
Governing A.I. in the Enterprise
Notes from the Security Architect’s Chair
When we stood up our Security Architecture function, we were working across several distinct operating divisions, each with its own technology DNA. I expected AI governance to be one workstream among many. Instead, it became the workstream that is reshaping many of the others. Not because AI is uniquely dangerous (every technology wave brings its own risk), but because it bends the assumptions our control frameworks were built on. Identity, blast radius, change control, vendor risk: all of them behave differently when the thing acting on your data is non-deterministic, potentially third-party, and increasingly autonomous.
This article is aimed at practitioners who are past the “should we allow ChatGPT?” stage and are now considering the harder questions: What does a durable AI control posture look like? How do you scope it, and how do you move quickly without building the wrong thing?
The mistake I see some organizations make is treating AI governance as a policy problem. It is not. It is an operating model problem. Policy matters, but durable governance also requires architecture, telemetry, identity, runtime enforcement, and a repeatable way to approve innovation without losing control of your environment.
The shift that changed our playbooks (and probably will yours)
Most enterprise security models assume a clean separation between human users, the systems they use, and the data those systems touch. We govern the human (identity, access), we govern the system (configuration, patching, logging), and we govern the data (classification, DLP, retention). It works because each layer has a relatively stable boundary.
Generative AI compresses those layers. The system may not rewrite its code with every prompt, but its behavior can change materially based on user instruction, retrieved context, tool access, model version, and memory. The user can now be another model. The data now moves through inference paths, retrieval layers, embeddings, prompts, and context windows that rarely appear in a CMDB. Your DLP rules were written for files; the exposure path is now a conversation, a retrieval call, or a context window.
The shift from chat-style copilots to agentic systems makes this acute. A copilot suggests; an agent acts. Once an agent has tools, MCP servers, a connector to your ticketing system, a code execution sandbox, a browser, or access to internal repositories, the question is no longer simply: What did the user see? The better question is: What did the agent do, on whose behalf, with what authorization, and how do you turn it off when something goes wrong? If you cannot answer those four questions for the agents already running in your environment, you are playing catch-up.
Consider a developer agent with access to source repositories, ticketing systems, internal documentation, and a CI/CD pipeline. On paper, it is just assisting an engineer. In practice, it may read sensitive design documents, summarize vulnerabilities, generate code, open pull requests, and trigger builds. That is not a chatbot risk profile. That is an identity, authorization, change-control, and auditability problem wearing a chatbot interface.
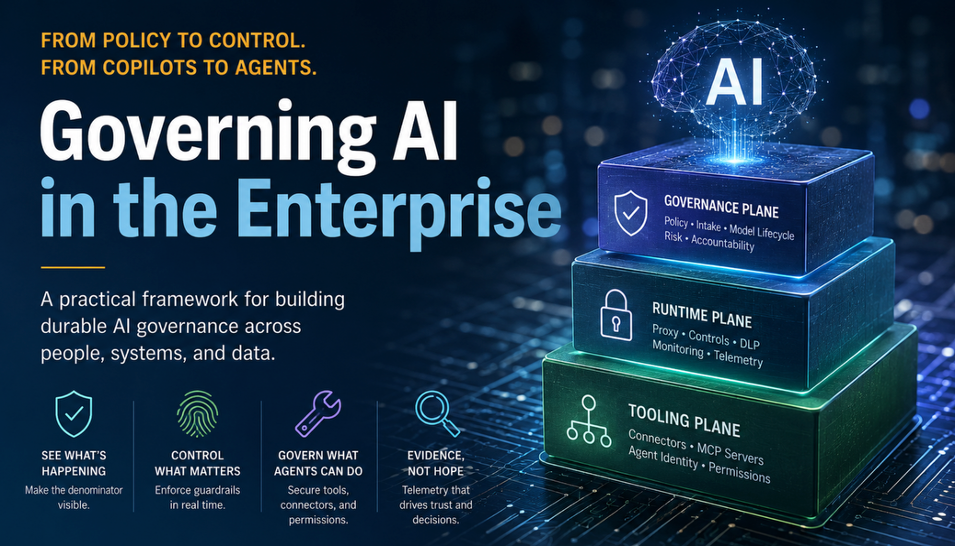
The control planes
I organize AI governance across three control planes. They have different owners, different vendors, and different failure modes. Trying to collapse them into one workstream is how programs stall.
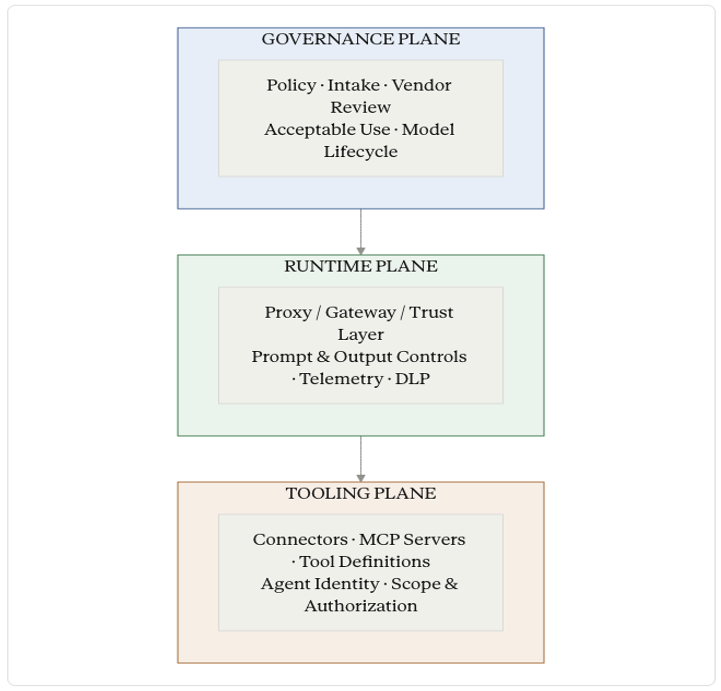
The governance plane is the slowest layer: policy, intake, vendor review, acceptable use, and model lifecycle. It answers two basic questions: should we use this, and under what conditions? Most organizations have something here already, even if it is stitched together from third-party risk, legal review, privacy input, and an AI ethics committee that meets once or twice a month. In our model, GRC and Security Architecture co-anchor this plane. GRC owns the risk and policy lifecycle; Security Architecture defines the control standards that sit underneath it.
The runtime plane is where real work happens, and it is where most programs are weakest. This is the proxy, gateway, or trust layer between users and models. It enforces what data can leave, what prompts are allowed, and what outputs are filtered. It is also where you log. Without a runtime plane, you do not have evidence; you have hope.
The tooling plane is the newest and most volatile layer: connectors, MCP servers, and the tool definitions an AI system uses to act on other systems. This is where agentic risk concentrates. A model that can read a ticket and write a pull request is exercising privilege your IAM team may never have reviewed. The tooling plane is where you decide what an agent is allowed to touch, how that authorization is bounded, and how you revoke it when something goes wrong.
A practical division of labor has worked well for us. Architecture defines the what and the why: reference patterns, threat models, and control standards across all three planes. Security operations owns the how and the when: detection, response, and evidence on the ground. Architecture and operations are the technical backbone, but they cannot be the whole operating model. Legal and privacy define contractual and regulatory boundaries. Third Party Risk Management needs to detect AI capability changes in existing SaaS. AI Strategy and Transformation owns use case prioritization and the AI portfolio. Product and engineering need clear adoption patterns. The CISO needs one accountable governance mechanism rather than five disconnected review boards.
AI governance is one of the rare domains where gaps between those functions become visible almost immediately. The runtime plane only works if architecture defines what to log and operations consumes that telemetry. Build the handoff intentionally; do not assume it will happen because the word governance appears in the title.
Vendors will tell you they cover all three planes. Most cover one and a half. Build the model first, then map vendors against it, not the other way around.
The board-level conversation is changing too. AI risk is no longer limited to data leakage or hallucination. Executives are asking whether the organization can explain where AI is used, what decisions it influences, which vendors process sensitive data, how outputs are validated, and who is accountable when an AI-enabled process enthusiastically makes the wrong call. Security Architecture does not own all of those questions, but we often own the evidence layer that makes them answerable.
The denominator problem
Here’s a question that derails AI governance programs: what percentage of your organization’s AI usage do you currently see?
Most teams cannot answer it because the denominator, total AI activity, is unknown. You might have a solid inventory of approved tools, but little visibility into shadow AI, browser-based usage from unmanaged devices, or AI features quietly added to SaaS products you already pay for. Your coverage is a fraction with a known numerator and a fictional denominator.

The first job of an AI security program is not to add controls. It is to make the denominator visible. That means egress telemetry, browser-side discovery, SaaS posture tools that flag new AI features, and (the one I have seen teams miss most) an intake process that triggers on architecture change, not vendor change. The vendor was approved last year; the agent it just shipped was not. If your governance front door only opens for new vendors, you will miss a lot of what is actually changing in your environment right now.
Once the denominator is visible, control decisions become manageable. Until then, you’re optimizing a number you can’t measure.
What good looks like
Good AI governance does not start with a perfect inventory or a universal policy. It starts with a small number of repeatable patterns. Classify AI use cases by risk: internal productivity, customer-facing content, decision support, code generation, and agentic action. Define the baseline controls for each tier. Route AI traffic through observable runtime paths wherever possible. Treat connectors and tools as privileged access, not convenience features. Then use telemetry to update governance decisions as the capability changes. The goal is not to approve AI once. The goal is to keep governing it as the system underneath you keeps moving.
Enable, don’t gate
Our instinct in security is to slow things down until we understand them. With AI, that instinct will very likely sideline you. The ecosystem is moving faster than any review cadence you can run, and the business will route around you if your default answer is to wait.
The posture I have come to is to enable with conditions. For any AI capability worth deploying, there is almost always a minimum viable control set: managed configuration, telemetry to a SIEM, endpoint policy that blocks the unmanaged version, and a documented review process for new connectors. Define that floor. Make it a one-page checklist. Approve quickly against it. Reserve your no for the small set of cases where the conditions cannot be met.
For most enterprise AI use cases, the fuller control set I look for builds out from that floor: an approved identity path, a documented data classification boundary, managed endpoint or browser controls, prompt and output telemetry, retention expectations, vendor data-use terms, connector review, and a revocation path. Sensitive use cases can require stronger controls, but they should not require inventing the governance model from scratch.
A recent example: an agentic developer assistant was about to land on every engineer’s laptop, and the path of least resistance was a multi-week security review that would have been obsolete before it finished. Instead, we published a tiered adoption pattern with three options: browser-only with baseline controls, CLI with additional controls, and CLI plus an enterprise model gateway with full controls. Teams then chose the tier that fit their work. We spent our time defining the tiers, not approving individual cases. A few weeks later, the same pattern absorbed two more vendor requests with minor adjustments. That is the leverage you want: a structured adoption framework that lasts longer than any one vendor’s or team’s roadmap.
This changes the conversation with the business. Instead of becoming the team that blocks AI, you become the team that defines how AI gets enabled. The cultural difference is enormous, and it changes who gets called early on the next request.
Agentic as the forcing function
The shift to agentic systems is the best thing that has happened to enterprise AI governance, because it forces decisions many organizations have been able to defer.
When the request is “can we use this model for content generation?” you can often manage it through acceptable use, data handling rules, and vendor terms. When the request is “can this agent take action in our environment on behalf of users?” you have to confront harder questions:
· Identity. Who is the agent acting as? Is it a human identity, a service account, or something new your IAM model doesn’t have a slot for?
· Authorization. What scopes does it have? Are those scopes least-privilege, or inherited wholesale from the human who launched it?
· Evidence. What did it do? Can you reconstruct the chain? Is that telemetry going somewhere your detection team actually monitors?
· Revocation. How do you turn it off cleanly when something goes wrong, without breaking the legitimate work it’s doing?
These are the same questions we should have been asking about RPA, service accounts, and integration platforms for years. AI is simply the technology that has made them impossible to ignore.
If you are scoping an AI governance program right now, treat the next agentic request that lands on your desk as the forcing function. This works in practice: taking one high-visibility enablement request and using it to fund runtime and tooling plane work that benefits every future agent, every future model, and every future SaaS feature that quietly grows an agentic tab. The trick is to have that conversation with your CISO, CDTO, and AI Strategy lead early, before “approve this one thing” becomes the only question on the table. By the time the deck is in front of leadership, the right answer should be yes, and here is the foundation we are building underneath it.
A note on scaling the practice
You will not staff your way through this. AI governance demand grows faster than headcount approvals, and small architecture teams in particular need leverage.
The teams I have seen keep up are the ones using AI to scale their own practice: intake triage assistants, generated reference architectures, structured threat-modeling copilots, and control-mapping helpers tuned to internal standards. If AI is the forcing function for new controls, it is also the lever that lets a small architecture team meet enterprise-wide demand. Practice what you are trying to govern. The dogfooding sharpens your control posture in ways no whitepaper ever will.
What I’m watching
The vendor landscape is still consolidating. The runtime plane is the most contested: every CASB, DLP, and AI security startup wants to own it, and they do not all play well together. The tooling plane is where the biggest shifts are coming, especially around MCP-style standards and how identity flows through tool calls. The governance plane will increasingly look like classic third-party risk, only faster, with more sub-processors and model lifecycle layered on top.
The unsexy work still wins more battles than any new vendor or solution: sensitivity labeling, DLP that actually fires, an intake process that scales, and a runtime layer that logs. If your data is not classified, no AI control will save you. If your runtime is not logged, no policy matters.
Build the planes. Make the denominator visible. Enable with conditions. Use the next agentic request to fund the foundation. The rest is iteration.
Governing A.I. in the Enterprise was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.