
Why Distributed State Management Is the Context Graph for Physical AI
In my last blog, I wrote about memory as the missing state layer for agents.
In this piece, I want to stretch the idea further and look at state across distributed endpoints — local agents, phones, robots, sensors, vehicles — what I think of as the context graph for physical AI, capturing intent, precedent, and decision traces across distributed actors. Not just as a buzzword, but as a world where compute, decisions, and data increasingly live outside centralized clouds.
Why distributed state matters, especially now
A personal moment in San Francisco made this intuitive for me.
One afternoon, I was riding a Waymo through the busy Financial District. Two other Waymos stopped ahead of us, one in the right lane trying to turn left, the other in the left lane trying to turn right. Neither could decide who should go first. For several minutes, both vehicles hesitated, blocking traffic and frustrating the human drivers behind them.
What struck me was how mundane the problem was, and how solvable it could have been. If one Waymo could have directly “gestured” to the other – over a short-range channel like Bluetooth or LoRa – signaling “you go first” via shared state, the deadlock could have been resolved almost instantly. No cloud round-trip or centralized coordination needed.

That moment also made me think about the future.
Centralized orchestration still works “well enough” today. But as local agents, autonomous vehicles and device fleets scale into the millions, shipping every coordination or decision back to a central authority becomes economically and architecturally unsustainable.
Specifically, I see three key forces converging that fundamentally change what state means in computing:
AI agents take intelligence to the edge: The rise of Clawdbot showed local agents are no longer hypothetical. Today, I could run a 4B-parameter open-source Qwen3 model on my Mac Pro with sub-second latency. By the end of this decade, it’s projected that ARM-class chips will be able to run LLMs efficiently.
Endpoints and data generation are exploding in number: Phones, wearables, robots, autonomous vehicles, medical devices etc. It’s estimated that over 400 million TB of data are generated daily – equivalent to 20 trillion high-res photos! Unlike the IoT era, systems are not just collecting telemetry for the cloud – they are making decisions locally.
Regulation + geopolitical push: Total fines by regulations like GDPR and HIPAA have increased more than 10x over the past 5 years. At the same time, geopolitical fragmentation has eroded trust in centralized software stacks. TikTok ban showed it’s no longer enough to claim data wasn’t tampered with – you must be able to prove it with auditable evidence that must stand up to legal and political scrutiny.
Why this is not just a replication problem
At first glance, this sounds familiar: distributed databases, primary-replica, eventual consistency…haven’t we solved this already?
Not quite.
Traditional cloud distributed systems assume stable infra — reliable, low-latency nets (<1ms pings), abundant resources (TB RAM VMs), and central coordination (replication leaders, quorum, control planes). Failures are also rare, handled by auto-failover with high-availability standby replica
Distributed device systems break almost every one of these assumptions, specifically:
Network assumptions break. Devices could go offline for minutes, hours, or even days. Connectivity is intermittent, asymmetric, or expensive. Up to 40% packet loss in remote areas.
Compute and Coordination is a luxury. Limited CPU/RAM (1–8GB), battery life that drains with constant syncs. Nodes join/leave dynamically (roaming phones), quorums fail at ~50% dropout.
Time is unreliable: No shared clock. Ordering events is a probabilistic exercise, not a given.
Trust boundaries are fuzzy: More devices mean more attackable endpoints with Byzantine risks (lying nodes).
This is where traditional tools like primary-replica replication, global clock, firewalls and Paxos/Raft consensus algorithm fall short.
Distributed devices require a fundamentally different architectural design that treats distributed state as a first-class primitive, not an afterthought or side effect of databases.
Emerging approaches: what’s actually interesting now
Over the past few years, I’ve seen a new class of systems has started to emerge, often grouped under local-first or offline-first architectures (see the local-first GitHub list).
Take some emerging tech stacks as an illustrative example:
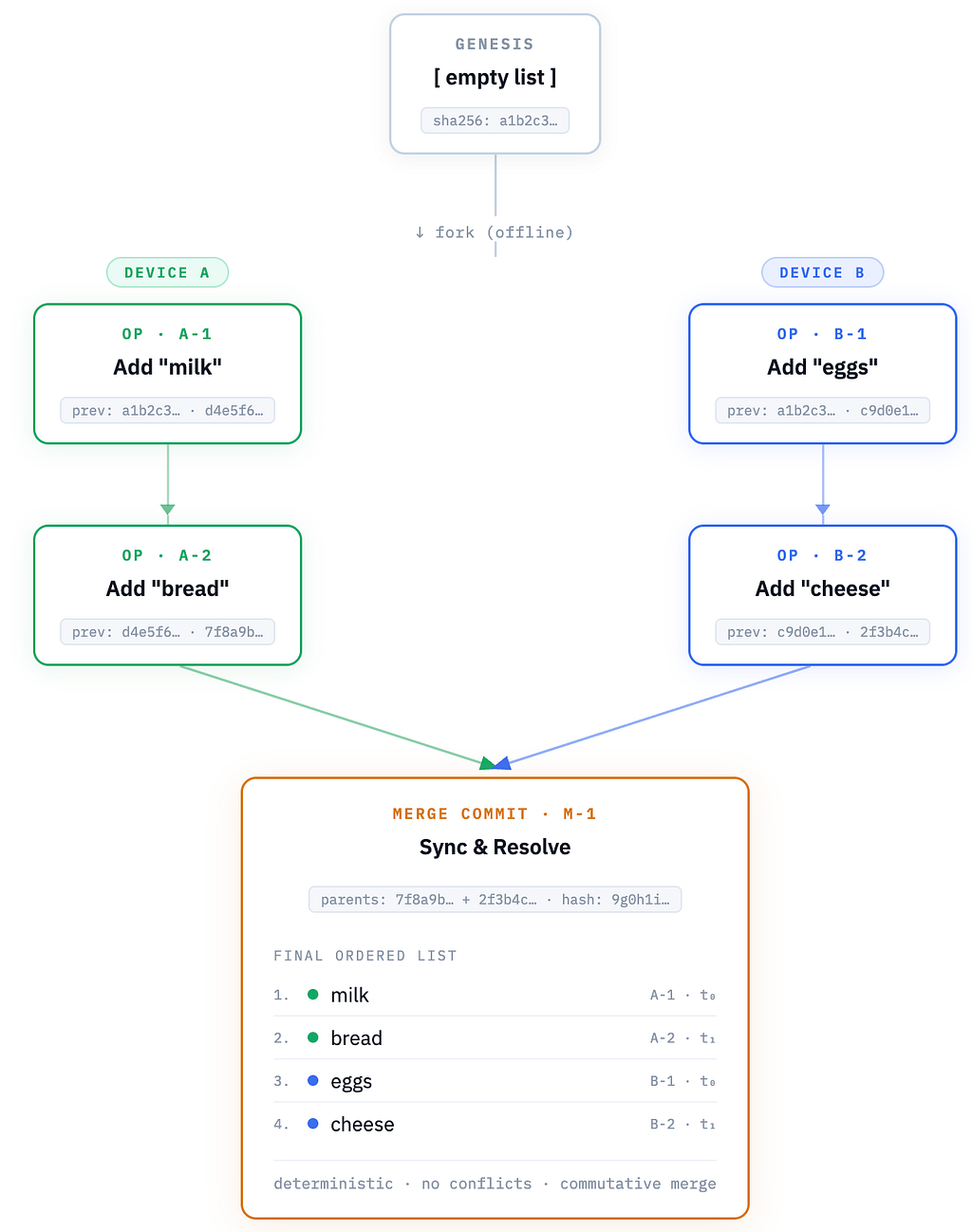
Content-addressable state using Merkle DAGs
In this structure, devices don’t need to trust where data came from, only that it matches a hash. History becomes intrinsic to the data structure, not an external log. Every update is a hash-linked node in an immutable graph, making provenance and tamper-proofing inherent, unlike plain key-value stores where history is opaque or requires extra logging.
Merkle-based CRDTs (Conflict Resolution Data Types)
Instead of asking “what time did this event happen?”, you ask “what history led to this event?”, and you get a content-verified causal chain.
Where updates form causally ordered graphs and merge automatically via delta-states. These extend delta-state CRDTs with Merkle clocks for causal ordering without vector clocks (which suffer from skew and size bloat in heterogeneous fleets), enabling deterministic auto-merges for conflicts in a way that’s lightweight for low-power devices.
Recursive ZK proofs
In effect, this allows a device to say: “This current state is the result of a valid sequence of updates, without replaying the entire history.”
Unlike common DAG-based systems where deep traversals slow queries, this compresses verification into practical, near-constant-time checks, a step beyond traditional CRDT snapshots that still demand full replays.
Leaderless P2P networking (LibP2P + Pub/Sub)
Instead devices discover peers, exchange state opportunistically, and sync only what’s relevant. Enabling ad-hoc synchronization contrasting cloud gRPC hierarchies.
Arguing whether any specific technology is superior misses the point. Limitations remain — developer complexity, overhead at massive scale — but what matters is the direction: applications built on self-describing, resilient data model rather than constantly fighting to reconstruct it after the fact.
So, where is the business model?
At first glance, distributed state management feels like it should end up as open-source infrastructure: important, ubiquitous, and hard to monetize directly. That skepticism is reasonable — many “data infra” categories have been commoditized over time (e.g. PostgreSQL, Kafka).
But I believe distributed state is one of the areas where a durable business model can exist, not because the code is proprietary, but because the operational risk and accountability are. The initial beachheads could be industries where state divergence has immediate financial, safety, or compliance consequences. In other words, the buyer isn’t paying for “a database”. They’re paying for fewer incidents, faster recovery and the ability to explain what happened.
Another reason for the belief: the “state tax” grows and compounds with every device shipped: as fleets grow, so does the churn, complexity, heterogeneity, and attack surface, which creates a recurring need for governance, rolling upgrades / rollbacks, audit trails, monitoring etc..
Notably, some startups I’ve spoken with are being intentional to business model here — prioritizing early revenue rather than relying solely on open-source adoption.
Pricing models showing early commercial success include: charging by No. of devices/nodes or by volume of data processed; Managed services for edge <> cloud sync with initial freemium tier (~ X GB/month); Licensing + enterprise support/maintenance for control and governance
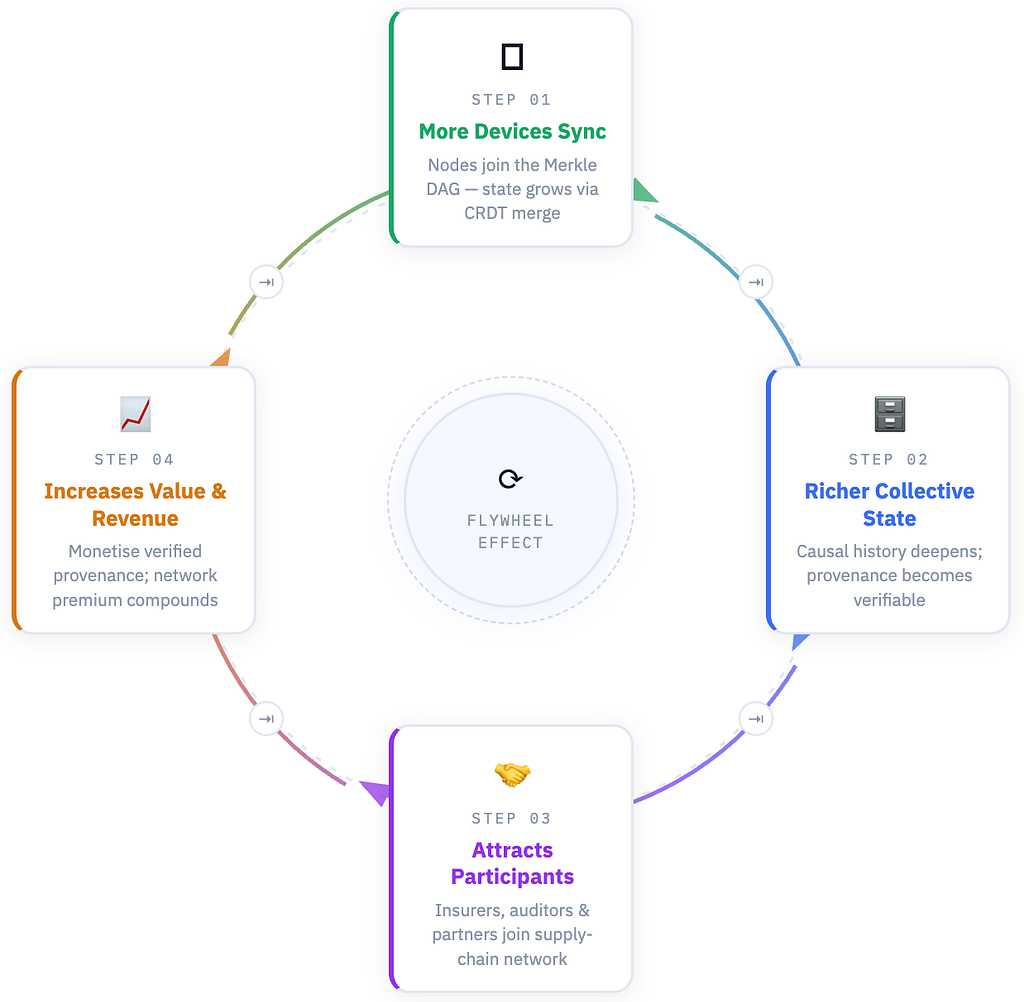
Data Flywheel
There’s also a potential data flywheel effect, where each new participant increases the system’s collective intelligence.
The more devices that participate in a shared synchronization layer, the more valuable that layer becomes — not just because there are more nodes, but because the collective state becomes richer and more predictive.
In the earlier Waymo example, two vehicles coordinating is helpful. But imagine thousands of AVs and traffic lights in a city sharing intent, road conditions, temporary obstacles, or behavioral heuristics in near real-time. The coordination layer itself becomes smarter as participation increases.
The same could apply in other industries. In defense, each additional drone or soldier wearable improves the completeness of the battlefield picture. In finance, fraud detection becomes stronger with more merchants and wallets participating.
Who Wins?
I believe it’d be a mix but with room for startups to becoming category leader:
· Open-source hybrids that balance PLG with enterprise GTM polish
· Vertical specialists nailing the specific pain points (e.g. industrials, healthcare)
· Big infra players potentially acquiring to bolt on edge smarts
Either way, the winners would be those who thrive on the next-gen protocol designed from first principles: infrastructure builders who treat distributed state as a core primitive.
Closing thought
As computation and agents move closer locally, we’re inevitably entering a world where intelligence is distributed and reality keeps moving, even when the network doesn’t.
In that world, state becomes more than just “record”; it becomes the context graph for physical AI, the causal context that makes decisions meaningful.
Whoever learns how to manage distributed state, securely and at scale, has a real chance to define the next generation of infrastructure, whether we call it edge, local-first, or something else entirely.
One last thought: as GenAI systems converge on semantic intent rather than bit-for-bit agreement — given their inherently non-deterministic nature — traditional deterministic consensus models may no longer be sufficient. The next generation of distributed protocols may need to reconcile meaning, not just state. We’ll explore that idea further in the future.
(Thank you for reading! I always appreciate thoughtful feedback and reflections. Feel free to connect with me on LinkedIn or X if you’d like to exchange ideas or discuss further 🙂
Why Distributed State Management Is the Context Graph for Physical AI was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.