called circuit tracing — a unified framework for mapping these computational pathways at scale. The approach replaces a model’s internal components with cross-layer transcoders, producing what the researchers call an attribution graph: a visual, traceable map of how a specific prompt travels through the model from input to output.
Each node in the graph is an active feature. Each edge is a dependency — this feature caused that feature to activate, which contributed to that conclusion. For the first time, researchers could point to a diagram and say: “This is the specific chain of reasoning the model used to answer this question.”
The results were striking. Researchers traced how Claude handles multi-step reasoning, how it detects when it is being asked to do something harmful, and even where hallucinations originate in the computational graph. Anthropic open-sourced the circuit tracing visualisation tool in May 2025, making it available for the broader research community.
Neuronpedia: The Google Maps of AI Internals
If attribution graphs are the maps, then Neuronpedia is the platform that makes those maps explorable by anyone.
Created by Johnny Lin — a former Apple engineer — and launched in early 2025, Neuronpedia is an open-source interpretability platform that gives researchers, developers, and AI safety practitioners a unified interface to explore the internal mechanisms of language models. Think of it as a searchable, interactive encyclopedia of what AI neurons and features actually do.
Here is what makes it remarkable. Before Neuronpedia, studying a specific feature inside a model meant writing custom code, running expensive inference, and building your own visualisation tools from scratch — a process that could take days just to answer a single question. Neuronpedia collapses that to seconds.
The platform lets you:
- Search features by concept — type “deception” or “uncertainty” and find the specific internal directions in the model that correspond to those ideas
- Explore activation dashboards — see exactly which inputs cause a feature to fire, with real examples ranked by activation strength
- Run live steering experiments — inject or suppress features during inference and watch how the model’s output changes in real time
- Browse attribution graphs — visualise the full circuit for a specific prompt, tracing the chain of features from input to output
What is particularly powerful is that Neuronpedia is model-agnostic. Following Anthropic’s open-source release of their circuit-tracing tools, the community has used Neuronpedia to apply those techniques to open-weight models including Gemma-2–2b and Llama-3.2–1b — meaning the interpretability work is no longer confined to what any single lab decides to share.
A note for readers: If you want to experience this firsthand, visit neuronpedia.org and search for any concept that interests you. Watching a feature dashboard load — seeing hundreds of real model inputs that activated a specific internal direction — makes the abstract suddenly concrete. It is one of those rare moments where a research tool genuinely changes how you think about the technology.
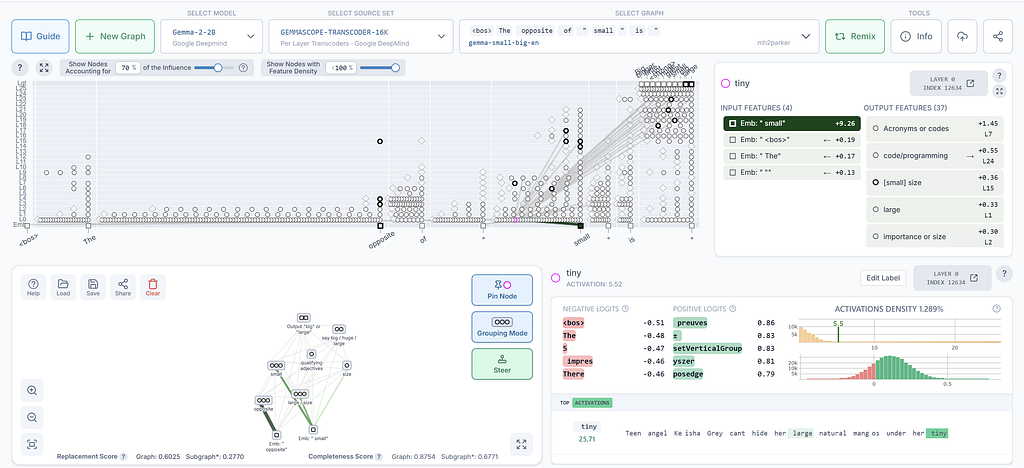
The image above shows an attribution graph for a multi-step reasoning prompt. Each node is a feature. Each arrow is a causal dependency. What looks like magic — a model reasoning through a problem — becomes, in this view, a traceable sequence of concepts activating other concepts.
Try It Yourself: A 5-Minute Neuronpedia Walkthrough
I want to be specific here, because “go explore this tool” is the kind of advice that sounds good and gets skipped. Here is exactly what to do, step by step, and what you will find.
Step 1: Go to neuronpedia.org and select a model — start with gemma-2–2b, which is well-indexed and fast to explore.
Step 2: In the search bar, type a concept you are curious about. Try “deception” first. What loads is a feature dashboard — a ranked list of real text inputs from the training distribution that caused this feature to activate most strongly. Read through them. You will notice they are not random — they cluster around a coherent idea, even if that idea is represented differently across hundreds of examples.
Step 3: Now try something more surprising. Search “uncertainty” or “I don’t know.” Then try “math competition.” Each one surfaces a distinct internal direction the model uses to represent that concept — a direction that, when activated, measurably influences what the model says next.
Step 4: Click into the Logit Lens tab on any feature. This shows you which output tokens this feature pushes toward and which it pushes away from when active. A feature associated with formal writing, for instance, will push toward words like “therefore” and “thus” and away from casual contractions. This is not a guess or a statistical correlation — it is a direct causal measurement.
Step 5: Navigate to the Circuit Explorer and paste in a simple prompt — something like “The capital of France is” or “2 + 2 =”. What renders is a live attribution graph: the actual computational path the model used to reach its answer. Click any node to see which feature it corresponds to and what concept it represents.
The whole exercise takes about five minutes. And I will say from personal experience — seeing your first attribution graph render for a real prompt is the kind of moment that permanently changes how you think about these systems. It is not magic anymore. It is structure.
For Developers: Getting Your Hands Dirty with TransformerLens
If you want to go deeper than a GUI, the standard toolkit for mechanistic interpretability research is TransformerLens — an open-source Python library originally built by Neel Nanda at DeepMind, now maintained by the community and widely used in research labs including Anthropic.
TransformerLens gives you direct access to a model’s internals during inference — activations, attention patterns, residual stream values — with a clean API designed specifically for interpretability research rather than just production inference.
Here is a minimal example of what hooking into a model’s internals looks like:
import transformer_lens
from transformer_lens import HookedTransformer
# Load a model with full activation access
model = HookedTransformer.from_pretrained("gpt2-small")
# Run a prompt and cache all internal activations
prompt = "The Eiffel Tower is located in the city of"
logits, cache = model.run_with_cache(prompt)
# Access residual stream at any layer
residual_layer_6 = cache["resid_post", 6] # shape: [batch, seq, d_model]
# Access attention patterns for any layer and head
attn_pattern = cache["pattern", 3] # layer 3, all heads
With just a few lines you can extract the full residual stream at any layer, inspect attention patterns head by head, patch activations from one run into another to test causal hypotheses, and run sparse autoencoders over cached activations to find active features.
If you want a structured way in, Neel Nanda’s 80-hour mechanistic interpretability curriculum — freely available online — is where most researchers start. It moves from TransformerLens basics through to full circuit-finding exercises on real models. It is one of the most well-constructed technical curricula I have come across in any field.
What Researchers Have Found So Far
The findings from mechanistic interpretability research are, depending on your disposition, either reassuring or deeply unsettling. For me, they are both — sometimes within the same paragraph.
On reasoning: AI models appear to genuinely construct intermediate representations when solving multi-step problems. It is not just pattern-matching at the surface level — there are internal states that correspond to sub-goals, partial conclusions, and backtracking. This suggests something more like genuine reasoning than simple retrieval. The practical implication is significant: if models truly reason through intermediate steps internally, then improving that internal reasoning process — rather than just training on more data — becomes a credible path to better performance. Test-time compute techniques, which we will cover in Part 3, build directly on this insight.
On hallucination: Researchers have traced specific failure modes where the model’s internal “confidence” features are poorly calibrated — the model reaches a conclusion through a chain of plausible-seeming steps, but the chain contains a weak link that isn’t flagged internally as uncertain. What makes this genuinely useful is that it points to a specific, fixable mechanism. Hallucination is not random noise — it has a traceable cause. Understanding it at the circuit level means we may eventually build models that know when they don’t know, rather than confabulating fluently.
On deception: Some of the most striking and concerning findings involve what happens when models are prompted to be deceptive. Researchers have found internal features that activate specifically for “I am saying something I don’t internally represent as true” — evidence of something resembling metacognition. The existence of these features raises profound questions about what AI models actually “know” versus what they “say.” I find this finding both fascinating and genuinely important for AI safety — if we can reliably detect when a model’s outputs diverge from its internal representations, that is a powerful tool for alignment.
On jailbreaks: Circuit tracing has revealed that jailbreak attacks — prompts designed to bypass safety training — often work by suppressing specific safety-relevant features rather than fundamentally changing the model’s reasoning. This means current jailbreaks are less like convincing the model to do something it wouldn’t otherwise do, and more like temporarily blinding the part of the model that would object. Understanding this mechanism points directly toward more robust defences — ones that protect the features themselves rather than just training on more refusal examples.
The Scale Problem — And Why It Is Not Defeated Yet
It would be misleading to suggest that mechanistic interpretability has solved the black box problem. It hasn’t. Not even close.
The techniques that work well on small, carefully studied models run into serious difficulties at frontier scale. A model like Claude or GPT-5 has hundreds of billions of parameters, millions of potential features, and circuits of extraordinary complexity. Mapping even a single reasoning chain fully can take days of researcher time.
The field is split on the fundamental question of whether full mechanistic understanding of frontier models is even achievable in principle. Some researchers believe that with better automated tools, the complexity is manageable. Others argue that large models are simply too complex for human-comprehensible circuit-level explanation — that the best we can hope for is statistical characterisation rather than mechanistic understanding.
What is clear is that the tools are improving fast. DeepMind’s Gemma Scope 2, Anthropic’s open-source circuit tracer, and a growing ecosystem of community tools are making interpretability research more accessible and more powerful every year.
Why This Matters Beyond the Lab
Mechanistic interpretability might sound like a niche academic concern. It is not.
Few people have articulated the stakes more clearly than Dario Amodei, CEO of Anthropic. In his April 2025 essay The Urgency of Interpretability, he made a case that should be required reading for anyone thinking seriously about AI. His central argument: the opacity of modern AI systems is not a technical inconvenience — it is the root cause of almost every serious risk associated with the technology.
As Amodei wrote, when a generative AI system does something, we have no idea at a specific or precise level why it makes the choices it does. Unlike traditional software, where every behaviour was explicitly programmed by a human, these systems are — as his co-founder Chris Olah is fond of saying — grown more than built. Their internal mechanisms are emergent rather than designed. And that gap between what we built and what we understand is, Amodei argues, both unprecedented in the history of technology and urgently in need of closing.
What makes his framing compelling is the race framing. The field of AI capabilities is advancing faster than interpretability research. If interpretability doesn’t mature in time — before models reach an overwhelming level of power — we may find ourselves deploying systems we fundamentally cannot audit, correct, or trust. The window to solve this problem before it becomes critical may be narrower than most people realise.
For AI safety, interpretability is therefore arguably the most important research direction in the field. Anthropic has stated publicly that its goal is to reliably detect most AI model problems by 2027 using interpretability tools. If you want to know whether an AI system is being deceptive, whether it has dangerous beliefs it is concealing, or whether its safety training is robust or brittle — interpretability is the only credible path to those answers.
For regulation, the EU AI Act, fully applicable from August 2026, imposes transparency and explainability requirements on high-risk AI systems. Mechanistic interpretability is one of the few research directions that could actually deliver the kind of explanations regulators are asking for.
For developers, the emerging toolkit — sparse autoencoders, circuit tracers, Neuronpedia, activation patching — means that debugging model behaviour is becoming a real engineering discipline rather than an empirical guessing game. In a few years, “I checked the attribution graph and found the hallucination originates at layer 24” may be as routine as reading a stack trace.
For everyone else, it matters because trust requires understanding. We are making civilisation-level decisions based on the outputs of systems we cannot read. Mechanistic interpretability is the field trying to change that — and if Amodei is right, the urgency of doing so has never been higher.
The Bigger Picture
There is something philosophically vertiginous about this field.
We built these systems. We designed every component, every training step. And yet they have developed internal structures, representations, and computational strategies that surprise their creators. Finding a feature that corresponds to “the concept of deception” inside a language model — a feature that activates reliably and causally influences outputs — raises questions that go beyond engineering.
Is it a feature of the world, captured from training data? Is it a useful internal abstraction the model constructed for its own purposes? Does it tell us something about the nature of intelligence itself?
Mechanistic interpretability researchers tend to be careful about overclaiming. They emphasise that finding a feature labelled “deception” does not mean the model is being deceptive, any more than finding a neuron that responds to faces means a person is thinking about faces at that moment. The map is not the territory.
But the maps are getting better. And the territory is starting to come into focus.
What I find most compelling about this field — and the reason I wanted to write this series — is that it is one of the few areas of AI research where the work feels genuinely urgent and genuinely tractable at the same time. The problems are hard. The tools are improving fast. And the window to solve them before they become critical is narrowing.
If you take one thing from this piece, let it be this: go open Neuronpedia and spend five minutes with it. Search for a concept that matters to you. Look at what the model actually built internally to represent it. That experience, more than any explainer I could write, will change the way you think about what these systems are.
Then come back and tell me in the comments — what feature surprised you most?
If this sparked a question or a disagreement, drop it in the comments — the best parts of this conversation happen there.
Tags: Mechanistic Interpretability · Artificial Intelligence · LLM Research · AI Safety · Machine Learning
Mechanistic Interpretability: We Built the Most Powerful Minds in History. We Can’t Read Them. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.