
Top AI Agent Frameworks in 2026: A Production-Ready Comparison

We tested 8 AI agent frameworks in production across healthcare, logistics, and fintech. Here’s what actually works — and what breaks when real users show up.
Six months ago, picking an AI agent framework meant choosing between LangGraph, CrewAI, and AutoGen. That was the entire conversation.
Now every major AI lab ships its own agent SDK. OpenAI, Anthropic, and Google all launched agent development kits in 2026. Microsoft rebuilt AutoGen from scratch. LangGraph hit 126,000 GitHub stars. CrewAI raised funding and shipped enterprise features.
The result: 120+ agentic AI tools across 11 categories, and every CTO we talk to asks the same question — which one should we actually build on?
Here’s the problem with most framework comparisons: they benchmark toy examples. They test “build a research assistant” or “summarize these documents.” That tells you nothing about what happens when your agent processes 15,000 support tickets a day, and the third-party API it depends on goes down at 2 am.
After shipping AI agents in production across healthcare, logistics, fintech, and e-commerce — using every major framework on this list — we’ve learned that the right framework choice depends on exactly three things: your failure tolerance, your observability requirements, and your team’s ability to debug what goes wrong.
This article gives you the production-tested comparison nobody else is writing.
Quick-Reference Comparison: AI Agent Frameworks in 2026
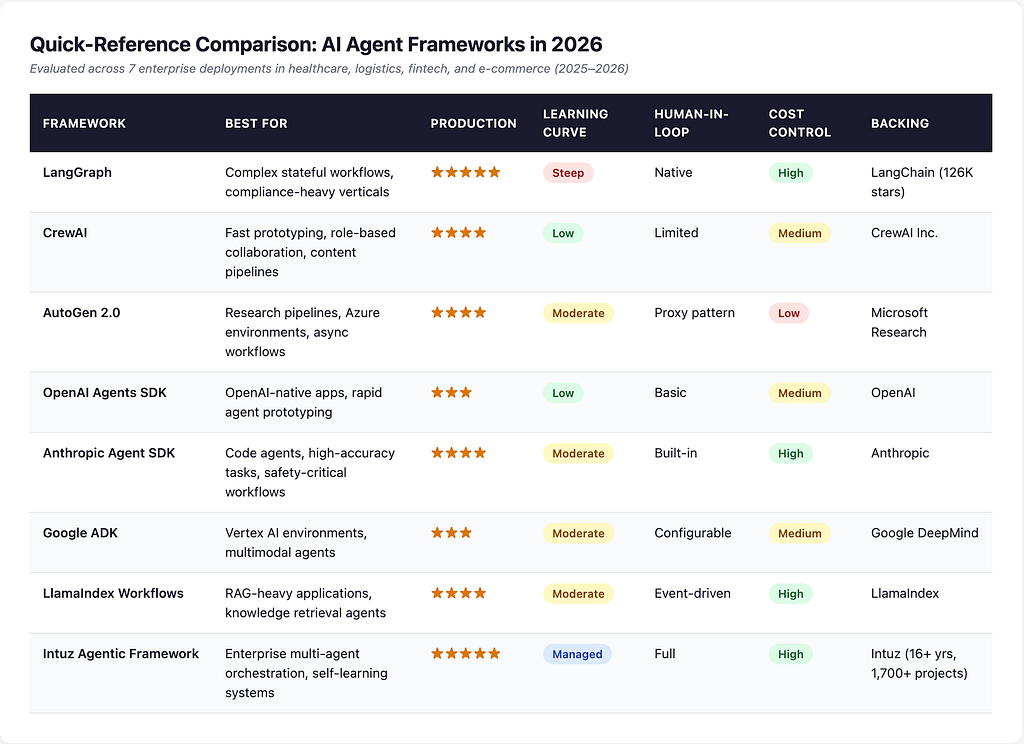
How We Evaluated These Frameworks
Before the deep dives, here’s the methodology. We didn’t rely on documentation claims or GitHub readme benchmarks. Our evaluation criteria come from deploying agents across 7 enterprise clients in 2025–2026:
- Production reliability — Does the agent behave consistently under load? What happens when tools fail, APIs timeout, or context windows overflow? We test failure modes, not happy paths.
- Observability — When something breaks at 2 am, can you trace exactly which step failed, what state it received, and what it returned? If you can’t debug it, you can’t ship it.
- Cost predictability — Can you estimate monthly inference costs before deploying? Frameworks that allow unbounded LLM calls in loops are a CFO’s nightmare. Inference now accounts for 55% of AI cloud spending — $37.5 billion in early 2026.
- Human-in-the-loop capability — Can humans review, approve, or redirect agent decisions mid-workflow? In healthcare, finance, and legal — this isn’t optional.
- Ecosystem longevity — Will this framework exist in 3 years? Who backs it? What’s the release cadence? Enterprise teams can’t afford to rebuild on a dead framework.
- Team adoption speed — How quickly can a mid-level Python developer build a working agent? Framework complexity kills more projects than framework limitations.
The 8 AI Agent Frameworks That Matter in 2026
1. LangGraph — The Production Standard
LangGraph is LangChain’s graph-based agent orchestration layer. Agents are nodes. State flows through edges. Conditional logic determines routing. Nothing is hidden behind a framework abstraction — every routing decision is code you wrote.
Why does it lead in production?
After deploying LangGraph agents for a healthcare client processing insurance prior authorizations, we observed that accuracy increased from 71% to 93% after implementing context isolation at the graph node level. The key advantage was deterministic execution — every state transition was explicit, making compliance audits straightforward.
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated
class AgentState(TypedDict):
query: str
context: list[str]
response: str
requires_human_review: bool
def route_after_analysis(state: AgentState) -> str:
"""Deterministic routing - compliance teams can audit this."""
if state["requires_human_review"]:
return "human_review"
return "generate_response"
workflow = StateGraph(AgentState)
workflow.add_node("analyze", analyze_query)
workflow.add_node("retrieve", retrieve_context)
workflow.add_node("human_review", pause_for_human)
workflow.add_node("generate_response", generate)
workflow.add_conditional_edges("analyze", route_after_analysis)
Strengths:
- Full control over agent flow — deterministic, auditable execution paths
- Native human-in-the-loop: pause graph, collect human input, resume exactly where stopped
- First-class streaming with partial outputs as tokens generates
- LangSmith observability: full trace per graph run, visual debugger
- State persistence across sessions — agents resume interrupted workflows
- 126,000+ GitHub stars, fastest-growing agent framework ecosystem
Weaknesses:
- Steeper learning curve — graph-based mental model takes time for teams new to it
- More boilerplate for simple use cases (overkill for a single-agent chatbot)
- Debugging complex graphs requires tracing skills most teams don’t have day one
Production verdict: LangGraph is the framework we reach for when the agent handles real patient data, financial transactions, or anything where “the agent did something unexpected” has legal consequences. If your use case requires compliance checkpoints, mandatory human review, or full audit trails — LangGraph is the only production-ready choice today.
2. CrewAI — The Fastest Path to a Working Demo
CrewAI’s abstraction is roles. You define agents with names, goals, backstories, and tools. A crew of agents collaborates to complete tasks — passing outputs between roles, delegating when appropriate.
The mental model is a team of specialists working on a project. This clicks immediately with non-technical stakeholders and makes certain use cases extremely fast to prototype.
Where it shines:
We used CrewAI to build a content analysis pipeline for an e-commerce client — a research agent, a competitor analysis agent, and a recommendation agent working as a crew. Time from concept to working demo: 3 days. The role-based abstraction meant the product team could read the agent definitions and suggest changes without touching code.
from crewai import Agent, Task, Crew, Process
researcher = Agent(
role="Market Research Analyst",
goal="Find competitor pricing and positioning data",
backstory="You're a senior analyst who's tracked this market for 10 years.",
tools=[web_search, database_query],
verbose=True
)
analyst = Agent(
role="Pricing Strategist",
goal="Recommend optimal pricing based on market data",
backstory="You've optimized pricing for 50+ e-commerce brands.",
tools=[calculator, reporting_tool]
)
crew = Crew(
agents=[researcher, analyst],
tasks=[research_task, analysis_task],
process=Process.sequential
)
Strengths:
- Fastest time-to-working-demo of any framework on this list
- Role definitions are readable by non-engineers — great for stakeholder buy-in
- Built-in delegation: agents can assign subtasks to other agents
- Sequential and hierarchical process modes
- Growing ecosystem with community-built tools and templates
Weaknesses:
- Less control over the exact execution flow compared to LangGraph
- Debugging “why did agent X delegate to agent Y” is non-trivial at scale
- State management across long-running workflows is more limited
- Hierarchical process mode can produce unpredictable delegation chains
- No institutional backing comparable to LangGraph, AutoGen, or the lab SDKs
Production verdict: CrewAI is the right choice when you need a working demo in under a week, and your use case is content generation, research, or analysis — not high-stakes operational workflows. Be honest about what “working” means before committing to scale it. We’ve deployed CrewAI prototypes that later needed to be rebuilt in LangGraph when production requirements tightened.
3. Microsoft AutoGen 2.0 — The Enterprise Async Engine
AutoGen is Microsoft Research’s multi-agent conversation framework, rebuilt from scratch in version 2.0. The core concept: agents communicate by exchanging messages in a conversation loop until they converge on a result. The 2.0 release introduced async-first architecture, a modular runtime, and addressed many of the original framework’s production limitations.
Where it wins:
For a financial services client running on Azure, AutoGen was the natural choice. Native Azure OpenAI integration meant zero additional infrastructure. We built a code-generation and review pipeline in which a coder agent writes, a reviewer agent critiques, and a human proxy agent makes the final call. The async architecture handled 200+ concurrent review sessions without breaking a sweat.
Strengths:
- Native async — built for high-concurrency multi-agent workflows
- Deep Azure OpenAI and Microsoft ecosystem integration
- Flexible conversation patterns: two-agent, group chat, nested conversations
- Strong code generation + execution workflows (human proxy agent pattern)
- Microsoft Research backing — features from research papers land in AutoGen first
- AutoGen 2.0 modular runtime is a significant production upgrade
Weaknesses:
- Conversation loops can be expensive — agents “debate” to reach conclusions, consuming unpredictable tokens
- Cost unpredictability: open-ended loops without hard termination conditions run hot
- Less native support for stateful, long-running workflows compared to LangGraph
- Azure ecosystem pull — building deep into Microsoft’s stack creates lock-in risk
Production verdict: If you’re a Microsoft shop running on Azure OpenAI, AutoGen 2.0 is worth serious evaluation. The async-first rewrite fixed the biggest production pain points. But always set hard token budgets and termination conditions on conversation loops — we’ve seen AutoGen agents consume 10x expected tokens in open-ended debates. The cost risk is real.
4. OpenAI Agents SDK — The New Entrant
OpenAI launched its Agents SDK in 2026, providing a native framework for building agent workflows on top of GPT models. The SDK abstracts tool use, function calling, and multi-step reasoning into a clean API that feels like a natural extension of the OpenAI ecosystem.
What’s notable:
The SDK is optimized for OpenAI’s models — function calling, structured outputs, and tool use are first-class citizens. If your stack already runs on GPT-4o or GPT-5.4, the Agents SDK removes the translation layer between your application and the model’s native capabilities.
Strengths:
- Tightest integration with OpenAI models — function calling and tool use feel native
- Low barrier to entry for teams already using the OpenAI API
- Built-in guardrails and safety features from OpenAI’s alignment work
- Rapid iteration — OpenAI ships updates frequently
- Growing marketplace of pre-built agent templates
Weaknesses:
- Model lock-in: built for OpenAI models, limited support for other providers
- Relatively new — less battle-tested in production compared to LangGraph or AutoGen
- Observability tooling is still maturing
- Less control over orchestration flow than graph-based approaches
- Enterprise features (SOC 2, HIPAA compliance tooling) are still catching up
Production verdict: The OpenAI Agents SDK is compelling for teams already committed to OpenAI’s ecosystem who want to add agentic capabilities without adopting a full orchestration framework. But the model lock-in is the dealbreaker for most enterprise clients we work with. When a client needs to switch from GPT to Claude for a specific use case — and they always do eventually — the migration cost from a model-locked SDK is significant. Carefully evaluate whether model flexibility matters to your roadmap.
5. Anthropic Agent SDK — The Accuracy-First Framework
Anthropic’s Agent SDK, which powers Claude Code and is available for custom agent development, takes a different approach: accuracy and safety over speed. Claude Opus 4.6 leads SWE-Bench at 80.8% — the highest score of any model on the most rigorous coding benchmark — and the Agent SDK is designed to leverage that accuracy in production workflows.
What sets it apart:
The SDK emphasizes extended thinking, tool use verification, and built-in safety layers. Agents built on Anthropic’s SDK tend to produce fewer hallucinations and more reliable tool calls — critical in domains where a wrong answer has consequences.
Strengths:
- Highest accuracy on complex reasoning tasks (SWE-Bench 80.8%)
- Built-in safety and alignment features — agents are less likely to go off-script
- Extended thinking mode for complex multi-step reasoning
- Strong tool use reliability — function calls are more consistent
- Multi-agent parallelism support in recent releases
- Growing MCP (Model Context Protocol) ecosystem for tool integration
Weaknesses:
- Anthropic model ecosystem only — same lock-in concern as OpenAI’s SDK
- Smaller agent framework community compared to LangGraph
- Enterprise deployment tooling is still evolving
- Higher per-token cost for Opus-level accuracy
Production verdict: When accuracy matters more than cost — healthcare documentation, legal contract analysis, financial compliance — Anthropic’s Agent SDK is worth the premium. We’ve deployed Claude-based agents for a compliance client, where the 2.4% false-violation rate (down from 12%) justified the higher inference cost. The MCP ecosystem is the sleeper advantage here: it’s becoming the standard for how agents connect to external tools, and Anthropic is leading that standard.
6. Google Agent Development Kit (ADK) — The Multimodal Play
Google’s ADK launched in 2026 as the native framework for building agents on Vertex AI and Gemini models. The differentiator: multimodal from day one. Agents can process text, images, video, and audio natively — no separate pipelines for each modality.
Where it matters:
For use cases that involve visual inspection (manufacturing quality control), document processing (scanned PDFs, handwritten notes), or video analysis (security, retail analytics) — Google ADK is the only framework where multimodal is a first-class capability, not a bolted-on feature.
Strengths:
- Native multimodal: text, image, video, audio processing in a single agent
- Tight Vertex AI integration for training, serving, and monitoring
- Gemini 3.1 Pro leads on general-purpose reasoning benchmarks (ARC-AGI-2: 77.1%)
- Google Cloud ecosystem: BigQuery, Cloud Functions, Pub/Sub integration
- Configurable human-in-the-loop with approval workflows
Weaknesses:
- Google Cloud lock-in — less portable than framework-agnostic options
- Newer ecosystem with fewer community templates and examples
- Documentation is still catching up to the feature set
- Enterprise adoption is slower than LangGraph or AutoGen communities
Production verdict: If your use case is multimodal — processing images, documents, or video alongside text — Google ADK is the strongest native option. For text-only agent workflows, the Google Cloud lock-in usually isn’t worth it when LangGraph gives you model flexibility. We’ve used ADK for a manufacturing client’s visual inspection pipeline where Gemini’s multimodal capabilities were a genuine technical differentiator, not just a convenience.
7. LlamaIndex Workflows — The RAG Specialist
LlamaIndex evolved from a RAG library into a full agent framework with its Workflows system. If your agent’s primary job is retrieving, reasoning over, and synthesizing information from large document sets — LlamaIndex Workflows is purpose-built for that.
Why it’s on this list:
67% of enterprise AI agents we deploy involve RAG at their core. For knowledge-intensive applications, retrieval quality determines 60–70% of agent performance — regardless of which orchestration framework you use. LlamaIndex’s deep retrieval capabilities give it an edge in this specific category.
Strengths:
- Best-in-class retrieval: hybrid search, reranking, agentic RAG with self-correction
- Event-driven workflow system for building multi-step agent pipelines
- Deep integration with every major vector store (Pinecone, Qdrant, Weaviate, pgvector)
- Strong document processing pipeline for PDFs, Word docs, and structured data
- Composable: works alongside LangGraph or other orchestration layers
Weaknesses:
- Agent orchestration is secondary to retrieval — less mature than LangGraph for complex flows
- Not designed for non-RAG agent use cases
- Smaller orchestration community compared to LangGraph or CrewAI
- Human-in-the-loop is event-based, not as native as LangGraph’s graph interrupts
Production verdict: LlamaIndex Workflows is the right choice when retrieval is the agent’s core job. For a client processing 50,000+ legal documents, we paired LlamaIndex’s retrieval layer with LangGraph’s orchestration — LlamaIndex handled knowledge retrieval, and LangGraph handled workflow routing and human review checkpoints. This “best of both” pattern is becoming standard in production deployments.
8. Intuz Agentic AI Framework — The Managed Enterprise Option
Full disclosure: this is our framework. We’re including it because it represents a category that the open-source frameworks above don’t cover — a fully managed, enterprise-grade agentic platform with built-in orchestration, RAG, and self-learning capabilities.
Why managed matters:
Most enterprise teams don’t want to assemble LangGraph + vector store + observability + deployment infrastructure + monitoring from scratch. They want agents that work in production on day one, with SLAs, support, and someone to call when things break.
What it includes:
- Multi-agent collaboration with automatic task routing
- Built-in RAG with retrieval optimization
- Self-learning orchestration — agents improve from production feedback
- Human-in-the-loop at every decision point
- Enterprise security: SOC 2 compliance, data isolation, audit trails
- Managed infrastructure: no MLOps team required
Results from production deployments:
- Customer support automation: 62% auto-resolution rate (up from 41%), average resolution time dropped from 4.2 hours to 47 minutes, 38% cost reduction
- Healthcare document processing: 93% accuracy after context isolation (up from 71%)
- Financial compliance: 2.4% false violation rate (down from 12%)
Production verdict: The Intuz Agentic Framework is the right choice for enterprises that need agents in production without building an internal ML platform team. It’s not the right choice if you have a strong ML engineering team that wants full control over every component — in that case, LangGraph or a lab SDK gives you more flexibility. We’re transparent about this because the worst outcome is a client who picks the wrong tool for their team.
Learn more about Intuz AI Agent Development Services
Head-to-Head: Which Framework Wins on What Matters
Which AI Agent Framework Is Best for Production Reliability?

Which AI Agent Framework Has the Lowest Cost Risk?
This is the question CFOs should be asking. Inference costs now represent 55% of enterprise AI cloud spending. The wrong framework choice can blow your AI budget before you see results.

Which AI Agent Framework Is Easiest to Adopt?

The adoption trap: The framework that’s fastest to prototype isn’t always the one you want in production. We’ve seen teams pick CrewAI for its 2-day demo speed, get stakeholder buy-in, then spend 3 months rebuilding in LangGraph when they hit production constraints. Factor in the total cost of adoption, not just the first week.
The Decision Matrix: Which Framework for Which Use Case
Stop evaluating frameworks in the abstract. Match the framework to your specific situation:
Choose LangGraph if:
- Your workflow has compliance requirements (healthcare, finance, legal)
- You need human review checkpoints in the agent flow
- You’re building a system that runs in production 24/7
- Your team has or can develop graph-based programming skills
- You need model flexibility (switch between GPT, Claude, Gemini)
Choose CrewAI if:
- You need a working demo in under a week
- Your use case is content generation, research, or analysis
- Your team thinks naturally in terms of roles and collaboration
- You’re willing to potentially rebuild when production constraints emerge
Choose AutoGen 2.0 if:
- You’re running on Azure OpenAI and want native integration
- Your use case involves code generation with iterative review loops
- You need high-concurrency async agent workflows
- You have the infrastructure for async programming at scale
Choose OpenAI Agents SDK if:
- Your stack is already built on OpenAI’s API
- You want the simplest path to adding agent capabilities
- Model lock-in to GPT is acceptable for your roadmap
- Your use case is straightforward (not multi-agent, not compliance-heavy)
Choose Anthropic Agent SDK if:
- Accuracy matters more than speed or cost
- Your use case involves safety-critical decisions
- You’re building code agents or complex reasoning pipelines
- MCP tool integration is part of your architecture
Choose Google ADK if:
- Your use case is multimodal (images, video, documents + text)
- You’re running on Google Cloud / Vertex AI
- Gemini’s reasoning capabilities match your task requirements
Choose LlamaIndex Workflows if:
- Your agent’s primary job is knowledge retrieval and synthesis
- You’re processing large document sets (legal, medical, financial)
- You want best-in-class RAG with agentic capabilities layered on top
Choose a managed platform (like Intuz Agentic Framework) if:
- You need agents in production without building an ML platform team
- Enterprise security, SLAs, and support are non-negotiable
- You want to move from concept to production in weeks, not quarters
The Pattern Most Teams Miss: Mixing Frameworks
Enterprise AI architectures increasingly combine frameworks rather than choosing a single one. The most effective pattern we’ve deployed:
CrewAI for research → LangGraph for execution.
The CrewAI crew produces a structured analysis using role-based agents (fast, intuitive, good at multi-perspective synthesis). LangGraph takes that output as its initial state and routes it through compliance review, human approval, and system action (deterministic, observable, auditable).
Both frameworks do what they’re best at. Neither is forced into a role it wasn’t designed for.
LlamaIndex for retrieval → LangGraph for orchestration.
LlamaIndex handles knowledge retrieval with its superior RAG pipeline — hybrid search, reranking, and self-correction. LangGraph handles the workflow logic, routing, and human review. This is the pattern we used for a legal-document-processing client handling 50,000+ documents.
The takeaway: Framework flexibility matters more than framework loyalty. The best production systems we’ve built use 2–3 frameworks, each handling the layer it was designed for.
What Matters More Than Framework Choice
After shipping agents across 7 industries, we’ve learned that the choice of framework accounts for maybe 20% of production success. The other 80%:
Retrieval quality. An agent with bad context will fail regardless of the orchestration framework. RAG architecture and document quality account for 60–70% of an agent’s performance in knowledge-intensive use cases. Fix your retrieval before blaming your framework.
Tool definitions. Vague tool descriptions produce unpredictable tool calls. Specific, example-driven tool definitions produce consistent ones. This is true across every framework on this list.
Failure handling. Every production agent needs explicit handling for: tool call failures, context window overflow, LLM timeout, rate limiting, and out-of-distribution inputs. No framework handles all of this by default. You build it, or your agents break in production.
Evaluation before deployment. Build a test set of 50–100 representative inputs before going live. Run every framework candidate against it. The benchmark on your data will tell you more than any comparison article — including this one.
Cost monitoring from day one. 49% of organizations cite high inference cost as their top blocker to scaling agents. Instrument token usage, track cost-per-task, and set alerts before your first production deployment. Not after the first invoice shock.
5 Strategic Patterns Shaping AI Agent Frameworks in 2026
Beyond individual framework selection, five macro trends are reshaping how enterprises think about agent infrastructure:
1. Graph-based orchestration is the convergence point. Whether it’s LangGraph’s explicit graphs, AutoGen’s conversation graphs, or Google ADK’s workflow graphs — every framework is moving toward graph-based state management. Teams that learn graph-thinking now will adapt faster as frameworks evolve.
2. MCP is becoming the standard for tool integration. Anthropic’s Model Context Protocol, now donated to the Linux Foundation with OpenAI, Google, Microsoft, AWS, and Salesforce all supporting, is how agents will connect to external tools. 50+ enterprise partners are implementing MCP. Framework choice matters less when tool integration is standardized.
3. Multi-agent specialization is replacing single general-purpose agents. The “one agent to rule them all” pattern is dying. Production systems use specialized agents — one for retrieval, one for analysis, one for action — orchestrated by a lightweight coordinator. Every framework on this list now supports this pattern.
4. Cost optimization is now a framework selection criterion. With inference accounting for 55% of AI cloud spending and agentic loops generating 10–20 LLM calls per task, frameworks that don’t offer explicit cost controls are being eliminated from enterprise shortlists. Expect “FinOps for AI agents” to become a standard procurement requirement.
5. The managed vs. open-source split is widening. Enterprises with strong ML teams are building on LangGraph. Enterprises without ML infrastructure are choosing managed platforms. The middle ground — “we’ll figure out production later” — is where 95% of agent projects fail.
Frequently Asked Questions About AI Agent Frameworks
What is the best AI agent framework for enterprise use in 2026?
LangGraph leads for enterprise production workloads due to its deterministic execution, native human-in-the-loop support, and LangSmith observability. For enterprises without dedicated ML teams, managed platforms like the Intuz Agentic AI Framework provide production-ready agents with built-in enterprise security and SLAs. The “best” framework depends on your team’s capabilities, your compliance requirements, and whether you need model flexibility.
Is LangGraph better than CrewAI for production?
For production reliability, yes. LangGraph’s graph-based execution model gives you explicit control over every state transition, making it auditable and deterministic — requirements in healthcare, finance, and legal. CrewAI excels at rapid prototyping and role-based collaboration, making it ideal for demos and content/research workflows. Many teams prototype in CrewAI and deploy in LangGraph.
How much does it cost to run AI agents in production?
Agent costs depend on the framework, model choice, and task complexity. Simple agents cost $3,500–$12,500 to build, while advanced autonomous agents range from $80,000–$120,000+. Ongoing inference costs are the hidden killer: agentic loops generate 10–20 LLM calls per task, and inference now represents 55% of AI cloud spending ($37.5B in early 2026). Initial development accounts for only 25–35% of the 3-year total cost of ownership.
Should I use OpenAI Agents SDK or LangGraph?
Use OpenAI Agents SDK if you’re committed to OpenAI’s model ecosystem and want the simplest path to agent capabilities. Use LangGraph if you need model flexibility (switch between GPT, Claude, Gemini), complex state management, or compliance-grade observability. LangGraph’s model-agnostic approach gives you more options as the model landscape evolves — and it evolves fast.
What is the Model Context Protocol (MCP) and why does it matter for agent frameworks?
MCP is Anthropic’s open standard for how AI agents connect to external tools and data sources, now governed by the Linux Foundation and backed by OpenAI, Google, Microsoft, AWS, and Salesforce. MCP standardizes tool integration across frameworks, meaning your tool definitions work regardless of which agent framework you use. 50+ enterprise partners are implementing MCP in 2026, making it the likely standard for agent-tool communication.
Can you mix multiple AI agent frameworks in one system?
Yes, and production systems increasingly do. The most common pattern: CrewAI for research/synthesis phases (fast, role-based) feeding into LangGraph for execution phases (deterministic, auditable). LlamaIndex Workflows paired with LangGraph is another production-proven combination — LlamaIndex handles retrieval, LangGraph handles orchestration. Framework flexibility beats framework loyalty.
How do I choose between building on an open-source framework vs. a managed platform?
Build on open-source (LangGraph, CrewAI, AutoGen) if you have a strong ML engineering team, want full control over every component, and can invest in building production infrastructure (observability, deployment, monitoring). Choose managed platforms if you need agents in production within weeks, require enterprise SLAs, or don’t have dedicated ML infrastructure. The 95% failure rate of AI pilots is primarily a production engineering problem, not a model problem.
What’s the biggest mistake teams make when choosing an AI agent framework?
Optimizing for demo speed instead of production reliability. 67% of organizations using agents report productivity gains, but only 10% are scaling in production. The gap is almost always this: the team picked the framework that produced the fastest demo, only to discover it couldn’t handle production failure modes, compliance requirements, or cost constraints. Evaluate frameworks against your production requirements, not your demo timeline.
Your Next Move
If you’re evaluating agent frameworks right now, here’s the fastest path to a decision:
- Define your failure tolerance. If an agent’s output has legal, financial, or safety consequences, you need LangGraph or a managed platform. Full stop.
- Run a cost projection on 1,000 representative tasks with your top 2 framework candidates. The invoice delta will eliminate one of them.
- Build the same agent in both finalists. Give your team 2 weeks with each. The framework your team can debug at 2 am is the one you ship.
The framework matters less than most teams think. What matters is whether you can observe, debug, and afford the agents you build — in production, at scale, when things go wrong.
Because they will go wrong. The question is whether your framework lets you fix it before your users notice.
Pratik K Rupareliya is Co-Founder & Head of Strategy at Intuz, He writes about what actually works when enterprises deploy AI to production.
Top AI Agent Frameworks in 2026: A Production-Ready Comparison was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.