
VL-JEPA: What Happens When AI Learns to Think Before It Speaks
Understanding VL-JEPA and its approach to embedding-based vision–language modeling

Modern vision language models can describe images, answer questions, and interpret videos with impressive fluency. Yet they all share an unusual habit: they talk constantly.
Even when nothing meaningful has changed. Even when the model already understands what is happening. This is not a stylistic flaw it is a structural one.
Most vision–language models (VLMs) are built on the same foundation as large language models: token-by-token generation. They must express understanding through language, even when language is unnecessary.
VL-JEPA starts from a radically different question:
What if a model could understand the world continuously and speak only when it actually mattered?
That single shift quietly challenges the foundations of today’s vision–language systems.
The Hidden Cost of Token-Centric Thinking
Most VLMs follow a simple pipeline:
Image or video + question → generate text → one token at a time
This feels natural because humans communicate in words. But thinking in words is not the same as thinking in meaning.
Consider a simple question:
What is the person in this video doing?
Two valid answers might be:
- “He is pouring water into a glass.”
- “He is filling the glass with water.”
Same action. Same understanding. Completely different token sequences. From a token-based model’s perspective, these answers are almost unrelated. During training, the model must learn:
- the underlying action
- the exact phrasing
- paraphrases and word order
- stylistic variation
A large portion of model capacity is spent modeling how things are said, not what is actually happening.
Because decoding is autoregressive:
- Meaning is revealed slowly
- The model must finish generating text before semantics are clear
- Real-time perception becomes inefficient by design
This limitation becomes critical for:
- streaming video understanding
- robotics and embodied agents
- always-on perception systems
VL-JEPA’s Core Insight: Predict Meaning, Not Words
VL-JEPA takes a fundamentally different path. Instead of predicting text tokens, it predicts semantic embeddings, continuous representations of meaning. In other words:
VL-JEPA predicts what the answer means, not how it should be worded.

Text is generated only when needed. This idea comes from Join Embedding Predictive Architectures (JEPA), a research direction championed for years by Yann LeCun. VL-JEPA is not just a new model it is a concrete implementation of this philosophy.
Why This Idea Comes From Yann LeCun (And Why That Matters)
Yann LeCun is not just another researcher commenting on language models.
He is one of the founders of modern deep learning: the inventor of convolutional neural networks, the Turing Award winner, and the Chief AI Scientist at Meta. For decades, his work has focused on how machines can learn representations of the world not just manipulate symbols.For years, LeCun has argued that autoregressive language models are not a true model of intelligence.
For years, Yann LeCun has argued that autoregressive language models are not a true model of intelligence.
His critique is consistent:
- Intelligence is not next-token prediction
- The world is continuous, not discrete
- Meaning exists before language
In talks and interviews, LeCun has emphasized that
Predicting representations is a more natural learning objective than predicting symbols.
Thinking Before Speaking: A More Human Model of Intelligence
Humans do not think in sentences.
Imagine watching someone pour water into a glass. You instantly understand the action. You do not internally narrate: “He is pouring water into a glass.” The understanding comes first. Words come later if they are needed at all.
We think in:
- Intentions
- Actions
- Expectations
- Internal world models
Language is something we apply after understanding.
VL-JEPA mirrors this process:
- Thinking: predicting latent semantic representations
- Speaking: optional decoding into text
The model reasons continuously in latent space and translates those thoughts into words only when required.
How VL-JEPA Works
VL-JEPA consists of four main components:
1. Visual Encoder (X-Encoder)
Compresses images or video frames into visual embeddings.
2. Text Encoder (Y-Encoder)
Encodes target answers into a semantic embedding space that captures meaning rather than phrasing.
3. Predictor (The Core)
Given:
- visual embeddings
- a textual query
The predictor directly outputs the answer embedding.
- No autoregressive decoding.
- No token loop.
- Just semantic prediction.
4. Text Decoder (Optional)
Used only at inference time when human-readable text is required. Crucially, this decoder is not involved in the main training loop, making learning significantly more efficient.
A Concrete Comparison: Tokens vs Meaning
Let’s take a different example one that makes the limitation of token-based models even clearer. Imagine a video showing a pedestrian approaching a road, pausing, and then crossing once the traffic stops.
A token-based model now has to choose a specific sentence:x
“The person is crossing the street”
“A pedestrian waits and then walks across the road”
“Someone safely crosses after traffic stops”
All are correct. All describe the same situation. Yet, for a token-based model, these are very different outputs with little overlap at the sequence level.
VL-JEPA approaches this differently.
Instead of selecting a sentence, it predicts a single semantic embedding that represents the situation of a pedestrian safely transitioning from one side of a road to the other after waiting for traffic. All valid textual descriptions cluster around this same meaning. This turns language from the target of learning into a flexible interface.
A token-based model must learn many surface forms. VL-JEPA learns the underlying event once and can express it in words only if needed. In token-based models, small wording changes can look like big mistakes. The model is penalized not for misunderstanding the action, but for choosing a different phrasing.
In embedding space, nearby meanings remain nearby. Learning becomes smoother, faster, and more stable. Instead of memorizing many surface forms, the model learns a single coherent representation of what is happening. In controlled experiments using the same vision encoder, dataset, and training budget VL-JEPA learned faster and achieved higher performance while using roughly half the trainable parameters of traditional VLMs.
Selective Decoding: Speaking Only When Something Changes
Because VL-JEPA reasons continuously in latent space, it can observe whether meaning itself has changed. Consider a long, uncut video. For several seconds, the same action continues. A traditional model must keep generating captions or answers, even though nothing new is happening.
VL-JEPA does not.
As long as the predicted embedding remains stable, the model stays silent. When a new action begins, the embedding shifts and only then does the model decode text. This behavior is called selective decoding. This is where VL-JEPA truly separates itself. Because it produces a continuous stream of semantic embeddings, the model can:
- track the meaning frame by frame
- detect genuine semantic changes
- decode text only when something new occurs
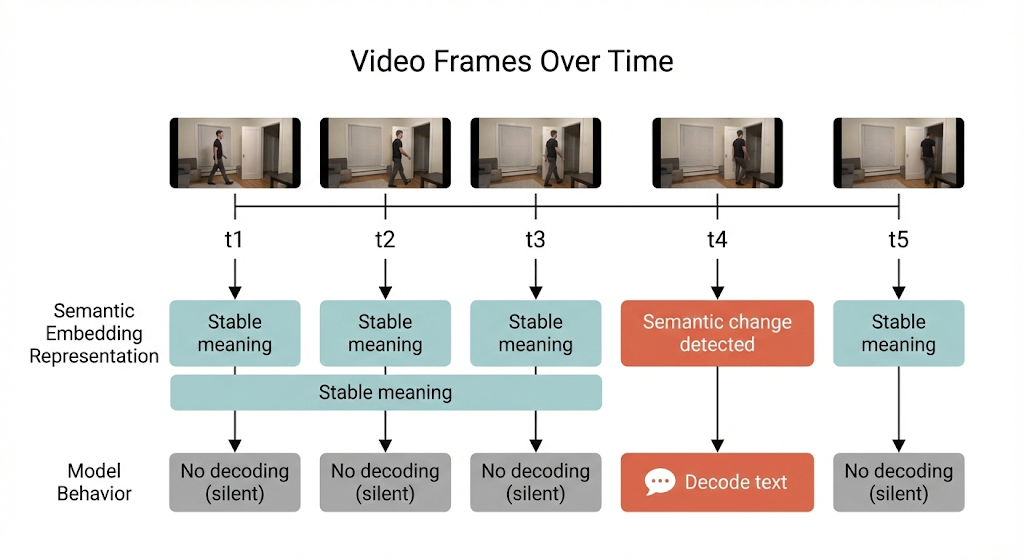
In experiments, selective decoding reduced decoding operations by approximately 2.85× without degrading output quality. Traditional vision language models cannot do this they must generate text every time.
One Unified Model, Many Capabilities
Because everything lives in a shared embedding space, VL-JEPA naturally supports:
- open-vocabulary classification
- text-to-video retrieval
- discriminative VQA
- captioning
- long-horizon video understanding
The same predicted embedding can be:
- decoded into text
- compared against label embeddings
- matched against retrieval queries
This unifies what CLIP-style models and generative VLMs traditionally handle separately.
Does It Actually Work?
Yes, and surprisingly well. With only 1.6B parameters, VL-JEPA:
- outperforms CLIP, SigLIP2, and Perception Encoder on multiple video benchmarks
- matches large generative VLMs like InstructBLIP and Qwen-VL on VQA tasks
- achieves state-of-the-art results on world-modeling benchmark
All while being:
- faster
- lighter
- better suited for real-time and embodied systems
Why VL-JEPA Matters
VL-JEPA represents more than a new architecture. It represents a philosophical shift. As AI systems move toward:
- embodied agents
- continuous perception
- real-time interaction
- world modeling
Token-by-token generation becomes a bottleneck. Latent-space reasoning does not. VL-JEPA aligns closely with Yann LeCun’s vision of AI systems that understand first and speak later.
A Shift in Perspective
VL-JEPA is not trying to replace language models. It is questioning their role. We do not need to speak in order to understand the world. Sometimes, the most intelligent systems are the ones that stay quiet until they have something meaningful to say.
VL-JEPA: What Happens When AI Learns to Think Before It Speaks was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.