")
Why 90% of Agentic RAG Projects Fail (And How to Build One That Actually Works in Production)

A Guide for Developers to Build Production-Level Rag Applications
Most enterprise AI pilots fail. McKinsey’s research found only 10–20% of AI proofs-of-concept scale beyond pilots.
Why? Teams treat production systems like demos.
I’ve seen companies spend six months building agentic RAG systems that work beautifully in notebooks, then deploy to production and discover queries cost dollars, take 8 seconds to respond, and loop infinitely on untested edge cases.
The problem? Complexity kills projects.
Every agent multiplies failure modes. Simple RAG makes 2–3 LLM calls per query. Add routing, validation, and fallbacks, and you’re at 10–15 calls. Without caching and monitoring, costs explode.
Here’s what breaks in production:
Your router misroutes 40% of queries. Your retrieval fetches irrelevant documents that pollute the context. Your validator approves hallucinations. And you have no observability to debug any of it because you focused on features, not instrumentation.
The companies that succeed? They design for failure first, then add intelligence.
What Agentic RAG Actually Is
Strip away the hype. Agentic RAG means your system makes decisions before retrieving data.
Instead of blindly fetching any matching document, it asks: Do I actually need to search? Which documents matter? In what order should I check them?
Here’s the difference:

Real example:
A compliance chatbot for financial services.
Traditional RAG retrieves documents for “What’s the interest rate?” and returns outdated policy PDFs mixed with current rates.
Agentic RAG routes simple rate queries directly to a database, retrieves policies only for complex regulatory questions, and cross-checks answers against multiple sources before responding.
The result: measurably better accuracy and fewer hallucinations compared to blind retrieval.
The key insight: Intelligence isn’t about more agents. It’s about smarter decisions at each step.
THREE PATTERNS THAT ACTUALLY WORK

Pattern 1: Smart Routing (Decide WHEN to Retrieve)
Not every question needs document retrieval. “What’s 2+2?” doesn’t require searching your vector database.
Smart routing reduces unnecessary retrieval calls.
Research from Adaline Labs on production RAG deployments showed that intelligent query classification can cut costs by 30–45% and reduce latency by 25–40% by routing simple queries directly to appropriate handlers instead of triggering expensive retrieval pipelines.
Here’s a simple router:
def route_query(query: str) -> str:
if matches_math_pattern(query):
return "calculator"
if needs_current_data(query):
return "web_search"
if is_simple_faq(query):
return "direct_llm"
return "rag_pipeline"
Production reality:
Start with heuristics (regex for dates, calculations, greetings), then add an LLM classifier for ambiguous cases. Don’t route everything through an LLM; that adds latency and cost for queries you can handle with rules.
The tradeoff:
A classification call costs around $0.0001. Five blind retrieval calls with embeddings and vector search cost roughly $0.001. That’s 10x savings per routed query.
Pattern 2: Self-Checking (Validate WHAT You Retrieve)
Your retrieval returned five chunks. Are they actually relevant? Does your answer use them correctly?
Self-RAG adds reflection: The model checks if retrieved documents help, then validates if its answer is supported by sources.
CRAG (Corrective RAG) scores chunks before generation and triggers a web search if the retrieval quality is low.
When to use each:
- Self-RAG: When factuality matters more than speed (legal, medical, compliance)
- CRAG: When retrieval often fails, and you need fallback strategies
Here’s Self-RAG in LangGraph:
def validate_retrieval(state):
docs = state["documents"]
query = state["query"]
score = llm.invoke(f"Are these docs relevant to '{query}'? YES/NO")
return "generate" if score == "YES" else "web_search"
Real impact: According to the original Self-RAG paper (Asai et al., 2023), the approach significantly reduces hallucinations in question-answering tasks by adding validation steps, though this adds 2–3 seconds of latency. Use it when correctness beats speed.
Pattern 3: GraphRAG for Complex Queries (Know WHEN to Use Graph)
Vector RAG fails on questions like “Which companies in our portfolio have both declining revenue and increasing operational costs?”
That’s a multi-hop query requiring entity relationships. Vector similarity won’t find it because the answer isn’t in a single chunk. It requires connecting facts across documents.
GraphRAG builds a knowledge graph from your documents: entities, relationships, and attributes. Then it answers queries by traversing the graph.
Microsoft’s GraphRAG research (2024) demonstrated significant accuracy improvements on complex enterprise queries. In their evaluation on multi-hop reasoning tasks, graph-based retrieval achieved 86% comprehensiveness compared to 57% for traditional vector RAG. However, these gains come with tradeoffs: graph construction takes 2–5x longer than vector indexing, and queries show roughly 2–3x higher latency than simple vector search.
Expanded Decision Matrix:

When GraphRAG wins: Schema-heavy queries (databases, org charts, financial statements), multi-entity questions (competitive analysis, research synthesis), questions requiring “why” not just “what” (root cause analysis).
When it’s overkill: Single-document questions, straightforward fact lookup, user-facing chatbots where sub-second latency matters.
Start with vector RAG. Add GraphRAG only after you identify query patterns where vectors fail. Don’t build graphs preemptively; most systems don’t need them.
The Hidden Precision Layer: Reranking
Here’s a problem nobody talks about: Your vector search returns 20 chunks. The answer is in chunk #17, but your LLM only reads chunks #1–5 because of lead bias.
Vector search is fuzzy. It finds semantic similarity, not correctness. You need a reranker to sort chunks by exact relevance.
The process:
- Retrieve 20 chunks from vector DB (fast, cheap)
- Rerank with a cross-encoder like Cohere or BGE (slower, precise)
- Send only the top 3 high-signal chunks to the LLM
This cuts context pollution significantly and improves answer quality without changing your retrieval setup. Libraries like LangChain support rerankers out of the box:
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CohereRerank
reranker = CohereRerank(top_n=3)
compressed_retriever = ContextualCompressionRetriever(
base_retriever=vector_store.as_retriever(search_kwargs={"k": 20}),
base_compressor=reranker
)
Cost tradeoff: Reranking 20 chunks costs about $0.002 per query. But it prevents sending irrelevant context to your LLM, which saves tokens and improves accuracy.
Where Teams Go Wrong
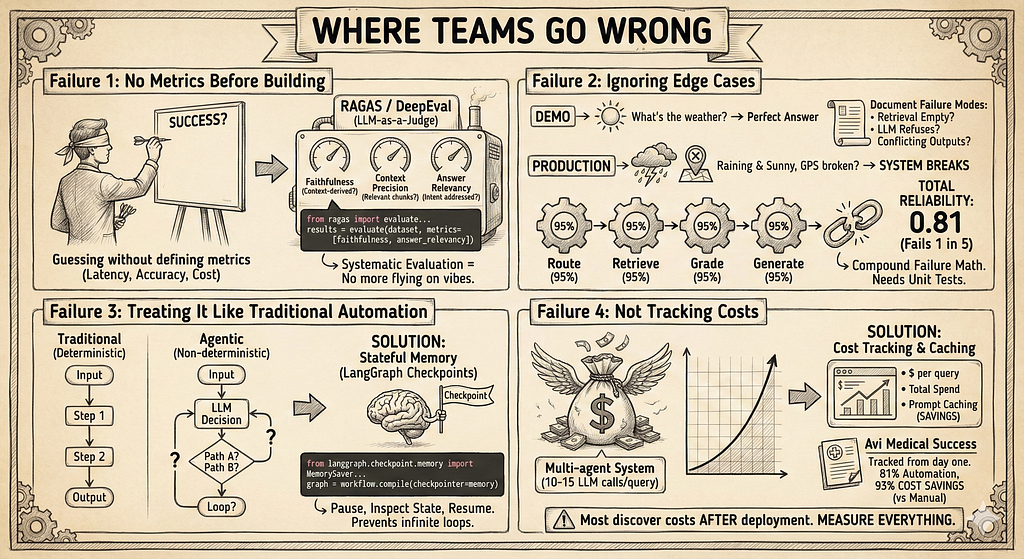
Failure 1: No Metrics Before Building
Teams build agentic systems without knowing what success looks like. Then they can’t tell if their routing logic improves anything or makes it worse.
Define metrics first:
What’s acceptable latency? What accuracy do you need? What’s your cost budget per query? If you can’t answer these, you’re guessing.
The solution: Use RAGAS or DeepEval. These frameworks use LLM-as-a-judge to evaluate your RAG system automatically:
- Faithfulness: Is the answer derived only from the retrieved context?
- Context Precision: Are retrieved chunks actually relevant?
- Answer Relevancy: Does the answer address the user’s intent?
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy
results = evaluate(
dataset=test_questions,
metrics=[faithfulness, answer_relevancy]
)
Without systematic evaluation, you’re flying on vibes. A prompt change might fix one case and break three others. RAGAS catches this before users do.
Failure 2: Ignoring Edge Cases
Your demo handles “What’s the weather?” perfectly. Production sees “What’s the weather like when it’s raining but also sunny, and my GPS is broken?”
Edge cases break systems. Document failure modes:
What happens when retrieval returns nothing? When does the LLM refuse to answer? When do two agents give conflicting outputs?
The math of compound failure:
If your system has 4 steps (Route, Retrieve, Grade, Generate) and each is 95% accurate, your total reliability is:
0.95 × 0.95 × 0.95 × 0.95 = 0.81
Your “perfect” components create a system that fails 1 in 5 times. Production systems need unit tests for every transition in the chain.
Failure 3: Treating It Like Traditional Automation
Agentic systems aren’t deterministic. The same query can take different paths based on LLM decisions. You can’t debug them like traditional software.
You need stateful memory. When an agent fails at step 3 (validation), it shouldn’t restart from scratch. It needs to remember what it tried and why it failed.
LangGraph solves this with checkpoints:
from langgraph.checkpoint.memory import MemorySaver
memory = MemorySaver()
graph = workflow.compile(checkpointer=memory)
Now your agent can pause, inspect the state, and resume without losing context. This prevents infinite loops and redundant API calls.
Failure 4: Not Tracking Costs
Multi-agent systems make 10–15 LLM calls per query. Without tracking, a single viral query pattern can cost thousands in a weekend.
Real example: Avi Medical built an agentic system for appointment scheduling. According to their published case study, they tracked costs from day one, implemented prompt caching, and achieved 81% task automation with 93% cost savings compared to their previous manual process. They succeeded because they measured everything.
Most teams don’t. They discover costs after deployment.
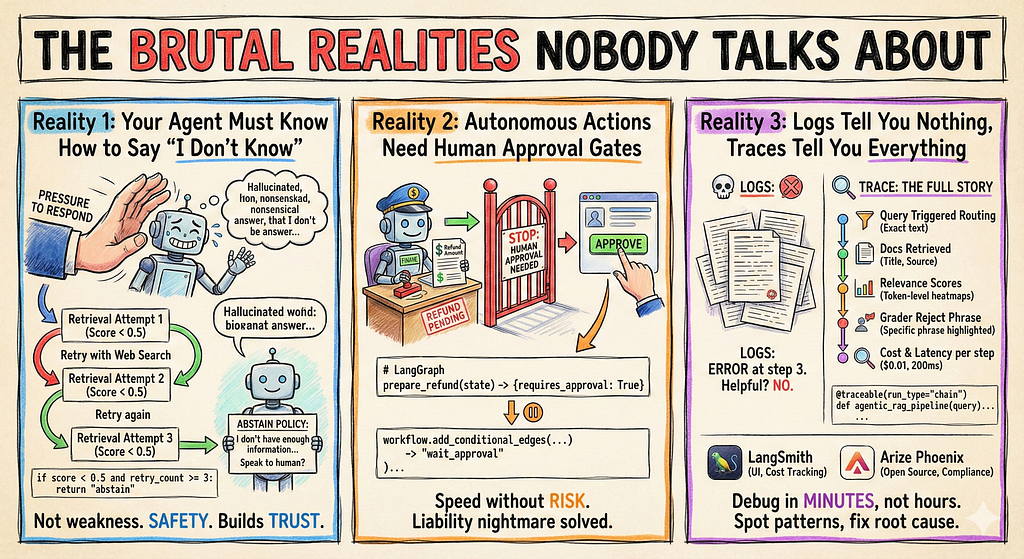
Reality 1: Your Agent Must Know How to Say “I Don’t Know”
The biggest production mistake? Forcing agents to answer everything. An agent pressured to respond will eventually hallucinate.
The abstain policy: If your context precision score is below 0.5 after three retrieval attempts, your agent should exit gracefully:
def grade_documents(state):
score = calculate_precision(state["documents"], state["query"])
retry_count = state.get("retry_count", 0)
if score < 0.5 and retry_count >= 3:
return "abstain"
elif score < 0.5:
return "retry_with_web_search"
return "generate"
def abstain(state):
return {
"answer": "I don't have enough information in our documentation to answer this safely. Would you like to speak with a human specialist?",
"confidence": "low"
}
This isn’t a weakness. It’s safety. Users trust systems that admit uncertainty more than systems that confidently hallucinate.
Reality 2: Autonomous Actions Need Human Approval Gates
If your agent can take actions (process refunds, update records, send emails), you need Human-in-the-Loop (HITL) gates.
The problem: Autonomous agents making financial or operational decisions are a liability nightmare.
The solution: Use LangGraph’s interrupt feature. The agent prepares the action, saves the state, and waits for human approval:
from langgraph.graph import StateGraph
def prepare_refund(state):
refund_amount = calculate_refund(state["order_id"])
return {
"pending_action": f"Refund ${refund_amount}",
"requires_approval": True
}
workflow = StateGraph(...)
workflow.add_node("prepare_refund", prepare_refund)
workflow.add_node("execute_refund", execute_refund)
# Agent pauses here until human approves via UI
workflow.add_conditional_edges(
"prepare_refund",
lambda x: "wait_approval" if x["requires_approval"] else "execute_refund"
)
The agent does the research, validates the policy, and prepares everything. A human just clicks “Approve” or “Reject.” This gives you speed without risk.
Reality 3: Logs Tell You Nothing, Traces Tell You Everything
You need observability, but let’s be specific: logs are useless for debugging agentic systems.
A log says: ERROR: Agent failed at step 3. Helpful? No.
A trace shows you:
- The exact query that triggered routing
- Which documents were retrieved
- The token-level relevance scores
- The specific phrase that caused the grader to reject
- The cost and latency of each step
Use LangSmith or Arize Phoenix for tracing:
from langsmith import traceable
@traceable(run_type="chain")
def agentic_rag_pipeline(query: str):
route = route_query(query)
docs = retrieve_documents(query)
graded = grade_relevance(docs, query)
answer = generate_response(graded, query)
return answer
Now every production query creates a trace you can inspect. You see exactly where failures happen and why. This turns debugging from hours of guesswork into minutes of targeted fixes.
Tools comparison:
- LangSmith: Best for LangChain/LangGraph users, excellent UI, automatic cost tracking
- Arize Phoenix: Open source, works with any framework, great for compliance teams that can’t send data externally
Without tracing, you’re debugging blind. With it, you can spot patterns like “90% of failures happen when query length exceeds 200 characters” and fix the root cause.
The Production Checklist
Before you deploy, answer these honestly:
Do you have clear metrics? YES / NO
What’s your target accuracy? Latency? Cost per query? If you don’t know, you’ll optimise blindly.
Are you using RAGAS or a similar evaluation? YES / NO
Can you quantify whether a change improved your system? Or are you relying on manual spot checks?
Does your agent know when to abstain? YES / NO
Can it gracefully exit when confidence is low? Or does it hallucinate under pressure?
Can you handle failures? YES / NO
What happens when your LLM provider is down? When does retrieval return garbage? When do gents loop infinitely? Do you have fallbacks?
Is cost-per-query tracked? YES / NO
Every LLM call, every embedding generation, every vector search has a cost. Are you monitoring it in real time?
Are edge cases documented? YES / NO
Have you tested malformed queries? Adversarial inputs? Empty retrieval results? The weird stuff will users definitely send?
Do you have stateful memory? YES / NO
Can your agents remember previous attempts to avoid repeating mistakes?
Are you using traces, not just logs? YES / NO
Can you debug a failed query in minutes by inspecting the full execution path?
Do high-risk actions have HITL gates? YES / NO
Can your agent trigger financial or operational actions without human approval?
If you answered NO to any of these, you’re not ready for production.
What Real Data Shows
Let’s be honest about tradeoffs. No pattern is universally better.
GraphRAG vs Vector RAG: According to Microsoft’s GraphRAG evaluation (Edge et al., 2024), graph-based approaches achieved 86% comprehensiveness on complex multi-entity queries compared to 57% for baseline vector RAG. However, this comes with roughly 2–3x higher latency (averaging 3–4 seconds vs 1.2 seconds for vector-only approaches) and increased computational costs.
Query Routing Impact: Production data from Adaline Labs’ RAG optimisation studies shows that intelligent routing can reduce unnecessary retrieval operations, leading to cost reductions in the 30–45% range and latency improvements of 25–40% for workloads with mixed query complexity.
Self-RAG Validation: The Self-RAG paper (Asai et al., 2023) demonstrated that adding retrieval validation and answer verification steps significantly improves factual accuracy in question-answering benchmarks, though these additional checks add 2–3 seconds of processing time per query.
The pattern: Smarter systems cost more and run slower. Choose intelligence where it matters. Use simple RAG for speed-critical user-facing features. Reserve GraphRAG and Self-RAG for high-stakes queries where accuracy justifies the cost.
The Scientific Journal Analogy
A production-ready agentic RAG isn’t just a “smart person.” It’s a scientific peer review process:
- The Editor (Router): Decides if the paper is worth reviewing or should be rejected immediately
- The Archive (Vector DB): Where the facts live
- The Librarian (Reranker): Sorts papers by relevance to the research question
- The Peer Reviewers (Validators): Check citations. If a citation is missing or fake, they send it back
- The Author (Generator): Writes the paper based on verified sources
- The Ethics Committee (HITL Gates): Approves publication of sensitive findings
- The Quality Control (RAGAS/Traces): Ensures the process follows standards
- The Abstain Button: When evidence is insufficient, don’t publish
If you just had an Author (traditional RAG), you’d get a lot of fake news. The process creates truth.
Build for Reality, Not Demos
Here’s what matters: Build one agent that works in production instead of ten that work in demos.
Production-ready means:
- You’ve tested failure modes, not just happy paths
- You track costs per query, not just overall spend
- You can debug why an agent made a decision with traces, not logs
- You have fallbacks when components fail
- Your agent knows when to abstain instead of hallucinating
- High-risk actions have human approval gates
- You know when to use simple patterns instead of complex ones
- You evaluate systematically with RAGAS, not vibes
- You implement reranking to cut context pollution
- Your agents have memory to avoid repeating mistakes
The companies that succeed with agentic RAG don’t build the most sophisticated systems. They build systems that handle failure gracefully, cost predictably, and solve real problems.
Start simple. Add intelligence only where data proves you need it. Measure everything. Design for failure.
That’s how you join the minority that actually ships.
References:
- Asai et al. (2023). “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection” [Source]
- Edge et al. (2024). “From Local to Global: A Graph RAG Approach to Query-Focused Summarisation” (Microsoft Research) [Source]
- McKinsey & Company (2023). “The State of AI in 2023: Generative AI’s Breakout Year”[Source]
- Adaline Labs (2024). “Production Patterns for Agentic RAG Systems”[Source]
- Beam.ai (2025). “Agentic AI in 2025: Why 90% of Implementations Fail (And How to Be the 10%).”[source]
- Microsoft Research. “GraphRAG: A Modular Graph-Based Retrieval-Augmented Generation System.” GitHub Repository.[source]
Why 90% of Agentic RAG Projects Fail (And How to Build One That Actually Works in Production) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.