
What Are LLM Parameters? A Simple Explanation of Weights, Biases, and Scale
No complicated words. Just real talk about how this stuff works.
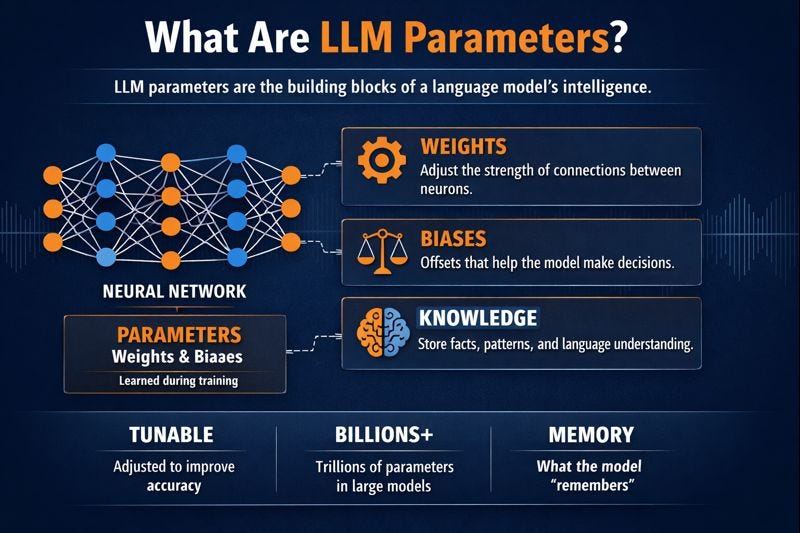
Large Language Models (LLMs) like GPT, LLaMA, and Mistral contain billions of parameters, primarily weights and biases, that define how the model understands language.
Everyone talks about “GPT-4 has 1.76 trillion parameters” like it’s supposed to mean something. But most people just smile and pretend they understand.
Let’s actually explain what this means. No confusing tech words. No showing off. Just clear answers.
What Exactly Is a Parameter?
A parameter is just a number. That’s all it is.
Think about baking cookies. The recipe says “2 cups of flour” and “1 cup of sugar.” Those numbers (2 and 1) control how the cookies turn out. Change those numbers and you get different cookies.
Parameters work exactly the same way. They’re numbers that control how the AI behaves. But instead of having 5 numbers in a recipe, an AI model has billions of them.
These numbers are usually decimals like 0.543 or -0.891. They sit inside the model in huge lists. When someone types a question, these numbers get used in calculations to figure out the answer.
The model takes your words, turns them into numbers, does a ton of math with all these parameters, and turns the result back into words. That’s your answer.
Every single parameter plays a tiny role in that process. Change one parameter and the answer might change slightly. Change a million parameters and the answer changes completely.
What Do These Numbers Actually Mean?
Each parameter value determines part of how the model thinks.
Imagine tuning a guitar. Each string needs to be set to exactly the right tightness. Too loose and it sounds wrong. Too tight and it sounds wrong. Get all six strings just right and it sounds beautiful.
Parameters are like that, except there are billions of “strings” instead of six. Each one needs to be set to exactly the right value for the model to work properly.
When parameter number 5,482 is set to 0.732, it helps the model recognize certain patterns in language. Change it to 0.941 and those patterns look different. Get all billions of parameters set correctly and the model can write essays, answer questions, and have conversations.
Nobody knows exactly what each individual parameter does. It’s all working together in complex ways. But we know that the right combination of all these numbers makes the model smart.
How Does Training Set These Numbers?
This part is actually pretty amazing.
At the start of training, all the parameters are random numbers. The model is basically useless. It gives garbage answers to everything.
Then training begins. The model sees examples of text and tries to learn patterns.
Here’s how it works:
The model sees: “The cat sat on the”
It tries to guess the next word: “banana”
The training system says: “Wrong. The answer is ‘mat’”
Now here’s the magic: Every single parameter in the entire model gets adjusted. Just a tiny amount. Maybe parameter 1 goes from 0.5430 to 0.5431. That’s a tiny change.
Then it tries again: “The dog ran through the”
Model guesses: “window”
Training system: “Wrong. Answer is ‘park’”
Again, every parameter adjusts slightly.
This happens trillions of times. Guess, check, adjust. Guess, check, adjust. Over and over and over.
After weeks of this with massive computers, those parameters have learned patterns of language. They’re no longer random. They’re tuned to recognize how words fit together, what questions mean, and how to respond.
Nobody manually sets parameter number 8,291,047 to 0.6234. The training process figures out the right value through repetition. Show enough examples and the model learns on its own.
It’s like learning to ride a bike. At first, everything is wobbly and wrong. But after falling down a hundred times, your body figures out the balance. Training does that but with billions of numbers instead of your body.
How Size Relates to Parameter Count
More parameters means bigger model. Simple as that.
Think about different phones:
- Basic phone: 32 GB storage, holds some apps and photos
- Medium phone: 128 GB storage, holds lots more
- Big phone: 512 GB storage, holds everything
AI models work the same way:
7 billion parameters needs about 14 GB of space. A decent computer can handle this. It fits on a regular hard drive. Responses come back fast.
70 billion parameters needs about 140 GB of space. Now you need serious computer equipment. Most regular computers can’t handle this. Responses take longer.
700 billion parameters needs about 1,400 GB of space. That’s massive. Only big companies with server rooms can run this. Very slow responses.
The name tells you the size. When you see “Llama 3 70B,” that means 70 billion parameters. When you see “Mistral 7B,” that’s 7 billion parameters.
Bigger number means bigger file size means more powerful computer needed means slower responses means more expensive to run.
This is why ChatGPT runs in the cloud instead of on your phone. The model is too big to fit on a phone. Even if it did fit, your phone battery would die in about 3 minutes trying to run it.
What Is Quantization? The Clever Compression Trick
Here’s where things get really practical and interesting.
Remember how a 70 billion parameter model needs 140 GB of space? That’s because each parameter normally takes up 2 bytes of storage. This is called “16-bit” or “fp16” format.
But here’s a clever trick: what if we could squeeze those numbers down to take less space?
That’s exactly what quantization does. It’s like compressing a photo. A high-quality photo might be 10 MB. Compress it and it becomes 2 MB. It loses a tiny bit of quality, but most people can’t tell the difference.
Quantization does the same thing to model parameters.
Normal parameters (16-bit): Very precise numbers like 0.54729184 Quantized parameters (8-bit): Less precise numbers like 0.547 Super quantized (4-bit): Even less precise like 0.5
The numbers are rounded and simplified. They take up way less space.
Here’s the real impact:
70 billion parameter model:
- Normal (16-bit): 140 GB
- Quantized (8-bit): 70 GB
- Super quantized (4-bit): 35 GB
That’s a huge difference! A model that needed 140 GB now only needs 35 GB. Suddenly it fits on a regular computer.
Does This Hurt Quality?
A little bit, but usually not much.
Think about it like measuring ingredients:
- Super precise: 2.847 cups of flour
- Normal: 2.8 cups of flour
- Rounded: 3 cups of flour
For most baking, all three work fine. The cookies taste basically the same.
Same with model parameters. The super precise version (0.54729184) and the rounded version (0.547) usually produce almost identical results.
Most people can’t tell the difference between a 16-bit model and an 8-bit quantized version. The 4-bit version is where you might start noticing small quality drops, but it’s still surprisingly good.
Why This Matters for Regular People
Quantization is the reason normal people can actually run AI models on their computers now.
Without quantization:
- Need expensive server equipment
- Need 200+ GB of storage
- Need special cooling systems
- Responses take forever
With quantization:
- Run on a gaming PC or even a MacBook
- Need 20–40 GB of storage (totally doable)
- Regular computer handles it fine
- Much faster responses
This is why you see model names like:
- “Llama 3 70B Q8” — the Q8 means 8-bit quantization
- “Mistral 7B Q4” — the Q4 means 4-bit quantization
The quantized versions are what most people actually use. The full-precision versions are mainly for researchers or companies that need absolute maximum quality.
The Trade-offs
8-bit quantization (Q8):
- Half the size
- Almost no quality loss
- Still pretty big files
- Most people use this as the minimum
4-bit quantization (Q4):
- Quarter of the original size
- Small quality loss (maybe 2–5%)
- Much more practical for regular computers
- Very popular choice
3-bit and 2-bit:
- Even smaller
- Noticeable quality drops
- Only use if really desperate for space
- Not recommended for most uses
Think of it like video quality on streaming services:
- 4K = Full precision model (huge file, perfect quality)
- 1080p = 8-bit quantized (good size, excellent quality)
- 720p = 4-bit quantized (smaller, still good quality)
- 480p = 2-bit quantized (tiny but noticeably worse)
Most people watch in 1080p because it’s the sweet spot. Same with models — most people use 8-bit or 4-bit because it’s the sweet spot.
Real World Example
Someone wants to run Llama 3 70B on their computer.
Option 1: Original model
- Size: 140 GB
- Needs: Server with multiple GPUs
- Cost: Thousands of dollars in equipment
- Speed: 2–3 seconds per response
Option 2: 8-bit quantized
- Size: 70 GB
- Needs: Good gaming PC with 80+ GB RAM
- Cost: Around $2,000–3,000 in equipment
- Speed: 1–2 seconds per response
- Quality: 99% as good
Option 3: 4-bit quantized
- Size: 35 GB
- Needs: Decent computer with 48 GB RAM
- Cost: Around $1,000–1,500 in equipment
- Speed: Under 1 second per response
- Quality: 95% as good
For most people, option 3 is perfect. They get 95% of the quality at a fraction of the cost and it runs faster too.
How Quantization Actually Works
The technical details don’t matter much, but here’s the basic idea:
Normal parameters can be any decimal number. Like measuring water with a beaker that has tiny markings for every milliliter.
Quantization says “we don’t need that much precision.” It’s like using a measuring cup that only has markings for every quarter cup. Less precise, but for most cooking, it’s totally fine.
The math behind it finds which rounded numbers best represent the original precise numbers. It tries to keep the overall meaning while using simpler numbers.
When the model runs, it uses these simpler numbers. The calculations are faster because simpler numbers are easier to work with. The results are almost the same.
When NOT to Quantize
There are times when the full precision matters:
Research work: Scientists studying how models work need the exact original version.
Building new models: When using one model to train another, precision matters more.
Extremely critical applications: Medical diagnosis or financial trading where tiny differences matter.
Maximum quality needed: When cost and speed don’t matter, only getting the absolute best answer.
For everyone else? Quantization is basically free performance. Smaller files, faster speed, almost no downside.
The Future of Quantization
People keep getting better at this. New quantization methods come out that maintain even better quality at smaller sizes.
Some recent models are even trained with quantization in mind. They’re designed to work great even when compressed. It’s like designing a photo to look good even when compressed to a smaller size.
There’s also “dynamic quantization” where the model uses high precision for important calculations and low precision for less important ones. Like using a precise measuring cup for baking but a rough estimate for adding salt to pasta water.
The bottom line: quantization is why regular people can now run powerful AI models on regular computers. It’s one of the most important practical advances in making AI accessible.
Do Big Models Always Work Better?
Not really. Usually yes, but not always.
More parameters gives the model more room to learn things. It’s like the difference between a 10-page notebook and a 1,000-page encyclopedia. The encyclopedia can hold way more information.
But here’s the catch: bigger doesn’t guarantee smarter.
Example one: What it learned from
Take two models. Model A has 7 billion parameters and learned from medical textbooks. Model B has 70 billion parameters and learned from random internet comments.
Ask both: “What causes headaches?”
Model A gives proper medical information because it learned from doctors.
Model B might tell you it’s because of bad vibes or something equally useless because it learned from internet randoms.
The smaller model wins because it learned from better information. Size doesn’t matter if the training data is garbage.
Example two: Focus matters
Model A has 13 billion parameters and only learned to write computer code.
Model B has 175 billion parameters and learned about everything — code, cooking, history, science, celebrity gossip, sports statistics.
Ask both to write a program.
Model A probably does it better because all its capacity is focused on one thing. Every parameter knows about coding.
Model B spreads its attention across everything. It knows coding but also knows a million other things, so it’s not as focused.
Example three: Speed counts
Small model answers in half a second. Big model answers in 5 seconds.
For a chatbot answering basic questions, people will prefer the fast one. Nobody wants to stare at a loading screen for 5 seconds to hear “It’s sunny today.”
The big model might give slightly better answers, but users don’t care. They just want answers quickly.
When big actually wins:
Large models ARE better for:
- Really complex problems that need deep thinking
- Understanding subtle differences in meaning
- Handling unusual topics or rare languages
- Working with very little information
But for regular everyday stuff? A well-trained small model often beats a poorly-trained large model.
Why Big Models Cost So Much to Train
Training a massive model is extremely expensive. Here’s why:
Computers needed: Training requires special processors called GPUs. These are expensive. One good GPU costs as much as a car. Training a small model might use 8 GPUs for a few days. Training a huge model might use 10,000 GPUs for months. That’s thousands of expensive computers running non-stop.
Electricity bills: These GPUs use tons of electricity. One GPU uses as much power as running your air conditioner all day. Now multiply that by thousands of GPUs. The electricity bill for training one large model could power a small town for a month.
Time multiplies cost: Training doesn’t take hours. It takes weeks or months. The computers run day and night without stopping. Every day costs money. Every week costs more money. Months of this? The costs explode.
Things go wrong: Training doesn’t always work the first time. Maybe the model doesn’t learn properly. Start over. Try different settings. Maybe you try 10 times before it works. That means paying 10 times the cost.
Smart people needed: Training needs constant watching by experts who understand this stuff. These people don’t work cheap. They need to monitor everything, fix problems, adjust settings. A whole team might work on one model for months.
Storage costs: The model creates enormous amounts of data during training. Every few hours, it saves its progress. Each save is huge. Storing all that data costs money. Moving it around between computers costs money.
The numbers explode: Here’s the really crazy part — doubling the model size doesn’t double the cost. It might triple or quadruple the cost. Going from 7 billion parameters to 70 billion parameters (10 times bigger) might cost 30 times more, not 10 times more. The math doesn’t scale nicely.
Think about it like building houses:
- Building a small house: A few workers for a few months. Manageable.
- Building a mansion: Tons of workers, special equipment, much longer time. Expensive but doable.
- Building a skyscraper: Hundreds of workers, cranes, years of work, constant inspections. Only big companies can afford this.
Training models is the same. Small models? Sure, a startup can do it. Massive models? Only companies with deep pockets can afford it.
This is why when Google or Meta releases a model for free, it’s actually a huge deal. They spent tens of millions creating it, and they’re giving it away. That’s rare and valuable.
Other Important Things to Know
Not all parameters do equal work: Some parameters are like managers — they organize things. Some are like workers — they do the heavy calculations. Some are like helpers — they just move information around. A 70 billion parameter model might have 60 billion doing real work and 10 billion doing support tasks.
Smart tricks exist: Some models cheat in clever ways. Instead of one huge 70 billion parameter model, they build several small 7 billion parameter models. When a question comes in, the system picks which small models to use. You get the knowledge of a big model with the speed of a small model. It’s like having 8 doctors on call but only consulting 2 of them per patient. Way more efficient.
Adjusting existing models is cheaper: Say a hospital wants an AI that understands medical stuff. They don’t train a model from scratch. That would cost millions. Instead, they take an existing 7 billion parameter model that already knows language and teach it medical knowledge. This costs maybe a few thousand dollars instead of millions. The parameters don’t start from random — they start from already being pretty smart.
Nobody understands it fully: Here’s something weird. Scientists can’t look at parameter number 45,729,483 and say “this one handles French grammar.” The knowledge isn’t stored that neatly. It’s spread across millions of parameters in patterns nobody fully understands. The models work, they work really well, but explaining exactly why they work is hard. It’s like knowing your car runs but not understanding every detail of the engine.
Different models for different jobs: Just like you use different tools for different jobs (hammer for nails, saw for wood, screwdriver for screws), different models work better for different tasks. A 7 billion parameter model is perfect for a chatbot. A 70 billion parameter model is better for complex research questions. A 700 billion parameter model is for when you absolutely need the smartest answer possible and don’t care about cost or speed.
The names matter: When you see model names like “Llama 3 70B” or “Mistral 7B,” that number tells you what you’re getting. It’s like shirt sizes — small, medium, large. The number is the AI version of that. Bigger number means more capable but also more expensive and slower.
Quality of learning matters most: You can have the biggest model in the world, but if it learned from junk, it gives junky answers. It’s like having a huge library full of books written by people who don’t know what they’re talking about. The library is big but useless. A small library with good books is way better. Same with AI models.
What This All Means
Parameters are the numbers inside AI models that control how they behave. These numbers get set during training by showing the model tons of examples until it learns patterns.
More parameters usually means more capability. But it also means needing bigger computers, more time, more money, and getting slower responses.
Quantization makes these models practical for regular people by compressing them down to smaller sizes with almost no quality loss. This is why someone can now run a powerful AI on their gaming PC instead of needing a server farm.
The biggest models aren’t always the best choice. Sometimes a smaller, focused model is better. It depends on what someone needs the model to do.
When people brag about having billions or trillions of parameters, they’re really saying “we spent a lot of money building something big.” Whether that big thing is useful depends on how well it was trained and what it’s being used for.
Don’t get scared by huge numbers. A 7 billion parameter model is actually pretty capable for most normal tasks. The 70 billion parameter models are for harder stuff. The trillion parameter models are for the really complex problems.
Think of it like cars. A regular car gets most people where they need to go. A sports car is nice but not necessary for daily driving. A semi-truck is only needed for specific jobs. All three are vehicles, but which one makes sense depends on what someone needs.
Same with AI models. Pick the right size for the job. Bigger isn’t always better — it’s just bigger.
The Real Truth
Here’s the honest bottom line: parameters are just settings that the model learned. Lots and lots of settings. More settings give more room to be smart, but only if those settings got trained properly.
The number of parameters tells you roughly how big and powerful a model is. But it doesn’t tell you if the model is actually good at anything useful. That depends on what it learned during training.
Small models trained well beat big models trained poorly every time. Focus and quality beat size and quantity.
Quantization changed everything by making powerful models accessible to regular people. A 70 billion parameter model that used to need a server room now runs on a decent laptop thanks to compression.
And that’s really all there is to it. Parameters are just numbers that got tuned to make AI models work. Quantization makes those numbers smaller so normal computers can handle them. Understanding these basic ideas is all anyone needs to know.
Final thought: Next time someone mentions parameters, just remember they’re talking about how many adjustable settings the model has. More settings mean more potential, but potential only matters if it’s used well. And thanks to quantization, those massive models are now small enough for regular people to actually use. That’s the real breakthrough.
What Are LLM Parameters? A Simple Explanation of Weights, Biases, and Scale was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.