
Vectors, Embeddings, and Search: An Intuition-First Guide

Vectors, embeddings, and search
When we talk about AI, search, or LLMs, it often sounds like magic. You type words. Something understands them. It finds meaning, not just keywords. But under the hood, there’s no magic. There are vectors. Lots of them.
Not symbols, not rules, not hidden dictionaries. Just numbers arranged in space.
When I built my previous blog, I used vectors to power article recommendations (surfacing related content based on what you’d just read). I never really went deep on how any of it worked. This article is me fixing that.
No heavy math. Just mental models you can actually feel.
Text isn’t what models read
It’s tempting to imagine models reading raw text, but they don’t. Language is broken down into smaller pieces called tokens.
You might wonder why this step even matters. Bear with me, it’ll make sense in a minute.

At this stage, nothing understands anything. Just segmentation. Slicing and indexing. It’s the bridge between language and math.
From ids to vectors
An integer id isn’t useful on its own. It’s just an index. What matters is what it points to. Each token retrieves a vector from a large learned table, the embedding matrix.
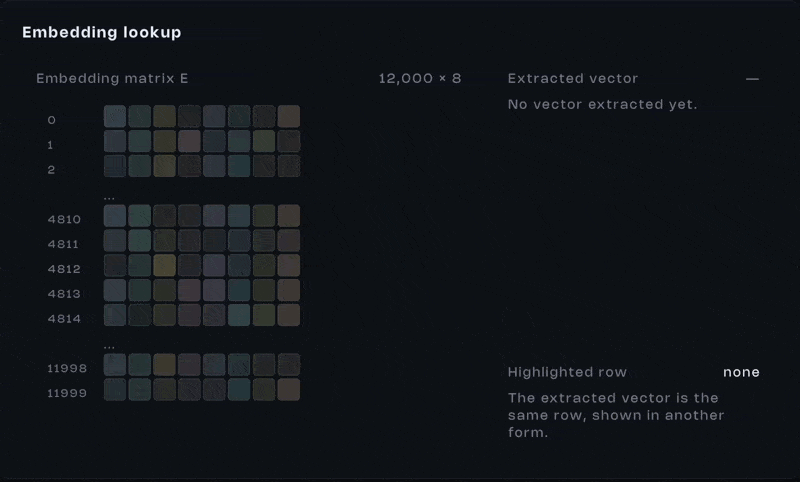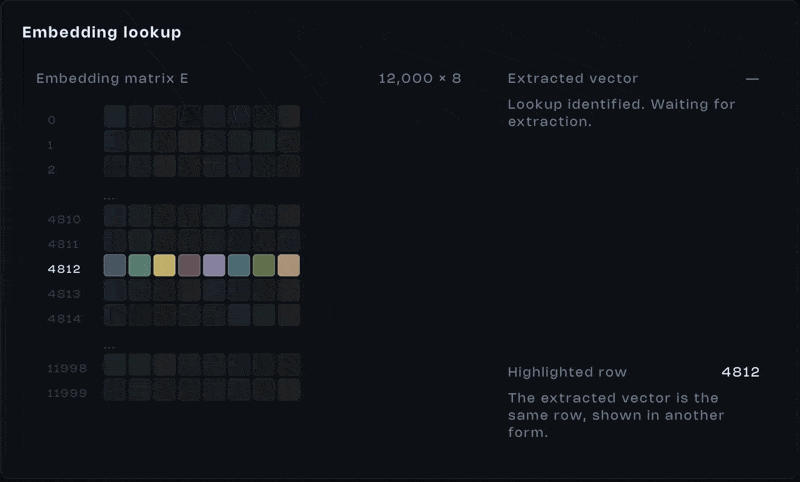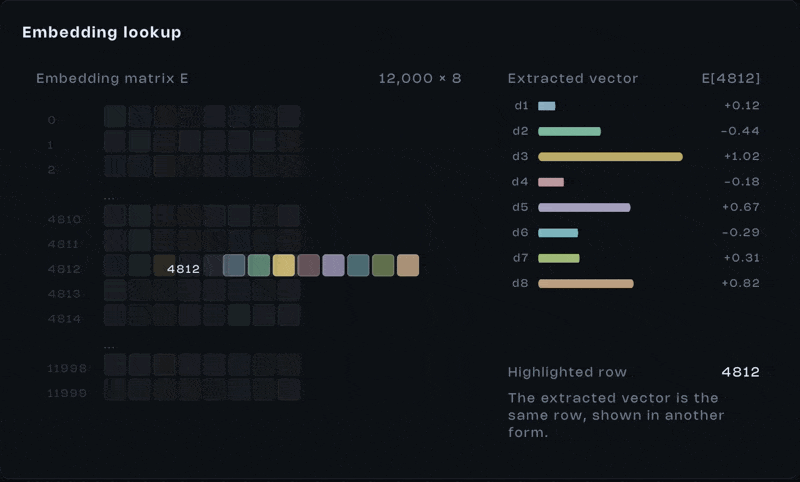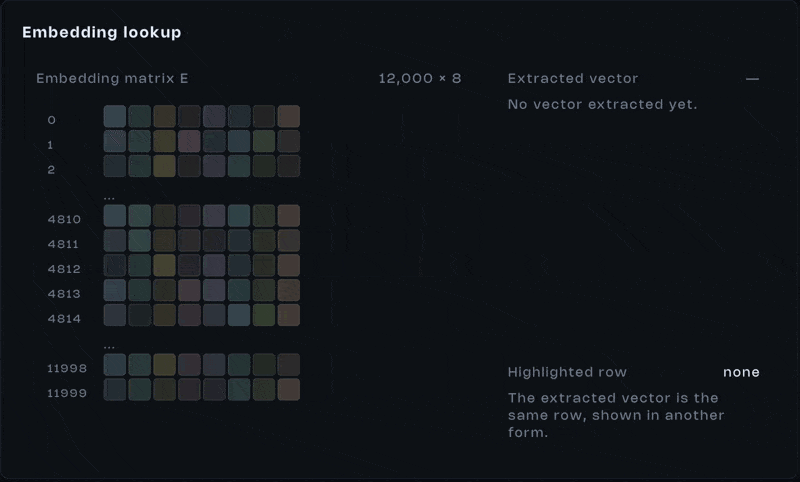
Every row in this matrix contains hundreds or thousands of values. Those values weren’t typed in by a human. They were learned during training, adjusted over billions of examples.
And here’s the important part, this isn’t a neural computation happening in real time. It’s a lookup. When a token appears, we fetch its vector. Token appears, vector comes out. That’s it.
Everything starts as coordinates
Imagine a blank 2D space. An infinite canvas. Every point can be described with two numbers:
(x,y)
That’s a vector. Nothing fancy. Just coordinates.
If you squint a bit, a vector is just a container for numbers. On its own, it means nothing. Meaning only appears when we decide what those numbers represent. In graphics, they might be positions. In physics, forces. In machine learning, concepts. And here’s the part that matters.
The (x,y) version is just the toy model, real embeddings don’t live in two dimensions. If you’re thinking “okay but that’s too simple to be useful“, you’re right. Here’s what real embeddings actually look like:
(x1,x2,x3,…,x1536)
Thousands of coordinates. No human can visualize that space. But the math still works exactly the same: add, compare, measure distance, measure angle.
Everything that follows in this article is just different ways of using those numbers.
Turning meaning into position
Imagine we define two axes. Cold and hot on the x-axis. Sad and happy on the y-axis. Words like ice, fire, party, and funeral suddenly find a natural position in space. Not because we wrote definitions for them but because their coordinates reflect relationships. And suddenly, position means something.
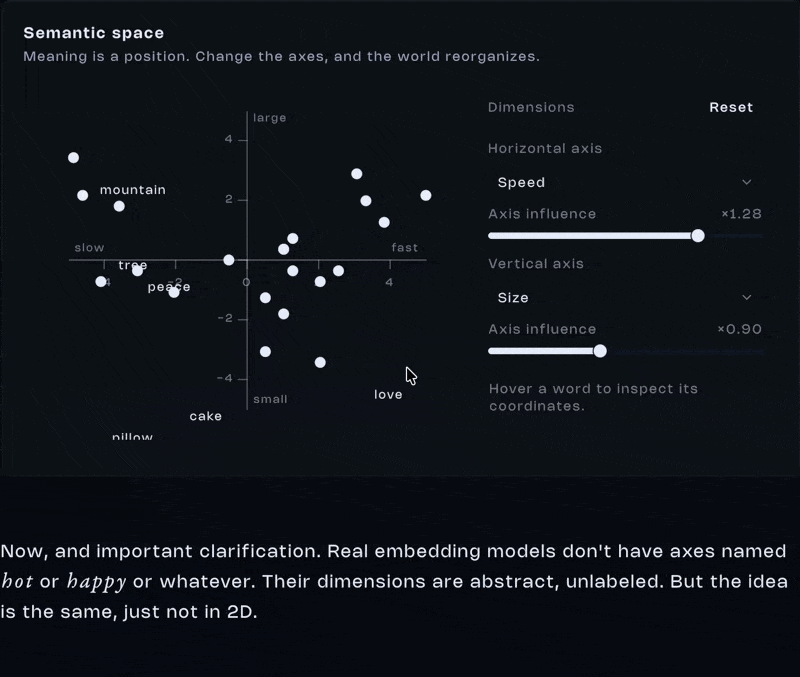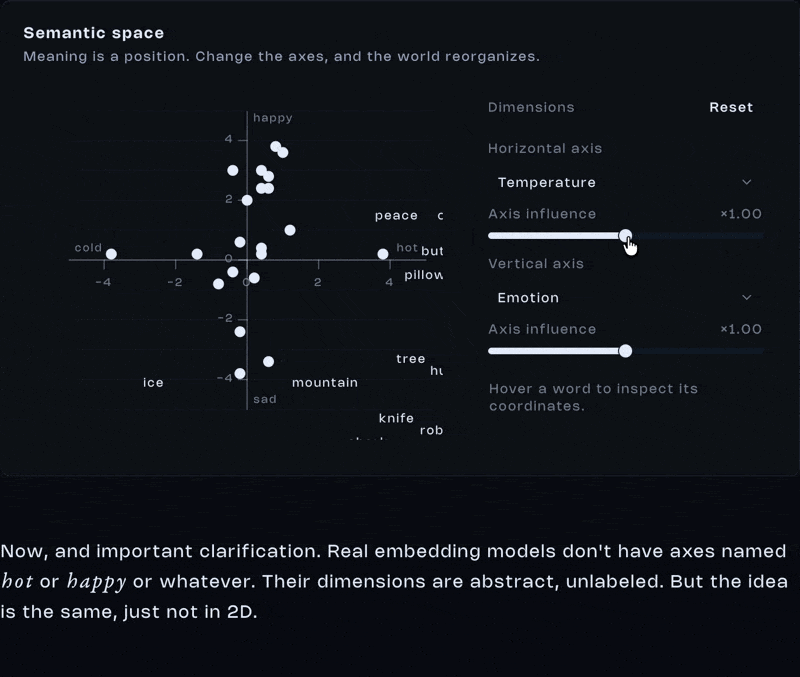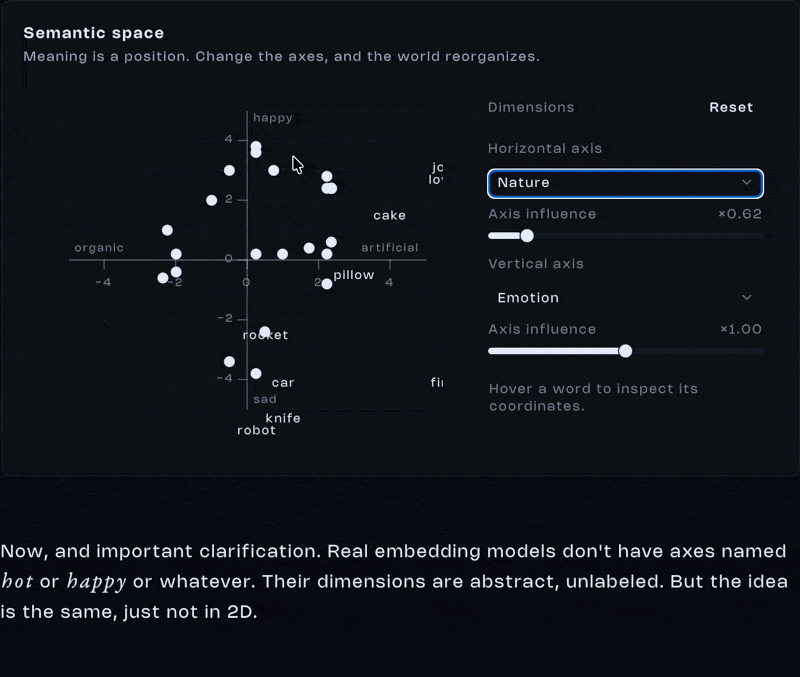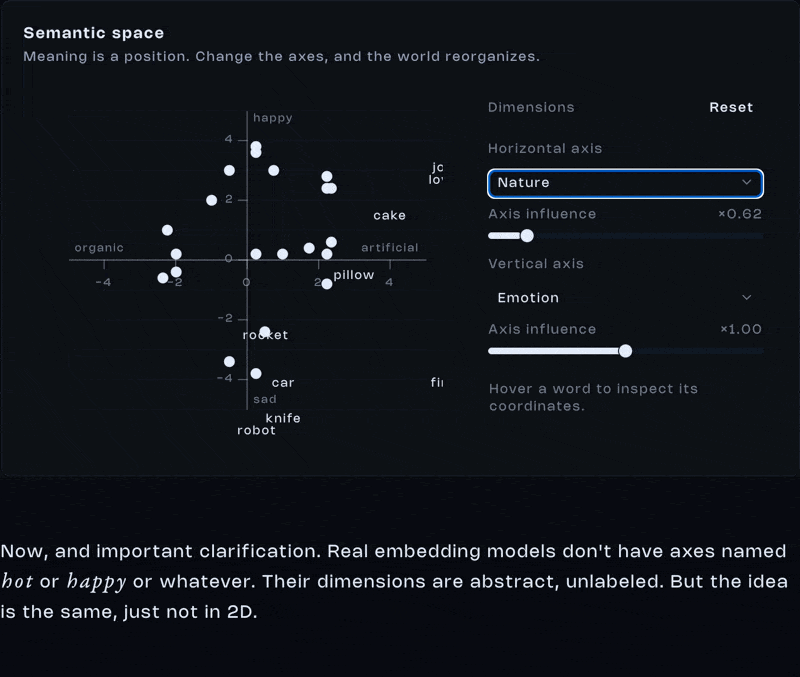
Now, and important clarification. Real embedding models don’t have axes named hot or happy or whatever. Their dimensions are abstract, unlabeled. But the idea is the same, just not in 2D.
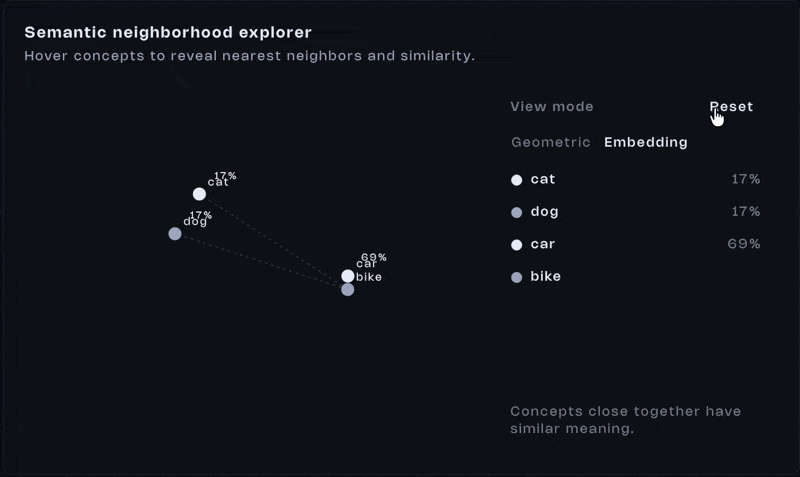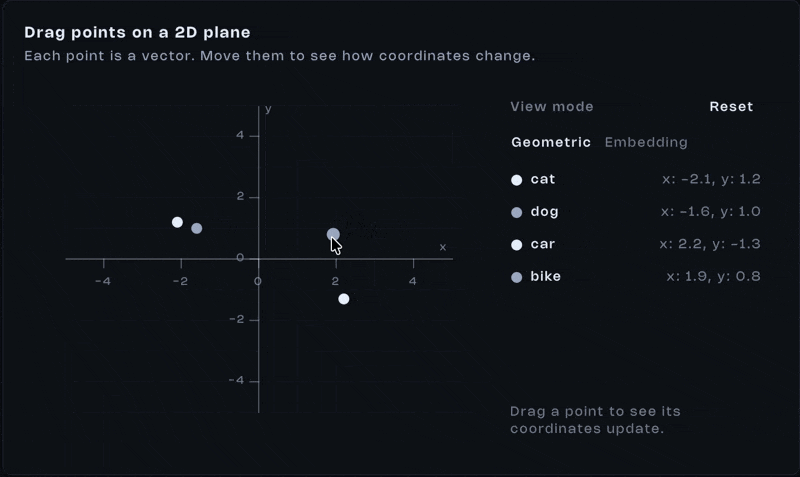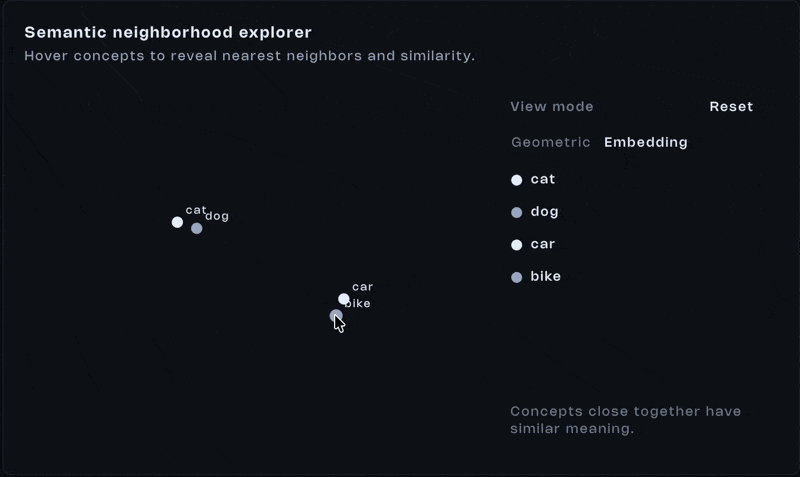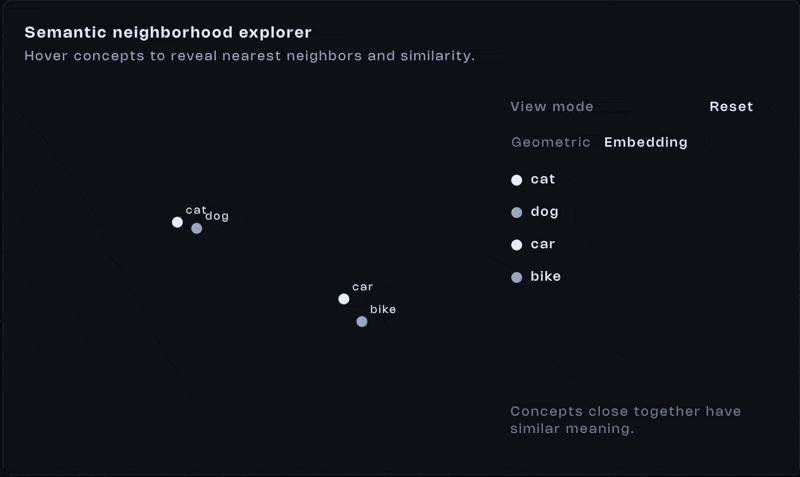
Comparing meaning geometrically
Once everything is represented as vectors, comparison becomes math. One of the most common tools is cosine similarity. It measures the angle between two vectors:

Yeah, that looks like a lot. Don’t stress it. What matters is the outcome. If vectors point in similar directions, the score is high. If they diverge, the score drops. If they’re perpendicular, the similarity is close to zero.
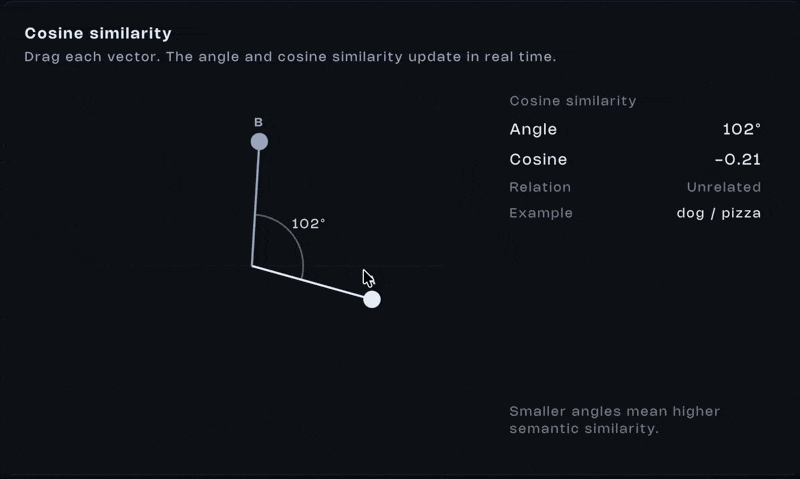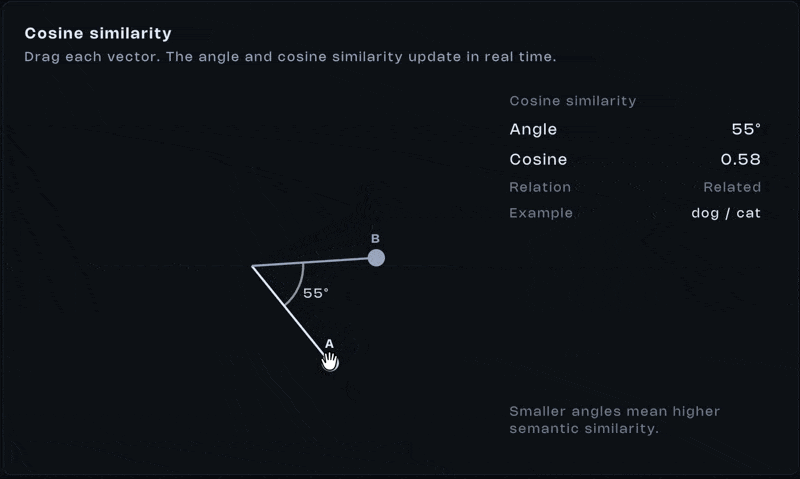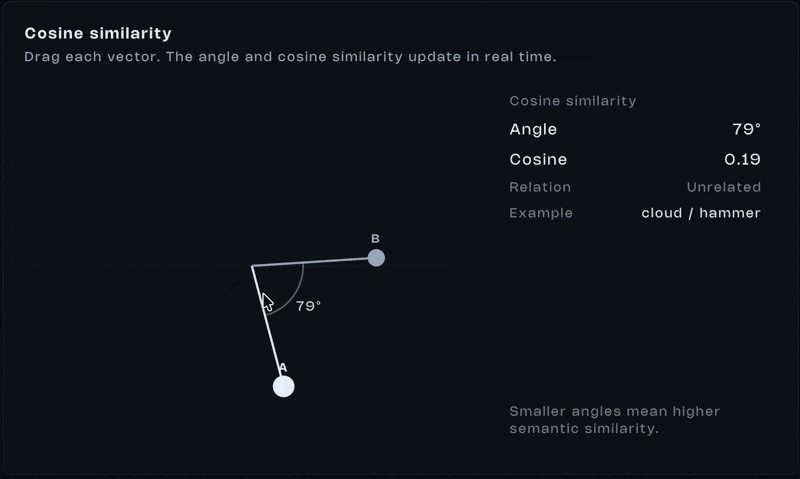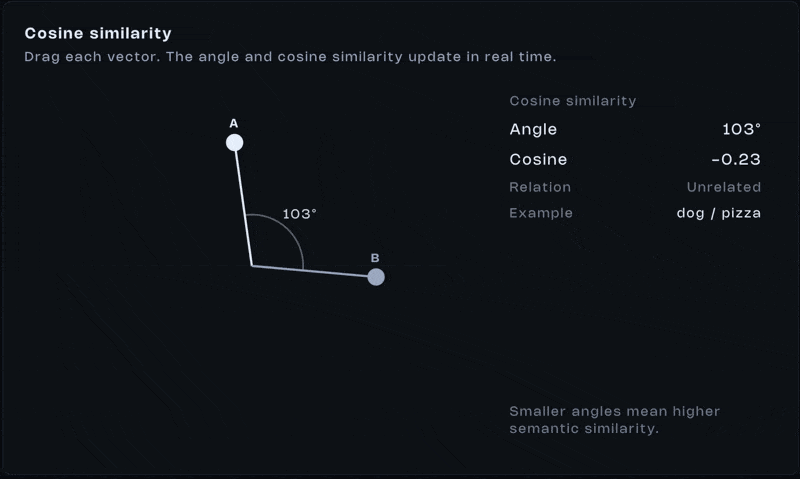
This single operation is behind semantic search, recommendations, RAG. One operation. That’s all it takes. Similarity isn’t stored, it’s computed.
From intuition to real embeddings
As we said, real embeddings aren’t two numbers. They’re more like:
[0.12,−0.93,0.44,…,0.003]
Hundreds. Sometimes thousands. You can’t point at one number and say, “that’s meaning.”. No single dimension tells the story. It’s the combination that matters. A bit like how no single pixel makes an image, but zoom out and suddenly there’s a face.
We don’t label these axes. We don’t interpret them directly. We just use them.
Here’s the important shift. We don’t compare text anymore. We compare distance. Two vectors that are close together represent similar meaning. That’s what semantic search runs on.

Let’s make it concrete. Imagine you have a database full of documents: docs, blog posts, code snippets. Each one has already been converted into a vector and stored.
A user searches: “How to fix slow react app?“. That query gets embedded into a vector too. Now we just compute the distance between that vector and every stored vector.
Closest matches win. No keyword matching. No handcrafted rules. Just geometry. That’s the whole thing, really.
Where transformers enter
Up to this point, we’ve been a bit hand-wavy. We’ve talked about vectors, distances, similarity, as if those vectors simply existed. They don’t. They are produced. You might be asking: “okay, but who produces them?“ That’s exactly the right question. And that’s where transformers enter the picture.
This section was the hardest to write. Transformers involve a lot of moving parts, and most explanations either go too deep or hand-wave everything. I tried to find the middle ground.
From static vectors to contextual ones
When a sentence enters a model, each token starts with a vector from the embedding matrix. At that moment, the vector is static. The word “react” always maps to the same initial coordinates. No context. No nuance. That’s a problem.
Because react in “react app“ doesn’t mean the same thing as react in “How humans react to stress“. Static embeddings can’t capture that difference. Transformers can.
Attention changes that
Transformers introduce attention. Instead of treating tokens independently, each token looks at the others and asks: Which parts of this sentence matter to me right now?
In practice, attention can be fully bidirectional like in encoder models, or strictly causal like in GPT-style decoders. But the intuition is the same either way.
The answer isn’t binary. It’s weighted. Some tokens pull strongly. Others barely matter. You can think of attention as contextual gravity. Words pulling on each other to reshape their positions in space.

Each layer slightly reshapes the representation. Not by adding new information, but by passing context around. After one layer, a token knows a bit about its neighbors.
After several layers, it knows: what role it plays, what it refers to, how it relates to the rest of the sentence.
By the final layer, it’s not “react“ anymore. It’s “react“ in “How to fix slow react app?“
Bringing it all together
We start with text. We end with spatial relationships.

Search, retrieval, generation, it all builds on this. Simple math, quietly powering most of what modern AI does.
Closing thought
Vectors aren’t just a technical detail buried somewhere in the stack. They’re what everything runs on. Once you start seeing language as geometry, a lot of things start making sense. RAG, semantic search, agents, recommendations, it’s all the same idea, just applied differently.
If you’ve used any of these systems without thinking too hard about what’s underneath, hopefully this gave you a clearer picture of what’s actually going on.
Nicolas
PS: You can find this fully animated article with concrete examples on my blog : https://nicolas.nz/blog/vectors-embeddings-and-search
Vectors, Embeddings, and Search: An Intuition-First Guide was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.