
Your AI Isn’t the Risk. Your Logs Are.

PII masking in AI agent systems: the problem, the playbook, and why it’s about to get harder
You call your bank’s AI assistant to update your address. You share your name, account number, and social security number for verification. The bot does its job — account updated, conversation over.
But every word you typed just got written into a conversation log. That log now sits in a database, gets piped to an observability platform, flows through an analytics warehouse, and lands in a QA environment where a developer is debugging a failed intent. Your name, your government ID, your email — all in plaintext, in systems that were built for monitoring, not for protecting personal data.
Your data didn’t leak out. It leaked into five systems that never needed it.
This is the PII problem in enterprise AI.
Why Encryption Alone Doesn’t Fix This
The most common pushback is: “We encrypt our logs.”
Encryption protects data at rest and in transit if someone intercepts the file, they can’t read it. But it doesn’t help when a developer with legitimate access decrypts the log to debug an issue, or when a pipeline decrypts data for indexing and it’s now searchable in plaintext.
Encryption locks the box. PII masking ensures there’s nothing sensitive in the box to begin with. You need both — but masking is the layer most teams skip.
How PII Masking Actually Works
PII masking intercepts sensitive data and replaces it with a sanitised version before it reaches storage. The AI agent uses the real data to process the request — the log only stores what’s necessary for observability.
A raw log entry:
input.raw_text: "My name is Sarah Chen, SSN is 421-55-0198,
email sarah.chen@gmail.com"
After masking:
input.raw_text: "My name is ***, SSN is ***, email ***"
input.entities: ["PERSON_NAME", "SSN", "EMAIL"]
pii.redaction: enabled
Intent captured. PII gone. But the how matters enormously, and there are multiple approaches with real trade-offs.
The Techniques: A Practical Breakdown
1. Pattern-Based Redaction (Regex)
The simplest approach. You write regex patterns to detect known PII formats — 10-digit phone numbers, email patterns, SSN’s 3–2–4 digit format, credit card number structures.
Where it works: Structured, predictable identifiers like phone numbers, credit card numbers, postal codes.
Where it breaks: It can’t catch “my son goes to Lincoln Elementary” as family information, or “I was diagnosed last March” as health data. It also generates false positives — a 10-digit order number gets flagged as a phone number.
Best used as a fast first layer, not the whole solution.
2. NER-Based Detection (Named Entity Recognition)
NLP models trained to identify entities like person names, locations, organisations, and dates in unstructured text. Models like spaCy’s NER, Google’s DLP API, or Azure AI Language can identify PII in context rather than just by format.
Where it works: Catching names (which have no fixed pattern), contextual references, and entities in free-form conversation.
Where it breaks: Multilingual conversations, code-switched text (users mixing two languages in one sentence, common in global customer support), and domain-specific jargon that confuses the model.
The best implementations combine regex for structured patterns with NER for unstructured ones — a layered approach.
3. Tokenisation (Reversible Masking)
Instead of permanently destroying the PII, tokenisation replaces it with a random token and stores the mapping in a separate, heavily secured vault. The log shows TOKEN_8f3a2b instead of the real name, and only authorised processes (like a fraud investigation team) can reverse the mapping.
Why it matters: Some use cases legitimately need the ability to recover the original data — fraud detection, legal holds, regulatory audits. Irreversible redaction doesn’t work here. Tokenisation gives you masking for 99% of use cases and a controlled, auditable path for the 1% that need the real data.
4. Differential Privacy & k-Anonymity (For Analytics)
When the goal isn’t individual log masking but aggregate analytics on conversation data — like “what percentage of users asked about loans in Q1” — statistical techniques like differential privacy (adding calibrated noise) or k-anonymity (ensuring no individual can be distinguished in a group smaller than k) let you extract insights without exposing anyone.
This is especially relevant when conversation data feeds ML training pipelines. You want the patterns, not the people.
Okay, But How Is Masking Actually Applied?
Knowing the techniques is one thing. Understanding how they get wired into a live system — and what happens to the data after masking — is where most articles stop short.
The Masking Pipeline
In practice, PII masking isn’t a single function call. It’s a pipeline that runs inline with your agent’s logging path:
Step 1: Intercept. Before the conversation is written to any log or data store, the raw text is routed through a masking service.
Step 2: Detect. Each detected entity is tagged with a type and a confidence score.
Step 3: Replace. Each detected entity is replaced. The replacement strategy depends on your downstream needs (more on this below). The masked version of the conversation is what gets written to the log, the analytics warehouse, the observability tool — everywhere.
Step 4: Audit. Records what was detected, what was masked, the confidence score, the policy that triggered it, and the timestamp.
The critical design principle: the agent runtime and the log store never share the same unmasked data path. The agent works with real data in memory, responds to the user, and discards it. The log only ever receives the sanitised version.
The Downstream Problem: Masked Data Still Needs to Be Useful
Here’s the question teams always hit next: “If we mask everything, how do we do analytics? How does the fraud team investigate? How do we debug a failed conversation?”
This is where the replacement strategy matters — and it’s not one-size-fits-all.
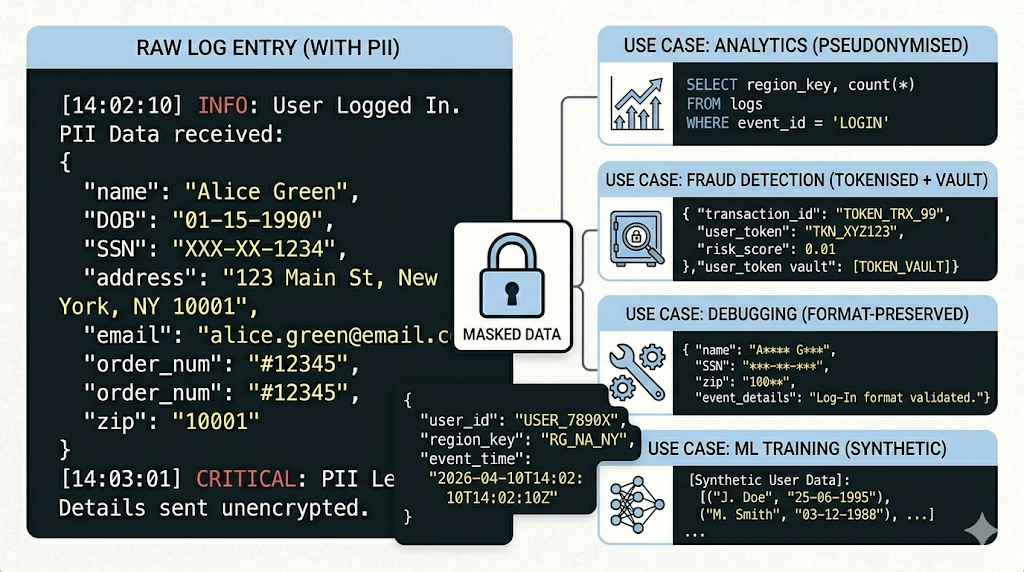
For analytics and ML training: use consistent pseudonymisation. Instead of replacing “Sarah Chen” with ***, replace it with a deterministic pseudonym like User_7f3a. The key property: the same real name always maps to the same pseudonym within a dataset. This means your analytics team can still track that User_7f3a had three conversations, escalated twice, and churned — they just can’t tell it was Sarah. Funnel analysis, cohort behaviour, conversion rates — all preserved. Individual identity — gone.
For fraud and compliance investigations: use tokenisation with a vault. Replace PII with a random token (TKN_8c92b1) and store the token-to-real-data mapping in a separate, access-controlled vault. The analytics layer sees tokens. If a fraud investigator needs the real name behind a suspicious transaction, they submit an authorised request to the vault — which logs the access, the reason, and the approver. This gives you masking for everyday use and a controlled, auditable recovery path for the cases that need it.
For debugging failed conversations: use format-preserving masking. A developer debugging a failed intent doesn’t need to know the user’s real SSN — but they do need to know it was a 9-digit number in the right format. Format-preserving masking replaces 421-55-0198 with 000-00-0000 or a synthetic value like 123-45-6789 that has the same structure. The developer can reproduce the bug without ever seeing real data.
For ML model retraining: use synthetic data generation. Rather than masking individual records, generate entirely synthetic conversation datasets that mirror the statistical properties of the real ones — same distribution of intents, same variety of entity types, same conversational patterns — but with zero real PII. Tools like Gretel, Mostly AI, or custom generative pipelines can do this.
The point is: masking doesn’t mean losing your data’s value. It means decoupling identity from insight — and choosing the right decoupling strategy for each use case.
The Agentic Wrinkle: Why This Is About to Get Much Harder
Everything above assumes a simple pattern: user talks to bot, bot responds, conversation gets logged. That’s the current paradigm. The next one is different.
Agentic AI systems don’t just converse — they act. An AI agent handling a customer request might call a CRM API, query a payments service, trigger an email, and update a database — all in a single turn. Each of those tool calls carries data. Each generates its own logs.
In a multi-agent architecture — where a supervisor agent delegates to specialised sub-agents — PII can propagate across three or four systems in under a second. The user’s social security number doesn’t just land in one log. It lands in the orchestrator’s log, the CRM agent’s log, the payment agent’s log, and the notification agent’s log.
This is the PII fan-out problem, and it’s the next frontier of data governance for AI. Masking at the conversation layer isn’t enough anymore — you need masking at the inter-agent communication layer, ensuring that when Agent A passes context to Agent B, sensitive fields are stripped or tokenised before the handoff.
The companies building agentic systems today — and I work on these at the enterprise level — need to think about this now, before the architecture calcifies and retrofitting becomes a nightmare.
A Practical Checklist If You’re Starting Today
If you’re an engineering or product leader deploying AI agents, here’s where to start:
Audit your log pipeline. Trace the path of a single conversation from the agent to every system it touches. You’ll likely be surprised by how many hops there are.
Classify your PII. Not all PII is equal. A name is sensitive. A social security number is critical. Your masking aggressiveness should match the sensitivity tier.
Mask pre-storage, not post. If plaintext PII hits disk, you’ve already failed the “by design” test.
Layer your detection. Regex for structured patterns, NER for unstructured. Neither is sufficient alone.
Build audit trails. Every masking event should be logged — what was detected, what was masked, when, under what policy. This is your evidence during a compliance review.
Test for re-identification. Masked data can sometimes be reverse-engineered by combining fields. “Male, 28, Seattle, works in consulting” might uniquely identify someone even without a name. Run re-identification risk assessments on your masked datasets.
Final Thought
The conversation between a user and an AI agent is a contract of trust. The user shares personal information because they need something done. That trust doesn’t extend to the fifteen backend systems that process, store, and analyse the conversation after it ends.
PII masking is how you honour that contract at the infrastructure level — not just in the privacy policy nobody reads.
If you’re building AI systems that handle personal data, the question isn’t whether to mask. It’s whether you’re masking at the right layer, with the right techniques, before it’s too late to retrofit.
Reference: Standards and Frameworks Worth Knowing
You don’t have to build your PII masking policy from scratch. These provide the guardrails:
- NIST SP 800–122 & NIST Privacy Framework — Guidance on identifying, minimising, and protecting PII, including risk assessment and de-identification strategies. https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-122.pdf
- GDPR Article 25 (Data Protection by Design) — Requires embedding data protection into system architecture, ensuring only necessary personal data is processed and stored.
https://gdpr-info.eu/art-25-gdpr/ - OWASP Top 10 for LLM Applications — Highlights risks such as sensitive data leakage, prompt injection, and unintended exposure through logs and training data. https://owasp.org/www-project-top-10-for-large-language-model-applications/
Building enterprise AI and thinking about data governance? I’d love to hear how your team handles PII in agent logs. Connect with me or drop your thoughts in the comments.
Your AI Isn’t the Risk. Your Logs Are. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.