")
How AI Learns to Pretend to Be Human (DeepFake Videos)
Modern AI-generated video systems are often discussed as though they emerged from a single breakthrough model. In practice, they resemble distributed software systems far more than singular inventions. The realism people associate with synthetic avatars, AI presenters, or deepfakes is not the result of one network suddenly “learning video.” It comes from the orchesation of multiple specialized systems operating across different representations of information: text embeddings, latent image spaces, phoneme timings, motion constraints, temporal attention layers, and post-processing pipelines.
What appears externally as a short talking-head clip is internally a coordinated negotiation between models solving different problems simultaneously. One system tries to preserve identity. Another predicts mouth motion from speech. Another attempts to maintain visual continuity across frames. A separate subsystem cleans artifacts introduced by generation itself. The final output is less comparable to a rendered video and more comparable to a continuously stabilized simulation.
The reason this distinction matters is that public understanding of generative AI still tends to frame these systems as analogous to autocomplete for images. That analogy works for early image models, but it begins to fail when generation becomes temporal. Video introduces continuity constraints that fundamentally change the engineering problem. A convincing still image can tolerate inconsistency because the human visual system evaluates it instantaneously. Video is evaluated comparatively. Every frame is judged against the frame before it. Small deviations that are invisible in isolated images become glaringly obvious once motion is introduced.
This is why early AI-generated videos felt uncanny even when individual frames looked impressive. Faces subtly changed shape between frames. Lighting flickered. Eyes shifted asymmetrically. Mouth movement drifted out of sync with speech. Hair appeared to melt and reform. The challenge was no longer simply generating realism, but preserving coherence over time.
Most modern systems solve this through a layered architecture that resembles production infrastructure more than artistic tooling. The process begins long before any frame is rendered.
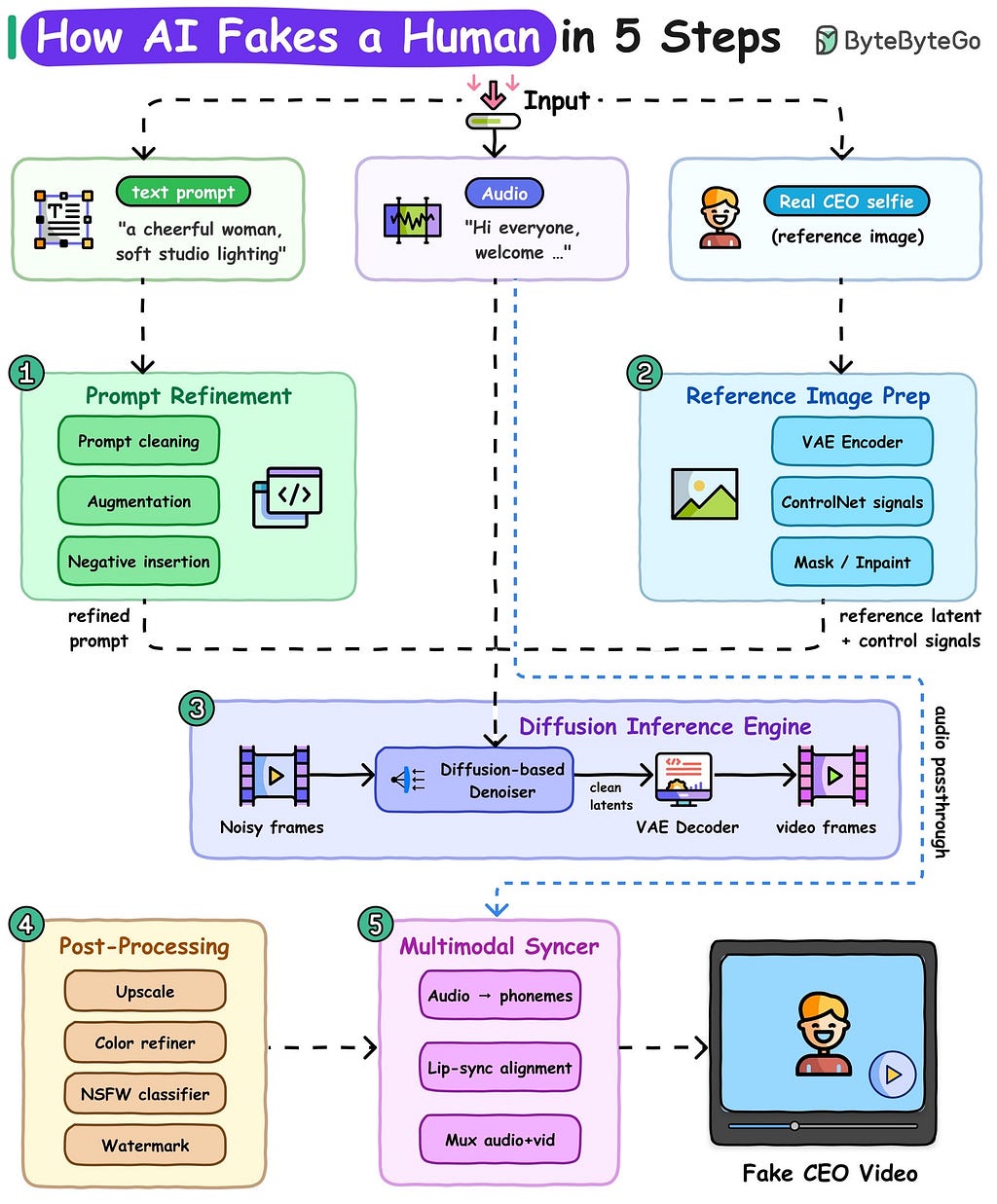
A typical pipeline starts with three independent inputs: a textual prompt, an audio stream, and a reference image. Each input serves a different role within the generation process, and importantly, each exists because no single modality contains enough information to generate a convincing talking human on its own.
The text prompt establishes semantic direction. It specifies visual intent in the same way cinematography notes might guide a human production crew. Descriptions such as “soft studio lighting,” “professional office environment,” or “warm cinematic tone” do not merely affect aesthetics. They constrain the diffusion process toward a narrower probability space.
“Without textual conditioning, generation becomes unstable because the model lacks guidance regarding style, mood, and composition.”
Interestingly, production systems rarely use raw prompts directly. Prompt refinement layers frequently sit in front of the actual inference engine. These layers operate somewhat like query optimizers in databases. Their goal is not creativity but constraint reduction. Ambiguous language is normalized, conflicting descriptors are removed, and missing contextual detail is inferred automatically.
A user may provide a prompt such as “a smiling woman in an office,” but internally the system may expand this into a much denser representation containing inferred descriptors about lighting, camera depth, facial detail, lens characteristics, and image quality priors. Negative prompts are often inserted as well, instructing the model to avoid known failure modes like facial asymmetry, extra limbs, blurred eyes, or anatomical distortion.
This preprocessing stage reflects a broader pattern in machine learning systems: production reliability often depends more on input shaping than raw model intelligence. Similar patterns exist in search ranking systems, recommendation infrastructure, and autonomous agents. The quality of downstream inference is frequently determined by the quality of constraints established upstream.
The second input, audio, introduces a completely different category of information. Unlike prompts, which establish semantic appearance, audio establishes temporal structure. Human speech contains precise timing information that governs facial motion at millisecond scales. Every syllable corresponds to a series of phonetic transitions, and those transitions map directly to muscular movement around the jaw, lips, cheeks, and tongue.
This creates one of the more fascinating aspects of synthetic video systems: speech becomes a control signal for geometry.
The audio stream is first transformed into intermediate linguistic representations, usually phonemes or visemes. A phoneme represents a unit of sound, while a viseme represents its corresponding visual mouth shape. The distinction matters because multiple phonemes can map to similar visual configurations. The sounds “b” and “p,” for example, are visually difficult to distinguish despite being acoustically different.
Modern lip synchronization systems therefore operate as alignment models rather than direct audio renderers. Their job is to predict how facial geometry should evolve over time in response to speech dynamics. This prediction process resembles sequence modeling problems seen in language translation or speech recognition. Temporal accuracy matters immensely because humans are unusually sensitive to audiovisual mismatch. Delays beyond even small thresholds begin to feel unnatural.
The third input, the reference image, solves perhaps the hardest problem in generative video: identity persistence.
Without identity anchoring, diffusion models tend to drift. Small stochastic changes accumulate across frames, gradually mutating the generated subject. A face may subtly age, eye spacing may change, or hair structure may fluctuate between frames. Individually these deviations appear minor, but collectively they destroy realism.
Reference conditioning systems attempt to stabilize this by extracting persistent facial features into latent representations. This typically involves a variational autoencoder, or VAE, which compresses the source image into a lower-dimensional latent space while preserving semantic structure. Rather than operating directly on pixels, the model works on compressed feature embeddings representing facial geometry, texture distributions, and structural relationships.
The architectural advantage here is significant. Latent representations drastically reduce computational cost while preserving high-level information density. Operating directly in pixel space for video diffusion would be prohibitively expensive at modern resolutions and frame counts. Latent spaces provide an abstraction layer similar to intermediate representations in compilers: they remove unnecessary detail while preserving the information needed for downstream transformation.
Yet latent compression alone is insufficient for stable motion. Modern systems increasingly rely on additional conditioning frameworks such as ControlNet-like architectures that inject structural constraints into the diffusion process. These systems guide generation using auxiliary signals like facial landmarks, pose skeletons, edge maps, or depth information.
The conceptual role of these control systems is remarkably similar to constraints in physics engines. They narrow the solution space. The diffusion model remains generative, but it is no longer free to hallucinate arbitrary geometry. Instead, it must satisfy structural conditions imposed externally.
This balance between freedom and constraint appears repeatedly across generative systems engineering. Unconstrained generation produces creativity but poor consistency. Excessive constraint produces stability but low diversity. Practical systems operate somewhere in between, selectively freezing certain attributes while allowing variation elsewhere.
Video generation itself occurs within the diffusion inference engine, which functions as the computational center of the pipeline. Diffusion models are conceptually elegant but operationally expensive. The process begins with noise and iteratively removes uncertainty until coherent imagery emerges.
The simplest analogy is sculpting from static. Each denoising step attempts to answer a probabilistic question: given the current noisy state and all conditioning information, what should this frame look like if it belonged to the desired distribution?
For still images, this process is already computationally intensive. For video, complexity increases dramatically because temporal consistency must also be maintained. The model cannot evaluate frames independently. Every generated frame influences the plausibility of adjacent frames.
This introduces the need for temporal attention mechanisms and motion-aware conditioning. In practice, video diffusion systems often operate more like spatiotemporal transformers than pure image generators. Attention layers must reason not only across spatial regions within a frame but also across sequences of frames over time.
The engineering implications are substantial. Memory requirements grow rapidly because temporal context must be preserved during inference. Training datasets become significantly more difficult to curate because sequential consistency matters as much as visual quality. Inference latency increases because generation becomes dependent on neighboring frames.
This is one reason why early generative video systems remained short in duration. Producing even a few seconds of coherent motion required enormous computational resources. Frame coherence is expensive because entropy accumulates over time. Small prediction errors compound recursively.
An interesting parallel exists here with distributed systems reliability. A single failed request in a large infrastructure environment may be tolerable. Continuous small failures over time eventually destabilize the system. Video diffusion behaves similarly. Minor visual inconsistencies that are individually acceptable eventually become perceptually catastrophic when compounded temporally.

Post-processing pipelines exist largely to compensate for these accumulated imperfections.
Upscaling systems restore detail lost during latent compression and low-resolution inference. Color refinement layers smooth temporal lighting fluctuations. Artifact detection systems attempt to identify broken geometry, inconsistent skin textures, or unstable motion regions.
Many production systems also incorporate moderation and watermarking layers at this stage. The inclusion of safety classifiers is not merely policy-driven but operationally necessary. Generative systems frequently produce outputs that violate visual constraints unpredictably. Automated filtering becomes part of the reliability architecture.
Watermarking introduces another emerging engineering challenge: provenance verification. As synthetic media quality improves, the distinction between generation and recording becomes increasingly difficult to establish visually. Invisible watermarking systems attempt to embed recoverable statistical signatures into generated outputs, though their robustness remains an active area of research.
The final synchronization stage combines all previous outputs into a temporally aligned audiovisual stream. Audio and video are muxed together, phoneme timings are refined, and subtle alignment adjustments are made to preserve natural speech perception.
Ironically, this last stage often determines whether the entire pipeline feels convincing. Humans tolerate a surprising amount of visual imperfection if timing remains coherent. Conversely, even photorealistic frames become unsettling when lip synchronization drifts slightly off.
This reflects a broader truth about realism in synthetic systems: perception is often governed less by absolute fidelity than by consistency across modalities. The brain evaluates coherence more aggressively than detail.
The rise of these architectures has broader implications beyond entertainment or internet culture. They represent an emerging class of multimodal systems in which independent models coordinate through shared latent interfaces. The future significance may lie less in AI-generated presenters and more in what these systems reveal about general-purpose multimodal reasoning architectures.
A modern video generation stack resembles a distributed operating system for probabilistic media synthesis. Specialized subsystems exchange compressed representations, negotiate constraints, and collaboratively stabilize outputs under uncertainty. The architecture is modular because the problem itself is multidimensional.
This modularity also explains why the ecosystem evolves so rapidly. Improvements in one layer propagate across the stack. Better speech alignment improves avatar realism. Better latent compression reduces inference cost. Better temporal attention stabilizes long-form video. Innovation compounds because the system is compositional.
At the same time, these architectures expose difficult societal questions. Identity replication now requires remarkably little source material. A few photographs and short audio samples may be sufficient to synthesize persuasive impersonations. The challenge is not merely technical but infrastructural. Trust systems built around visual evidence become weaker when generation costs approach zero.
Historically, media manipulation required significant expertise and labor. Modern diffusion pipelines increasingly automate the entire production workflow. What was once a specialized visual effects process now resembles cloud inference infrastructure.
Yet beneath the public fascination with deepfakes and AI avatars lies a more important engineering story. These systems demonstrate how modern AI increasingly operates not as isolated monolithic models but as coordinated networks of specialized components. The future of generative systems may depend less on building larger singular models and more on designing better interfaces between heterogeneous ones.
In that sense, AI-generated humans are not simply a triumph of visual synthesis. They are an example of systems architecture becoming probabilistic, multimodal, and temporally aware all at once.
— — — — — — -— — — — — -—(Thanks for reading!) — — — — — — -— — — — — —
I’m currently working on a deep dive into Supply Chain + AI as part of my Job, I’ll publish an article soon on that as well.
If there’s a topic you’d like to see explored in a future article, I’d love to hear your suggestions.
How AI Learns to Pretend to Be Human (DeepFake Videos) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.