
The Production Agentic AI Reality Check: Five Truths Nobody Tells You
Why your brilliant demo fails in production — and how to build systems that actually work
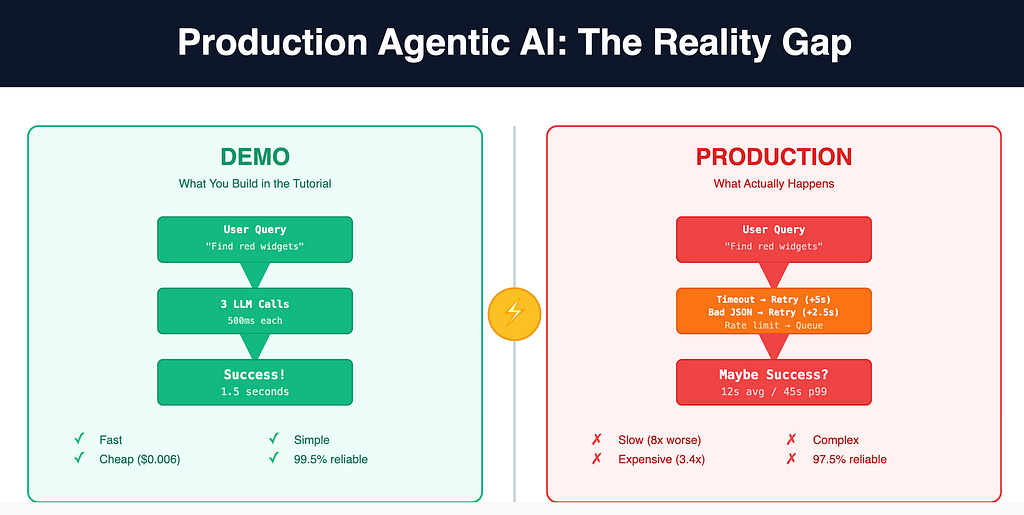
The agentic AI hype is everywhere. Elegant demos showcase autonomous systems solving complex problems. Vendors promise, “Just add agents and watch the magic.” Then, you deploy to production. Your latency explodes. Costs spiral. Error rates skyrocket.
After two years building production AI systems at scale, I’ve learned the gap between tutorial and production is wider than most imagine. Here are the five hard truths I wish someone had told me.
Truth #1: Latency Compounds Exponentially
Demo math: 3 LLM calls × 500ms each = 1.5 seconds. Users wait. Magic happens.
Production reality: Those same 3 calls now average 12 seconds, with p99 hitting 45 seconds.
Why? Network failures force retries. Rate limits create queues. LLM latency varies wildly (500ms to 8 seconds). Sequential dependencies compound every delay.
Your timeout triggers a retry (+5 seconds). Malformed JSON requires another attempt (+2.5 seconds). Suddenly you’re at 8 seconds and users have left.
What actually works:
Tier 1: Fast Path (80% of requests)
- Single optimized prompt, zero agent complexity
- Latency: <1 second | Cost: $0.001
- Handles common cases directly
Tier 2: Agent Path (15% of requests)
- Maximum 3 tool calls, hard 10-second timeout
- Parallel execution where possible
- Circuit breakers at every step
Tier 3: Complex Path (5% of requests)
- Multi-agent collaboration for high-stakes cases only
- $0.50 max budget, human-in-the-loop
- Async processing (don’t make users wait)
The insight: Most requests don’t need agents. Use the simplest solution that works.
Truth #2: The Reliability Paradox
Single LLM call: 99.5% success rate.
Five sequential calls: 0.995⁵ = 97.5% success rate
You just went from 1-in-200 failures to 1-in-40 failures.
But it’s worse. These failures cascade:
- Tool selection fails → garbage to next step
- Retrieval returns empty → agent hallucinates answer
- Poor decisions compound → the system executes incorrectly
- Future requests learn from bad data → error propagates
The fix: Circuit breakers everywhere:
def call_retrieval_tool(query):
results = retrieval_service.search(query)
if not results:
return fallback_to_simpler_approach()
if confidence_score(results) < 0.7:
return escalate_to_human()
return results
Don’t let agents proceed when uncertain. If confidence is low:
- Admit uncertainty to users
- Fall back on a simpler approach
- Escalate to human review
Mindset shift: Traditional software designs for success. Agentic AI must be designed for failure.
Truth #3: Cost Spirals From Unexpected Places
Tutorial economics: 1,000 requests/day × 3 calls × $0.002 = $6/day ($180/month)
Production reality after 3 months:
- Retry overhead: $5/day
- Validation loops: $2.25/day
- Multi-tool requests: $4.50/day
- Complex cases: $6/day
Total: $20.75/day ($622/month) — 3.4× your estimate
Hidden multipliers:
- Retries — failed requests cost more (multiple attempts)
- Validation — can’t trust outputs blindly (extra LLM calls)
- Context expansion — agents need more tokens
- Logging — full traces for debugging — isn’t free
- “Just one more call” trap — Agents being “thorough”
Smart model selection:
- Cheap models (Haiku, GPT-3.5) for routine decisions
- Expensive models (Opus, GPT-4) only for critical reasoning
- Never use Opus for “select which tool to use”
The dashboard that saved us: Real-time monitoring showing:
- Cost per successful request
- Cost per failed request
- Most expensive query patterns
- Alerts when thresholds exceeded
We discovered that 5% of requests consumed 60% of costs. Optimizing those edge cases had a massive ROI.
Truth #4: Observability Is Harder Than You Think
Traditional logging fails:
[INFO] Agent started
[INFO] Tool called: search
[ERROR] Validation failed
This tells you nothing. What you actually need:
{
"trace_id": "req_abc123",
"steps": [
{
"step": 1,
"action": "tool_selection",
"reasoning": "User specified color and price, need product search",
"confidence": 0.89,
"cost": 0.003,
"latency_ms": 234
},
{
"step": 2,
"tool": "product_search",
"results_count": 0,
"warning": "No results - possible data issue"
}
],
"total_cost": 0.012,
"success": false,
"failure_reason": "no_products_matched_criteria"
}
Now you can:
- Reconstruct decision-making
- Identify failure points
- Find patterns
- Estimate business impact
Required infrastructure:
- Structured trace IDs throughout the entire execution
- Semantic logging (WHY decisions made, not just WHAT)
- Selective context capture (log full context when confidence low)
- Tool call replay capability
- Cost attribution per trace
The lesson: build observability infrastructure BEFORE building complex agents.
Truth #5: Evaluation is Continuous, Not OneTime
You test on 50 examples. 100% accuracy! You deploy.
Three months later: 83% accuracy, systematic biases, doubled costs.
What happened?
- Data drift (new patterns agents haven’t seen)
- System evolution (prompt updates broke edge cases)
- User behavior changes
- Seasonal variations
Most teams can’t answer:
- Real production success rate?
- Why does it fail?
- Getting better or worse?
- How does Version 2 compare?
What works:
- Continuous evaluation:
if random() < 0.05: # 5% sample
queue_for_human_review(request, response)
automated_checks = [
check_for_hallucinations(response),
check_tool_usage_appropriate(tools_used),
check_cost_within_budget(total_cost)
]
2. Multi-dimensional metrics:
- Task success (solved user’s problem?)
- Reasoning quality (right approach?)
- Efficiency (wasted tokens?)
- Cost per completion
- User satisfaction
3. Regression test suite: Build collection of “known hard” cases. Every agent version must pass before deployment.
4. Drift detection:
if current_accuracy < baseline - 0.05:
alert_team("Performance degraded 5%+")
trigger_retraining()
The Architecture That Survives Production
After multiple production systems, this pattern balances power with reliability:
Smart Router (Fast & Cheap)
- Handles 80% with a single prompt
- <1 second, $0.001
- No agent complexity
Focused Agent (Medium)
- Handles 15% needing tools
- Max 3 calls, 10-second timeout
- Circuit breakers, fallbacks
Expert System (High Stakes)
- Handles 5% complex cases
- Multi-agent with human oversight
- Worth the cost and latency
Anti-pattern: complex multi-agent for every request because “that’s what agentic AI means.”
No, use the simplest solution that works.
The Prompt Engineering Reality
Good agent prompts are 5–10× longer than simple prompts.
Not this:
You have tools. Use them to help the user.
This:
CORE PRINCIPLES:
1. Accuracy over speed
2. Transparency — explain reasoning
3. Know your limits — admit uncertainty
DECISION FRAMEWORK:
1. Can you answer without tools? If yes, answer directly.
2. If tools needed, which ONE is most relevant?
3. After each result: Do you have enough information?
4. Max 3 tool calls. Then admit uncertainty.
CRITICAL CONSTRAINTS:
– Never call tools speculatively
– Never call same tool twice with similar inputs
– If confidence < 70%, tell user you’re uncertain
– If cost > $0.05, escalate to human
ERROR RECOVERY:
– Tool failed? Try once, then fall back
– Unexpected output? Validate before proceeding
Prompt engineering for agents is a core discipline. Version it, test it, iterate it like code.
What I Wish I’d Known
- Start with the simplest thing — don’t build a 5-agent system when a single call works
- Observability isn’t optional — you can’t debug what you can’t see
- Cost WILL spiral — hard budgets per request, monitor real time
- Design for failure — agents fail constantly, every step needs a failure path
- Users don’t care about architecture — they care: fast, accurate, reliable
- Evaluation never ends — performance drifts, continuous monitoring required
- The 80/20 rule is real — focus agent complexity on 20% where it adds value
- Production ≠ demos — the gap is wider than you think
The Path Forward
Agentic AI is genuinely powerful when done right. But production is messy, slow, expensive, hard to debug, and fragile.
Teams that succeed:
- Respect complexity instead of ignoring it
- Build observability from day one
- Start simple, adding complexity only when justified
- Design for failure
- Measure and optimize continuously
- Keep user experience front and center
The future is agentic. But the gap between demo and production is real.
Build systems that cross it!
Senior Software Engineer with 15 years building distributed systems at scale. I write about what actually works in production, not what looks good in demos.
Connect with me: LinkedIn
Discussion: What surprised you most moving from POC to production? What’s your biggest production agent failure story?
Share this if it helps others building production AI. The more we share real lessons, the better the field gets.
The Production Agentic AI Reality Check: Five Truths Nobody Tells You was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.