
Why I Spent Years Building a 35,000 Prediction/s Forecasting Engine…

I have spent most of my career working in high-frequency data environments where data moves continuously and at a large scale. In telecom networks, every cell, every subscriber interaction, every network function generates a time series, each one carrying relevant information about performance, behaviour, and risk.
Yet for years, one assumption remained largely unchallenged:
We cannot analyse everything.
Not because it wasn’t valuable, but because it wasn’t practical.
It has traditionally been too expensive, too computationally heavy, and too complex to operate at scale. In many cases, the business case simply did not justify the infrastructure required to sustain it… That assumption wasn’t wrong; it was a reflection of the tools we had.
The problem was not the absence of data.
The problem was never the absence of data, but the inability to keep up with it sustainably. As systems scale, a gap emerges between how fast the system evolves and how fast models can adapt, and it is within this gap that many failures occur.
From Accuracy to Adaptation: The Bottleneck Shift
Over the past decade, time series modelling has improved significantly, with better handling of non-stationarity and drift, increased robustness to noise, support for multiple forecasting horizons, and strong performance in controlled and benchmark environments.
These are meaningful advances, but in production, a different limitation becomes visible.
In real-world systems, the challenge is no longer how well models can predict, but how fast they can adapt without stopping. Most approaches still rely on a cycle of training on historical data, deploying the model, and retraining as performance degrades, creating an unavoidable delay between a change in the system and adaptation of the model; at a small scale, this delay is manageable, but at a large scale, it becomes structural.
From Accuracy to Adaptation
What I realised over time is that the problem was misframed. We were optimising for accuracy (we were obsessed with accuracy). But the real constraint was the cost and latency of learning.
In environments where thousands of time series evolve continuously, a model that adapts too slowly, or requires too many resources to stay relevant, is effectively operating on outdated assumptions, regardless of how accurate it once was.
Why This Matters
This is why I spent years building a system capable of processing tens of thousands of predictions per second, while continuously absorbing drift and maintaining competitive accuracy on challenging datasets. Not to make forecasting faster for its own sake, but to remove the constraint that made large-scale, continuous analysis economically and operationally unfeasible.
Because once prediction becomes the bottleneck, you are no longer limited by data; you are limited by your ability to learn in time.
The Hidden Assumption: Train → Freeze → Predict
Most time series systems, whether statistical, machine learning, or deep learning, follow the same cycle: train on historical data, freeze the model, use it for prediction, and retrain when performance degrades. This is not a limitation of specific algorithms, but of an underlying assumption about how learning should occur, only when necessary.
A Model That Stops to Think
While this approach is intuitive, learning from the past, deploying, and updating when needed, it introduces a critical limitation in continuously evolving systems: the model cannot learn while it is acting.
Each adaptation requires retraining, creating a learning gap where the system has already changed, but the model still operates on outdated assumptions, missing new patterns and potential anomalies.
This paradigm performs well in controlled environments where training data is normally stable, retraining is manageable, and computing resources are abundant. But in production systems, non-stationary, distributed, resource-constrained, and continuously evolving, retraining shifts from an update mechanism to a fundamental bottleneck.
The scalability challenge
As the number of time series grows, the cost of retraining scales rapidly: more signals require more models, more drift demands more frequent updates, and more updates increase compute, latency, and operational complexity.
This leads to a structural trade-off: either simplify models to keep them deployable or centralise processing and absorb the increase in latency and cost, but in both cases, adaptability is compromised.
Underlying this is a deeper assumption: intelligence can be centralised, periodically refreshed, and scaled by adding compute, yet in practice, this scales infrastructure, not adaptation. As systems become more dynamic, behaviour evolves faster than retraining cycles, creating a growing gap between observation and response, where models appear accurate on average but fail precisely where decisions matter.
But what if learning did not require retraining?
From Functions to Transitions
Most time series approaches treat the problem as function approximation: learn a global relationship from past data and use it to predict the future. But in continuously evolving systems, signals do not behave like stable functions. They behave like sequences of transitions between states.
Instead of asking “what is the function that fits this data?”, a different question emerges:
“What are the patterns, and how do they evolve over time?”
A Continuous View of Learning
In this view, learning is no longer a periodic event; it becomes a continuous process. Each new observation updates the internal representation, refines existing patterns, or creates new ones as the system evolves.
There is no retraining cycle and no freeze phase. Learning and inference are no longer separate steps; they become the same operation, happening continuously as data flows.
Tracking Transitions, Not Fitting Curves
Rather than fitting a model to the entire history, the system builds a structure of observed transitions. Patterns are identified online, relationships between them are tracked, and future behaviour is inferred from how these transitions have occurred over time. This can be understood as a graph of evolving states, rather than a fixed equation.
By removing the need for retraining, adaptation becomes immediate, and latency disappears. Complexity no longer scales with data volume, but with the diversity of patterns the system encounters.
The system no longer needs to “catch up” with reality. It evolves with it.
The Benchmark
A Direct Comparison Under Continuous Load
To evaluate this approach under realistic conditions, I ran a direct benchmark against two widely used baselines: Adaptive ARIMA using Kalman Filters and Prophet.
The setup was intentionally simple. All models were exposed to the same input data simulating a continuous streaming scenario, with no HTTP overhead and no artificial batching. The dataset comes from the Numenta Anomaly Benchmark (NAB), specifically the Machine Temperature System Failure series, a widely used reference for time series evaluation.
Results

This output summarises the three models under identical conditions. DriftMind achieved a mean absolute error (MAE) of 0.8213 while processing approximately 34,500 predictions per second, completing the full dataset in around 0.65 seconds.
ARIMA reached a slightly higher MAE of 0.8529, but required roughly 207 seconds to process the same data, operating at approximately 108 predictions per second.
Prophet showed a significantly higher error (MAE 2.9901) and required approximately 940 seconds to complete, with a throughput of around 23 predictions per second.
The differences become clearer when aggregated:
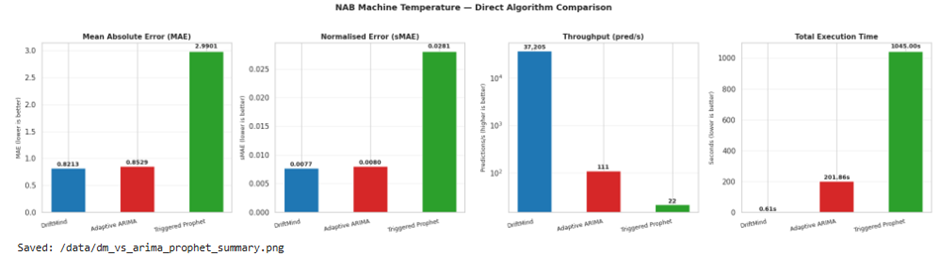
DriftMind achieves both the lowest error and the highest throughput by a wide margin.
The key observation is not only the performance gap, but its nature: while ARIMA and Prophet trade accuracy for computational cost through repeated retraining, DriftMind maintains both efficiency and accuracy through continuous updates.
This is not a marginal improvement; it reflects a fundamentally different scaling behaviour.
Looking beyond aggregate metrics, the behaviour over time reveals a more important difference:

All three models track the overall signal reasonably well, but their error profiles differ significantly.
DriftMind maintains a more stable and consistently low error distribution across the entire sequence, while ARIMA and Prophet exhibit higher variance and more frequent spikes, particularly around abrupt changes.
These spikes are not just statistical artefacts; they reflect moments where the model is misaligned with the current state of the system, often due to retraining lag.
What This Shows
The difference is not just speed.
DriftMind is both faster and slightly more accurate than ARIMA, while being orders of magnitude faster than both ARIMA and Prophet. More importantly, it achieves this without any retraining phase.
ARIMA and Prophet spend most of their execution time repeatedly rebuilding their internal models as new data arrives. DriftMind, by contrast, updates continuously. It does not pause, does not retrain, and does not need to reprocess history to remain relevant.
Reproducibility
The full benchmark can be reproduced locally with a single command:
docker run -p 8080:8080 -p 8888:8888 thngbk/driftmind-edge-lab
Then open http://localhost:8888/notebooks/dm_vs_arima_prophet.ipynb and run the notebook
The Latency of Learning
What this benchmark exposes is not just a performance gap, but a structural one. In most systems, learning is not continuous. It happens in discrete steps, triggered by retraining cycles. Between those steps, the model operates on assumptions that are already becoming outdated.
This introduces what can be described as the latency of learning: the delay between a change in the system and the model’s ability to incorporate it.
In static environments, this delay is acceptable. In continuously evolving systems, it becomes the defining limitation. When learning is delayed, everything downstream is affected.
- Anomalies are detected later than they occur.
- Predictions reflect past conditions rather than present ones.
- Decisions are made with partial awareness of what is actually happening.
Over time, this erodes confidence. Systems may appear accurate on average, but fail precisely in the moments where adaptation matters most.
Removing retraining does more than improve performance. It removes the delay between observation and adaptation. Learning becomes immediate. Prediction becomes a byproduct of continuous state tracking. The system no longer reacts to change; it evolves with it.
In environments such as telecom or IoT, this distinction is critical. The question is no longer whether models can handle drift in theory, but whether they can do so under real-world constraints of scale, cost, and latency.
Because in the end, the limiting factor is not how much data we have or how sophisticated our models are. In real-time systems, intelligence is not defined by how well you predict the future, but by how fast you adapt to the present.
Why I Spent Years Building a 35,000 Prediction/s Forecasting Engine… was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.