
The LLM Speed Hack Nobody Is Talking About
I’ve been a fast typer my whole life.
For decades, I optimized my input speed. I learned keyboard shortcuts, practiced touch typing, and prided myself on how quickly I could translate thought into text. It was the only bottleneck I knew.
Then Large Language Models arrived, and suddenly I found myself waiting. Not for my own fingers, but for the machine to think. I’d type a prompt — something that took me thirty seconds to articulate — and then stare at a blinking cursor while the AI streamed its answer back, word by agonizing word.
The bottleneck had shifted. It was no longer about my input speed. It was about the machine’s output speed.

The Secret War on Latency
If you follow AI news, you’ve seen the headlines: new models with better benchmark scores, larger context windows, multimodal capabilities. But there’s a quieter revolution happening underneath, one that doesn’t get the same attention.
It’s about speed.
And the latest breakthroughs aren’t coming from bigger GPUs or better hardware alone. They’re coming from clever software techniques that make LLMs think dramatically faster without sacrificing the quality of their answers.
Here’s the thing: most people assume there’s a trade-off. Speed or accuracy. Fast answers or smart answers. Choose one.
But recent research from labs around the world is proving that assumption wrong. In fact, some of the newest techniques are achieving 2.8x speedups while maintaining or even improving output quality .
Let me show you how.
Technique 1: The Drafting Game (Speculative Decoding)
The first hack is called speculative decoding, and it’s brilliantly simple.
Normally, an LLM generates text one token at a time. Token by token, word by word, it runs its entire massive brain on every single step. It’s like having a world-class expert write every single word of a memo from scratch, including the articles and prepositions.
Speculative decoding flips this script. It introduces a “draft model” — a much smaller, faster model — that proposes several tokens in a sequence. Then the big, smart model reviews the entire sequence in one parallel pass and either accepts it or corrects it .
Think of it like this: you have a senior architect and a junior assistant. The junior drafts a bunch of blueprints quickly. The senior reviews them all at once. If the junior’s work is good, the senior approves the whole batch in the time it would have taken to draw a single line.
The math works because modern GPUs are optimized for parallel processing. Checking five tokens simultaneously takes roughly the same time as generating one . The challenge? The draft model has to stay aligned with the target model. If the big model gets updated, the draft’s guesses become stale.
Technique 2: The Self-Improving Engine (TIDE)
This is where things get really interesting — and where the “hack nobody is talking about” comes into focus.
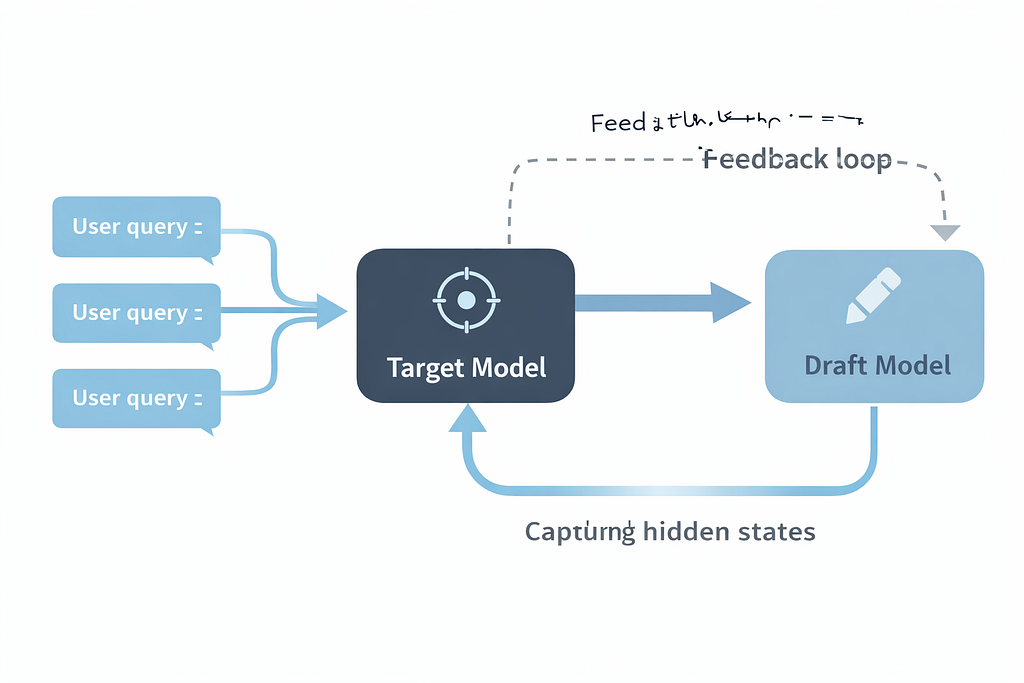
Researchers have developed a framework called TIDE (Temporal Incremental Draft Engine) that solves the stale draft problem in an elegant way . Instead of training a draft model once and hoping for the best, TIDE continuously adapts the draft model during inference.
Here’s the clever part: as the target model processes user requests, it generates hidden states — internal representations of its thinking. TIDE captures these states and uses them as real-time training signals for the draft model. No extra computation. No separate training runs. The draft model learns on the job, for free .
In real-world tests, TIDE achieved up to 1.15x throughput improvement over static speculative decoding while reducing draft training time by 1.67x . It’s not just faster — it’s smarter about becoming faster.
Technique 3: The Quantization Breakthrough (Hierarchical Framework)
Now let’s talk about quantization — the practice of shrinking model weights from high precision (like 16-bit) to lower precision (like 4-bit). This reduces memory footprint and speeds up computation. But here’s the problem researchers recently discovered: when you combine quantization with speculative decoding, the benefits can actually cancel each other out .
Wait, what?
It turns out that on 4-bit quantized models, verifying a “tree-style” draft (multiple branching token possibilities) creates significant time overhead. The memory savings are great, but the computational load spikes .
The solution? A hierarchical framework that uses a small intermediate model to convert tree-style drafts into simple sequences. This tiny extra step leverages the memory access benefits of the quantized model while avoiding the computational penalty.
The results are striking: a 2.78x speedup on a 4-bit quantized Llama-3–70B model running on an A100 GPU. That’s nearly three times faster than baseline, and it outperforms previous state-of-the-art methods by 1.31x .

Technique 4: The Training Revolution (TLT)
Here’s another angle that most people miss: the speed gains don’t have to come at inference time. They can come from how we train the models in the first place.
MIT and NVIDIA recently collaborated on a technique called TLT (Taming Long Tails) that addresses a massive inefficiency in training reasoning models . When these models solve complex problems, they generate multiple “rollout” answers. Some answers are short. Some are long. And the processors that finish early just sit idle, waiting for the stragglers.
TLT grabs those idle processors and puts them to work training draft models in real-time. The result? Training speed improvements between 70% and 210%, with zero loss in model accuracy .
And here’s the kicker: the lightweight draft models produced during training become free byproducts that can be used later for efficient inference. You get faster training and faster deployment from the same process.

Technique 5: Complementary Schemes (QSpec)
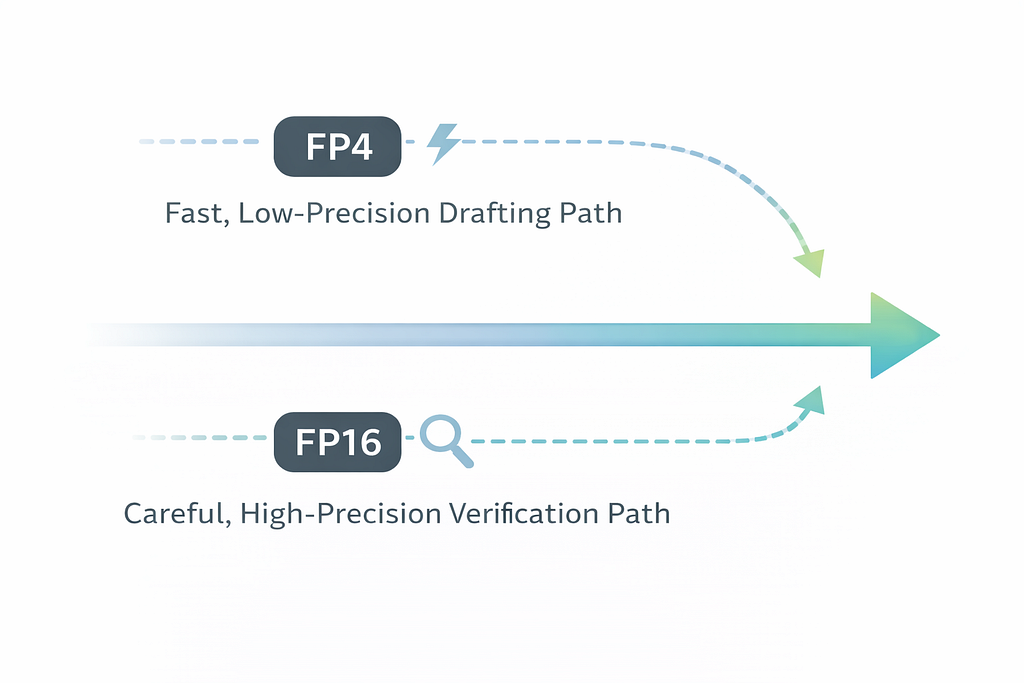
Finally, researchers have developed an approach called QSpec that combines two different quantization schemes in one pipeline .
Here’s the insight: you don’t have to use the same precision for everything. QSpec uses low-precision joint quantization (weights and activations both compressed) for the fast drafting stage, and high-precision weight-only quantization for the accurate verification stage .
The two stages share weights and KV cache, enabling near-zero-cost switching without retraining or auxiliary models. In testing, QSpec achieved up to 1.64x speedup without quality degradation, and outperformed other speculative decoding methods by up to 1.55x in batched settings .
The Myth of the Trade-Off
For years, we’ve accepted the idea that speed and quality are opposing forces. You want fast answers? Use a smaller model. You want smart answers? Wait longer.
But these techniques are systematically dismantling that assumption.
TIDE continuously adapts draft models to changing workloads . The hierarchical framework solves the quantization-speculation conflict . TLT eliminates idle training time . QSpec combines complementary precision schemes . And new loss functions like LK losses directly optimize for acceptance rate rather than proxy metrics like KL divergence, yielding 8–10% improvements in average acceptance length .
Each technique alone is impressive. Together, they represent a fundamental shift in how we think about LLM inference.

Why This Matters for the Rest of Us
You might be reading this thinking, “Okay, but I just want my chatbot to answer faster.” Fair enough. But the implications go far beyond convenience.
Lower Costs: When models run faster on the same hardware, the cost per query plummets. The hierarchical framework’s 2.78x speedup isn’t just an engineering win — it’s an economic one . It means startups can afford to run sophisticated models. It means developers in developing nations can build on technology that was previously out of reach.
New Applications: Real-time translation that keeps pace with conversation. AI gaming companions that react instantly. Voice assistants that don’t make you wait. Each of these becomes viable only when latency drops below a certain threshold. The techniques described here are pushing us toward that threshold.
Democratization: When models can run efficiently on smaller instances — like running quantized DeepSeek-V3 on AWS instances with 640GB memory instead of 1128GB — deployment becomes accessible to more organizations . The barriers to entry keep falling.
Environmental Impact: Faster inference means less energy per query. When you’re serving millions of users, those savings add up to real reductions in carbon footprint.
The Hack Nobody Is Talking About
So why isn’t anyone talking about these techniques?
Partly because they’re technical. Speculative decoding, quantization, hierarchical frameworks — these aren’t as catchy as “GPT-5 released” or “model achieves PhD-level reasoning.” They don’t make for splashy headlines.
Partly because they’re happening in research papers and open-source repositories, not press releases. The arXiv papers I’ve cited here represent work from academic institutions and industry labs, not marketing departments.
And partly because the people building these techniques are too busy building to stop and explain them to the rest of us.
But here’s the truth: these incremental advances — the 1.15x improvements, the 2.78x speedups, the 210% efficiency gains — are what will make AI truly ubiquitous. Not the next massive model with trillions of parameters. The optimizations that let us run existing models faster, cheaper, and more efficiently.

What Comes Next
I spent thirty years learning to type faster so I could keep up with machines. Now the machines are learning to think faster so they can keep up with me.
The research I’ve covered here — TIDE, hierarchical frameworks, TLT, QSpec, LK losses — represents the bleeding edge of that effort. But it’s only the beginning.
As these techniques mature and make their way into production systems like vLLM and cloud platforms , they’ll become invisible infrastructure. You won’t know they’re there. You’ll just notice that your AI feels faster. More responsive. More natural.
And you might wonder, briefly, how they did it.
Now you know.
Enjoyed this piece? Follow me for more deep dives into the technology shaping our future. Clap if you believe speed matters.
Sources and Further Reading
- Park, J. et al. (2026). TIDE: Temporal Incremental Draft Engine for Self-Improving LLM Inference. arXiv:2602.05145.
- Zhao, J. et al. (2025). Speculative Decoding Meets Quantization: Compatibility Evaluation and Hierarchical Framework Design. arXiv:2505.22179.
- Zhao, J. et al. (2025). QSpec: Speculative Decoding with Complementary Quantization Schemes. Proceedings of EMNLP 2025.
- MIT & NVIDIA. (2026). TLT Technology for Inference LLM Training. MIT News.
- Samarin, A. et al. (2026). LK Losses: Direct Acceptance Rate Optimization for Speculative Decoding. arXiv:2602.23881.
- AWS Machine Learning Blog. (2026). Accelerating LLM inference with post-training weight and activation using AWQ and GPTQ on Amazon SageMaker AI.
The LLM Speed Hack Nobody Is Talking About was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.