
RNNs Explained: How Neural Networks First Tried to Carry Meaning Forward
There is a quiet difference between seeing a sentence and moving through it.
A fixed-window neural language model still sees language a little like a camera sees a street. At each step, it captures a local view. It can be a very intelligent camera. It can learn rich internal transformations. It can make far better guesses than count-based models ever could. But it still works by repeatedly taking a bounded snapshot.
Language is not really a snapshot. It is closer to a walk.
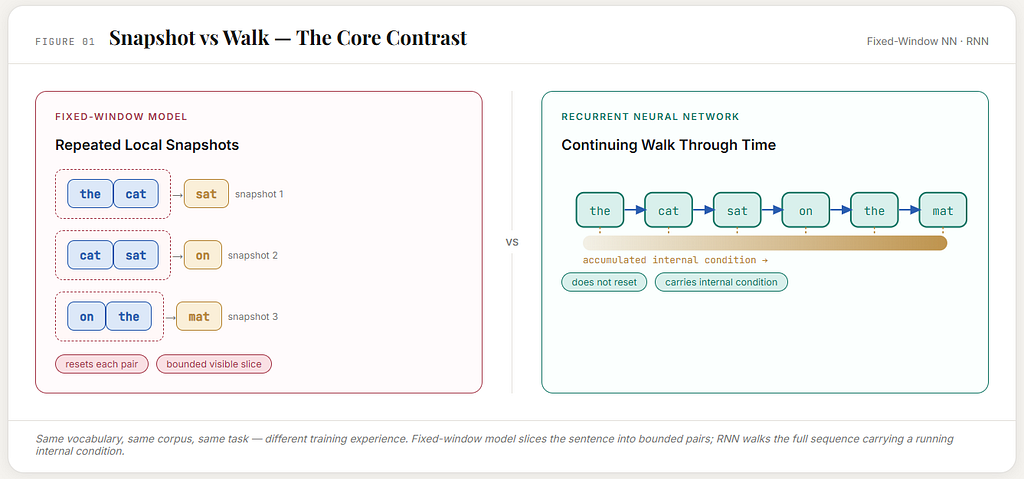
A sentence does not arrive all at once. It reveals itself in time. Each new word does not simply sit beside the previous ones; it changes the state of understanding. By the time you reach the end of a sentence, you are not the same reader you were at the beginning. Something has been carried. Something has accumulated. Something has survived.
That is the intuition from which RNNs were born.
Once early neural language models had learned how to transform a short visible context into a prediction, the next question became unavoidable:
What if the model did not have to keep rebuilding meaning from a fresh local window?
What if it could keep going in a changed condition?
That is what the Recurrent Neural Network tried to do.
Not merely look back.
Not merely widen the frame.
But carry forward an evolving internal state.
That was the breakthrough.
Not a better snapshot.
A first neural attempt at continuity.
Why this article must begin by rebuilding the earlier model
To understand what an RNN changes, we must first make completely clear what came just before it.
An early neural language model already did something remarkable. It no longer relied only on raw counts of exact phrases. It learned word embeddings, internal weights, and a hidden layer. It took a short visible context and turned that context into a next-word prediction.
That was already a major leap beyond n-grams.
But it still had one deep structural limit:
it only saw a fixed visible block.
So before we talk about recurrence, let us rebuild that older model carefully in a tiny world that we can hold in our minds.
The tiny world we will use throughout
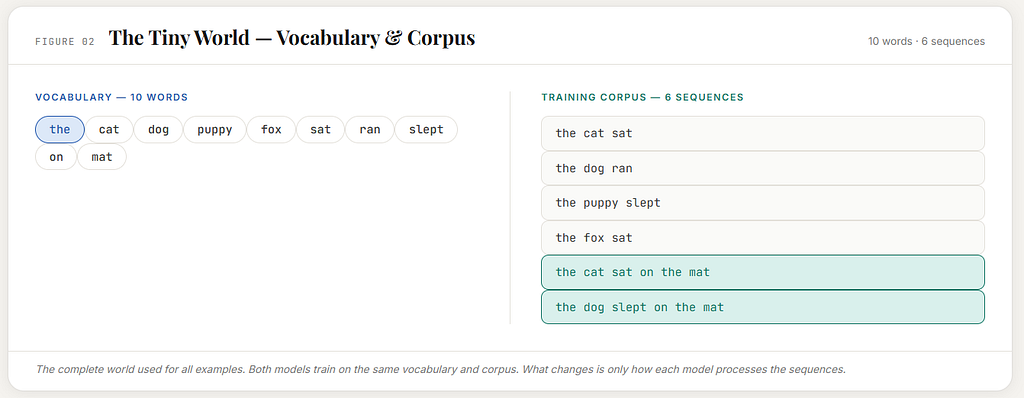
Let us imagine a vocabulary of just ten words:
the, cat, dog, puppy, fox, sat, ran, slept, on, mat
This is not real language in all its scale. It is a toy world. But it is large enough to show the core idea.
Now let us imagine a small toy corpus built from that world:
the cat sat
the dog ran
the puppy slept
the fox sat
the cat sat on the mat
the dog slept on the mat
These sentences are our training world.
That means:
- the vocabulary tells us what words exist in the model’s world
- the corpus tells us what sequences exist in that world
That distinction matters.
The vocabulary is the list of possible words.
The corpus is the collection of actual sequences the model gets to learn from.
How the fixed-window neural language model is trained
Suppose the model is allowed to see only a visible context window of two words.
Then each sentence in the corpus is cut into little local prediction tasks.
From:
the cat sat
we get:
the cat → sat
From:
the cat sat on the mat
we get:
the cat → sat
cat sat → on
sat on → the
on the → mat

From:
the dog slept on the mat
we get:
the dog → slept
dog slept → on
slept on → the
on the → mat
This is the core training format.
The model is repeatedly shown a short visible slice, and for that slice it is told what the next word should be.
So training does not happen on a whole sentence in one gulp.
It happens on many small supervised examples extracted from sentences.
That is how the fixed-window model experiences language:
as a large collection of bounded snapshots.
What the fixed-window model actually does with those examples
Take the training example:
the cat → sat
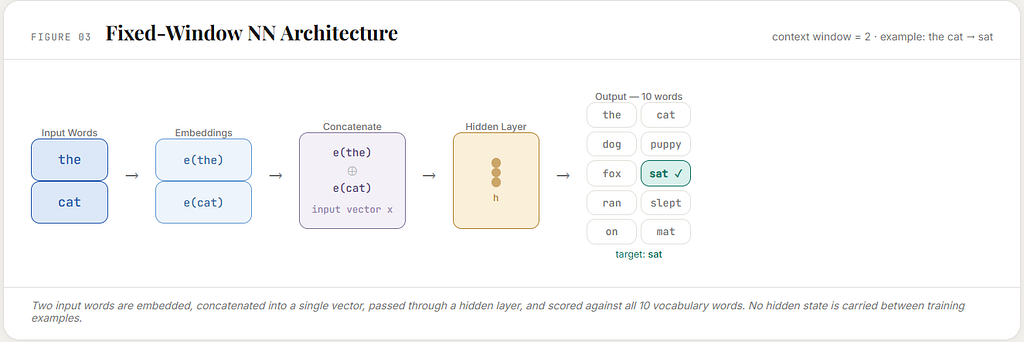
The words the and cat are first represented inside the model. In an early neural language model, they are turned into embeddings: dense learned vectors that stand in for those words.
Those embeddings are then combined into one input vector.
That input vector is passed through the neural network.
The network produces one score for each possible next word in the vocabulary:
the, cat, dog, puppy, fox, sat, ran, slept, on, mat
Then those scores are turned into probabilities.
If the model gives too little probability to sat, its internal weights are adjusted so that next time, in a similar situation, sat becomes more likely.
That is what learning means here.
The same thing happens again and again for many little examples:
the dog → ran
the puppy → slept
fox sat → ? if such a pair exists in the extracted data
on the → mat
So the model gradually becomes better at turning a short visible slice into a next-word prediction.
That was already powerful.
But the structural limit is still there.
Each prediction is rebuilt from a fresh visible block.
The limitation becomes clear in the same tiny world
Let us stay with the sentence:
the cat sat on the mat
The fixed-window model sees this as:
the cat → sat
cat sat → on
sat on → the
on the → mat
At the final step, when it predicts mat, what does it see?
Only:
on the

That may be enough in this tiny toy world. But architecturally, the limitation is visible.
The model does not have the whole sentence alive inside it.
It does not continue through the sentence in a changed condition.
It simply sees the current local window.
So if something important happened earlier and slipped outside the window, the model had no real place to keep it.
That is the problem recurrence tries to solve.
The shift from visible window to continuing condition
An RNN keeps the same basic task:
given what has come so far, predict what should come next.
It can keep the same vocabulary.
It can keep the same corpus.
It can even keep the same overall goal of next-word prediction.
What it changes is the architecture’s relation to the sequence.
Instead of saying:
show me a fresh visible block, and I will predict from that
the RNN says:
let me keep going through the sequence, and let each new word update an internal condition that I carry forward
This is the essential idea.
The model does not reset at every word.
It continues.
What “hidden state” means, without drama

The phrase hidden state can sound more complicated than it needs to.
In this article, we can understand it simply as:
the model’s current internal condition after reading what it has read so far
That is all.
It is not a sentence stored in plain language.
It is not a little human thought inside the machine.
It is not consciousness.
It is the model’s running inner condition.
Each word leaves some trace in that condition.
Then the next word arrives into that already-shaped condition.
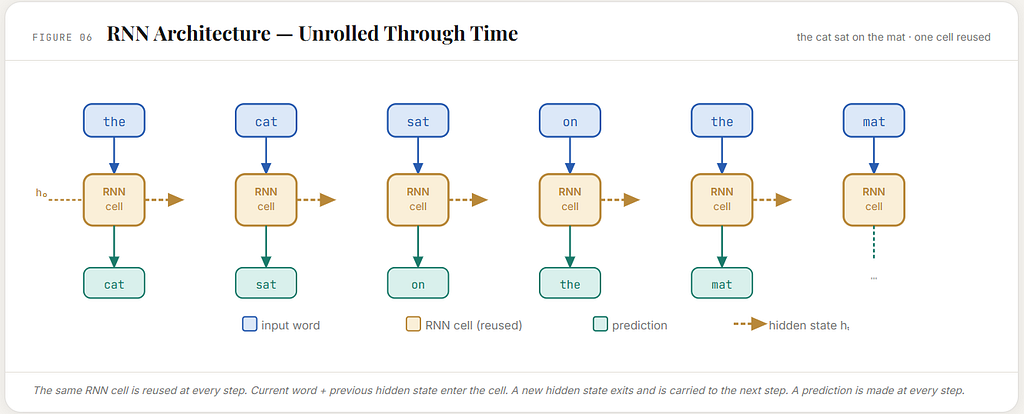
So when the RNN reads a sentence, it is not repeatedly starting from a blank point. It is moving through the sentence with something carried forward.
That is why recurrence matters.
The same tiny world, but now seen as a path
Let us use the same sentence:
the cat sat on the mat
The fixed-window model turned this into separate little tasks.
The RNN experiences it more like this:
read the
leave the model in one condition
read cat
update that condition
read sat
update it again
read on
update it again
read the
update it again
then predict what should come next
What matters is not just the current visible word.
What matters is the current word arriving into a carried condition.
That is the deepest change.
Language is no longer treated mainly as a sequence of separate snapshots.
It is treated as an unfolding path that continuously changes the model.
How the RNN is trained using the same vocabulary and the same corpus
This is the part that often gets skipped too quickly, but it is the heart of the matter.
The vocabulary is still:
the, cat, dog, puppy, fox, sat, ran, slept, on, mat
The training corpus is still:
the cat sat
the dog ran
the puppy slept
the fox sat
the cat sat on the mat
the dog slept on the mat
So the world has not changed.
What changes is how the model is trained on that world.
Fixed-window training
In the earlier model, training looked like this:
the cat → sat
cat sat → on
sat on → the
on the → mat
Each training pair is treated as its own small supervised example.
RNN training
In the RNN, training is more continuous.
Take the sentence:
the cat sat on the mat
Now training unfolds step by step through the sequence:
read the predict cat
read cat predict sat
read sat predict on
read on predict the
read the predict mat
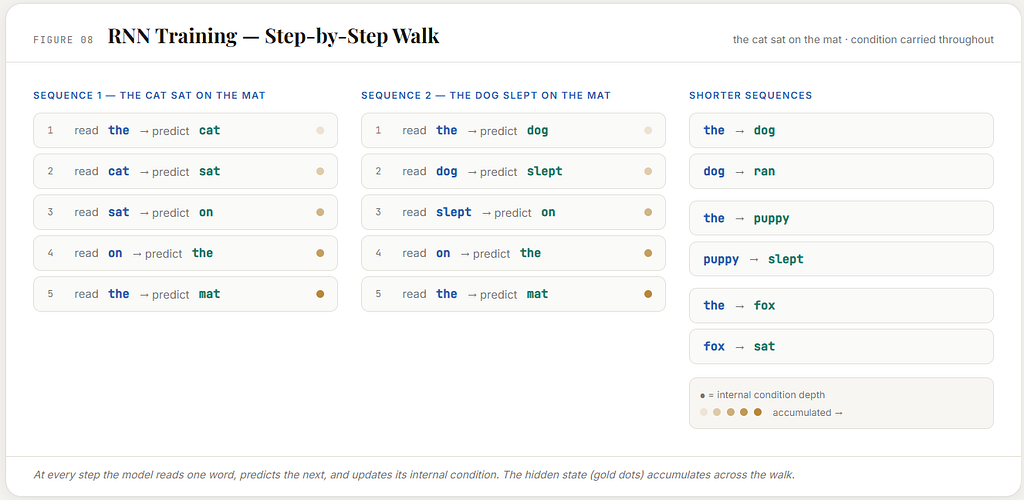
The next word is still the supervision signal.
The vocabulary of possible predictions is still the same ten words.
The corpus is still the same source of truth.
But the model is no longer trained on isolated visible slices alone.
It is trained as a continuing process moving through the sentence.
That is the crucial difference.
Why this is not just a small variation
At first glance, someone might say:
Is this really so different?
In both cases, the model is still predicting the next word.
Yes, it is different.
Because in the fixed-window model, when the model predicts sat, it does so from the visible input the cat presented fresh as a block.
In the RNN, when the model predicts sat, it does so after having read the, carried forward a changed condition, then read cat inside that changed condition.
So the prediction no longer comes only from a visible block.
It comes from:
the current word
plus the running condition created by earlier words
That is a different training experience.
The model is not only being taught what next word is correct.
It is also being taught how to leave itself in a better condition for the next step.
A short example with the same corpus
Take:
the dog ran
RNN training moves like this:
read the
predict dog
read dog
predict ran
Now take:
the puppy slept
read the
predict puppy
read puppy
predict slept
Now take:
the fox sat
read the
predict fox
read fox
predict sat
Across these examples, the model begins to notice something.
After the, noun-like animal words often follow:
cat, dog, puppy, fox
After those words, action-like words often follow:
sat, ran, slept
This is not because the model is given a hand-written grammar.
It is because repeated correction gradually shapes its embeddings, recurrent weights, and output weights so that similar situations produce similar expectations.
So even in this tiny world, training begins to create generalization.
The same word can be met in different conditions
This point is subtle and very important.
In the sentence:
the cat sat on the mat
the word the appears twice.
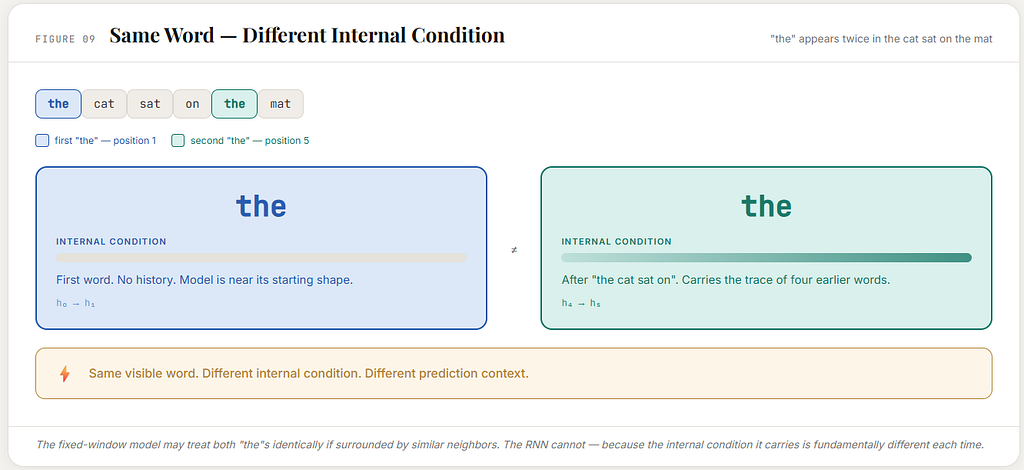
But those two appearances do not happen in the same running condition.
The first the is the opening word.
The second the comes after the cat sat on.
So even though the visible word is the same, the inner condition is not the same.
That means the RNN can, in principle, respond differently to the same current word depending on what path has led to it.
This is one of the deepest shifts introduced by recurrence.
A word is no longer just a visible item in a local slice.
It is an arrival inside a continuing condition.
How correction works in RNN training
The model still learns through error and correction.
Suppose it reads:
the
and fails to strongly predict cat in the sentence the cat sat on the mat.
Then its internal settings are nudged so that, in a similar condition, cat becomes more likely.
Next, it reads cat in the condition created by the earlier the.
If it then fails to predict sat strongly enough, its settings are adjusted again.
But now something deeper is true.
The error at the sat prediction is not only about the current word cat.
It may also reflect that the model did not carry the earlier context into the right condition.
So training in an RNN can correct not only the current reaction, but also how earlier steps shaped the running condition that was passed forward.
This is the basic idea behind backpropagation through time.

That phrase sounds technical, but the intuition is simple.
The sentence is unfolded step by step.
Predictions are made along the way.
Then the error from later steps can flow backward through the earlier steps, improving how the recurrent mechanism builds the carried condition.
In plain words:
the model is trained not only to guess well now
but also to leave itself in a better condition for what comes next
That is the real difference.
Why the same recurrent mechanism is reused
An RNN does not use a different network for each word position.
The same recurrent mechanism is reused at every step.
The same machinery that processes the at the beginning also processes cat, sat, on, and later the again.
That matters because improvements learned at one step can help at many other steps.
If the model learns something useful from:
the dog ran
that same learned way of updating its inner condition can help with:
the fox sat
or
the puppy slept
The recurrence is shared.
One mechanism.
Repeated through time.
Continuously corrected through many sequences.
That is one reason RNNs felt so powerful.
How one full pass through the toy corpus looks
Let us imagine one training pass through the whole tiny corpus.
The corpus is:
the cat sat
the dog ran
the puppy slept
the fox sat
the cat sat on the mat
the dog slept on the mat
The RNN walks through each sentence word by word.
For the cat sat, it trains on:
read the → predict cat
read cat → predict sat
For the dog ran, it trains on:
read the → predict dog
read dog → predict ran
For the puppy slept, it trains on:
read the → predict puppy
read puppy → predict slept
For the fox sat, it trains on:
read the → predict fox
read fox → predict sat
For the cat sat on the mat, it trains on:
read the → predict cat
read cat → predict sat
read sat → predict on
read on → predict the
read the → predict mat
For the dog slept on the mat, it trains on:
read the → predict dog
read dog → predict slept
read slept → predict on
read on → predict the
read the → predict mat
That is the real training experience in miniature.
Same vocabulary.
Same corpus.
Same next-word task.
Different architecture.
Different way of moving through the sequence.
How generation works after training
Once trained, the RNN can also generate text step by step.
Suppose it begins with:
the
It reads that word, enters some internal condition, and predicts what should come next.
Perhaps it predicts:
cat
Now it reads cat, updates its condition, and predicts again.
Perhaps now it predicts:
sat
Then it reads sat, updates again, and predicts:
on Then: the Then: mat. So generation becomes:
the → cat → sat → on → the → mat
This may look similar on the surface to fixed-window generation, because both models produce one word at a time.
But the internal logic is different.
The fixed-window model keeps looking at a fresh local slice.
The RNN keeps going in a changed condition.
That is the true distinction.
Why this felt closer to real reading
A sentence is not just a pile of neighboring fragments.
Something is carried.
The beginning matters to the middle.
The middle matters to the end.
The same word can matter differently depending on where it appears and what has already happened.
RNNs were the first major neural architecture to take that seriously at the architectural level.
They tried to let language change the model continuously as the sentence unfolded.
That is why they mattered so much.
They introduced a new picture of language processing:
not repeated local viewing
but continuing internal transformation

But continuity is not the same as strong memory
And yet, the story does not end here.
The RNN introduces continuity.
But continuity alone is not enough.
A natural next question appears:
What exactly survives in the hidden state?
How long does it survive?
Does the model keep earlier clues clearly enough?
Or do they become weak and blurred as more words pass through?
This is where plain RNNs begin to struggle.
In principle, they can carry information forward.
In practice, that information can fade.
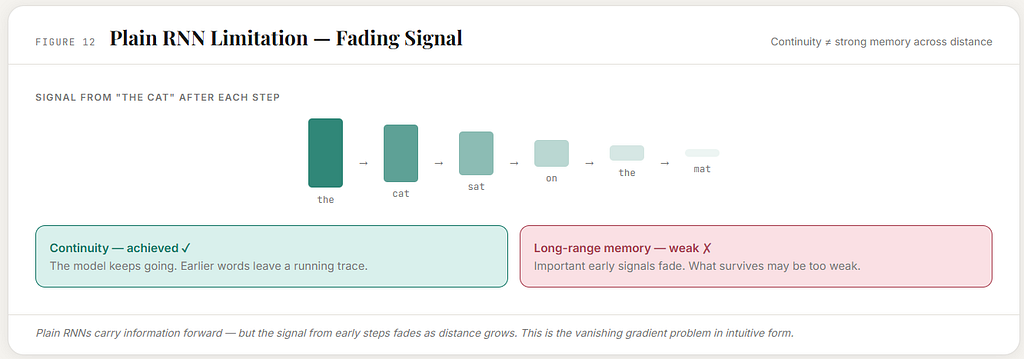
Earlier signals may become thin after many steps.
The running condition may no longer preserve what matters strongly enough.
So the RNN was a major advance, but not the final answer.
It gave the field a continuing inner condition.
It did not yet fully solve how to preserve the right things across longer stretches.
The exact conceptual shift from the earlier model
If we compare the fixed-window neural language model and the RNN very carefully, the difference can be stated cleanly.
In the fixed-window model:
- language is cut into local visible slices
- each slice becomes its own training example
- prediction is rebuilt from a fresh visible block each time
- anything outside the chosen window is gone for that step
In the RNN:
- the same language world can be used
- the same next-word task can be used
- the same corpus can be used
- but the model moves through the sentence step by step in a continuing internal condition
That is the leap.
Not a new task.
Not a new vocabulary.
A new way of staying with the sequence.
Why recurrence stopped feeling magical once the earlier model became clear
Once the fixed-window model is seen clearly from the inside, the RNN no longer feels like a mysterious invention that appeared from nowhere.
It feels like the natural next question.
If a model can learn how to transform a visible local slice into a prediction, then why should it not also try to carry some running trace of the past?
If a model already has embeddings, hidden layers, and learned weights, then why should it be forced to start from a fresh visible block at every step?
If language unfolds, why should the model not unfold with it?
That is why recurrence was not merely a random new architecture.It was the next necessary thought.
Final intuition
A fixed-window neural language model says:
Give me the recent visible slice, and I will predict from that.
An RNN says:
Let me continue through the sequence, and let each word leave me in a changed condition.
That was the breakthrough. Not a better snapshot. A first neural attempt at continuity. Not a wider local view. A first attempt to carry something forward. And that is why RNNs matter in the history of language models. They were the first serious neural move from local context processing toward ongoing sequence experience.

One-line memory hook
RNNs kept the same next-word task, the same vocabulary, and the same training data, but changed training from separate local snapshots into a continuing process that carries an internal condition forward.
RNNs Explained: How Neural Networks First Tried to Carry Meaning Forward was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.