
The Self-Healing Cloud: An Architectural Blueprint for Autonomous Operations with Agentic AI
1. Introduction: Beyond Automation to Autonomy
The Current State: The Wall of Monitors and the War Room
The alert fires at 2:17 AM. A cascade of notifications lights up the on-call engineer’s phone, each a symptom of a deeper, unseen problem. What follows is a familiar, frantic ritual of modern operations. A digital war room is convened in Slack, pulling engineers from their sleep into a flurry of activity.
One engineer pores over Datadog dashboards, trying to correlate a spike in API latency with memory usage. Another dives deep into Splunk, grappling with a firehose of logs, searching for a single anomalous entry. A third checks the recent deployment history. It’s a high-stakes, high-pressure search for a needle in a haystack of data.
This is the reality of operations at scale. We have built incredible automation — systems that can scale nodes in response to CPU load or restart a failing container. These automations are powerful, but they are also brittle. They are scripts written to solve known problems, codified responses to failure modes we have seen before. But what happens when the problem is novel? When it’s a subtle memory leak introduced by a new library, or a “noisy neighbor” issue in a multi-tenant cluster? Our scripts fail, and we are back in the war room, armed with experience and caffeine, fighting a reactive battle.
The Vision: From Reactive to Proactive & Autonomous
But what if the system itself could be the first responder? What if it could not only detect an issue but also understand it, reason about its cause, and propose a solution? This is the leap from simple automation to true autonomy.
We are on the cusp of a new paradigm: the “self-healing” cloud. This is not a system that just automates fixes, but one that can diagnose, reason about, and resolve new problems on its own. It can connect the dots between a slight increase in latency, a recent deployment, and a new pattern in the logs — a feat that previously required a room full of our best engineers.
This post will lay out a practical architectural blueprint for a closed-loop, autonomous operations system. We will design an AI agent that monitors observability data, diagnoses novel problems using Large Language Models (LLMs), proposes code-level fixes, and, after human approval, executes the remediation. This is no longer science fiction; it is the practical and achievable end-state of AIOps, and this guide will show you how to start building it.
2. Meet the Autonomous Agent: Core Concepts
To build a self-healing system, we first need to define its core actor: the AI agent.
What is an AI Agent in this context?
An AI agent is not a single tool or model. It’s a system of components that work together to achieve a goal. Think of it less as a script and more as a digital on-call engineer. It is defined by three key characteristics:
- Goals: The agent has a clear, high-level objective. For our purposes, the goal is to “maintain the health and performance of the production environment.”
- Tools: The agent has access to a curated set of APIs and command-line tools that allow it to both perceive and affect its environment. These are its senses and its hands. Examples include querying the Datadog API, running kubectl get pods, or creating a GitHub pull request.
- Reasoning Engine: At its core is a Large Language Model (LLM). This is the agent’s brain. It takes the goal, the available tools, and the current situation (e.g., an alert) and decides which tool to use next to get closer to its goal.
Introducing the Key Technologies at a High Level
Our autonomous agent is built upon a stack of modern technologies, each playing a critical role:
- AIOps/Observability Platforms (Datadog, Dynatrace, Prometheus): These are the sensory inputs — the eyes and ears of the system. They provide the raw data (metrics, logs, traces) that signal when something is wrong.
- Agentic AI Frameworks (LangChain, CrewAI, Microsoft Autogen): These are the brain and nervous system. They provide the scaffolding to connect the LLM to the tools, manage the conversation history, and orchestrate the complex workflows.
- Large Language Models (GPT-5, Claude 3, Gemini): This is the core reasoning engine. The LLM’s ability to understand natural language, synthesize data from multiple sources, and generate code is what makes the diagnosis and remediation of novel problems possible.
- Infrastructure as Code (Terraform, Kubernetes YAML): These are the hands. By generating and applying IaC, the agent can interact with and change the state of the cloud environment in a safe, repeatable, and auditable way.
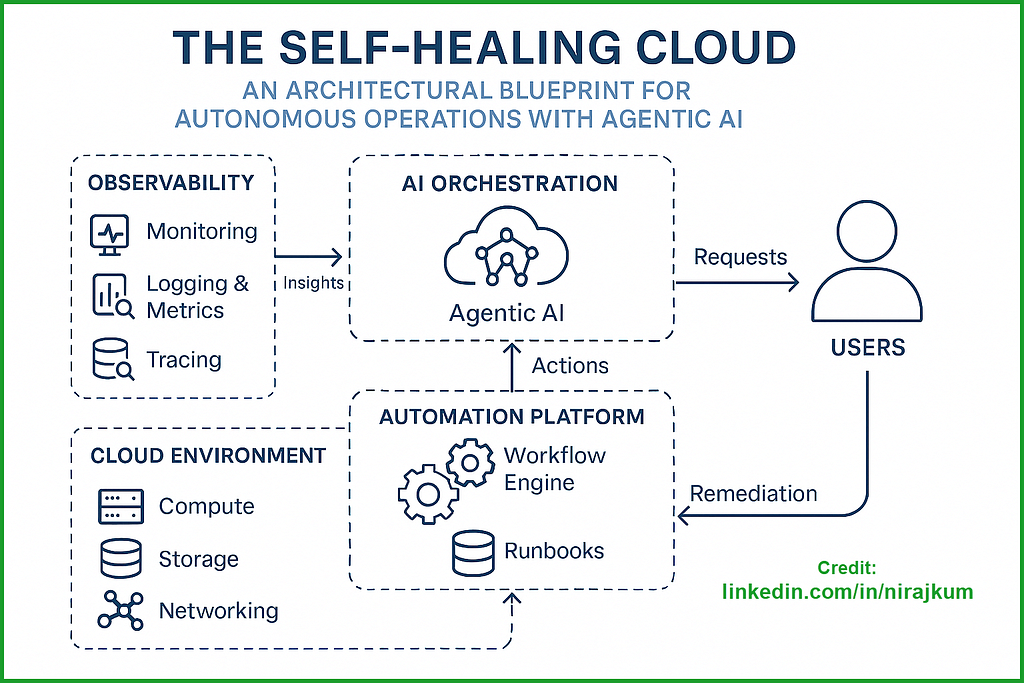
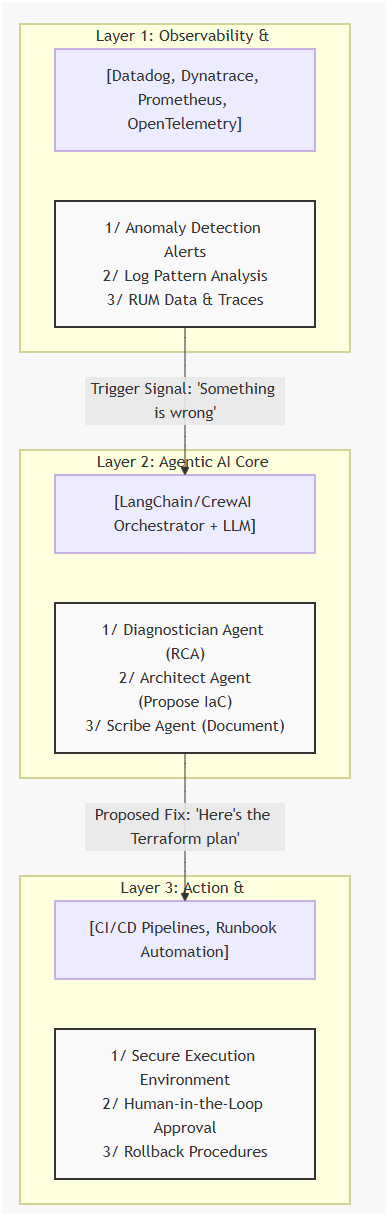
3. The Architectural Blueprint: Three Core Layers
Our self-healing system can be visualized as a three-layer stack, forming a closed loop from detection to action.
4. The Autonomous Healing Loop in Action (A Practical Scenario)
Let’s make this concrete. We’ll walk through a real-world example of the system in action.
Scenario: A new deployment introduces a subtle memory leak in a critical microservice running on AKS. It’s not causing a crash, but it’s slowly degrading performance in a way that traditional threshold-based alerts miss.
Phase 1: DETECT — The Anomaly Signal
The process begins not with a loud alarm, but with a whisper. The Observability Layer (Datadog’s Watchdog) detects a statistical anomaly: a consistent, linear upward trend in memory usage for the auth-service pods, which is highly correlated with a slight increase in p99 API latency. It sends a detailed webhook to the Agentic AI Core’s API endpoint. The payload is rich with context: a link to the relevant dashboard, the time the anomaly was first detected, and initial log snippets showing no outright errors.
Phase 2: DIAGNOSE — The Agentic Root Cause Analysis
The webhook triggers the Diagnostician Agent, a specialized agent whose goal is to find the root cause.
- Tool Use (Query Metrics): It starts by using its Datadog API tool to pull granular memory, CPU, and latency metrics for the auth-service and its direct dependencies, focusing on the time window starting 30 minutes before the anomaly was detected.
- Tool Use (Analyze Deployments): Concurrently, it uses its kubectl tool to check the deployment history in the production namespace. It discovers that a new version of the auth-service deployment was rolled out 75 minutes ago.
- Reasoning (LLM Prompt): The agent synthesizes this information into a prompt for its core LLM: “GIVEN: Metrics show steadily increasing memory since 11:00 PM. A new deployment of ‘auth-service’ occurred at 10:45 PM. API latency is slowly rising. HYPOTHESIZE: What is the likely root cause? What additional data is needed to confirm?”
- Tool Use (Fetch Logs): The LLM, with its vast training data, hypothesizes a potential memory leak. It instructs the agent to use its Loki API tool to fetch logs from the auth-service pods, specifically searching for keywords related to garbage collection (GC) pauses or resource warnings.
- Final Diagnosis (LLM): The logs show increasing GC pause times. The agent now has high confidence. It concludes: “Root cause is a likely memory leak introduced in the image tagged ‘v1.2.1’ deployed at 10:45 PM.”
Phase 3: PROPOSE — The AI-Generated Fix
The diagnosis is passed to the Architect Agent, whose goal is to design a safe and effective remediation.
- Reasoning (LLM Prompt): The agent receives the context and is prompted: “GIVEN: A memory leak was introduced in the latest deployment of ‘auth-service’. PROPOSE: A safe, immediate remediation plan and a long-term fix.”
- Tool Use (Code Generation): The LLM reasons that the safest immediate action is a rollback. It uses its code generation ability to generate the precise kubectl command needed: kubectl rollout undo deployment/auth-service -n production.
- Tool Use (Create Pull Request): For the long-term fix, it uses its GitHub API tool. It creates a new branch, performs a git revert on the commit that was deployed, and opens a new pull request. The body of the PR is automatically populated with a summary of the incident, linking to the Datadog dashboard and the key log findings.
Phase 4: ACT — The Human-in-the-Loop Execution
The proposed fix (the kubectl command and the PR link) is sent to the Action Layer. A message is posted to the on-call SRE’s Slack channel with “Approve Rollback” and “Reject” buttons. The SRE reviews the agent’s concise diagnosis and the proposed plan. Upon clicking “Approve,” a secure CI/CD pipeline (GitHub Actions) executes the kubectl rollout undo command. Simultaneously, the Scribe Agent automatically documents the entire incident—from detection to resolution—in a Confluence page for the post-mortem.
5. Building the Agentic Core: Technical Deep Dive
The magic in Layer 2 requires careful construction.
Choosing Your Framework:
- LangChain: Excellent for rapid prototyping. Its vast library of pre-built “tools” and integrations makes it easy to connect your agent to external APIs like Datadog and GitHub.
- CrewAI / Microsoft Autogen: These frameworks are superior for creating a “society of agents.” They allow you to define specialized agents (like our Diagnostician, Architect, and Scribe) with distinct roles and have them collaborate to solve a problem, which often yields more robust and accurate results.
Prompt Engineering for Reliability:
- This is the most critical skill. You must engineer your prompts to force the LLM to “show its work” and reason step-by-step. Use structured prompts that provide clear context, list the available tools, and define the desired output format (like JSON). Incorporating Retrieval Augmented Generation (RAG) to pull context from your internal runbooks can dramatically improve accuracy.
Tool Development:
- A “tool” is simply a function that the agent can call. It should be simple, deterministic, and have a clear description. Here’s a pseudo-code example of a kubectl tool:
def get_deployment_history(service_name: str, namespace: str) -> str:
"""
Returns the rollout history for a given Kubernetes deployment in a
specific namespace.
Useful for correlating incidents with recent code changes.
"""
# Code to execute 'kubectl rollout history
deployment/{service_name} -n {namespace}'
# ... returns the formatted output as a string
6. Risks, Ethics, and Guardrails
Granting autonomy to a system that can modify a production environment requires building a robust framework of safety and control. This is not about trusting the AI; it’s about building a system where trust isn’t required.
- The “Hallucination” Problem: An LLM can confidently generate an incorrect diagnosis or a destructive command. It might misinterpret a log line or propose a terraform destroy command when a simple restart would suffice. This is the single biggest risk.
- The Importance of the Human Gate: For the foreseeable future, a human-in-the-loop approval gate for any write, update, or delete operation is non-negotiable. The agent’s power should be limited to observing, analyzing, and proposing. The final “go” decision for any remediation must rest with a human expert who can sanity-check the agent’s reasoning. This can be implemented via Slack buttons, ServiceNow approvals, or GitHub Actions environments.
- Least Privilege for Agents: The AI agent’s service account or cloud role must be aggressively locked down with the absolute minimum permissions required. It should never have cluster-admin or owner roles. For diagnosis, it needs read-only access to observability platforms and the Kubernetes API. For action, it might only need permission to rollout undo a specific deployment or trigger a specific, pre-approved CI/CD workflow.
- Cost Management: The LLM API calls that power the agent’s reasoning, especially to powerful models like GPT-4, can be expensive. A misconfigured agent that enters a loop could quickly run up a significant bill. Implement strict budget alerts, rate limiting, and caching for repeated queries to keep costs under control.
7. Conclusion: The Dawn of the Autonomous Cloud
We are moving from a world where humans are the first responders to a world where humans are the strategic overseers of an autonomous system. The architecture laid out here is not about replacing engineers; it’s about augmenting them. It’s about building a force multiplier that frees our most valuable engineers from the toil of late-night firefighting and allows them to focus on what they do best: building better, more resilient systems.
The future of cloud operations is not just automated; it’s autonomous. As these systems mature, we can look forward to:
- Predictive Healing: Agents that detect problems from leading indicators — like a subtle change in garbage collection patterns — before they cause a user-facing outage.
- Automated Optimization: Agents that don’t just fix problems but actively look for ways to improve efficiency. Imagine an agent that opens a pull request on a Monday morning with the message: “This service is consistently over-provisioned during weekends. I’ve created a PR to adjust its HPA and resource requests, saving an estimated $200/month.”
The journey to a self-healing cloud is a marathon, not a sprint. The call to action is to start small. Begin by building an agent that can only diagnose problems and post its findings to a Slack channel. Build trust in its analytical capabilities. Once the agent has proven itself as a reliable diagnostician, you can gradually grant it the ability to propose, and eventually, with a human always in the loop, to act. The autonomous cloud is here. It’s time to start building.
Keep Building & Stay Connected!
🌟 Found this guide useful? Don’t let the momentum stop! Share it with your team to spark new solutions, and drop your own challenges or success stories in the comments below — I’d love to hear how you’re using these ideas.
📲 Let’s connect on LinkedIn to swap DevOps war stories and build resilient systems together.
☕ Support more practical, real-world guides like this one by buying me a coffee at ko-fi.com/nirajkum. Your support fuels the mission to empower engineers!
At last, If you’ve found this article helpful and want to show your appreciation, please consider giving it a clap 👏 or two. If you’d like to stay updated on my future content, be sure to connect with me on LinkedIn and follow me on Twitter, so you don’t miss out. Thank you for reading and for your support!
The Self-Healing Cloud: An Architectural Blueprint for Autonomous Operations with Agentic AI was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.