
The Great Compression: How AI Model Distillation Is Rewriting the Rules of the Industry
The Free Lunch That Came With a Bill
In October 2019, a team at Hugging Face, a French-American AI startup, published a model called DistilBERT. It retained 97% of its parent model’s performance on language-understanding benchmarks while running 60% faster and carrying 40% fewer parameters.
“The numbers looked like a free lunch. Six years later, the bill arrived — as a geopolitical crisis.”
When Distillation Became Geopolitics
When DeepSeek, a Chinese AI lab founded in 2023 by Liang Wenfeng and backed by the Hangzhou hedge fund High-Flyer, released its R1 model in January 2025, Silicon Valley’s reaction was not admiration.
DeepSeek-R1 achieved performance comparable to OpenAI’s o1 across mathematics, coding, and reasoning tasks. The company claimed a training cost of roughly $5.6m for its earlier V3 model — a figure that, even accounting for excluded prior research expenditure, was an order of magnitude below the $50–100m that Epoch AI attributes to training runs for comparable frontier models.

The Distillation Accusation
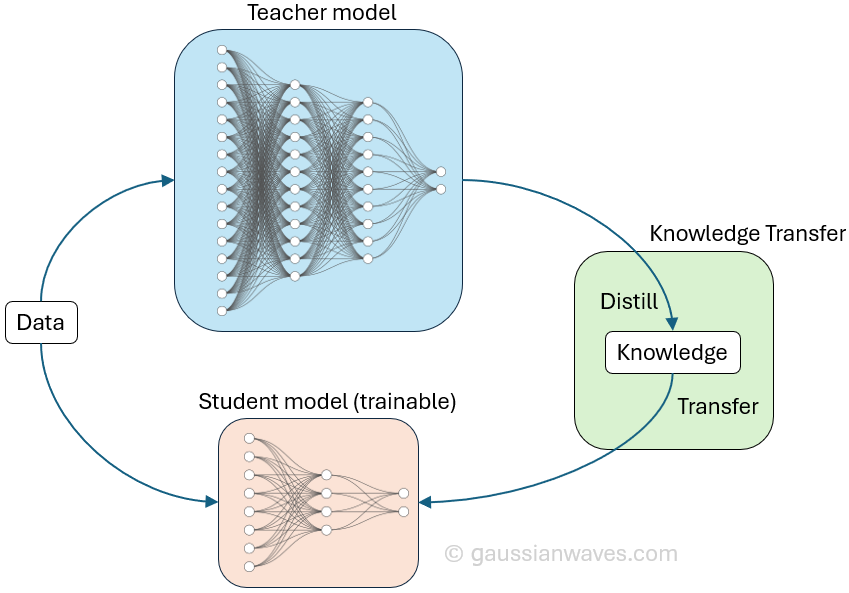
More troubling for American AI firms was how DeepSeek got there. The company had used distillation techniques, training smaller “student” models on the outputs of larger, more expensive “teacher” systems.
OpenAI alleged, in a memo sent to the U.S. House Select Committee on China in February 2025, that DeepSeek employees had developed methods to circumvent its access restrictions and had used its models’ outputs to accelerate their own development.
A technical procedure had become an accusation of economic warfare. Model distillation — a technique that had lived quietly in machine learning research for a decade — was suddenly at the centre of a geopolitical confrontation over intellectual property, national security, and the future economics of AI.
How Distillation Actually Works
The core idea is deceptively simple, and it dates back to a 2015 paper by Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. A large, expensive “teacher” model — trained on vast datasets using enormous computational resources — doesn’t just produce final answers.
It produces probability distributions across all possible answers. When a model classifies an image and says “cat” with 90% confidence, it also assigns smaller probabilities to “dog,” “fox,” and dozens of other categories.
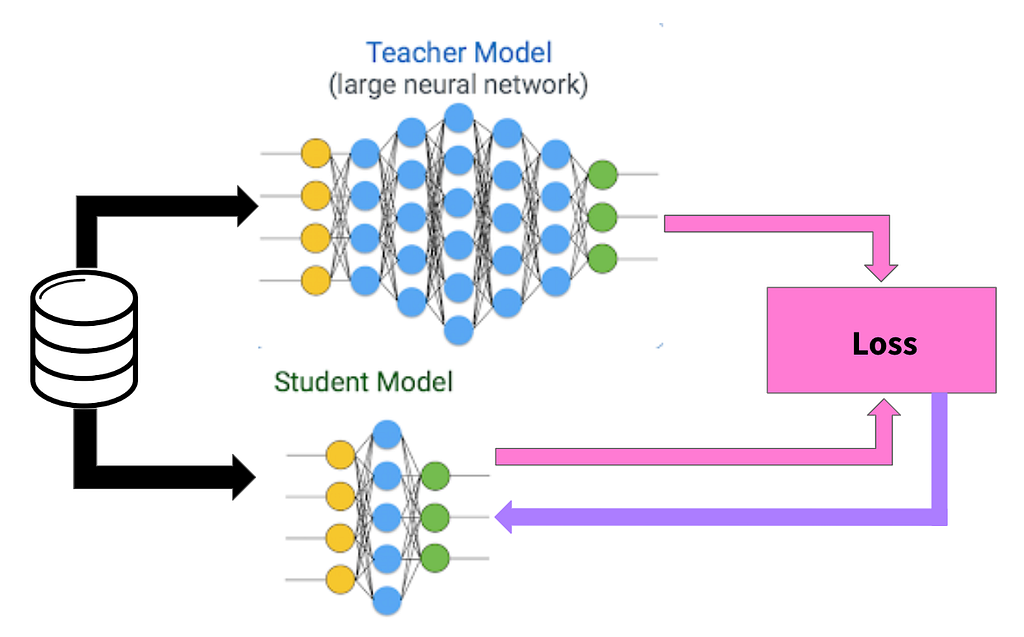
These “soft targets,” as Hinton and colleagues called them, contain far richer information than the hard binary labels in the original training data. A student model trained on these soft probability distributions learns not just what the right answer is, but how the teacher thinks about wrong answers — which wrong answers are close, which are distant, and why.
The process works through a temperature parameter. Raise the temperature, and the teacher’s probability distribution softens, spreading more evenly across categories and revealing subtler relationships between concepts.
The student model trains on these softened outputs, effectively inheriting the teacher’s internal knowledge structure without needing the teacher’s size or the teacher’s original training data. Lower the temperature back down at inference time, and the student produces sharp, confident predictions — but informed by the richer understanding it absorbed during training.


This matters because it is not merely compression. Pruning and quantisation — the other main techniques for shrinking neural networks — operate on the model itself, removing redundant connections or reducing the numerical precision of its weights.
Modern quantisation methods like GPTQ and AWQ are sophisticated, and pruning can be remarkably surgical, but both preserve the original architecture while trimming it down. Distillation does something fundamentally different: it transfers knowledge to an entirely new model, which can have a different architecture, a different size, and a different purpose.
What the student inherits is not structure but understanding.
Why It Matters for Access
Training a frontier model from scratch requires resources that only a handful of organisations on Earth can marshal. Compute costs run into tens or hundreds of millions of dollars. The data requirements are vast. The engineering talent is concentrated in a few dozen teams worldwide.
Distillation breaks that bottleneck. Hugging Face demonstrated this early with DistilBERT — 66 million parameters, 97% of BERT’s language understanding, small enough to run on a phone.
The principle has since scaled dramatically. DeepSeek’s distilled R1 variants, including models with as few as 1.5 billion parameters, brought reasoning capabilities previously confined to massive systems within reach of organisations running modest hardware.
Real-World Impact: Healthcare at the Edge
Wadhwani AI, a Mumbai-based non-profit, offers a useful illustration. Its “Cough Against TB” tool analyses cough sounds and symptom data through a mobile app used by healthcare workers in rural India, enabling cost-effective tuberculosis screening in settings where a GPU cluster, let alone a radiologist, is unavailable.
The tool relies on model compression — not distillation in the strict Hinton sense, but a close cousin in the family of techniques that make large models small enough to run where they are needed most. The principle is the same: knowledge developed at scale, deployed at the edge.
For organisations operating under these constraints, compression techniques are the only viable path to deploying AI that works in the field.
What Disappears
The cost is real, and it does not show up where most observers expect. This is the part of the distillation story that deserves more attention than it gets, and the part where the research is thinnest — which is itself part of the problem.
In 2019, Sara Hooker — then at Google Brain, now head of Cohere for AI — published “What Do Compressed Deep Neural Networks Forget?” The paper examined pruning, not distillation, but its findings are instructive — and underappreciated.
Hooker found that the examples most affected by compression are disproportionately those from underrepresented groups in the training data. Specifically, the long tail of rare, unusual, or minority-class examples suffers most when a model is made smaller.
The common patterns survive. The edge cases don’t.
Hooker’s findings concern pruning specifically. The mechanism, though, is analogous: both techniques prioritise the patterns a model has learned most confidently, which are by definition the most common ones.
The rare, edge-case knowledge that a teacher model acquired through exposure to millions of unusual examples is precisely the knowledge least likely to survive compression into a smaller student.
No peer-reviewed study has yet quantified this effect for distillation at frontier scale — a gap in the literature that is itself telling. It is not clear whether the gap exists because the effect is minor, or because nobody with access to frontier models has an incentive to publish findings that would undermine confidence in their distilled products.
The Real-World Gap
The benchmarks say 97%. The real-world gap is considerably wider — and harder to measure, because failures cluster in populations and use cases that benchmark designers rarely prioritise.
A distilled medical diagnostic model might match its teacher on the 50 most common conditions while missing rare diseases. A distilled legal reasoning model might handle routine contract analysis while stumbling on novel fact patterns. The discrepancy is the predictable consequence of compressing a system that learned from billions of examples into one that must represent that knowledge with a fraction of the capacity.
And then there is the problem of mimicry without comprehension. A student model trained on a teacher’s outputs learns to reproduce those outputs. It does not learn why the teacher produces them.
When the teacher is wrong — and frontier models are wrong regularly — the student faithfully inherits the mistake without the architectural context needed to diagnose it. The errors become second-hand, untraceable, and in some deployments, invisible until something breaks.
The Intellectual Property Abyss
The legal questions surrounding distillation have no good answers — only increasingly expensive ones.
Copyright law protects specific expressions, not ideas or knowledge. If a student model is trained on a teacher’s outputs — generated text, probability distributions, not copied code — it is far from clear that any copyright has been infringed.
OpenAI’s terms of service explicitly prohibit using its model outputs to train competing systems. But terms of service are contractual, not statutory. They bind the user who agreed to them, not a third party who obtained the outputs through other means.
Enforcement across international borders is effectively theoretical. OpenAI’s February 2025 memo to Congress did not announce a lawsuit. It called for policy intervention — an implicit acknowledgment that existing legal tools are inadequate.
The company framed distillation as “free-riding” on American AI investment, a rhetorical move designed to shift the issue from contract law to trade policy and national security.
Coordinated Distillation Attacks
Anthropic went further. On February 23, 2026, the company published a detailed account of what it described as coordinated distillation attacks by three Chinese AI firms — DeepSeek, Moonshot AI, and MiniMax — alleging that they had generated over 16 million exchanges with Claude through approximately 24,000 fraudulent accounts combined.
Days earlier, Google’s Threat Intelligence Group had published its own findings: commercially motivated actors had bombarded Gemini with over 100,000 carefully structured prompts in what GTIG described as model extraction and distillation attacks.
These allegations point to a fundamental challenge to the business model that funds frontier AI research. If the billions spent developing a cutting-edge model can be substantially replicated for a few million dollars through distillation, the incentive to invest in frontier research erodes.
The Regulatory Void
Europe’s AI Act, which entered into force on August 1, 2024, is the most ambitious attempt to regulate artificial intelligence to date. It imposes transparency obligations on providers of general-purpose AI models, including requirements to disclose training methodologies and data sources.
But the Act was drafted primarily with training-data governance and deployment risk in mind. Distillation — which can occur entirely through a model’s public API, without access to its training data or weights — sits awkwardly within the framework.
The Regulatory Ambiguity
A distilled model is not a copy of the teacher model in any sense the regulation clearly addresses. It is a new model, trained on a different dataset (the teacher’s outputs), with a different architecture, by a different organisation. Whether it inherits the teacher’s regulatory obligations is an open question the Act does not convincingly answer.
In the United States, regulation remains even more fragmented. The executive orders and proposed legislation that have emerged since 2023 focus primarily on safety testing, compute thresholds, and export controls for chips.
Distillation — which by definition requires less compute and can work with smaller models — slips beneath most of these thresholds. A distilled model that achieves frontier-level performance on specific tasks while remaining small enough to avoid reporting requirements is a genuine blind spot.
The blind spot is not small. Three staffers on congressional committees with AI oversight responsibilities, asked in early 2026 whether distillation-specific provisions were under consideration, offered no clear answer.
China’s Asymmetric Framework
China’s own regulatory framework offers no counterweight. The Interim Measures for the Management of Generative AI Services, which took effect on August 15, 2023, focus on content control and domestic deployment — requiring that AI-generated output reflect “core socialist values.”
They say nothing about the provenance of the knowledge a model contains, let alone whether that knowledge was distilled from a foreign competitor’s API. The asymmetry is structural: American and European regulations constrain how models are built and deployed at home, while doing nothing to prevent their capabilities from being extracted abroad.
What Should Give
The frontier labs’ bid for legal protection will probably fail, because the technology moves faster than any legislature. Distillation requires only API access and ingenuity, both of which are abundant and borderless.
OpenAI can update its terms of service. It cannot change the reality that querying a model millions of times and training a student on the results is trivially easy for a competent engineering team.
The strongest objection to this argument is that it proves too much. If distillation makes frontier models indefensible, why would anyone spend $100m training one?
The answer is that the training run is not the product — it is the loss leader. OpenAI does not need its next model to be undistillable. It needs that model to be the reason enterprises sign up for its platform, where the real revenue lies in API access, fine-tuning services, and data integration that no distilled model can replicate.
The investment case for frontier training has already shifted from “we will sell the model” to “we will sell everything around the model.” Distillation accelerates that shift. It does not prevent it.
This is already visible in how the major labs are repositioning. OpenAI’s pivot toward enterprise platforms, Anthropic’s push into government contracts, Google’s bundling of Gemini into its cloud infrastructure — all represent a bet that the moat is not the model but the system around it.
That bet is probably correct — and uncomfortable for companies that spent years telling investors their models were the product.
The End of an Era
The era in which a model’s weights constituted a defensible advantage is ending. Distillation made sure of that. The companies that recognise this first, and restructure around services, integration, and data partnerships rather than raw model capability, will define what comes next.
The ones that spend the next five years lobbying for legal protections against mathematical operations will find themselves in the position of IBM in the 1960s, watching DEC sell PDP minicomputers to engineering firms and university labs that didn’t need a mainframe and couldn’t afford one.
IBM’s architecture was superior — and it didn’t matter, because the economics had already decided.
Sources
[1] Sanh, V. et al., “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter,” Hugging Face, 2019. https://arxiv.org/abs/1910.01108
[2] Epoch AI, “How much does it cost to train frontier AI models?” June 2024; updated January 2025. https://epochai.org/blog/how-much-does-it-cost-to-train-frontier-ai-models
[3] Epoch AI, “The rising costs of training frontier AI models,” May 2024. https://arxiv.org/abs/2405.21015
[4] Reuters report on OpenAI’s memo to the U.S. House Select Committee on China, February 2025. https://www.reuters.com/technology/artificial-intelligence/openai-says-chinas-deepseek-trained-its-ai-by-distilling-us-models-memo-shows-2025-02-13/
[5] Hinton, G., Vinyals, O., & Dean, J., “Distilling the Knowledge in a Neural Network,” 2015. https://arxiv.org/abs/1503.02531
[6] Hooker, S. et al., “What Do Compressed Deep Neural Networks Forget?” 2019. https://arxiv.org/abs/1911.05248
[7] OpenAI Terms of Service, including restrictions on using outputs to develop competing models. https://openai.com/policies/terms-of-use
[8] Anthropic, “Detecting and preventing distillation attacks,” February 23, 2026. https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks
[9] Google Threat Intelligence Group, “GTIG AI Threat Tracker: Distillation, Experimentation, and Escalating Risks,” February 12, 2026. https://cloud.google.com/blog/topics/threat-intelligence/ai-threat-tracker-distillation
[10] Wadhwani AI, “Cough Against TB” mobile screening tool for tuberculosis detection in rural India. https://www.wadhwaniai.org/programs/cough-against-tb
[11] White & Case, “AI Watch: Global regulatory tracker — China,” covering the Interim Measures for the Management of Generative AI Services, effective August 15, 2023. https://www.whitecase.com/insight-our-thinking/ai-watch-global-regulatory-tracker-china
[12] OpenAI’s strategic shift from consumer tokens to enterprise value-based pricing and platform services. https://opentools.ai/news/openais-strategic-shift-from-tokens-to-value-in-the-ai-frontier
The Great Compression: How AI Model Distillation Is Rewriting the Rules of the Industry was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.