 HTTP range requests")
Unicode Explorer using binary search over fetch() HTTP range requests
Unicode Explorer using binary search over fetch() HTTP range requests
Here’s a little prototype I built this morning from my phone as an experiment in HTTP range requests, and a general example of using LLMs to satisfy curiosity.
I’ve been collecting HTTP range tricks for a while now, and I decided it would be fun to build something with them myself that used binary search against a large file to do something useful.
So I brainstormed with Claude. The challenge was coming up with a use case for binary search where the data could be naturally sorted in a way that would benefit from binary search.
One of Claude’s suggestions was looking up information about unicode codepoints, which means searching through many MBs of metadata.
I had Claude write me a spec to feed to Claude Code – visible here – then kicked off an asynchronous research project with Claude Code for web against my simonw/research repo to turn that into working code.
Here’s the resulting report and code. One interesting thing I learned is that Range request tricks aren’t compatible with HTTP compression because they mess with the byte offset calculations. I added 'Accept-Encoding': 'identity' to the fetch() calls but this isn’t actually necessary because Cloudflare and other CDNs automatically skip compression if a content-range header is present.
I deployed the result to my tools.simonwillison.net site, after first tweaking it to query the data via range requests against a CORS-enabled 76.6MB file in an S3 bucket fronted by Cloudflare.
The demo is fun to play with – type in a single character like ø or a hexadecimal codepoint indicator like 1F99C and it will binary search its way through the large file and show you the steps it takes along the way:
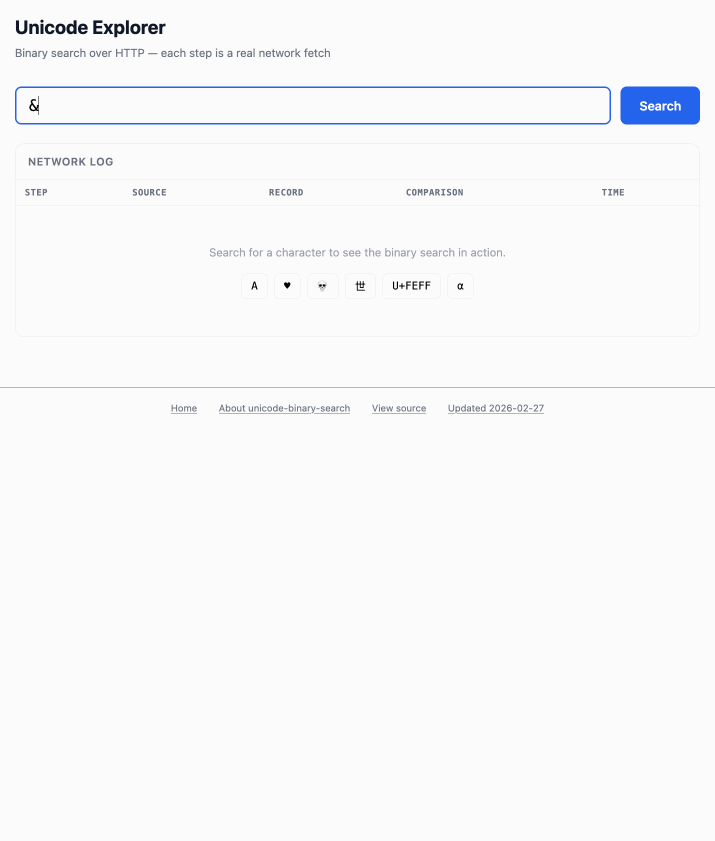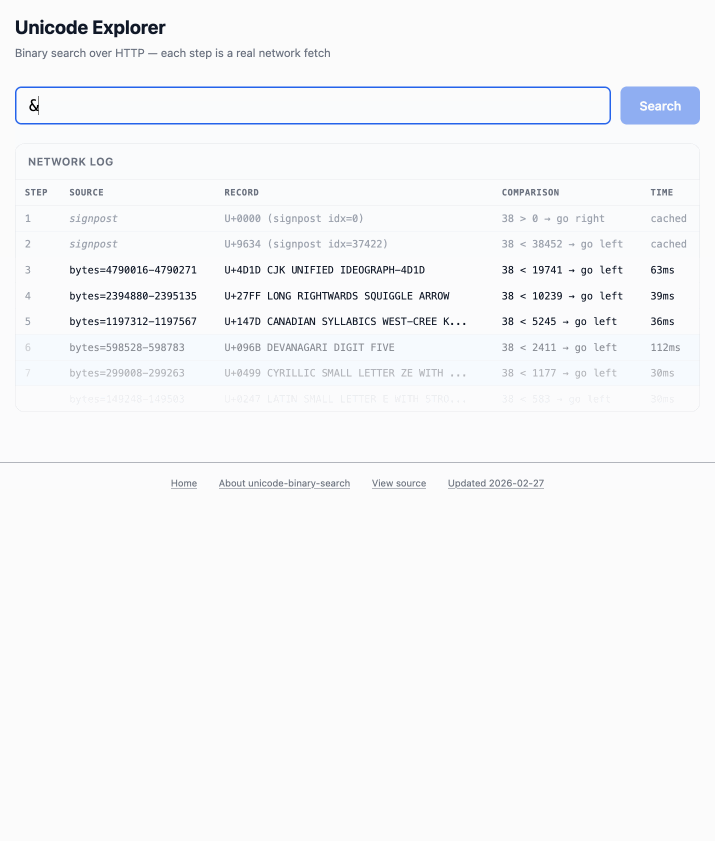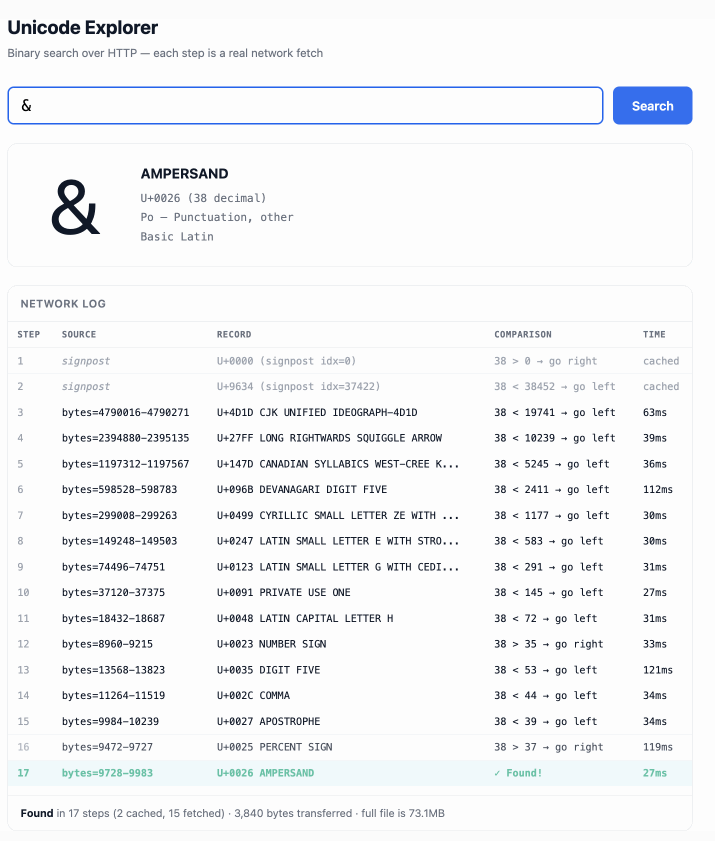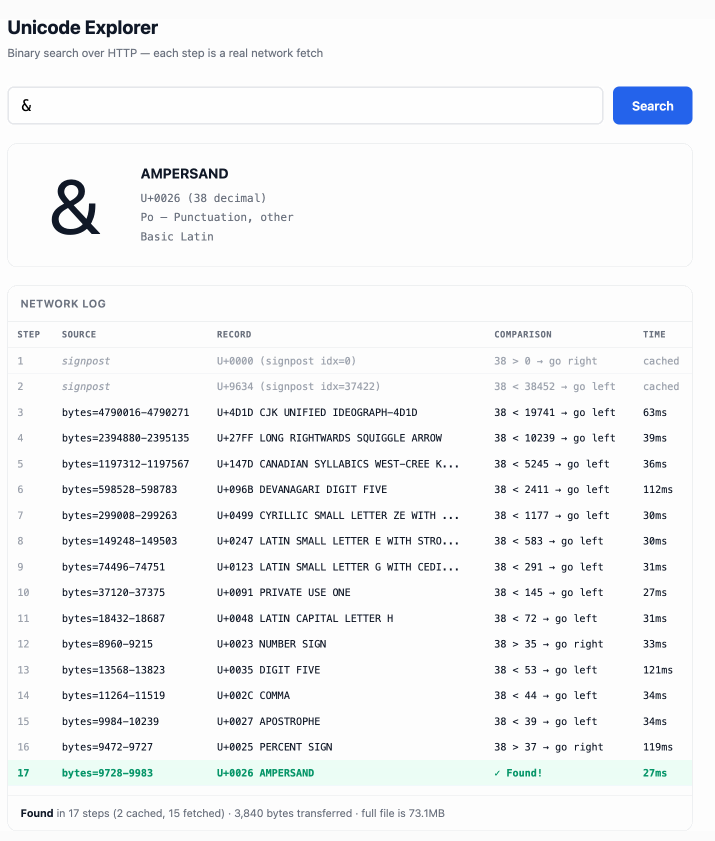
Tags: algorithms, http, research, tools, unicode, ai, generative-ai, llms, ai-assisted-programming, vibe-coding, http-range-requests