
When Anomaly Detection Flags Your Best Affiliates: The Baseline Problem in ML Fraud Detection

Last month I watched a legit affiliate go from “normal” to “under review” in a single afternoon — because a post went viral and the audience happened to be geographically tight.
No bots. No incentivized junk. Just a distribution shift.
My thesis: a lot of ML-based affiliate fraud detection is doing exactly what it was designed to do — flag low-density behavior relative to a baseline. The failure mode is that “low-density” often includes the best legitimate partners, because high performance in affiliate is structurally outlier-shaped.
And yes, I’m seeing this now.

The typical hybrid stack: rules catch the obvious stuff; anomaly scoring catches the “weird” stuff — sometimes including your best partners.
1) How affiliate fraud detection systems actually work (rules + anomaly scoring + the baseline problem)
A colleague recently threw this problem my way, and it got me thinking. The affiliate team had a partner flagged for “abnormal velocity” and “geo anomaly” within the same 6-hour window. The partner’s explanation was boring: a creator mentioned their page; most of the creator’s audience lived in one country.
From the model’s perspective, though, that’s not “boring.” It’s a multi-signal tail event.
Most modern affiliate fraud detection pipelines look like this:
- Ingest events (clicks, conversions, sometimes impressions) from tracking links / postbacks.
- Enrich with identity-ish signals (IP reputation, ASN, device fingerprint probabilities, geo, UA).
- Apply deterministic rules to block or hold obvious invalid traffic.
- Compute an anomaly score over rolling windows (per SubID, per affiliate, per offer, per geo).
- Route to actions: auto-block, commission hold, manual review queue, or “monitor.”
TrafficGuard describes the industry arc pretty plainly: rules define invalid criteria and establish baselines; ML then hunts for patterns like unnatural click velocity or improbable funnels that static rules won’t capture (TrafficGuard).
Signal architecture: what gets logged and featurized in affiliate pipelines
Affiliate tracking systems are basically event pipelines with attribution semantics bolted on. The raw schema is usually simple:
- Click event: timestamp, affiliate ID, offer ID, tracking params (SubIDs), referrer/landing, IP, UA, maybe device hints.
- Conversion event: timestamp, order/lead ID, amount, status, sometimes hashed identifiers, and the click ID it attributes to.
Everything interesting happens in derived features. The common ones show up repeatedly in vendor and practitioner writeups:
- Click velocity / burstiness: clicks per minute, derivative of click rate, change-point-like behavior (TrafficGuard; Zigpoll).
- IP reputation + ASN / datacenter heuristics: cloud ASNs, proxy/VPN suspicion, repeat IP density.
- Device fingerprint consistency: “same device” patterns, UA diversity, entropy of device-like identifiers (often probabilistic because privacy constraints reduce stable IDs) (Zigpoll).
- Geo clustering: concentration by country/region/city; mismatch between click geo and conversion geo.
- CVR deviation: conversion rate relative to program or cohort baseline.
- Time-to-conversion distribution: click→conversion lag histograms; mass near-zero lags.
- SubID pattern features: entropy, template detection, top-k concentration, n-gram repetition.
- Cross-channel proximity: “paid click then affiliate click right before conversion” patterns (poaching / last-second hijack) (TrafficGuard).
Oddly enough, a lot of this is just standard entity monitoring. Anodot makes the point in a different domain: business metrics are volatile and context-dependent; you can’t evaluate them in absolute terms, so you end up learning patterns per metric/entity (Anodot).
Affiliate fraud detection is that — plus adversaries.
Deterministic rules: the stuff that still catches obvious fraud
Rules aren’t glamorous, but they’re cheap and interpretable. And they’re still doing a lot of work.
Common rule families:
- Datacenter / proxy / VPN heuristics (often via ASN and IP reputation).
- Click flooding thresholds: “N clicks from same IP/device in T seconds.”
- Impossible geo / mismatch checks: clicks from banned geos; click geo inconsistent with billing/shipping patterns.
- Repeated IP/device patterns beyond expected household/campus norms.
- Cookie stuffing / injection signatures: conversions with affiliate click extremely close to conversion, especially if repeated and inconsistent with normal funnel timing (TrafficGuard).
- Poaching patterns: affiliate interactions clustering unnaturally close to paid channel interactions (TrafficGuard).
Rules are brittle, sure. Fraudsters route around them. But rules also define what the system considers “invalid,” which quietly shapes the training data for ML stages downstream.
Before moving on, it’s worth highlighting a subtle nuance here: rules don’t just block traffic — they curate the baseline by removing (some) known-bad patterns from the “mostly legit” pool.
ML anomaly scoring: isolation forests, autoencoders, z-scores — and why “normal” drifts toward the mediocre middle
Most affiliate fraud ML I’ve seen described publicly is unsupervised or semi-supervised anomaly detection. Zigpoll’s overview is representative: collect historical clicks/conversions, engineer features like click velocity and geo dispersion, train models like Isolation Forest or autoencoders, then score incoming traffic and flag anomalies for review (Zigpoll).
Mechanically:
- Isolation Forest isolates points in sparse regions quickly; fewer splits → more anomalous.
- Autoencoders learn a reconstruction manifold; high reconstruction error → out-of-manifold.
- Z-score / robust z-score flags deviations in rate metrics (clicks/min, CVR, lag percentiles).
Now for the part that keeps biting teams in production: the false positives aren’t random. They’re a predictable outcome of three properties of affiliate traffic:
- Heterogeneous legitimate populations (mixture distributions).
- Heavy-tailed dynamics (power-law-ish referral spikes).
- Non-stationarity (content cycles, creator posts, seasonality).
Anodot’s partner monitoring post basically screams this in a different context: business KPIs fluctuate with changing conditions and human behavior; topology is unknown; sampling is irregular; absolute thresholds don’t work (Anodot).
So what happens to common anomaly detectors?
- Isolation Forest: rare-but-legit modes get isolated quickly because they occupy sparse regions. If “viral spike + tight geo” is rare in training, it’s anomalous by construction.
- Autoencoders: the manifold is dominated by the most frequent behaviors. A high-intent bottom-funnel page can be “off-manifold” even if it’s perfectly legitimate.
- Z-score deviation: assumes something like stable variance and roughly well-behaved distributions. Click velocity and CVR often aren’t. They’re skewed, heavy-tailed, and regime-switching.
And then there’s Simpson’s-paradox-style aggregation pain: program-wide averages can move opposite to subgroup trends, so “baseline vs partner” comparisons can be misleading even before you get to ML.
One sentence summary: if “normal” is a mixture, then “outlier” is often just “a minority mode.”
Once you see how the baseline is learned, the false-positive pattern becomes predictable: the best legitimate partners often share the same statistical shape as fraud — bursty, concentrated, and sharply bottom-funnel — so Section 2 is really about separability, not morality.
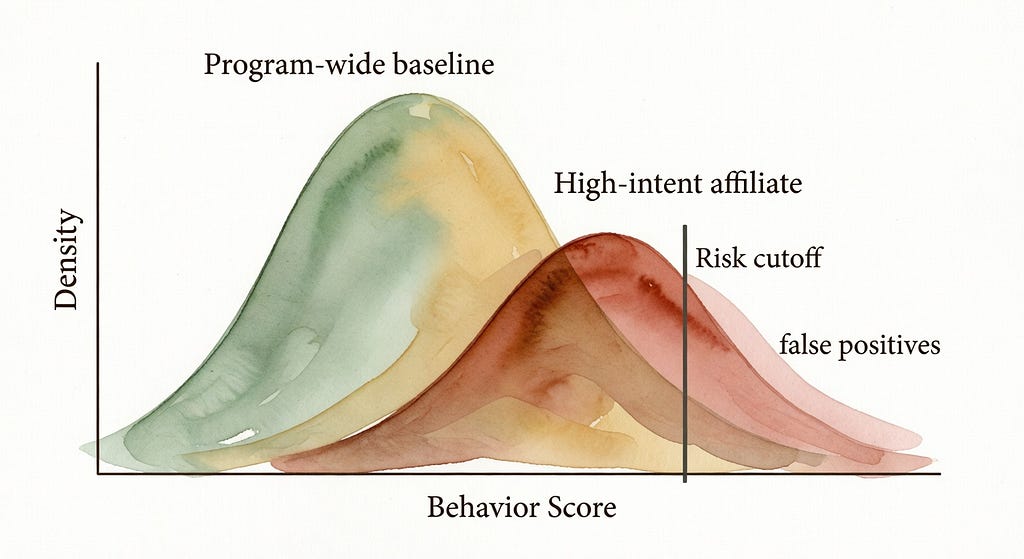
If the cutoff is learned from the mediocre middle, targeted performance lives in the danger zone.
2) Why legitimate high-performing affiliate traffic is structurally indistinguishable from fraud signals (a precision problem)
What complicates matters further is the underlying assumption that “unusual” is a good proxy for “malicious.” In affiliate, “unusual” is also a proxy for “excellent.”
There are plenty of field writeups on this, but one of the clearest “warts and all” descriptions I’ve seen is a practitioner post that documents legitimate traffic getting flagged because it matches the shape of fraud signals — viral spikes, tight geo clusters, high CVR bottom-funnel pages, and even “too clean” SubID structures (LinksTest).
I’m going to reframe that from the model’s perspective: the system isn’t “accusing” anyone. It’s computing likelihood under a baseline, then thresholding.
And the thresholding is where precision dies.
Here’s a concrete (hypothetical, but close to what I’ve seen) scenario:
- Normal: 1,500 clicks/day, 3.2% CVR on a niche SaaS comparison page.
- Event: newsletter mention + short-form clip hits.
- Spike: 18,000 clicks in 24h, CVR drops to 1.1%, and 80% of clicks land in a 3-hour window.
In one day, you’ve triggered:
- velocity anomaly (rate derivative),
- time-of-day clustering,
- engagement dilution (more top-funnel curiosity),
- CVR deviation (relative to your own history and program baseline),
- time-to-conversion distribution shift (more “fast” and more “never”).
A fraud stack that fuses scores will see a multi-signal event and crank the risk.
But here’s where things get interesting: fraud and virality are both bursty processes. The model doesn’t get to observe intent.
Viral spike → click velocity anomaly (and time-of-day clustering)
Fraud patterns like click farms and bots often show up as sharp step changes in click rate. So do viral posts.
From an anomaly model’s perspective, this is textbook contextual anomaly: the point isn’t extreme in absolute terms; it’s extreme given the recent window. That’s exactly what rolling-window z-scores and isolation-style methods are good at flagging.
The catch, however, is that virality is a real distribution shift. If your training data under-represents “legit viral,” the model has no stable concept for it.
Geo-concentrated audiences → geo clustering flags (even when it’s just good targeting)
Geo clustering is a common fraud analytic technique. Databricks’ geospatial clustering writeup (in financial fraud) describes DBSCAN-style density clustering as a way to find dense regions and outliers, and it explicitly frames the goal as “personalized AI” — you need to know what’s normal per entity to call something abnormal (Databricks).
Affiliate systems often do the opposite: they treat dense geo as suspicious globally.
Meanwhile, click fraud operators also exploit geo-targeting. ClickGUARD lists the usual tricks: VPN/proxy masking, fake IPs, and click farms physically located in targeted regions — meaning “tight geo” can be either a great audience or a fraud ring (ClickGUARD).
Density ≠ fraud. It’s just density.
So if your model uses geo concentration as a strong feature without per-affiliate context, you’re going to torch precision on legitimate niche publishers.
Bottom-funnel high CVR + short time-to-conversion → “improbable funnel” / cookie stuffing lookalikes
This one always trips people up because it feels like a compliment: “your CVR is too high.”
TrafficGuard explicitly calls out “improbable funnels” and “repetitive last-second conversions” as the kind of patterns ML anomaly detection will hunt for (TrafficGuard).
But bottom-funnel affiliate pages are supposed to compress time-to-conversion. If someone searches “Brand X alternative,” hits a comparison table, and buys in 4 minutes, the lag distribution is going to be tight. That’s not cookie stuffing; that’s intent.
The statistical problem is the comparator. Program averages are a terrible baseline for niche intent pages. Even broad web benchmarks vary a lot: Spider AF cites “Average CVR: B2B sites = 10%, B2C sites = 3%” (Spider AF). Within an affiliate program, the spread is usually wider because partner types differ wildly (coupon, loyalty, content, influencers, etc.).
So a model that says “CVR > μ_program + kσ_program is suspicious” is basically hard-coding “outlier = bad.”
Disciplined SubID structure → “synthetic templating” features
This is the funniest and saddest one.
Advanced affiliates often pass structured SubIDs because they want an audit trail, but structured SubIDs can look “template-like” to systems expecting messy metadata — especially if top-k SubIDs account for a large share of conversions (practitioner reports describe this pattern a lot).
If you engineer features like:
- SubID entropy,
- repetition rates,
- template detection,
- concentration metrics,
…then disciplined tracking can look machine-generated.
To be clear, those features aren’t wrong. Fraudsters also use templated patterns. The issue is separability: “clean” is not a class label.
If “unusual” is overloaded as “malicious,” the only durable fix is to change how baselines, thresholds, and review costs are designed — because you can’t feature-engineer your way out of a definition problem.

The awkward truth: a lot of “great traffic” is visually indistinguishable from classic fraud signals — until you add context.
3) How to reduce false positives without letting fraud through (design changes + ops incentives)
This is the part that matters.
You can’t fix this by telling affiliates to “be less spiky” or “lower your CVR.” That’s like telling your best model to add noise so it looks average.
To reduce false positives without letting fraud through, you need to change what “normal” means and what context the model can see — then back that up with ops policies that don’t quietly reward “more alerts” over “better alerts.”
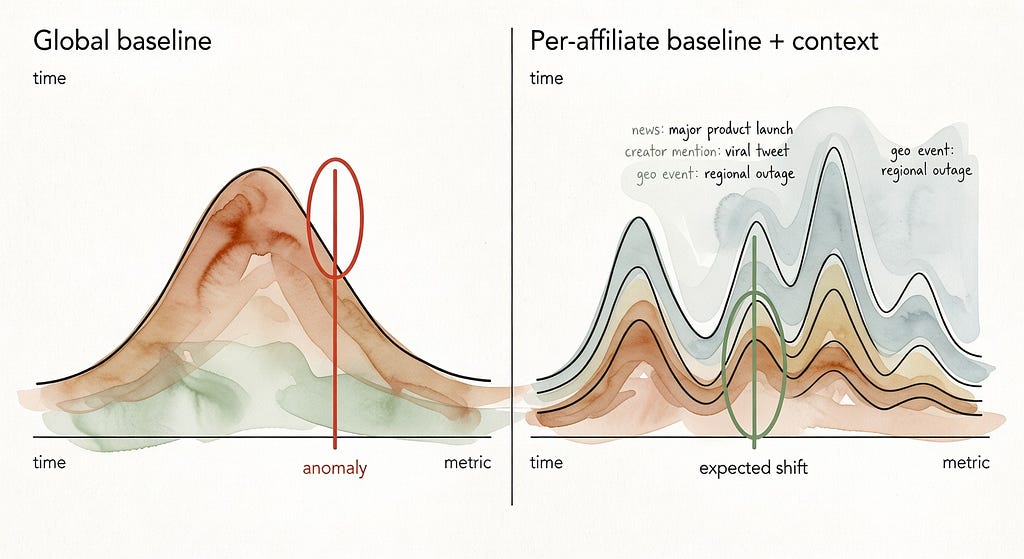
Same data, different frame: per-affiliate baselines (and a bit of real-world context) can turn “suspicious” back into “plausible.”
Per-affiliate baselines: personalized anomaly detection instead of program-wide averages
The most direct fix is personalized baselines.
Databricks frames geospatial fraud detection as “personalized AI”: you can’t identify abnormal patterns without understanding what normal behavior is for that entity (Databricks). Anodot similarly argues each partner’s patterns are unique and must be learned individually (Anodot).
Translated to affiliate fraud:
- Model each affiliate’s click velocity, geo mix, CVR, and lag distribution as its own time-varying baseline.
- Use hierarchical priors / partial pooling so you can share strength across similar affiliates without collapsing everyone into one mean.
- Handle cold start with cohort priors (partner type, vertical, traffic source class), then adapt quickly.
This doesn’t eliminate fraud detection. It changes the question from “are you weird vs the program?” to “are you weird vs yourself, given your known modes?”
It’s also expensive: you’re now maintaining many baselines, dealing with sparse partners, and building infra for entity-level drift.
Context injection: treat spikes as explainable events, not just distribution shift
Models are blind to “why.” They see velocity and timing clusters; they don’t see “newsletter issue #142.”
So give the system context:
- Email platform send logs (timestamp, segment size).
- Scheduled creator posts (timestamp, platform).
- Content publish/update events (CMS logs).
- Known promo windows (merchant calendar).
Zigpoll’s implementation-style guidance already pushes toward richer feature sets and continuous retraining (Zigpoll). Context injection is the next step: treat these as exogenous variables so the model can learn “spike with newsletter flag” is less suspicious than “spike with no plausible driver.”
This is basically causal hygiene. Not full causality, but at least “don’t punish known events.”
Asymmetric costs and tenure-aware thresholds: stop treating every affiliate like a fresh burner account
Last month I noticed something that felt backwards: long-tenured partners with clean histories were getting the same automated holds as brand-new accounts with no track record.
That’s a policy choice masquerading as ML.
TrafficGuard talks about combining deterministic rules with ML and partner classification by type (TrafficGuard). Extend that idea into decisioning:
- Tenure-aware thresholds: higher tolerance for outlier behavior from partners with long histories of clean traffic.
- Cost-sensitive scoring: weight false positives more heavily for high-value, high-trust partners (because the business cost of freezing them is real).
- Expected-loss calibration: threshold based on expected fraud loss vs expected partner harm, not a single global “risk score > t.”
Operators tune toward recall because false positives are “cheap” in their accounting. Make them expensive — explicitly — and the tuning changes.
Be honest, though: fraudsters will adapt. If tenure reduces scrutiny, they’ll try to age accounts or buy aged accounts. You’ll need guardrails (for example: separate “trust” from “exemption,” and keep high-sensitivity checks on identity signals even for trusted partners).
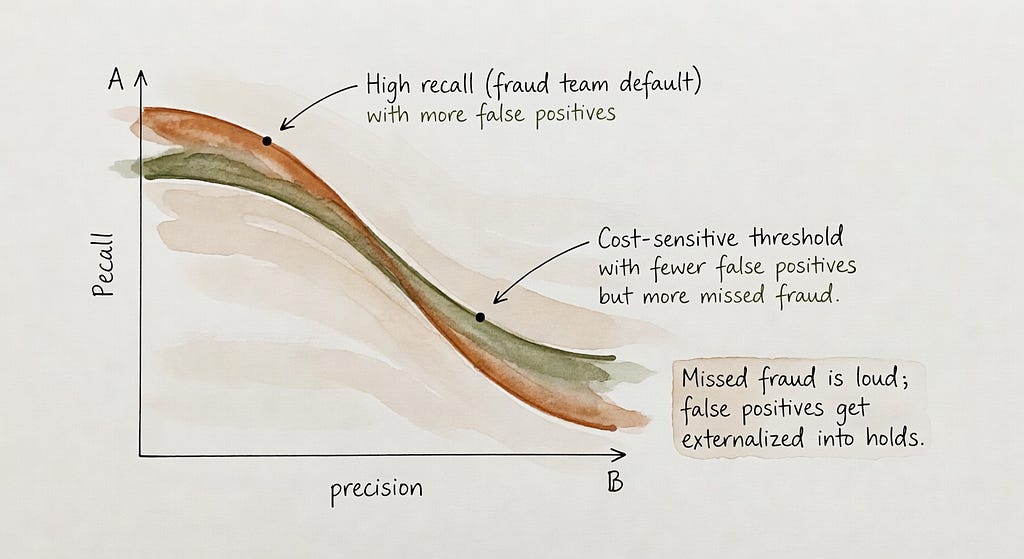
Tuning is politics as much as math: missed fraud is expensive and obvious; false positives are someone else’s problem.
Ops reality: why teams tune for recall (and how to counterbalance it)
The catch, however, is that tuning is not purely technical. It’s economic.
Fraud teams live with asymmetric incentives:
- False negatives (missed fraud) show up as direct spend leakage, angry finance emails, and sometimes public postmortems.
- False positives get “handled” via holds, reviews, and partner support tickets — costly, but often externalized onto affiliates via delayed payouts and churn.
Databricks makes a similar point about fraud stacks in finance: they’re patchworks of rules + AI under governance and SLA constraints, and they’re expensive and hard to adapt (Databricks). Affiliate stacks have fewer regulatory constraints, but the “patchwork + queue” dynamic is familiar.
If you have a finite review queue, you set thresholds to fill it with “highest risk.” If your risk score is basically “distance from baseline,” you will fill it with high-performing outliers. The operational fix is to stop treating the review queue as the only safety valve.
Concretely, teams that want fewer false positives usually need a tiered decision policy — something like:
- Tier 0 (allow): low risk; no friction.
- Tier 1 (monitor): log extra evidence; tighten sampling; no payout hold.
- Tier 2 (soft hold): partial hold or delayed payout only on the incremental spike window; require lightweight partner attestation (e.g., “this was a scheduled send”).
- Tier 3 (hard hold / manual review): reserve for multi-signal anomalies that persist and lack plausible context, or for identity-risk signals (proxy farms, repeated device/IP clusters) that don’t look like mere virality.
That policy layer is where you operationalize “precision matters,” even if the underlying anomaly score is imperfect.
Limitations and open problems (cold start, privacy, adversaries, and measurement)
Full disclosure: I’m not an expert in every affiliate network’s internal stack, and public documentation is thin. Even in the sources above, we get architecture hints and signal lists, not full evaluation reports.
A few hard problems remain:
- Ground truth is messy: “held” isn’t the same as “fraud,” and review outcomes are biased by policy.
- Feedback loops: affiliates change behavior to avoid flags; fraudsters do the same, faster.
- Privacy constraints reduce stable identifiers, making device fingerprinting probabilistic and weakening linkage across events (Zigpoll).
- Cold start: per-affiliate baselines are weakest exactly when risk is highest (new partners).
- Measuring false positive rates in affiliate fraud detection is hard without shared datasets; I don’t see strong published FPR numbers in the sources available here, so I’m not going to fake precision.
My best working model is simple: if you define “fraud” as “distance from a global baseline,” you’ll keep punishing legitimate partners who are exceptional by design. The path out is also simple to say and annoying to build — personalize baselines, inject context, and make ops policies pay attention to partner harm as a first-class cost.
Key takeaways (recap)
- Affiliate fraud stacks are usually hybrid: deterministic rules catch obvious invalid traffic, then anomaly scoring catches “weird stuff” rules miss (TrafficGuard).
- The core technical failure mode is the baseline: program-wide “normal” is dominated by the mediocre middle, so high-performing partners land in low-density regions and get scored as risky.
- Legit patterns map cleanly onto classic fraud signals: viral spikes resemble click flooding; geo concentration resembles farms; bottom-funnel fast conversions resemble stuffing; clean SubIDs resemble templating.
- Unsupervised anomaly detectors (Isolation Forest, autoencoders, rolling z-scores) will reliably flag minority modes when “normal” is a mixture distribution (Zigpoll).
- Reducing false positives without opening the door to fraud typically means per-affiliate baselines, context injection, and cost-sensitive thresholds — plus an ops policy that doesn’t treat “manual review” as the only control surface (Anodot; Databricks).
Sources
- LinksTest — Affiliate Fraud Detection False Positives: Legit Traffic That Gets You Flagged
- TrafficGuard — Affiliate Fraud Detection: From Rule-Based Checks to Machine Learning
- Zigpoll — Strategies to build AI models for anomalous affiliate traffic (Isolation Forest, autoencoders, signals, privacy)
- Anodot — Using Machine Learning to Scale Partner & Affiliate Tracking (business metrics volatility)
- Databricks — Identifying Financial Fraud With Geospatial Clustering (personalized baselines, DBSCAN/GEOSCAN)
- ClickGUARD — Geo-targeting click fraud techniques (VPN/proxy, click farms)
- Spider AF — Understanding CVR (benchmark ranges)
When Anomaly Detection Flags Your Best Affiliates: The Baseline Problem in ML Fraud Detection was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.